











.webp)
Conçu pour une IA à grande échelle dans le monde réel
99,99 %
Les basculements, le routage et les garde-corps centralisés garantissent que vos applications d'IA restent en ligne, même lorsque les fournisseurs de modèles ne le font pas.
PLUS DE 10 MILLIARDS
Inférence évolutive à haut débit pour l'IA de production.
30 %
Les contrôles intelligents de routage, de traitement par lots et de budget réduisent le gaspillage de jetons.
1600+
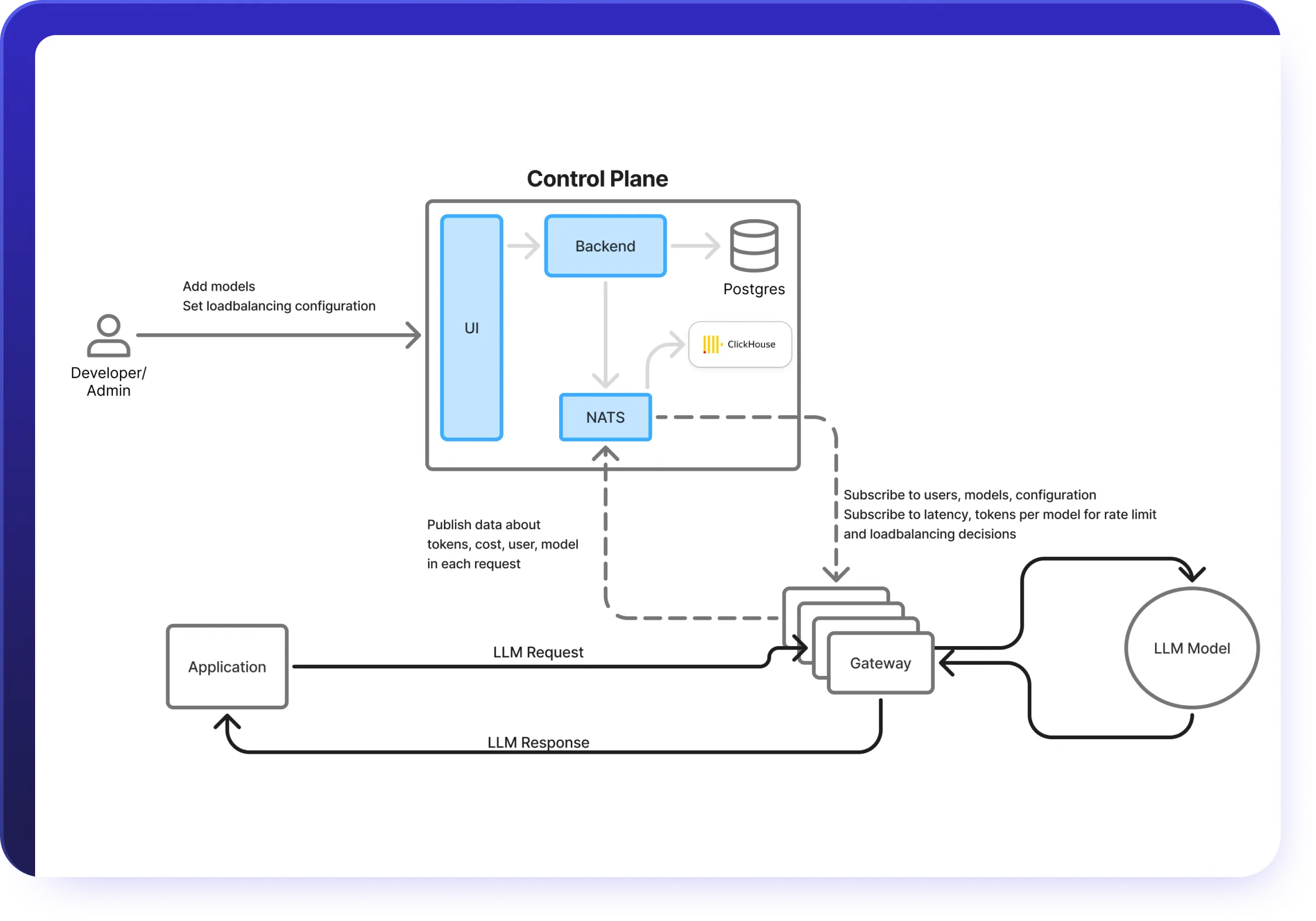
Connected through one AI gateway.
AI Gateway : accès unifié à l'API LLM
Simplifiez votre stack GenAI grâce à une passerelle IA unique qui intègre tous les principaux modèles.
- Connectez-vous à OpenAI, Claude, Gemini, Groq, Mistral et à plus de 250 LLM via une API AI Gateway
- Utilisez la passerelle AI pour prendre en charge les types de modèles de chat, de complétion, d'intégration et de reclassement
- Centralisez la gestion des clés d'API et l'authentification des équipes en un seul endroit.
- Orchestrez des charges de travail multimodèles de manière fluide dans votre infrastructure.

.avif)
Observabilité d'AI Gateway
Track your AI gateway performance, costs, and ensure compliance across models in real-time.
- Surveillez l'utilisation des jetons, la latence, les taux d'erreur et les volumes de demandes sur l'ensemble de votre système.
- Stockez et inspectez les journaux complets des demandes/réponses de manière centralisée pour garantir la conformité et simplifier le débogage.
- Étiquetez le trafic à l'aide de métadonnées telles que l'identifiant utilisateur, l'équipe ou l'environnement pour obtenir des informations détaillées.
- Filtrez les journaux et les mesures par modèle, équipe ou zone géographique pour identifier rapidement les causes profondes et accélérer la résolution.

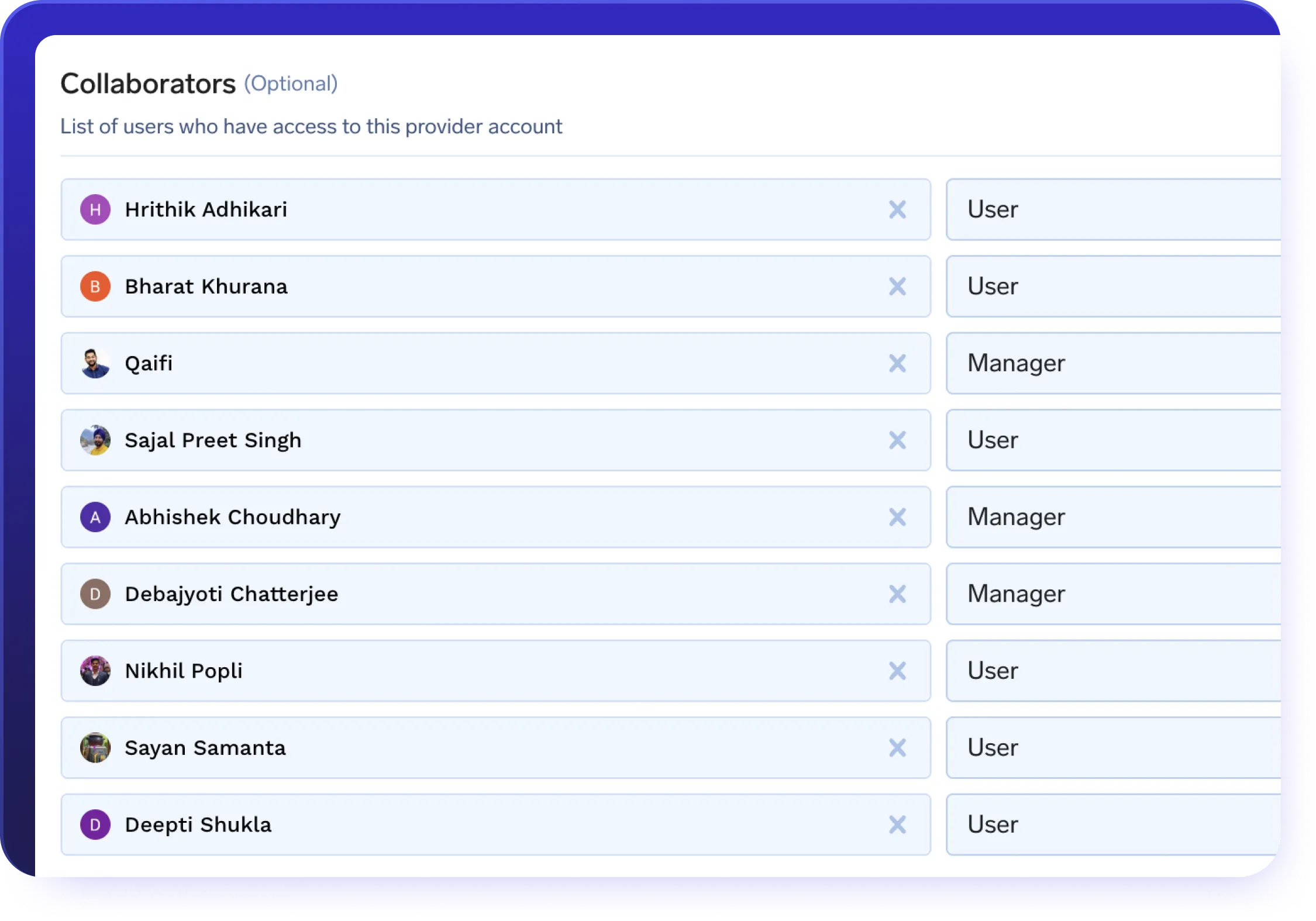
Contrôle des quotas et des accès via AI Gateway
Renforcez la gouvernance, contrôlez les coûts et réduisez les risques grâce à une gestion cohérente des politiques.
- Appliquez des limites de débit par utilisateur, service ou terminal.
- Définissez des quotas basés sur les coûts ou sur des jetons à l'aide de filtres de métadonnées.
- Utilisez le contrôle d'accès basé sur les rôles (RBAC) pour isoler et gérer l'utilisation.
- Gérez les comptes de service et les charges de travail des agents à grande échelle grâce à des règles centralisées.
Inférence à faible latence
Run your most performance-sensitive workloads through a high-speed AI gateway infrastructure.
- Atteignez une latence interne inférieure à 3 ms, même avec des charges de travail à l'échelle de l'entreprise.
- Évoluez en toute fluidité pour gérer le trafic en rafale et les charges de travail à haut débit.
- Offrez des temps de réponse prévisibles pour les assistants de chat en temps réel, RAG et IA.
- Placez les déploiements à proximité des couches d'inférence pour minimiser la latence et éliminer la latence du réseau.
Routage et solutions de secours de la passerelle AI
Garantissez la fiabilité, même en cas de défaillance du modèle, grâce à des contrôles de trafic intelligents AI Gateway.
- Prend en charge le routage basé sur la latence vers le LLM le plus rapide disponible.
- Répartissez le trafic de manière intelligente à l'aide d'un équilibrage de charge pondéré pour plus de fiabilité et d'évolutivité.
- Revenir automatiquement aux modèles secondaires en cas d'échec d'une demande.
- Utilisez le routage géo-sensible pour répondre aux besoins régionaux en matière de conformité et de disponibilité.
.webp)
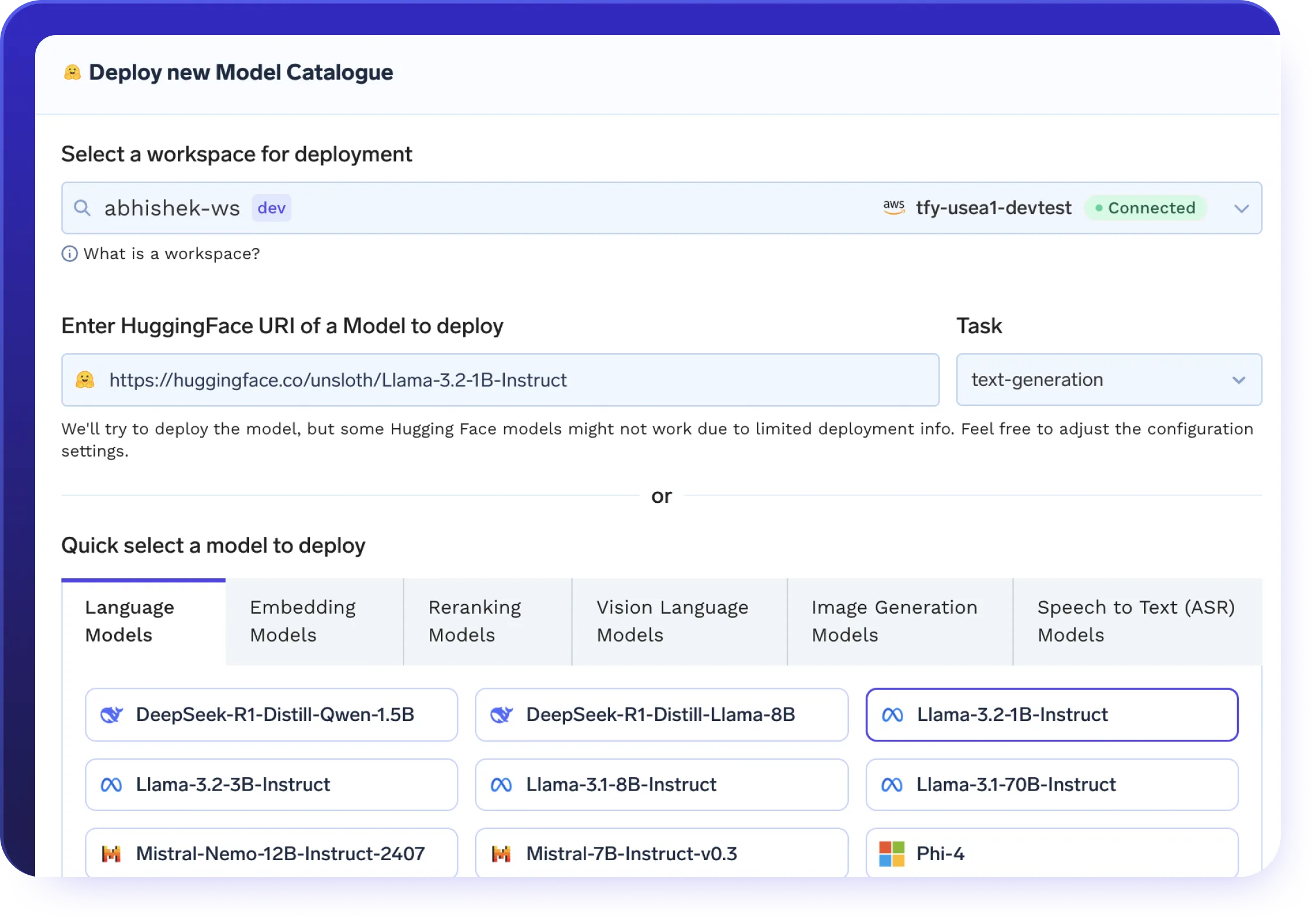
Servez des modèles auto-hébergés
Exposez des modèles open source avec un contrôle total.
- Déployez LLama, Mistral, Falçon et plus encore sans aucune modification du SDK.
- Compatibilité totale avec vLLM, SGLang, KServe et Triton.
- Rationalisez les opérations grâce à la gestion basée sur HELM de la mise à l'échelle automatique, de la planification des GPU et des déploiements
- Exécutez vos propres modèles dans des environnements VPC, hybrides ou ventilés.
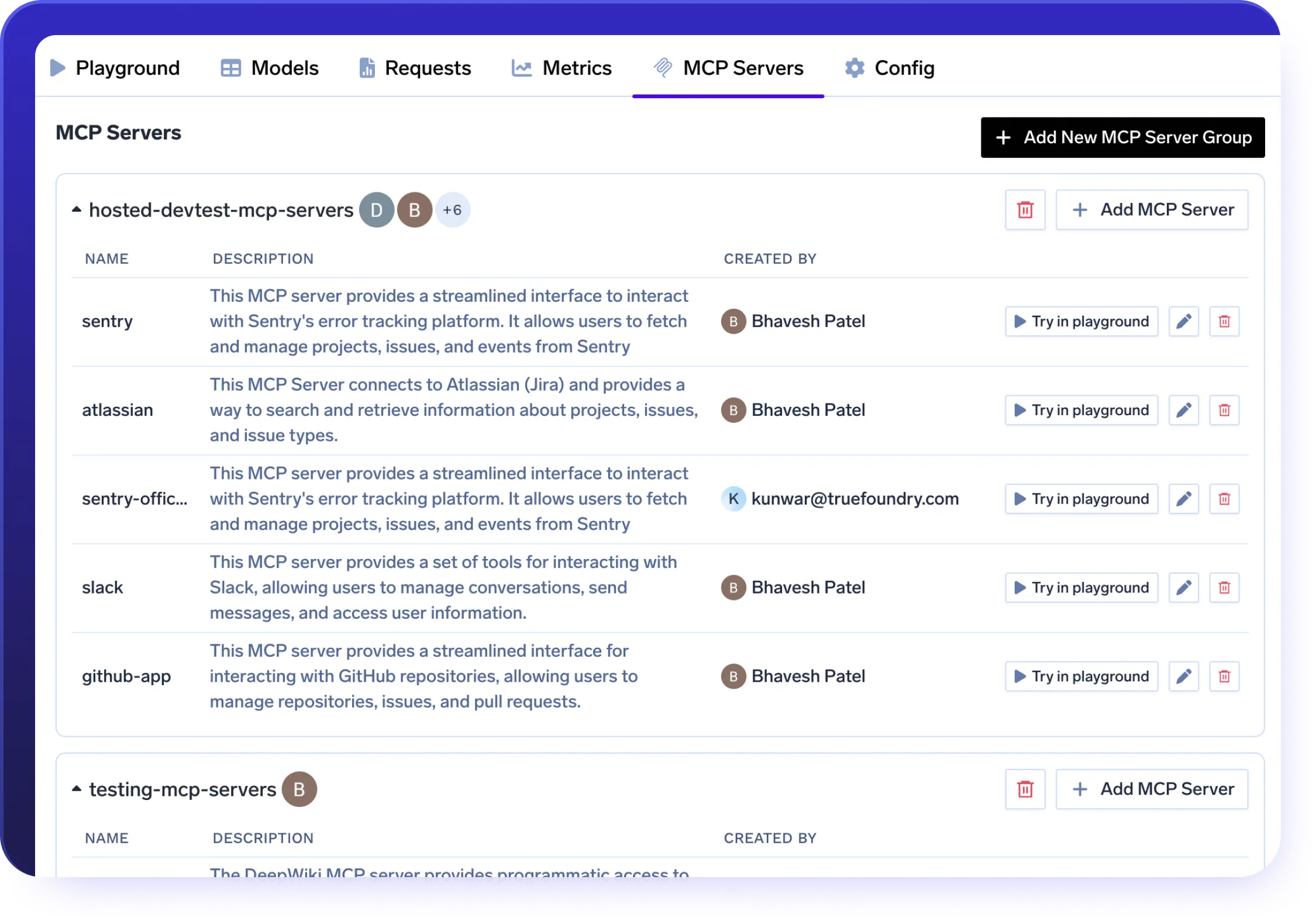
Intégration d'AI Gateway et de MCP
Optimisez les flux de travail des agents grâce à la prise en charge MCP native d'AI Gateway.
- Connectez des outils d'entreprise tels que Slack, GitHub, Confluence et Datadog.
- Enregistrez facilement les serveurs MCP internes avec une configuration minimale requise.
- Appliquez les politiques OAuth2, RBAC et de métadonnées à chaque appel d'outil.
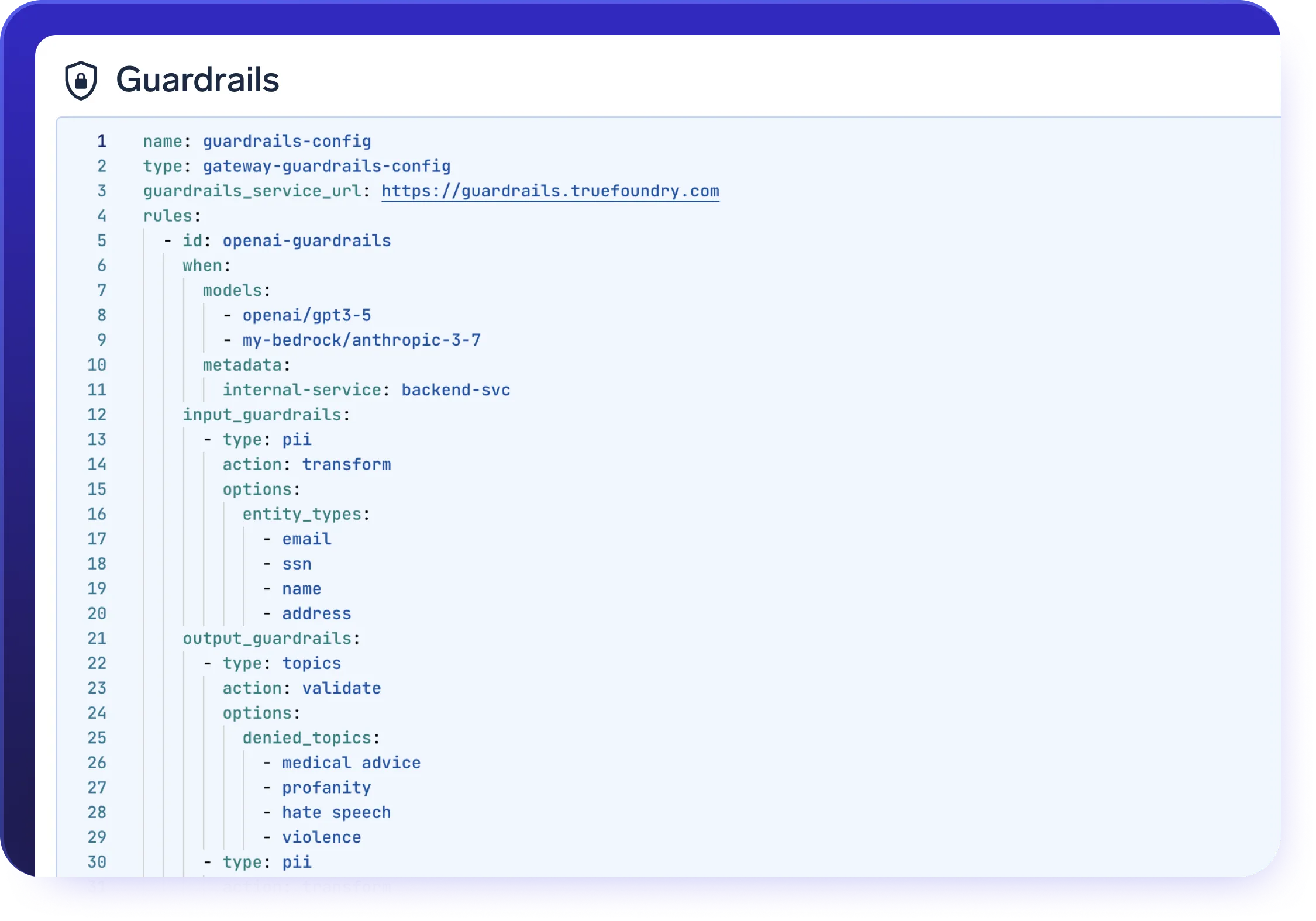
Garde-corps AI Gateway
Build secure AI applications with configurable AI gateway guardrails and policy controls.
- Appliquez facilement vos propres dispositifs de sécurité, y compris le filtrage des informations personnelles et la détection de la toxicité
- Personnalisez l'AI Gateway avec des garde-corps adaptés à vos besoins en matière de conformité et de sécurité
Prêt pour les entreprises
Déployez une passerelle IA sécurisée qui maintient vos données et modèles au sein de votre infrastructure cloud / sur site.


Conformité et sécurité
Normes SOC 2, HIPAA et GDPR pour garantir une protection robuste des donnéesGouvernance et contrôle d'accès
SSO + Contrôle d'accès basé sur les rôles (RBAC) et journalisation des auditsSupport et fiabilité pour les entreprises
Assistance 24 h/24 et 7 j/7 avec support SLA SLA de réponse
VPC, sur site, en espace isolé ou sur plusieurs clouds.
Aucune donnée ne quitte votre domaine. Profitez d'une souveraineté totale, d'un isolement et d'une conformité de niveau professionnel partout où TrueFoundry fonctionne
Des résultats concrets chez TrueFoundry
Pourquoi les entreprises choisissent TrueFoundry





.webp)
.webp)
.webp)
Frequently asked questions
Qu'est-ce qu'une passerelle IA ?
Comment fonctionne une passerelle IA ?
Quels sont les avantages d'une passerelle IA ?
Quelles sont les fonctionnalités des passerelles IA ?
Quelle passerelle IA est la meilleure ?
Quelle est la différence entre une passerelle API et une passerelle IA ?
Où se situe une passerelle IA dans l'architecture GenAI ?
Une passerelle IA peut-elle être utilisée avec des modèles auto-hébergés et open source ?
Comment une passerelle IA permet-elle de contrôler et d'optimiser les coûts d'inférence ?
Comment une passerelle IA contribue-t-elle à la confidentialité et à la conformité des données ?
Comment une passerelle IA peut-elle prendre en charge plusieurs équipes et environnements ?
Comment le TrueFoundry AI Gateway Playground aide-t-il les développeurs à créer et à tester ?
Une fois que vous êtes satisfait d'une configuration, l'intégralité de la configuration (invite, modèle, outils, garde-corps et schéma de sortie structuré) peut être enregistrée en tant que modèle réutilisable dans un référentiel partagé. Le Playground génère également des extraits de code prêts à l'emploi pour le client OpenAI, LangChain et d'autres bibliothèques, à l'aide de l'API unifiée AI Gateway, afin que les équipes puissent mener une expérience fonctionnelle et l'intégrer directement à leurs services avec un minimum d'effort.
Que signifie « accès unifié » pour les API, les clés, les outils et les agents ?
Pour les développeurs, cela se traduit par une intégration plus simple et un modèle de sécurité plus propre : les clés des fournisseurs sont stockées une fois dans la passerelle, l'accès est régi de manière centralisée à l'aide du RBAC et des politiques, et les équipes peuvent standardiser sur un modèle de client unique dans tous les langages et frameworks. À mesure que de nouveaux modèles ou fournisseurs apparaissent, ils peuvent être ajoutés à la passerelle et devenir immédiatement disponibles via la même interface unifiée.
Comment la gestion rapide, la gestion des versions et les applications d'agent fonctionnent-elles ensemble ?
Lorsqu'une configuration particulière est prête à être partagée plus largement, elle peut être publiée en tant qu'application d'agent. Les applications d'agent sont alimentées par la passerelle mais sont exposées via une interface simple et verrouillée : les utilisateurs professionnels ou les équipes internes peuvent interagir avec l'agent exactement comme il s'exécutera en production, tandis que les instructions, outils et barrières sous-jacents restent immuables. Les applications d'agent sont donc idéales pour les tests d'acceptation par les utilisateurs, les démonstrations avec les parties prenantes et les copilotes internes, car les équipes chargées des produits et des plateformes conservent le contrôle de la configuration tout en offrant aux autres un moyen sûr d'essayer les flux de travail des agences.
Comment fonctionnent les garde-corps, les contrôles de sécurité et les contrôles PII de bout en bout ?
La passerelle peut se connecter à des services de sécurité et de conformité existants tels que OpenAI Moderation, AWS Guardrails, Azure Content Safety et Azure PII detection, et elle prend également en charge les règles personnalisées écrites sous forme de configuration ou de code Python. Les barrières étant configurées de manière centralisée et appliquées de manière cohérente dans tous les modèles et applications passant par AI Gateway, les équipes chargées de la sécurité et de la conformité disposent d'un moyen prévisible d'appliquer les politiques organisationnelles relatives à l'utilisation de GenAI, y compris dans les environnements réglementés tels que la santé, les services financiers et les assurances.
Quelles sont les fonctionnalités d'observabilité, de traçage et de débogage fournies par AI Gateway ?
Pour un débogage plus approfondi, il existe une vue au niveau des requêtes qui vous permet d'inspecter les appels individuels, de voir l'invite et la réponse complètes et de comprendre comment le routage, les solutions de secours et les garde-fous ont été appliqués. Pour les flux de travail des agences utilisant des outils et un MCP, la passerelle peut capturer des traces indiquant chaque étape franchie par un agent, les outils qu'il a appelés et la manière dont les résultats intermédiaires ont circulé dans le système. Tous ces journaux et mesures sont également exposés via des API, afin que les équipes chargées de la plateforme et de l'observabilité puissent créer des tableaux de bord et des alertes personnalisés dans leurs piles de surveillance existantes.
Comment les politiques, les limites tarifaires, les solutions de repli et les budgets sont-ils configurés et automatisés ?
Tous ces contrôles peuvent être gérés via l'interface utilisateur ou déclarés en YAML et appliqués via la CLI TrueFoundry, permettant ainsi un flux de travail GitOps où la configuration de la passerelle côtoie le code de l'application et les définitions d'infrastructure. Combinées à la mise en cache, au traitement par lots et à la gestion centralisée des clés d'API, ces fonctionnalités permettent aux équipes de la plateforme de traiter AI Gateway comme l'endroit unique où elles définissent comment GenAI doit être utilisé, combien peuvent être dépensées et comment les applications doivent se comporter en cas de défaillance, sans obliger les équipes d'applications individuelles à réimplémenter ces préoccupations à maintes reprises.

GenAI infra- simple, plus rapide et moins cher
Plus de 10 entreprises du Fortune 500 nous font confiance








