












LLMops pour le service de modèles et l'inférence
.webp)
- Déployez n'importe LLM open source au sein de votre pipeline LLMops à l'aide de configurations préconfigurées et optimisées en termes de performances
- S'intègre parfaitement à Hugging Face, registres privés, ou n'importe quel hub de modèles, entièrement géré au sein de votre plateforme LLMops
- Tirez parti de modèles de serveurs de pointe tels que VllM et SG Lang pour une inférence à faible latence et à haut débit
- Activer Mise à l'échelle automatique du GPU, arrêt automatique et provisionnement intelligent des ressources sur l'ensemble de votre infrastructure LLMops.
.webp)
Servez n'importe quel LLM avec modèles de serveurs hautes performances tels que vLLM et SGlang, alimentés par la mise à l'échelle automatique du GPU et une infrastructure LLMOPs rentable.
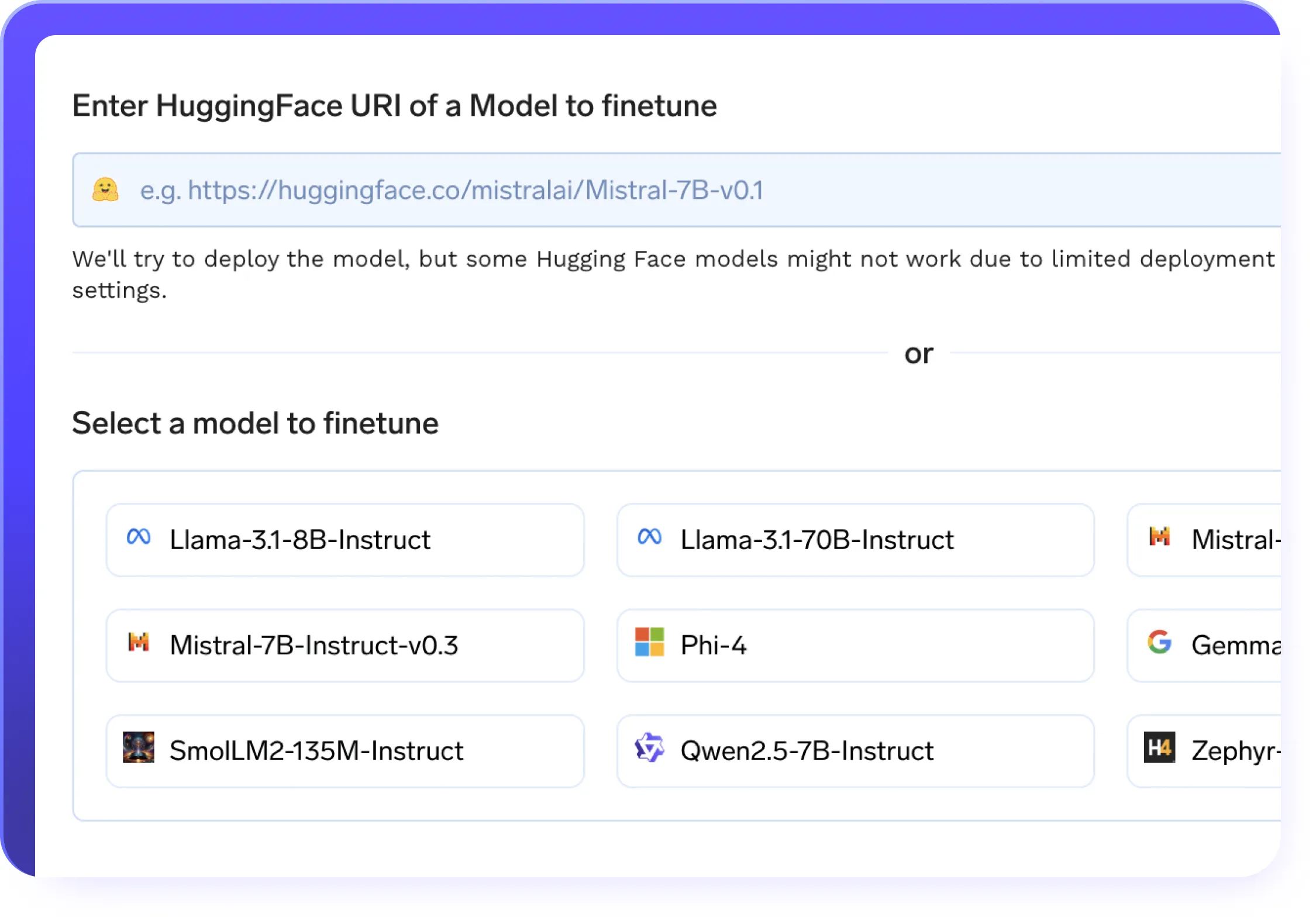
Réglage fin efficace
- Prise en charge de l'ajustement sans code et en code complet sur les ensembles de données personnalisés
- LoRa et QLoRa pour une adaptation efficace à un rang inférieur
- Reprenez la formation en toute simplicité avec pointage de contrôle assistance sur l'ensemble de vos pipelines LLMops
- En un clic déploiement de modèles affinés avec les meilleurs modèles de serveurs de leur catégorie
- Canalisations de formation automatisées avec intégration suivi des expériences intégré à vos flux de travail LLMops
- Support de formation distribué pour une optimisation plus rapide et à grande échelle des modèles
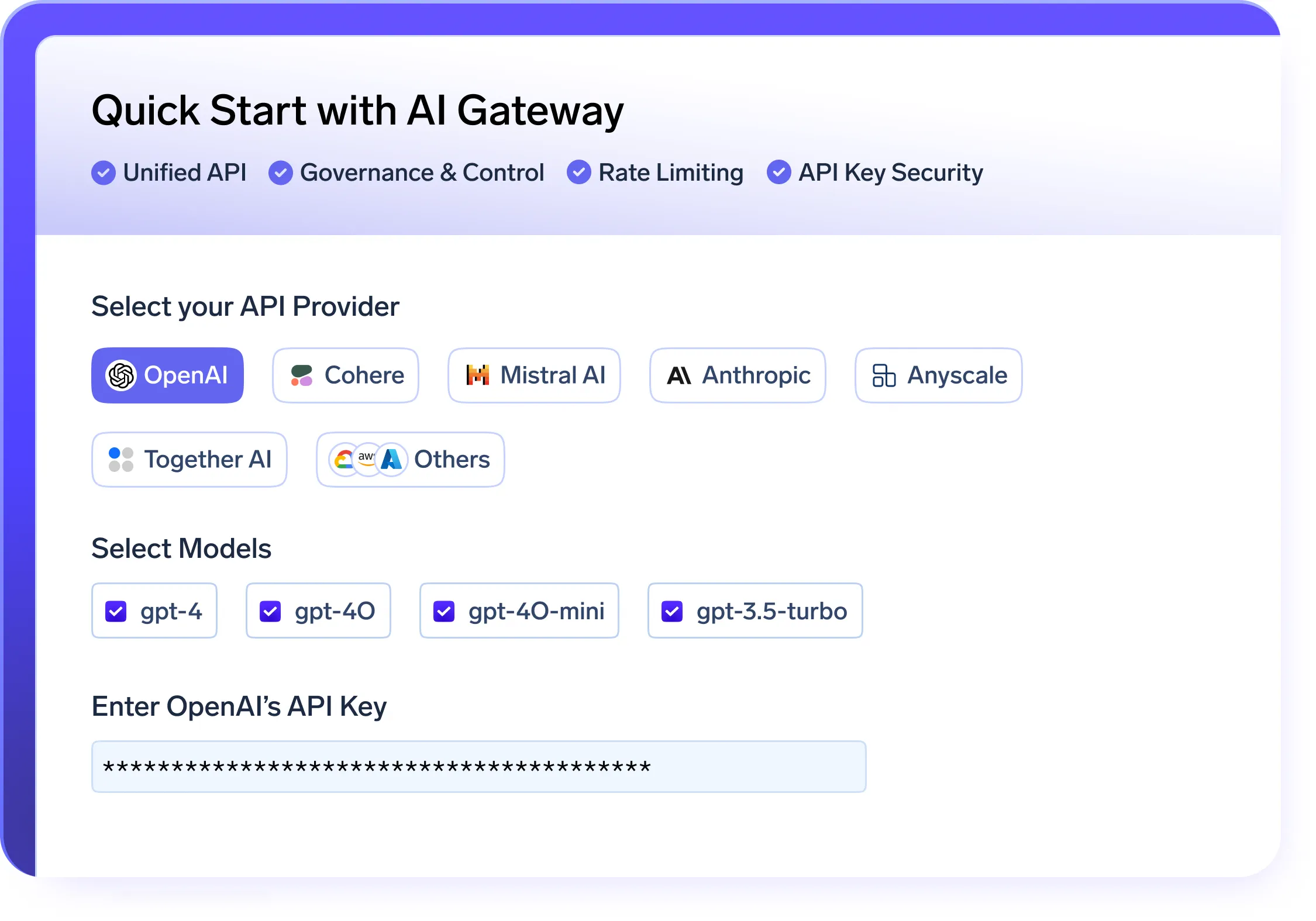
Gérez l'utilisation de l'IA grâce à une passerelle IA qui unifie l'accès aux modèles, applique les quotas et garantit l'observabilité et la sécurité.
Passerelle IA sécurisée et évolutive
- UNE API unifiée couche pour servir et gérer les modèles via OpenAI, LLama, Gemini et d'autres fournisseurs
- Intégré gestion des quotas et un contrôle d'accès pour appliquer une utilisation sécurisée et régulée des modèles au sein de votre plateforme LLMops
- Statistiques en temps réel pour l'utilisation, le coût et les performances afin d'améliorer l'observabilité du LLMOP
- Intelligent repli et nouvelles tentatives automatiques pour garantir la fiabilité de vos pipelines LLMops
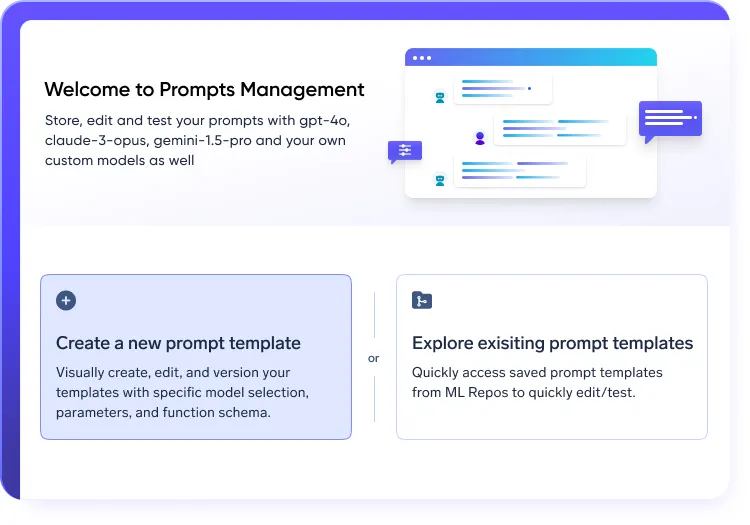
Flux de travail rapides structurés dans la pile LLMops
- Expérimentez et itérez en utilisant invite contrôlée par version ingénierie
- Courez Tests A/B sur tous les modèles pour optimiser les performances
- Maintenez une traçabilité complète des modifications rapides au sein de votre plateforme LLMops
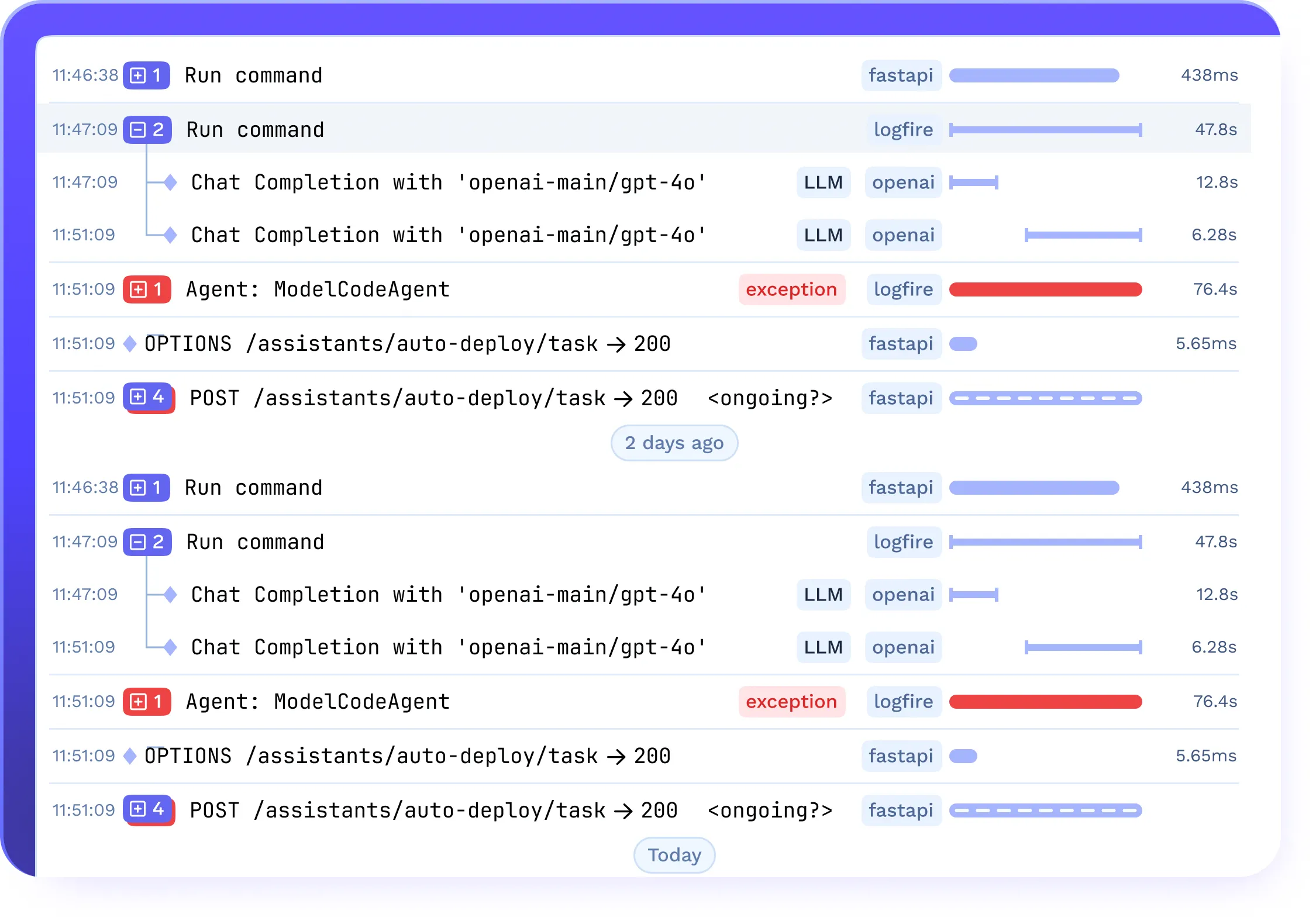
Traçage et garde-corps pour les flux de travail LLMops
- Capturez traces complètes des invites, des réponses, de l'utilisation des jetons et de la latence
- Surveillez les performances, les taux d'achèvement et les anomalies
- Intégrez avec garde-corps pour la détection des informations personnelles et la modération du contenu dans les pipelines LLMOPS
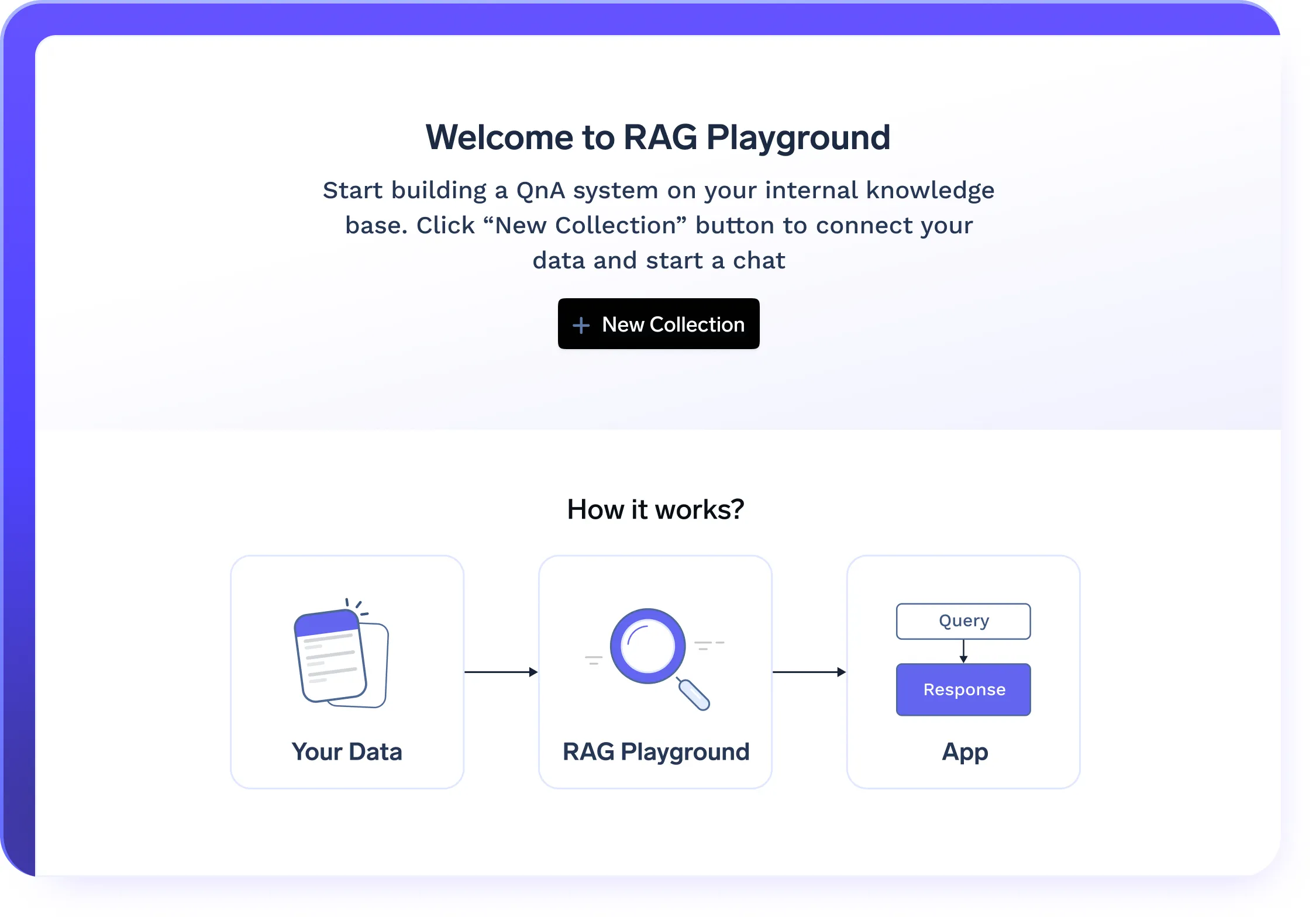
Déploiement de RAG en un clic
- Déploie tous les composants RAG en un seul clic, y compris VectorDB, les modèles d'intégration, le frontend et le backend
- Infrastructure configurable pour optimiser le stockage, la récupération et le traitement des requêtes
- Gérez des bases de documents de plus en plus nombreuses grâce à l'évolutivité LLMOPs native du cloud
Gérez le cycle de vie des agents - du déploiement à l'observabilité, quel que soit le cadre, alimenté par votre plateforme LLMops.
LLMops pour la gestion du cycle de vie des agents d'IA
- Exécutez et faites évoluer des agents sur n'importe quel framework à l'aide de votre infrastructure LLMops
- Support pour LangChain, AutoGen, CrewAI et les agents personnalisés
- Orchestration des agents indépendante du framework avec surveillance LLMOPs intégrée
- Prise en charge de l'orchestration multi-agents, permettant aux agents d'interagir, de partager le contexte et d'exécuter des tâches de manière autonome
.webp)
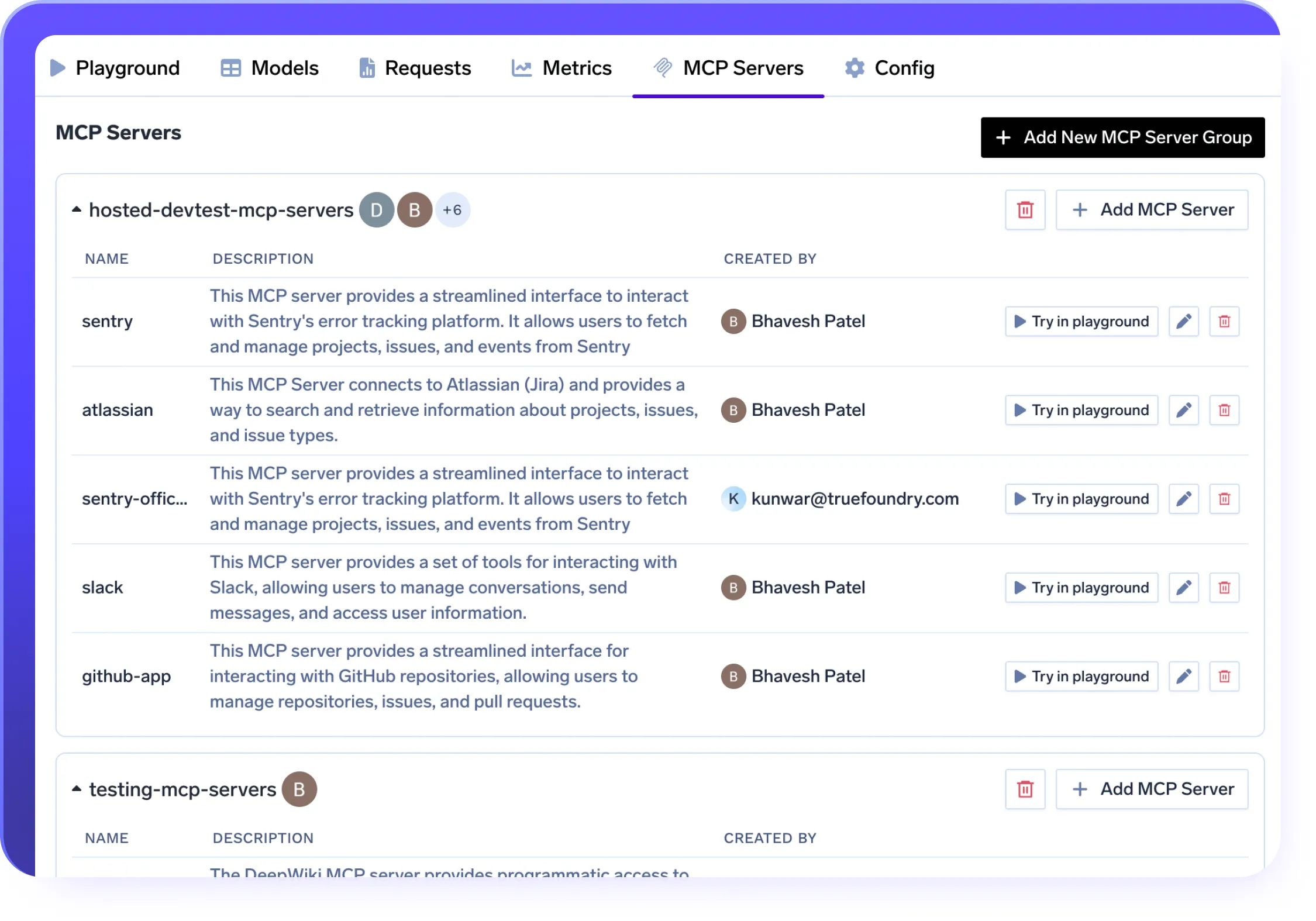
Intégration du serveur MCP dans votre stack LLMops
- Connectez en toute sécurité les LLM à des outils tels que Slack, GitHub et Confluence à l'aide du protocole MCP
- Déployez des serveurs MCP dans des configurations VPC, sur site ou isolées avec un contrôle total des données
- Permettez une utilisation native et rapide des outils sans wrappers, entièrement intégrés à votre stack LLMops
- Gérez l'accès avec RBAC, OAuth2 et suivez chaque appel grâce à l'observabilité intégrée
Prêt pour les entreprises
Déployez une passerelle IA sécurisée qui maintient vos données et modèles au sein de votre infrastructure cloud / sur site.


Conformité et sécurité
Normes SOC 2, HIPAA et GDPR pour garantir une protection robuste des donnéesGouvernance et contrôle d'accès
SSO + Contrôle d'accès basé sur les rôles (RBAC) et journalisation des auditsSupport et fiabilité pour les entreprises
Assistance 24 h/24 et 7 j/7 avec support SLA SLA de réponse
Déployez TrueFoundry dans n'importe quel environnement
VPC, sur site, en espace isolé ou sur plusieurs clouds.
Aucune donnée ne quitte votre domaine. Profitez d'une souveraineté totale, isolation et conformité de niveau professionnel, où que vous soyez TrueFoundry fonctionne
Questions fréquemment posées
Qu'est-ce que LLMops et pourquoi est-ce important ?
LLMops (Large Language Model Operations) fait référence à la pratique consistant à gérer l'intégralité de
cycle de vie des grands modèles de langage, de la formation et de la mise au point au déploiement, à l'inférence,
le suivi et la gouvernance. LLMops aide les organisations à intégrer les applications GenAI dans
production fiable et à grande échelle. TrueFoundry fournit une plateforme LLMOPS de qualité industrielle
qui simplifie et accélère l'ensemble de ce processus.
cycle de vie des grands modèles de langage, de la formation et de la mise au point au déploiement, à l'inférence,
le suivi et la gouvernance. LLMops aide les organisations à intégrer les applications GenAI dans
production fiable et à grande échelle. TrueFoundry fournit une plateforme LLMOPS de qualité industrielle
qui simplifie et accélère l'ensemble de ce processus.
En quoi le LLMops est-il différent du MLOP traditionnel ?
Alors que MLOps prend en charge une large gamme de modèles de machine learning, LLmops est spécialement conçu pour GenAI et
modèles de langage de grande taille. Il inclut des fonctionnalités telles que l'orchestration de serveurs modèles, le prompt
gestion, observabilité au niveau des jetons, frameworks d'agents et accès sécurisé aux API.
La plateforme LLMOPS de TrueFoundry gère ces flux de travail spécifiques à GENAI de manière native, contrairement à
outils MLOps génériques.
modèles de langage de grande taille. Il inclut des fonctionnalités telles que l'orchestration de serveurs modèles, le prompt
gestion, observabilité au niveau des jetons, frameworks d'agents et accès sécurisé aux API.
La plateforme LLMOPS de TrueFoundry gère ces flux de travail spécifiques à GENAI de manière native, contrairement à
outils MLOps génériques.
Pourquoi investir dans une plateforme LLMops dédiée comme TrueFoundry ?
Une plateforme LLMops dédiée élimine le besoin d'associer des outils d'infrastructure, de suivi et d'évaluation. TrueFoundry permet un déploiement sécurisé, une expérimentation rapide, une observabilité et une optimisation des coûts sur une seule plateforme. Cela permet aux équipes de passer plus rapidement du prototype à la production tout en préservant la gouvernance et la fiabilité de l'entreprise.
Quelles sont les principales fonctionnalités de la plateforme LLMops de TrueFoundry ?
La plateforme LLMOPS de TrueFoundry intègre le contrôle de version, des tests B et un réglage rapide pour chaque modèle de base. Les composants clés des LLMOP incluent le réglage automatique des hyperparamètres et la surveillance de la qualité des données. Ces fonctionnalités prennent en charge les applications d'IA complexes en optimisant les ressources de calcul et en garantissant des performances LLM cohérentes sur tous les ensembles de données.
Puis-je déployer la plateforme LLMOPS de TrueFoundry sur mon infrastructure ?
Oui TrueFoundry prend en charge le déploiement dans votre VPC, votre cloud privé ou votre environnement sur site. Cela garantit un contrôle total des données sensibles, la conformité aux politiques de sécurité internes et une intégration fluide avec l'infrastructure existante tout en maintenant une évolutivité et des performances de niveau entreprise.
Comment LLMops améliore-t-il l'observabilité et le débogage ?
Cette plateforme LLMops améliore les performances des modèles grâce à des mesures de performance et à une analyse des données en temps réel. Les ingénieurs utilisent l'évaluation sommaire et les mesures de doublure d'évaluation bilingues pour déboguer les modèles de machine learning. En suivant les commentaires humains et les opérations des modèles, vous bénéficiez d'une visibilité approfondie sur le comportement de l'intelligence artificielle dans les environnements de production en direct.
La plateforme LLMOPS de TrueFoundry est-elle sécurisée et conforme ?
Notre plateforme LLMops d'entreprise donne la priorité à la sécurité de l'IA d'entreprise grâce à la conformité RBAC et SOC 2. Nous garantissons la qualité des données et protégeons les données sensibles grâce à l'isolation multi-tenant. En intégrant une intégration continue et des protocoles stricts de préparation des données, la plateforme maintient un environnement sécurisé pour le déploiement de tout modèle de langage de grande envergure.
Quels modèles et frameworks sont pris en charge par la plateforme LLMOPS de TrueFoundry ?
La plateforme LLMops de TrueFoundry prend en charge des modèles de langage tels que Mistral et LLama, ainsi que des modèles ML traditionnels. Il est indépendant du framework et s'intègre aux transformateurs Hugging Face et aux outils de science des données. Que vous utilisiez un modèle de base ou des systèmes d'IA personnalisés, notre plateforme facilite le déploiement et la mise à l'échelle fluides des modèles.
Puis-je utiliser la plateforme LLMops de TrueFoundry pour gérer plusieurs équipes et projets ?
Oui, la plateforme LLMOPS d'entreprise de TrueFoundry est conçue pour la multilocation, permettant aux équipes d'ingénierie des données de gérer des projets distincts. Vous pouvez surveiller les ressources informatiques, suivre les coûts et organiser la collecte de données pour des tâches spécifiques. Cette structure améliore l'expérience utilisateur des grandes entreprises qui étendent leurs initiatives génératives en matière d'IA et de science des données.
À quelle vitesse puis-je commencer à utiliser TrueFoundry pour LLMOPS ?
Vous pouvez lancer notre plateforme LLMops en quelques minutes à l'aide de modèles d'invite prédéfinis et de flux de travail de développement d'IA. La plateforme accélère la préparation des données et l'automatisation du support client. Grâce à l'automatisation des opérations de modélisation, votre équipe peut passer rapidement de la collecte initiale des données à des environnements de production performants avec un minimum de friction.

GenAI infra- simple, plus rapide et moins cher
Plus de 30 entreprises et sociétés du Fortune 500 nous font confiance








