

August 1, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 17, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
In June 2026, Yahoo Finance reported that Meta had told roughly 6,000 employees, in an internal memo, that it would tighten oversight of their AI token usage and introduce spending controls — weeks after pushing those same employees to use AI more. According to that coverage, Meta's internal AI use alone is on track to cost the company billions of dollars in 2026. Within weeks, Amazon was reported to have shut down its own internal AI-usage leaderboard, and Uber was reported to have burned through its entire planned 2026 AI coding budget in the first four months of the year. The press coined a name for the reversal: tokenminimizing.
This is the appendix the tokenmaxxing trilogy was always going to need. The trilogy argued — before the reaction began — that celebrating token consumption measures the wrong thing, and that an organization without a governance layer ends up with only two settings: wide open, or clamped shut. The tokenminimizing reaction is the second setting. The point of this post is not that the prediction was correct; it's that both settings are the same mistake, recent reporting across three large technology companies illustrates it within a single quarter, and there's a third option that makes the whipsaw unnecessary.
The facts here are drawn entirely from published reporting, and we attribute each claim to its source rather than asserting any of it independently. We name these companies only because their internal moves became public through that reporting; we make no independent claim about any company's internal operations beyond what these outlets published.
Meta. As Yahoo Finance reported, citing a Meta internal memo first reported by The Information, Meta told roughly 6,000 staff it would introduce spending controls, budgets, and usage limits, citing internal AI costs on track to run into the billions of dollars in 2026. Per that coverage, employees and teams had limited visibility into their own consumption, and the company expects to move by 2027 toward a structured framework of budgets and allocation decisions. To get there, the reporting says, Meta built a centralized dashboard it calls an "AI Gateway" to track usage and spending in one place, with automated alerts for unusual spikes. That detail is worth pausing on: a company of Meta's scale, having run the maxxing experiment, is reported to be hand-building exactly the category of system — real-time attribution, spend tracking, spike alerts, structured budgets — that this series has argued belongs in the request path from the start.
Amazon. Weeks earlier, as TheStreet and other outlets reported (citing the Financial Times, which broke the story), Amazon shut down an internal leaderboard called "KiroRank" that scored employees on AI activity on its Kiro developer platform. According to that reporting, staff had inflated their scores by running low-value tasks through AI agents to climb the rankings — the behavior the industry now calls tokenmaxxing — which drove up compute costs. The reporting notes Amazon replaced the leaderboard with a metric it calls "normalized deployments," meaning AI-assisted code that actually ships. A senior executive reportedly told staff not to use AI just for the sake of using AI. That replacement is the input-to-output correction made concrete by Amazon itself: stop counting tokens consumed, start counting work shipped.
Uber. And as noted in the same Yahoo Finance report and covered earlier by Business Insider, Uber was reported to have exhausted its entire planned 2026 AI coding budget in the first four months of the year; the same coverage notes Uber's COO said the company had not found a clear link between higher AI spending and shipped results. Three companies, three different mechanisms, one quarter, the same shape.
The labels "tokenmaxxing" and "tokenminimizing" make this sound like two trends. It is more useful to read it as one pattern with two phases, now visible at three separate companies: adoption is encouraged with no governance layer underneath it, usage becomes the visible metric, costs surprise leadership, and the only lever available is a blunt one.
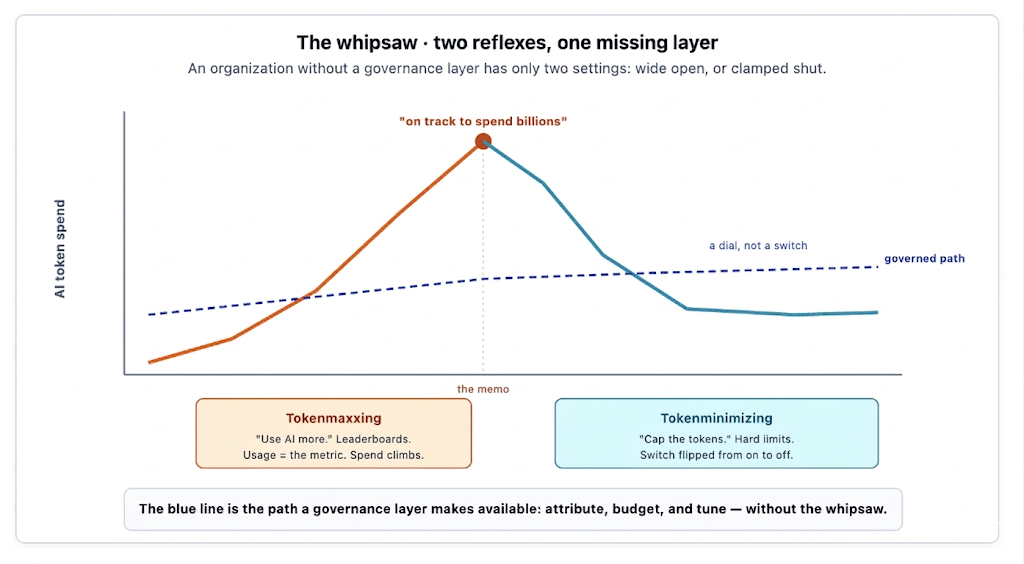
The tokenmaxxing trilogy (all links are in Reference) was not a celebration of token consumption. It was a critique of it. The central argument, made across all three parts, is the distinction between an input and an output: tokens are something you spend, and the work the tokens produce is the thing that actually matters. A leaderboard that ranks employees by tokens consumed is measuring the input and rewarding its maximization — and the moment a measure becomes a target, by Goodhart's Law, it stops being a good measure. The trilogy said this plainly while the maxxing phase was still in full swing, when the prevailing mood treated rising token graphs as unambiguous evidence of productivity.
That is the part worth being precise about, because it is easy to misread this post as a victory lap. It isn't one. The trilogy didn't predict that any specific company would send a memo in June 2026. It made a structural argument — that measuring the input would eventually force a painful correction — and the structural argument is what the reporting now illustrates, at more than one company. The remark attributed to Meta CTO Andrew Bosworth in MLQ's coverage — token usage alone is not a measure of impact — reads as the trilogy's thesis in a CTO's words, reportedly arrived at independently under the pressure of a billions-of-dollars forecast. And the Amazon case has been described in industry coverage as a textbook instance of Goodhart's Law: the moment token consumption became a leaderboard target, the reporting argues, it stopped measuring productivity and started measuring competitive anxiety. That is the trilogy's argument almost verbatim, reached independently by observers watching the same failure unfold.
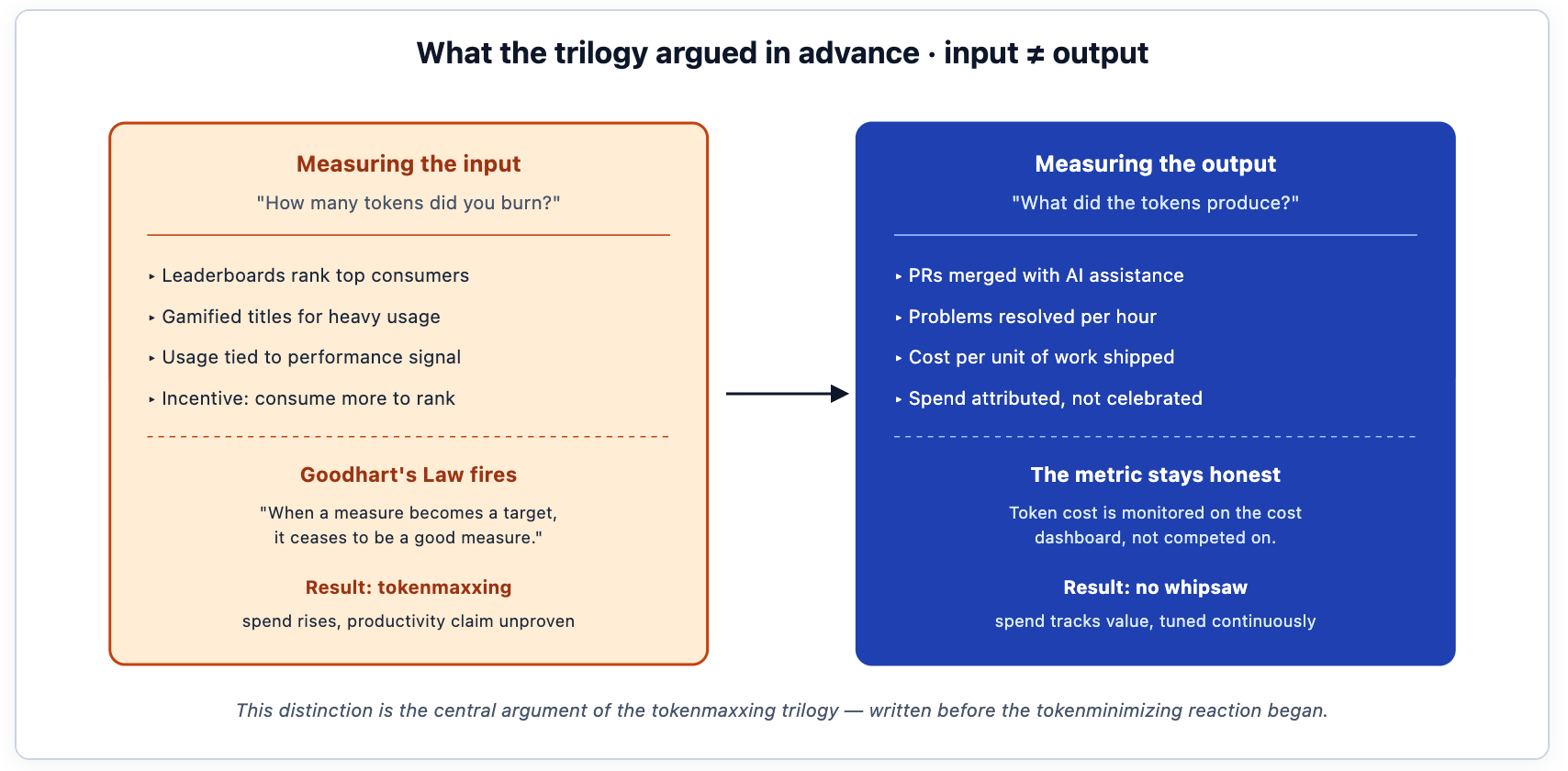
The trilogy's recommendation followed from the distinction: measure the output (work shipped, problems resolved, cost per unit of value), and keep token cost on the platform team's cost dashboard rather than on a leaderboard employees compete to top. An organization that does this never builds the incentive that produces the maxxing spike, and therefore never faces the bill that forces the minimizing clamp. The whipsaw is avoidable, but only by declining to take the first swing.
It is tempting to read the tokenminimizing reaction as the responsible correction — the adults arriving to shut down the party. That reading is wrong, or at least incomplete. A blanket token cap is not governance; it is the absence of governance wearing a responsible-looking costume. It throttles the security-review pipeline that was catching real vulnerabilities at the same rate it throttles the engineer who was gaming the leaderboard, because a blunt cap cannot tell the two apart. The organization trades one undifferentiated policy ("use AI freely") for another ("use AI less"), and neither policy can distinguish valuable spend from wasteful spend, which was the entire problem in the first place.
This is the reasonable core of the companies that burned money on tokens and are now reversing: the spend was real, the productivity questions were legitimate, and pulling back is a defensible response to a billions-of-dollars forecast with no attribution behind it. We are not critical of the decision to control cost. We are critical of the fact that, lacking a governance layer, the only available instrument is a sledgehammer. A company that swings to minimizing is making the best move available to it — given that it skipped the move that would have made a better one possible.
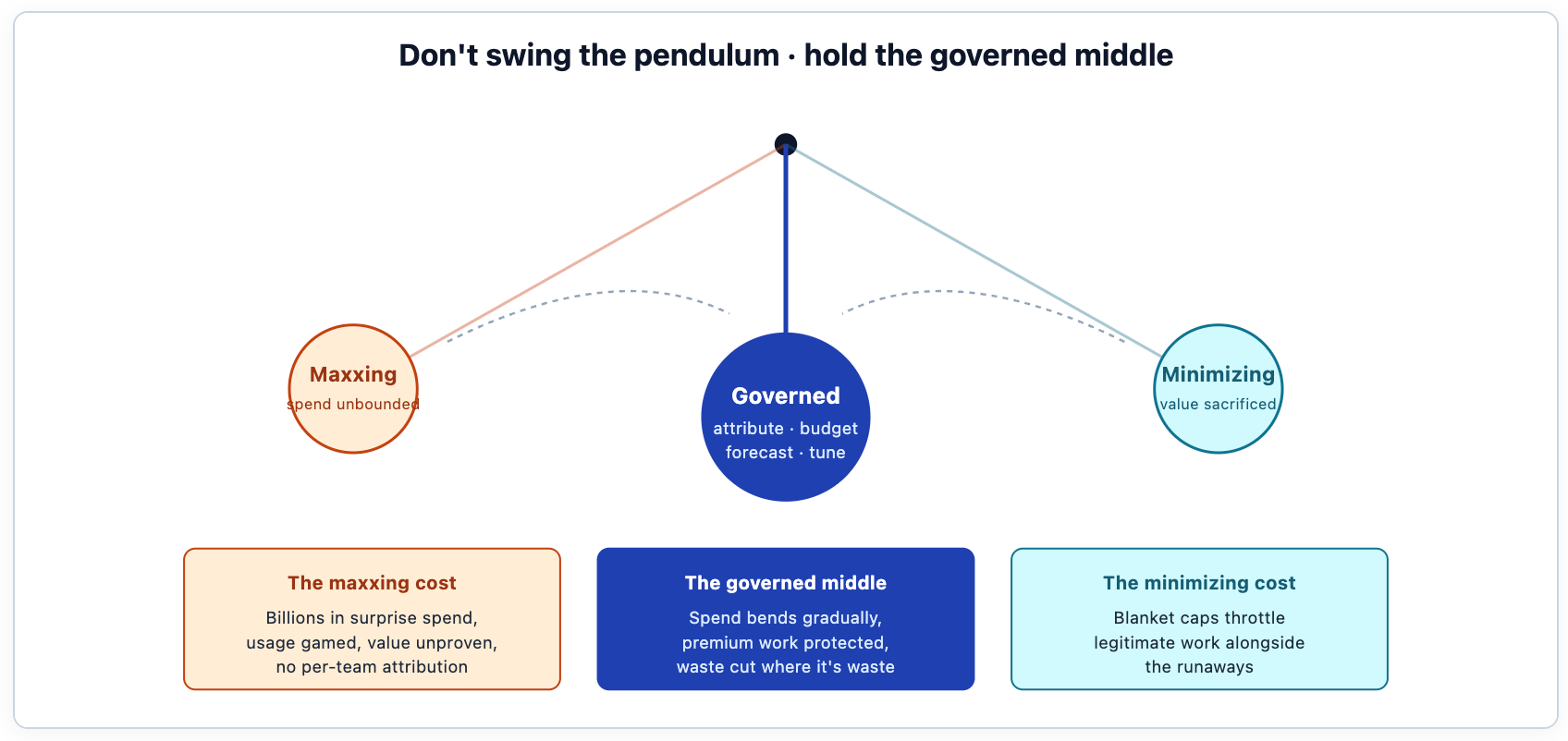
The governed middle is not a moderate compromise between maxxing and minimizing. It is a different axis entirely. The maxxing-minimizing axis runs from "spend everything" to "spend nothing." The governed axis runs from "spend blindly" to "spend with attribution, budgets, and a forecast." A team operating on the governed axis can spend aggressively on the workloads that produce value and starve the ones that don't — at the same time, because it can tell them apart.
Concretely, the layer the trilogy advocated, and that TrueFoundry's AI Gateway ships, has three parts. First, attribution: every request carries identity — team, repo, pipeline, cost center — so "who is spending" is a query, not an investigation. Second, hierarchical budgets with graduated responses: a soft alert at 75% of a cost center's cap, a constrained mode at 90% that transparently routes premium-model traffic to cheaper fallbacks so pipelines keep working, and a hard cap at 100% that fails cleanly with a descriptive error. Third, a rolling forecast that projects month-end spend with enough lead time to act before the cap fires. These are documented in TrueFoundry's Budget Limiting and Rate Limiting schemas, and they compose into a single property: the spend curve bends gradually under control instead of spiking and then collapsing.
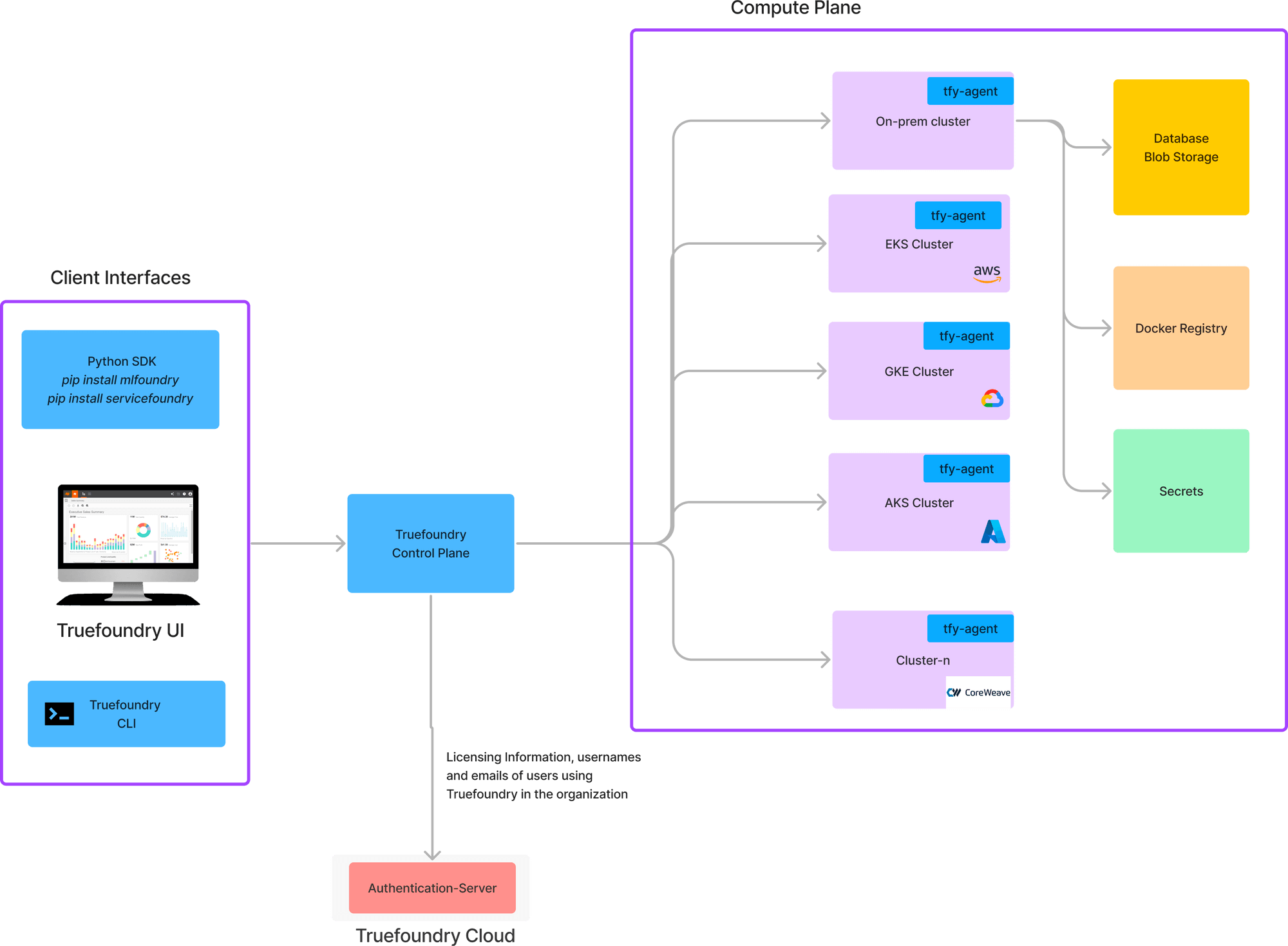
A team that had this layer in place during the maxxing phase would not have needed a reactive memo. The 75% alerts would have surfaced the heavy cost centers in real time; the forecast would have projected the billions-of-dollars trajectory months before it became a headline; the constrained mode would have flattened the curve on the wasteful workloads without touching the productive ones. There is a quiet validation in the current news here, and it is worth stating plainly but carefully: when Meta is reported to respond to its cost crisis by building an internal dashboard it calls an "AI Gateway," and Amazon is reported to replace its usage leaderboard with a shipped-code metric, those reports point toward the same architectural category TrueFoundry has productized — attribution, budgets, routing controls, and observability in the request path. TrueFoundry's AI Gateway is an enterprise-grade implementation of that same category: one OpenAI-compatible endpoint across its supported model catalog, attribution and budgets in the request path, and the control-plane/compute-plane split shown above that keeps it deployable in a regulated company's own cloud. TrueFoundry documents this split-plane model — the control plane managing configuration and policy while the compute plane runs in the customer's VPC, on-prem, or air-gapped environment, with "no data leaves your domain" as the stated boundary; teams in regulated settings should still confirm the exact data-handling guarantees against the deployment docs and their contract. We will not claim any of these companies should have used, or would have been saved by, TrueFoundry specifically — that is unknowable and not the point. The point is structural: the teams that build this layer early hold a dial when the bill arrives. The reason to say it carefully is the same reason the trilogy said it: the layer gives you the dial; it does not turn the dial for you.
The reason this matters for buyers is that a governance layer is only as good as the breadth of control it gives you in the request path. A thin routing proxy can attribute spend and stop there; an enterprise-grade gateway turns attribution into a full operating surface — cost, reliability, safety, access, and agents, governed in one place. TrueFoundry's AI Gateway is built as that surface, and the capabilities below are the difference between "we can see the spend" and "we can run the strategy." Each is documented on TrueFoundry's product and docs pages; TrueFoundry's observability overview and the AI Gateway product page are the references.
One endpoint, 1600+ models, sub-3 ms internal latency. Every model — OpenAI, Anthropic, Gemini, Bedrock, Mistral, self-hosted — sits behind a single OpenAI-compatible API; TrueFoundry's product page describes one endpoint across 1600+ models and 250+ LLMs. The auth, rate-limit, and load-balancing checks run in-memory, so the gateway adds minimal latency in the hot path; TrueFoundry documents sub-3 ms internal gateway latency and, on its observability overview, 350+ RPS on a single vCPU. The control surface costs you almost nothing in the request path, which is the precondition for putting everything else on it.
Guardrails on every request, in and out. The gateway applies input and output guardrails — PII detection and redaction, toxicity and bias checks, content moderation, and custom policies — and can connect to external services like OpenAI Moderation, AWS Guardrails, and Azure Content Safety. This is the layer that catches the NYC-MyCity-style failure: a response that advises something it shouldn't is blocked or routed to human review before it reaches the user. Guardrail activity is a first-class metric (llm_gateway_guardrails_requests_total), so you can see exactly how often each policy fires and on which routes.
Token-aware rate limiting, not just RPS. A single long prompt can cost more than a thousand short ones, so request-per-second limits are the wrong unit for AI. TrueFoundry enforces quotas by tokens or requests per minute, hour, or day, scoped to user, team, model, virtual account, or any metadata key — the exact mechanism that stops a single runaway loop or a leaderboard-gaming engineer from consuming a shared budget. This is the structural answer to tokenmaxxing: not a company-wide cap, but a per-identity ceiling that throttles the outlier without touching everyone else.
Access control built for the enterprise. Centralized API-key management means provider keys are never sprayed across application code; the gateway issues scoped tokens instead. RBAC with SSO, OAuth 2.0, and API-key auth governs who can call which model, and centrally stored, audit-ready request/response logging records who called what, with what data, and what came back — the compliance spine that GDPR, SOC 2, and HIPAA workloads require. Keys can be rotated or revoked without downtime.
Fallbacks and load balancing that keep the lights on. Declarative fallback chains, weighted and latency-based routing, health checks, and automatic failover mean a provider outage or a throttle becomes a transparent reroute rather than an incident. This is also a cost lever: the 90%-budget "constrained mode" from the trilogy is exactly a fallback rule that routes premium-model traffic to a cheaper tier when a budget threshold trips, so pipelines keep running while spend flattens. Fallback activity is observable per request (llm_gateway_fallback_requests_total), so you can quantify what every failover cost you.
MCP and agents, governed on the same plane. As agents move from single model calls to tool-using loops, the control surface has to follow them. TrueFoundry's MCP Gateway adds a central registry of MCP servers, user-scoped OAuth 2.0 plus virtual-account tokens for least-privilege tool access, RBAC and approval gates on sensitive actions, and per-tool tracing. The Agent Harness runs the agent loop itself: per its documentation, budgets, quotas, and rate limits apply to the loop as its own agent identity, and stop conditions — step ceilings, token budgets, and stall detection — are harness configuration rather than something each team rebuilds. This is the difference between governing the model call and governing the whole agentic workflow — model, tools, and the loop that drives them.
Observability that turns all of it into action. Every request emits OpenTelemetry traces with gen_ai.* attributes and exports to Prometheus, Grafana, Datadog, or Elastic; cost is auto-priced from providers' published rates and attributed by model, team, user, and metadata. The same dashboard shows policy activity — rate limits, fallbacks, guardrails, budgets — so a spend spike, a guardrail trip, and a fallback storm are all visible on one pane, in real time, instead of discovered on next month's invoice.
That last point is worth stating plainly for the buyer, and stating accurately: these primitives are what make the operating model possible — they are not the operating model by themselves. Cost attribution tells you where the money goes; budgets and rate limits bound it; fallbacks protect the experience while you tune; guardrails and access control keep it safe and compliant; the agent harness extends all of it to loops. Together they are what let a platform team implement the dial-not-switch model in one request path, rather than rebuilding each control in isolation — which is the work the whipsaw companies are now taking on after the fact. The one thing the gateway does not do is decide your policy for you: it gives you the dial and the data, and a capable team still has to set the thresholds and act on the alerts. That is not a weakness of the tooling; it is the correct division of labor, and it is exactly why having the layer in place early is what separates a strategy from a reflex.
It helps to put a number on the gap between "blind" and "attributed" — not a precise one, because no honest model could be, but an order-of-magnitude one. The estimator below maps directly to the TrueFoundry capabilities above: attribution surfaces the wasteful spend, and budgets, token-aware rate limits, and fallback routing are what let you act on it. The "actionable share" slider is shorthand for how much of the surfaced waste those mechanisms can actually recover. Nothing is hidden; the formula prints under the result.
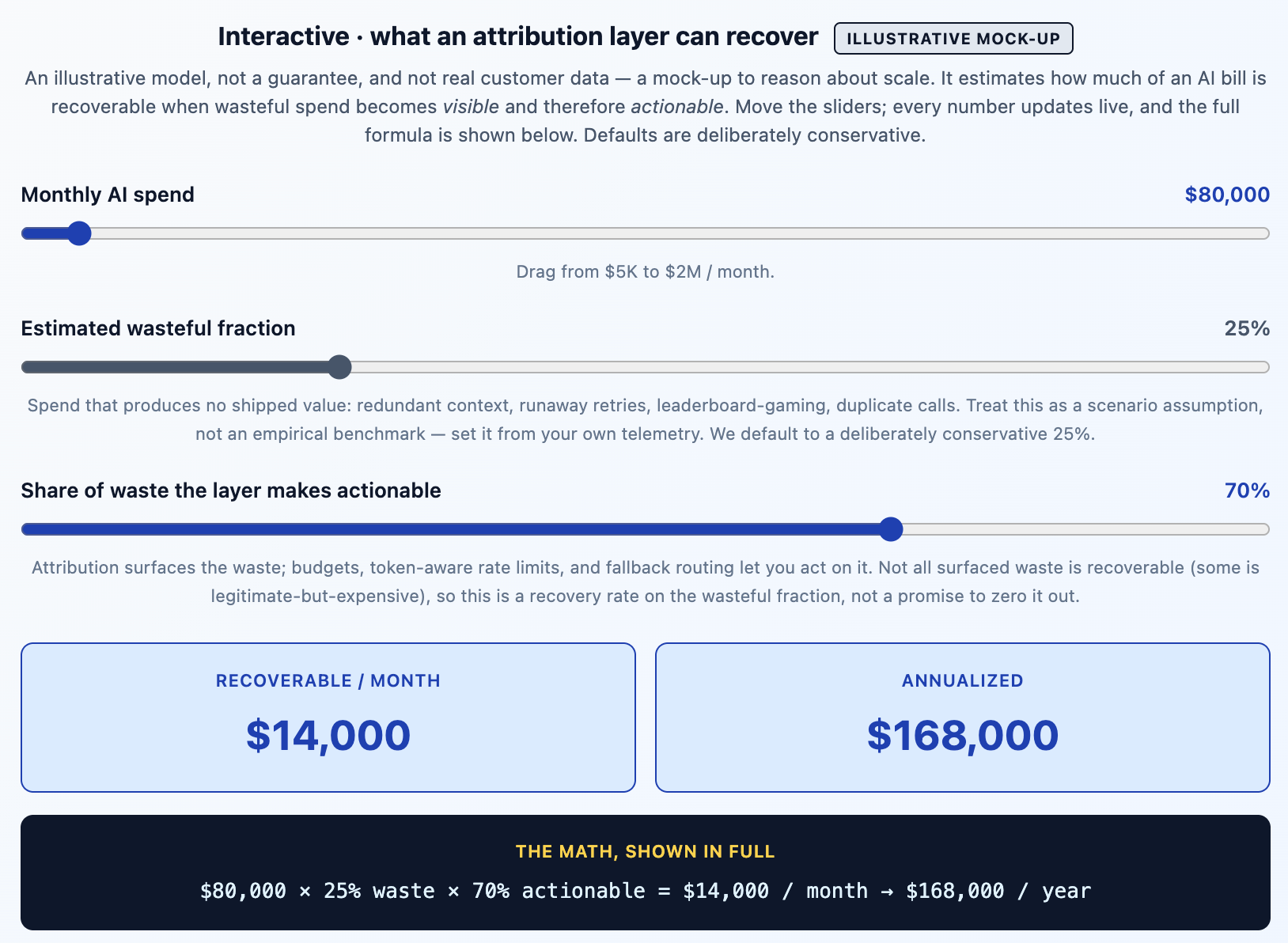
The reason the model is built on "wasteful fraction" rather than a flat percentage saving is that this is the honest shape of the problem. Some AI spend is pure waste — a 50,000-token manual injected into every prompt, a loop retrying a broken dependency, tasks run purely to climb a leaderboard. Some is legitimate and expensive and should be left alone. The value of an attribution layer is that it tells the two apart — and the budgets, rate limits, and fallbacks then let you cut the waste precisely — which is exactly what a blanket cap cannot do. The recoverable number is whatever fraction of the genuinely wasteful spend the gateway lets you see clearly enough, and control precisely enough, to act on.
If the whipsaw teaches anything, it is that the governance gap doesn't close — it moves. The next place it is moving is loop engineering: the mid-2026 practice, named in Addy Osmani's essay and echoed by practitioners like Anthropic's Boris Cherny, of designing the systems that prompt your agents rather than prompting them by hand. A loop finds work, hands it to an agent, checks the result, records state, and decides what's next — unattended, on a schedule. It is a genuine advance in the discipline, and it has the exact property that produced tokenmaxxing: there is no human in the cost loop.
TrueFoundry's two-part treatment of the topic — Loop Engineering at Enterprise Grade and its fleet-scale sequel — opens with the canonical incident: an engineer's morning loop spends two days enthusiastically retrying against a broken test environment over a weekend, and the cost is discovered on the invoice. That is the weekend token bill, one level up the stack from the individual leaderboard. And the predictable institutional reaction, when enough of those bills land, will be the loop-engineering version of tokenminimizing: ban unattended loops. It will be just as blunt and just as costly as the token cap, for the same reason — a blanket ban cannot tell the loop that is shipping real fixes from the loop that is burning money against a broken dependency.
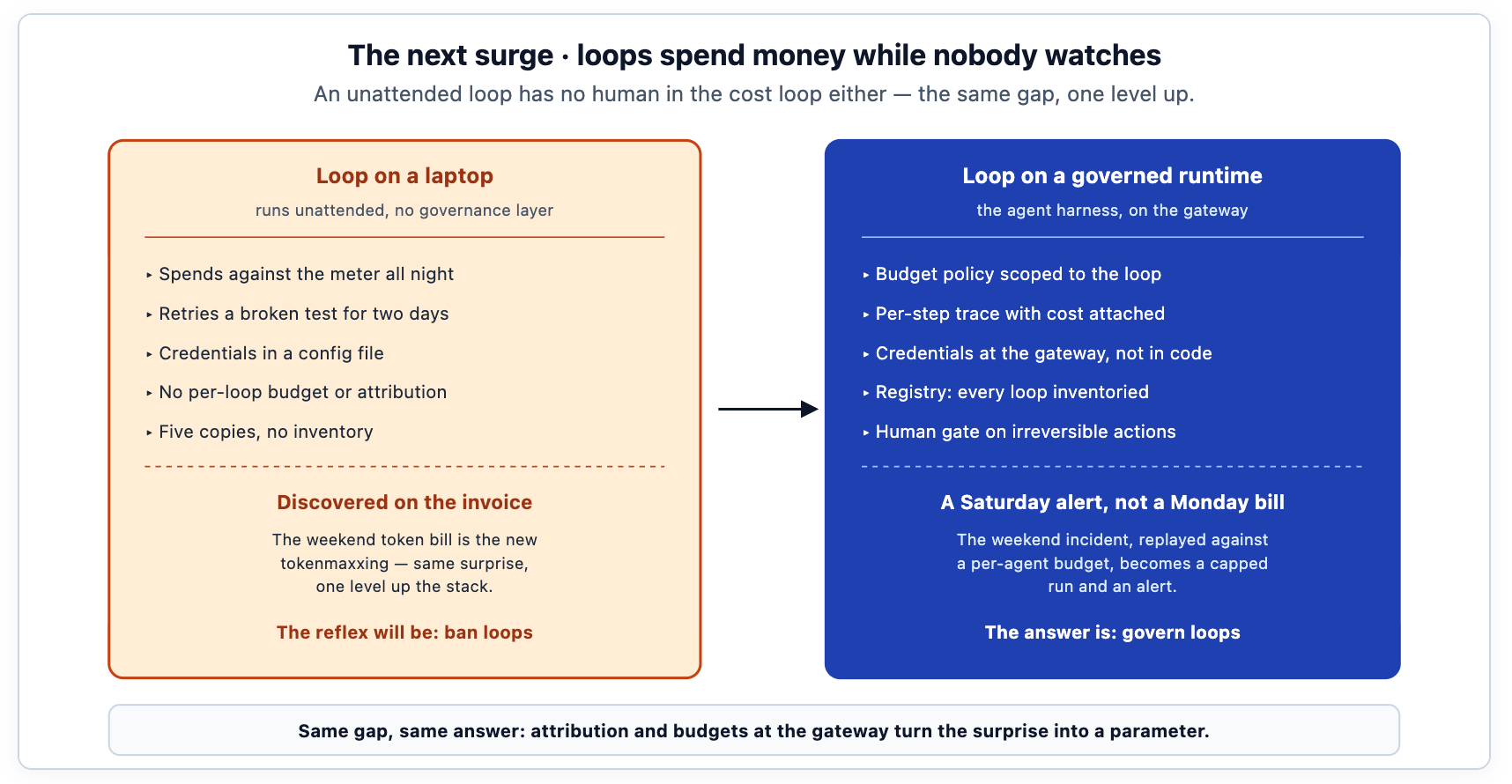
The answer is the same answer, applied one level up. Put the loop on a governed runtime — TrueFoundry's Agent Harness, built on the AI Gateway and MCP Gateway — where the loop runs as a registered agent with its own identity, budget and rate-limit policy scoped to that identity, and a per-step trace that attaches cost to every model and tool call. The weekend incident, replayed against a per-agent budget, becomes a capped run and a Saturday-night alert instead of a Monday-morning invoice. Each loop's economics are a line item, not a residual on the provider bill, so "is this loop worth it?" becomes a dashboard comparison rather than a debate. The harness adds the controls that unattended operation specifically requires: human-in-the-loop gates on irreversible actions, guardrails on every model and tool call, and stop conditions — step ceilings and token budgets — that turn "run until done" into "run until done or until the budget says stop."
The structural point is the one this whole series keeps arriving at. Loop engineering is not a cost problem first; it is a runtime and governance problem that has a cost dimension. But the cost dimension is where the tokenmaxxing lesson applies most directly: a loop, like a leaderboard-driven engineer, will spend whatever it is allowed to spend, and the only durable way to make that safe is to attribute the spend and bound it at the layer every request passes through. Teams that learned this from the token whipsaw get to apply it to loops before the loop whipsaw happens to them.
This post is the appendix to the trilogy; the trilogy is the argument it refers back to. Read in order, the three parts build the case that the whipsaw validates.
For the forward-looking thread on loops, the two-part loop-engineering series — Loop Engineering at Enterprise Grade and the fleet-scale sequel — carries the same argument into unattended agents, and the Agent Harness documentation is the product surface underneath it.
This is not a claim that token costs don't matter or that companies were foolish to control them. They matter enormously, and controlling them is correct. The criticism is narrower: controlling cost with a blanket cap, after encouraging unlimited usage, is the second half of a whipsaw that a governance layer would have made unnecessary. Both halves were avoidable.
It is also not a claim that TrueFoundry's gateway, or any gateway, is a substitute for judgment. The honest version of the argument is that the gateway changes what an organization can see and control — and therefore what good decisions are available to it — without making those decisions automatically. A team can hold the dial and still turn it the wrong way. The value is in having the dial at all, in a domain where most organizations discovered they had only a switch.
And it is not a prediction that loop engineering will go badly. It is a prediction that loops will spend money unattended, that some organizations will discover this on the invoice, and that the ones who apply the token-whipsaw lesson early — attribute, budget, and bound the spend at the gateway — will skip the loop-engineering version of the same painful swing. The pattern is the constant. The layer is the thing that breaks it.
Controlling cost is responsible; controlling it with a blanket cap is the least precise way to do it. A cap throttles valuable and wasteful spend equally, because it has no attribution behind it to tell them apart. The responsible version is to attribute spend per workload and bend the curve where the waste actually is — which is the governed middle, not the minimizing extreme. Minimizing is what's left when the attribution layer was never built.
The trilogy's central argument — that token usage is an input, that a leaderboard ranking people by input rewards maximizing it, and that this would force a correction — was published during the maxxing phase, before the tokenminimizing reaction began. It did not predict any specific company's memo; it made the structural argument that the reporting now illustrates. The observation attributed to Bosworth in published coverage — that raw token usage measures no real impact — reads as that argument restated by a CTO under cost pressure. The honest framing is structural foresight, not a specific prophecy.
The same reason you buy observability before you buy a fix: you cannot manage what you cannot see, and you cannot tune what you cannot control. The gateway gives an organization attribution, budgets, and a forecast — the instruments that make good cost decisions possible. It is the precondition for governance, not a replacement for the person who owns it. Without the layer, the only instruments available are "on" and "off," which is how the whipsaw happens.
That's the best position to be in, and the cheapest time to build the layer. The trilogy's argument is most valuable read before the maxxing phase, not after: install attribution and budgets while spend is small, measure output rather than input from the start, and the whipsaw never begins. A company that builds the governed middle early simply never has the crisis that forces the swing.
The mechanism is identical: a system that spends against the meter with no human watching it spend. A leaderboard-driven engineer and an unattended loop are the same cost-governance gap at two levels of the stack. The loop case is arguably sharper, because a loop can retry a broken dependency for days while everyone sleeps. The teams that govern loops at the gateway and the agent harness — budgets and rate limits scoped to the loop's identity, per-step cost traces, stop conditions — get the dial before they need it. The teams that don't will meet the loop-engineering version of the tokenminimizing memo.
No, and we want to be precise about this. According to the reporting, Meta built its own internal dashboard and named it "AI Gateway" — it is a separate, internally-built system that happens to share the category name. We have no information that Meta uses, evaluated, or endorses TrueFoundry, and we make no such claim. The reason we find the detail striking is convergent, not commercial: a company of Meta's scale, having run the maxxing experiment, is reported to be hand-building the same category of system — real-time attribution, spend tracking, spike alerts, structured budgets — that TrueFoundry ships as a product. That independent convergence is evidence the architecture is right, not evidence of any relationship between the companies.
Reporting on the token-policy reversals (all factual claims about these companies in this post are attributed to these published accounts; we make no independent claims beyond them):
Meta — Yahoo Finance / StockTwits, "Meta's AI Costs Spike — Company Reportedly Tightens Grip With New Tracking System" (freely accessible, the primary source used here); The State of AI, "From Tokenmaxxing to Tokenminimizing"; MLQ, "Meta Caps Internal AI Token Spending." The story was originally reported by The Information (Jyoti Mann; subscription).
Amazon — TheStreet, "Amazon Joins Microsoft in Sending Shocking Message to Employees"; Human Resources Director, "Amazon Shuts Down AI Leaderboard After Tokenmaxxing" and "Amazon Workers Are Gaming the AI Leaderboard" (Goodhart's Law analysis). The KiroRank shutdown was originally reported by the Financial Times.
Uber — Business Insider, "The Tokenmaxxing Debate"; the Uber budget-exhaustion detail is also noted in the Yahoo Finance and TheStreet coverage above.
The tokenmaxxing trilogy (the argument this post is an appendix to):
Part 1 — The Cost-Governance Gap. Part 2 — The Architecture of Governed AI Usage. Part 3 — From Token Spend to AI Leverage.
Loop engineering (the forward-looking thread): Loop Engineering at Enterprise Grade — From Laptop Loops to Governed Runtimes; Loop Engineering, Continued — From One Governed Loop to an Operable Fleet; and the originating community essay, Addy Osmani, "Loop Engineering" (June 2026).
TrueFoundry product documentation (the configurations and primitives referenced in this post):
Platform overview and architecture — docs.truefoundry.com/introduction. AI Gateway — product page. Budget Limiting — configuration reference. Rate Limiting — configuration reference. Request Headers — the metadata and header contract. Cost Tracking — public and private pricing modes. Agent Harness — the governed runtime for unattended loops.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception






.webp)




.webp)


.webp)


