













.png)
July 30, 2026
|
5 min read

Published: June 17, 2026

Blazingly fast way to build, track and deploy your models!
Six months after Noor’s loops moved off her laptop, Northwind has eleven registered triage and maintenance loops, and the problems have changed shape. Nothing is on fire the way the weekend token bill was on fire. Instead: two loops both “own” the release-notes draft and overwrite each other every Friday; the Tuesday dependency-bump loop quietly stopped doing anything useful three weeks ago because a model it depended on was deprecated and it kept passing its own checker anyway; a security reviewer noticed that the loop reading inbound bug reports will cheerfully follow instructions written in a bug report; and the cheapest, most-used loop now spends more than the next four combined, and nobody can say whether it’s worth it. None of these are the failures the first post fixed. They’re the failures that only appear once the pattern works well enough to multiply. That’s the subject here.
The first post did the vertical translation — laptop primitive to governed primitive, one loop at a time. This post does the horizontal one: what an organization has to make true across loops and over their lifetime. The vocabulary still follows Addy Osmani’s June 2026 essay and the surrounding discussion (Steinberger, Cherny, Willison), paraphrased with credit; the enterprise half follows TrueFoundry’s Agent Harness and Gateway documentation.
The first post vs. this one
Osmani’s anatomy describes a loop in the singular — one heartbeat, one set of skills, one maker and one checker. That is the right way to learn the pattern and the wrong way to run it, because loops do not stay solitary. They are useful, so they reproduce, and the moment there are several they start interacting in four ways the single-loop picture never has to account for.
Four ways loops interact once there is more than one
The fan-out case is already first-class on the harness. TrueFoundry’s Agent Harness sub-agents let the root agent delegate focused subtasks to parallel sub-agents, each with its own isolated context, returning only concise results — a context-hygiene win and a fleet-management win, since each delegated run is a unit you can trace independently. Delegation is deliberately one level deep and sub-agents can’t message the user — guardrails against a fleet that spawns a fleet that spawns a fleet. (Worth being precise: sub-agents share the root agent’s tools and sandbox, so the isolation here is about context, not a separate set of tool grants — privilege boundaries belong at the agent and MCP level, which is the next section.)
The operating pattern that answers all four interactions is to treat each loop as a registered agent definition rather than a script, so the fleet has an inventory. On the harness, each loop is an agent definition — a model, MCP servers, skills, instructions — that lives in a catalog, runs in the same gateway plane as all other model and tool traffic, and carries its own identity. That last word is what makes the fleet tractable: per-agent identity is what lets contention, cost, and access be reasoned about per loop instead of per laptop. Northwind’s release-notes collision gets fixed not with cleverness but with ownership — one loop owns the artifact, the registry says so, and “which loops touch this?” is a lookup, not a hunt.
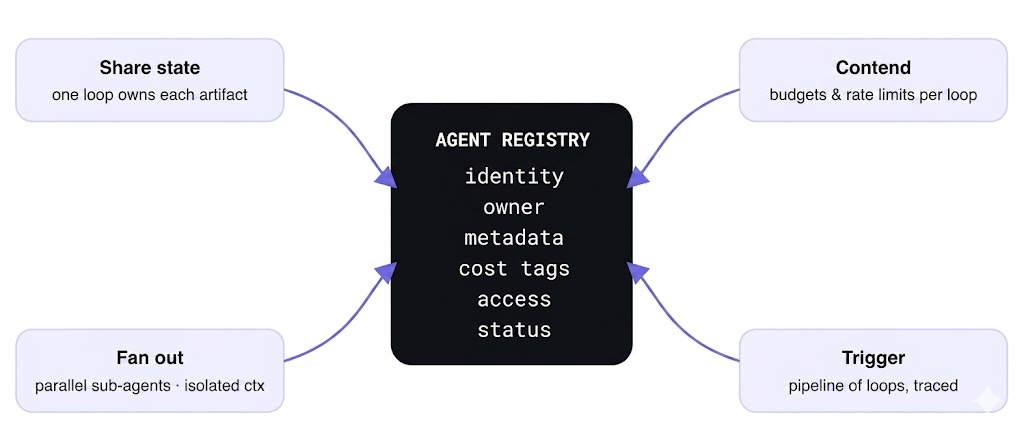
The defining fact about a loop is that nobody is watching it, and the corollary the single-loop discussion underplays is that nobody is watching it when the world breaks. A human at the keyboard absorbs a provider 503 without noticing — they just hit enter again. An unattended loop at 3 a.m. meets the same 503 and either dies, or worse, retries forever against a broken dependency and reprises Noor’s weekend bill. Reliability mid-run is not a nice-to-have for loops; it is the difference between a loop and a liability.
The AI Gateway is where a loop borrows the reliability it can’t build for itself.
Reliability a loop borrows from the gateway
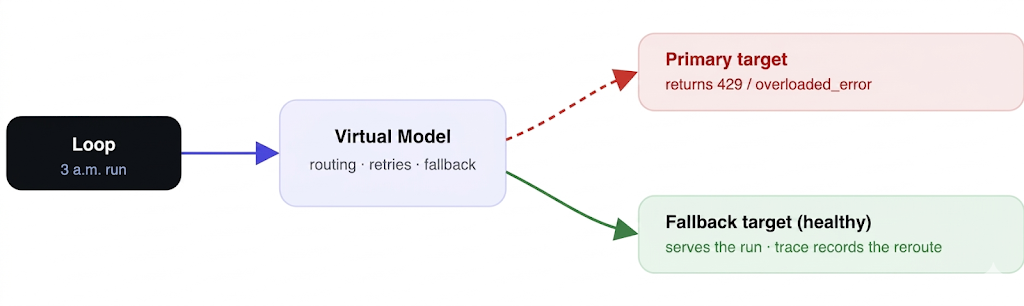
One thing the gateway can route around but cannot fix for you: idempotency. If a loop’s “open a PR” or “post to the channel” tool call gets retried after a network blip, you want one PR, not three. That’s a property of how the loop’s tools are designed (idempotency keys, create-or-update semantics), and it’s worth stating plainly because reliable retries make non-idempotent side effects more likely to double-fire, not less. The gateway gives you bounded retries; you still owe the fleet idempotent actions.
Here is the topic the single-loop framing has the least to say about, and it deserves the most care. A loop’s whole value is that it reads the world — overnight CI output, open issues, error feeds, inbound emails, sometimes the open web — and acts on what it finds. Every one of those inputs is untrusted content that the loop will treat as instructions if you let it, and the thing that makes this acutely dangerous in a loop is the missing human turn. In an interactive session a prompt injection has to get past a person watching the output. In an unattended loop the injected instruction is read, believed, and acted on before anyone is awake. Northwind’s bug-report-reading loop following instructions embedded in a bug report is not an exotic attack; it is the default behavior of a system designed to do what its inputs tell it.
Least privilege at the agent and tool-grant boundary — not in a prompt. The maker/checker split is also a blast-radius split: a checker that can write is just a second maker with a security hole. The mistake to avoid is treating a verifier prompt like an authorization system. Enforce the boundary where it actually holds: the MCP Gateway cleanly separates inbound auth (which loop is calling) from outbound auth (whose credentials reach the downstream system), with per-tool RBAC and per-user OAuth delegation in between. If a workflow needs hard read-only vs. write separation, model it explicitly — separate agents with separate MCP grants, or separate tool policies — rather than relying on the checker to behave. An injection that reaches an agent without the relevant write grant hits a wall prompting alone never builds: the grant simply isn’t there. (TrueFoundry sub-agents today give each delegated task isolated context and parallel execution while sharing the root agent’s tools, so the privilege boundary belongs at the agent and grant level, not inside the delegation.)
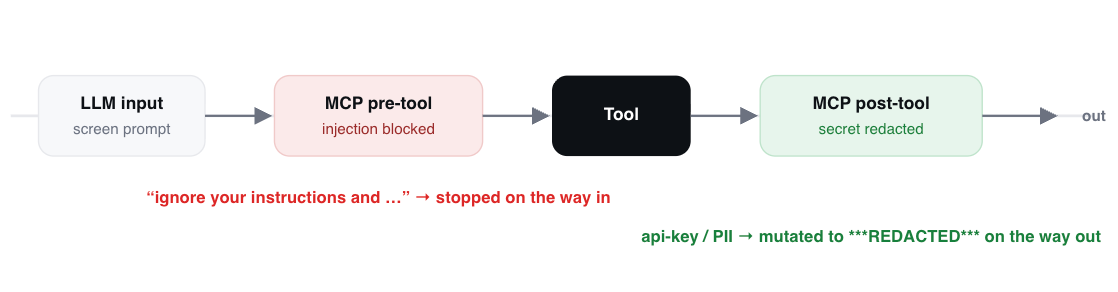
Guardrails on every call — including tool calls. The part teams miss is that injection and exfiltration don’t only ride the model’s text channel; they ride tool inputs and outputs too. TrueFoundry’s guardrails run on four hooks — LLM input, LLM output, MCP pre-tool, and MCP post-tool — so prompt-injection and secrets-detection checks screen not just what the model says but what the loop fetches and what it’s about to send. Because these are configured at the gateway, every loop inherits the policy automatically — no depending on five engineers to each remember it.
Human gates on the irreversible. A perfect checker still doesn’t earn an unattended merge. Human-in-the-loop approvals pause the run before a destructive or non-read-only tool call, hold the run’s state durably, and resume only on an explicit decision — and the “which tools are destructive” judgment is made once at the MCP Gateway, org-wide, so it covers loops that don’t exist yet. Sub-agents can trigger the same gate. This is the structural completion of the maker/checker idea: the checker grades the work; the gate guards the action; injection has to defeat both, and the second one isn’t a model it can talk its way past.
The single-loop story is told in the present tense — you build the loop, it runs. But a loop that earns its place runs for months, and over months it is edited: its instructions get tweaked, its skills get new versions, the models under it get deprecated and replaced, the systems it integrates with change their APIs. A loop is long-lived software that mutates while unattended — and that has a lifecycle, which is the thing a fleet cannot survive without.
Day-2 failure modes and the runtime’s answer
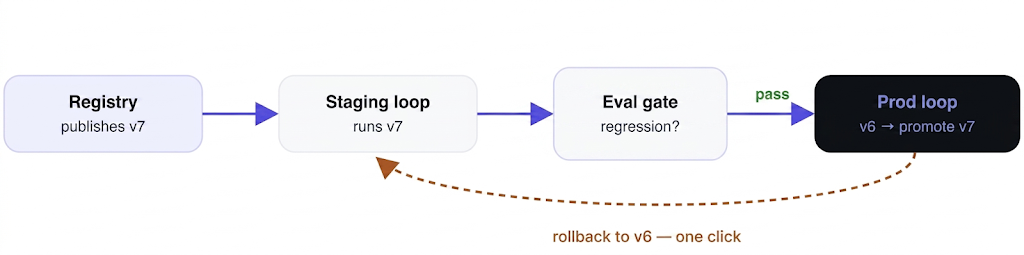
The runtime answers each as version control plus measurement, not heroics. Skills are versioned artifacts in the Skills Registry — you pin a version to a production loop, test a new version on a staging loop, and roll back instantly if it regresses, with an audit trail of what changed and who changed it; prompts get the same treatment in the Prompt Registry. That turns “someone edited the skill” from a Friday incident into a Tuesday promotion: staging loop on v7, prod loop on v6, promote only when v7 has earned it — and an eval gate should stand between an unattended edit and an unattended mistake.
And the dead-weight question becomes a line item. Because every run is a per-step trace with cost, tokens, and latency, and each run can carry loop or agent metadata, gateway cost analytics can roll spend up by loop, team, and model over time — so “is this loop worth it?” stops being a debate and becomes a comparison: the checker’s cost visible separately from the maker’s, the popular loop’s economics legible enough to justify it or retire it. The lever is tagging the traffic correctly; the rollup follows from the metadata.
Everything above is configuration, and configuration is the point: the fleet’s behavior should be declared, reviewable, and diffable — GitOps for loops — rather than living in scattered scripts and remembered conventions. An illustrative shape (simplified, not literal product schema):
# Fleet-level policy (set once, at the gateway — inherited by every loop)
gateway:
routing:
virtual_model: triage-default # weight/latency/priority targets + fallback
retries: { attempts: 2, on_status_codes: ["429","500","502","503"] }
caching: { type: semantic, similarity_threshold: 0.9, namespace_per: agent }
guardrails: # all four hooks, every loop
llm_input: [prompt-injection]
llm_output: [pii, secrets-detection]
mcp_pre_tool: [prompt-injection]
mcp_post_tool: [secrets-detection, pii]
budgets:
- { applies_per: agent, limit: 50/day, alert_at: [75,90,100] } # no more weekend bills
destructive_tools: [merge_pr, delete_*, deploy_*] # org-wide approval gate
---
# One loop in the fleet (references the above by name — no keys, ever)
agent:
name: bug-report-triage
owner: platform-team # the registry knows who owns it
model: triage-default # the virtual model, not a raw endpoint
instructions: ./triage.md@v6 # versioned; staging runs @v7
skills: [triage-runbook@v3] # pinned; rollback is one click
mcp_servers: [github, linear] # scoped, rotatable, RBAC'd at MCP Gateway
subagents: [explorer] # isolated context, parallel — share the root's tools
# hard read-only vs write separation → model as separate agents / MCP grants, not a prompt
harness: { max_steps: 60, max_tokens_per_run: 1_500_000 }
trigger: { schedule: "0 6 * * 1-5" } # the heartbeat — no laptop requiredThe exact field names above are illustrative — the real product primitives are routing and fallback, caching, guardrails, budgets and rate limits, MCP auth, skills, prompt versions, and approvals; the fleet-level policy shape is an operating convention you implement with them. The shape is the argument. Fleet-wide safety (routing, guardrails, budgets, the org-wide destructive-tool list) is declared once and inherited; per-loop specifics (owner, pinned versions, sub-agents) are declared per loop; and no long-lived provider or tool credentials need to appear in the loop definition — models resolve at the AI Gateway, tools authenticate at the MCP Gateway, skills come from the registry. Adding the twelfth loop is a reviewed pull request, not an archaeology project for the eleven that came before.
Osmani’s closing warning — the loop changes the work, it doesn’t delete you from it — survives the jump to a fleet, and gets a second clause. At single-loop scale, the danger is comprehension debt: the gap between what the loop ships and what you understand, growing with every unread PR. At fleet scale there’s a parallel risk — operational debt: the dashboards exist, the traces exist, the budgets exist, and no one is appointed to read them. A runtime makes the fleet legible; it does not make it governed. Legibility is the precondition for governance, not a substitute for the person who owns the review.
So the role the fleet creates is not “the person who built the loops” but “the person who operates them” — who watches review rates and approval patterns, reads the per-loop economics, and decides which loop to pin, promote, or retire. That role is cheaper and more possible on a managed harness than on a pile of personal rigs, because the operator inherits one pane of glass across model, tool, and agent traffic. But it is still a role, and the organizations that do loop engineering well will be the ones that staff it. Steinberger’s line was that you should be designing loops that prompt your agents; the fleet-scale corollary is that someone should be operating the loops that prompt your agents — and Cherny’s “my job is to write loops” has a manager’s mirror image: somebody’s job is to run them.
We only have a handful of loops. Is “fleet” thinking premature?
The transition is quieter than you’d expect — it’s not a decision, it’s a Tuesday. Loops reproduce because they work, and the first time two of them touch the same system, or both spike the same provider, or one follows a poisoned input, you’re operating a fleet whether or not you’ve named it. The cost of fleet thinking early is a registry and some policy; the cost of it late is the four incidents in this post’s opening paragraph.
How is a loop reading external content different from any agent reading external content?
By the missing human. Both face prompt injection; only the loop faces it with nobody in the turn to catch the obviously-wrong action before it executes. That’s why the loop case leans harder on defenses that don’t require a human — least-privilege agents and MCP grants, isolated-context sub-agents, gateway guardrails on tool inputs and outputs, and hard approval gates on irreversible actions — rather than on a reviewer who, by definition, isn’t there.
Doesn’t routing and fallback just hide failures the loop should surface?
They hide transient failures, which is the goal — a 503 that resolves on the next target is noise, not signal. What they must not hide is persistent failure, which is why fallbacks pair with traces and budgets: the reroute keeps the run alive, and the trace records that it happened, so a loop that’s constantly failing over is visible as a pattern even though no single run died. Reliability you can’t see is just a slower way to be surprised.
How do we change a loop that’s been running unattended for months without breaking it?
The same way you change any long-lived production software: pin the current version, run the candidate on a staging loop against recorded cases, gate promotion on not regressing, promote, and keep rollback one click away. The failure mode to design out is the well-meaning edit shipped straight to a 6 a.m. loop — versioning and an eval gate turn that into a reviewed promotion instead of a silent regression.
The first post’s thesis was that a loop is a production system the instant it runs without you. The Day 2 thesis is the plural and the long form of the same idea: a collection of loops, running for a year, is a production system-of-systems — with a system-of-systems’ needs: an inventory, isolation, reliability under failure, defense against hostile input, a release process, and an owner. Design the loop, as Osmani says, like someone who intends to stay the engineer. Operate the fleet, we’d add, like someone who intends to stay the operator — on a runtime built to be operated, not just run.
Northwind and Noor are an illustrative composite continued from the first post, not a specific organization or incident. The loop-engineering framing follows Addy Osmani’s June 2026 essay and surrounding community discussion (Steinberger, Cherny, Willison), paraphrased with credit; quoted phrases are under fifteen words and attributed. Configuration snippets are simplified for readability and are not literal product schema. TrueFoundry capabilities reflect public documentation at the time of writing; verify against current docs.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.webp)






.webp)


.webp)
.png)
.webp)
.webp)
.webp)




