













Plus de 1000 marques mondiales nous font confiance
Servez n'importe quel modèle, n'importe quel framework
IA générative
Diffusez n'importe quel modèle Hugging Face sous forme de texte, d'image, de contenu multimodal et audio, avec une prise en charge complète des terminaux compatibles OpenAI
ML traditionnel
Déployez et redimensionnez sans effort des modèles conçus avec XGBoost, scikit-learn et LightGBM pour des prévisions fiables et performantes.
Apprentissage profond
Exécutez des modèles prêts à la production développés à l'aide de PyTorch, TensorFlow ou Keras, optimisés en termes de vitesse, d'évolutivité et de stabilité.
Conteneurs personnalisés
Déployez des pipelines d'inférence entièrement personnalisés à l'aide de vos propres conteneurs Docker pour un contrôle complet de l'exécution et des dépendances.
CHIFFON
Déployez des modèles intégrés, des reclassement et des bases de données vectorielles pour créer des applications d'IA précises et contextuelles.
Modèles de vision
Déployez et adaptez facilement n'importe quel modèle de vision par ordinateur, de la classification des images à la compréhension visuelle avancée.

Exécutez n'importe où : dans le cloud, sur site ou en périphérie
- Déploiements basés sur Kubernetes entièrement natifs du cloud
- Déployez sur AWS, GCP, Azure, sur site, ou au bord
Mise à l'échelle automatique sans effort sur les CPU/GPU
- Supporte les modèles gourmands en CPU et en GPU
- Mise à l'échelle à zéro ou mise à l'échelle automatique à la demande
.webp)

Accès sécurisé et contrôlé
- Contrôle d'accès affiné basé sur les rôles
- Authentification basée sur des jetons et sécurité des API
Inférence par lots et en streaming
- Diffusez des prévisions en temps réel via REST ou gRPC
- Planifier ou déclencher une inférence par lots
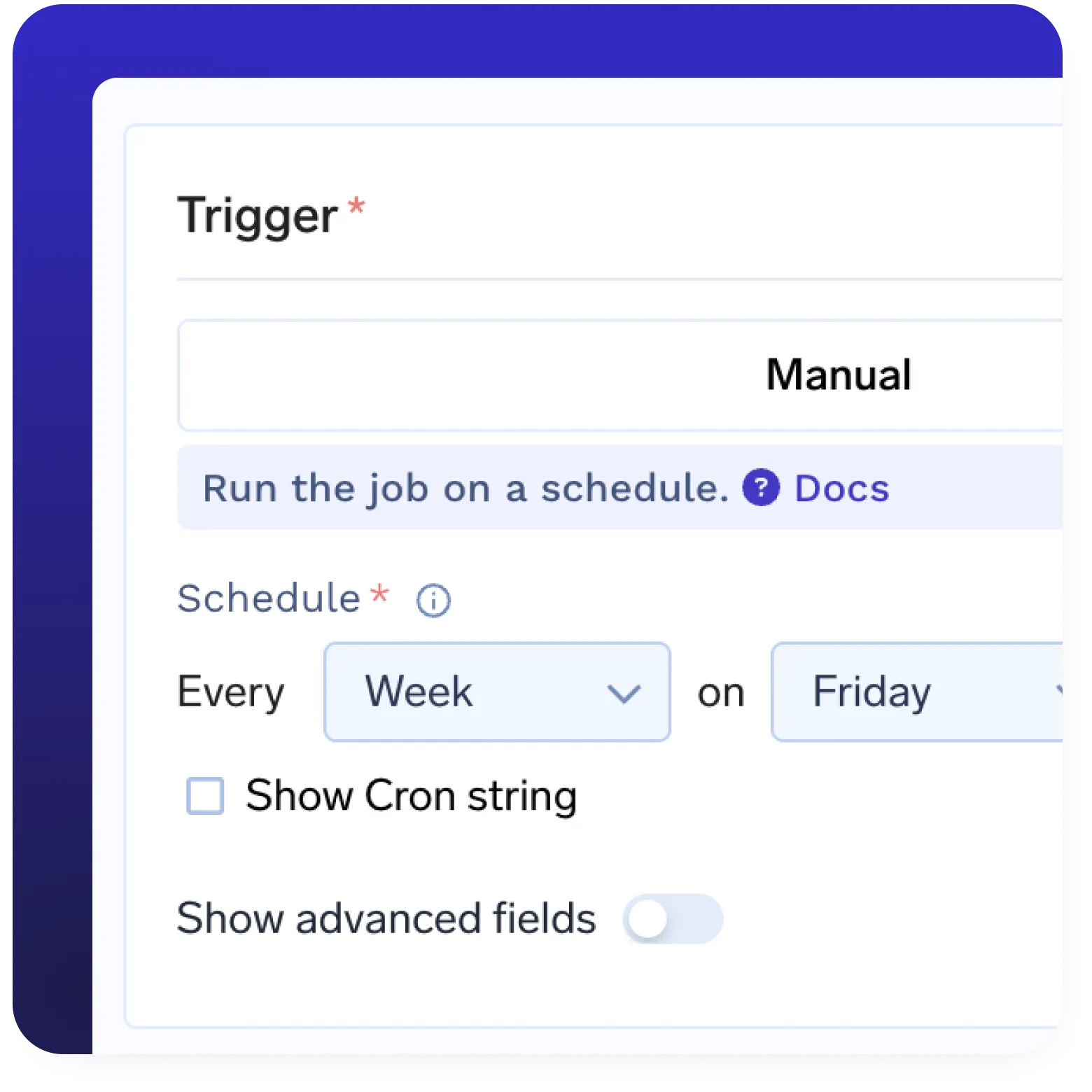

Registre de modèles intégré
- Registre de modèles complet intégré
- Déploiement automatique de modèles à partir du registre
- Gérer les versions et les métadonnées
Observabilité et surveillance complètes
- Support natif pour Prometheus, Grafana et OpenTelemetry
- Journaux, traces et mesures en temps réel
- Visibilité sur le déploiement, l'utilisation et l'état du système
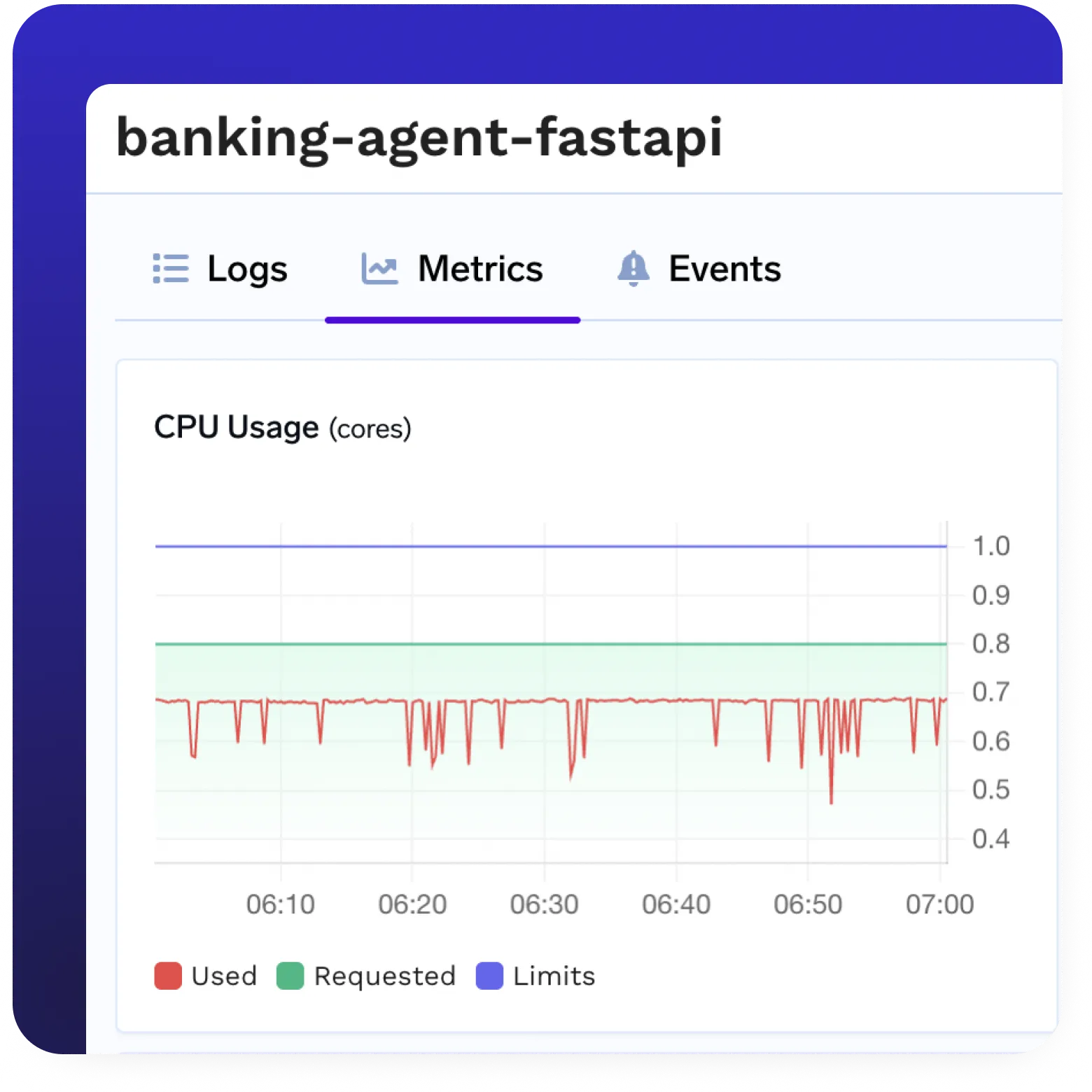

Une expérience de développeur agréable
- Interface utilisateur intuitive, SDK et CLI pour gérer, tester et surveiller vos modèles.
- Conception axée sur le développeur, du développement local à la production.
Rentable
- Optimisation intelligente de l'infra
- Utilisation efficace du GPU et prise en charge des instances ponctuelles
- Pas de dépendance vis-à-vis d'un fournisseur

Prêt pour les entreprises
Vos données et modèles sont hébergés en toute sécurité dans votre infrastructure cloud ou sur site.

Systèmes entièrement modulaires
S'intègre à votre stack existant et le complèteConformité véritable
Normes SOC 2, HIPAA et GDPR pour garantir une protection robuste des donnéesSécurisé dès la conception
Contrôle d'accès et pistes d'audit flexibles basés sur les rôlesAuthentification conforme aux normes du secteur
Intégration SSO via OIDC ou SAML

GenAI infra- simple, plus rapide et moins cher
Plus de 30 entreprises et sociétés du Fortune 500 nous font confiance
Témoignages TrueFoundry rend votre équipe ML 10 fois plus rapide
.webp)
Deepanshi S.
Scientifique des données en chef



Matthieu Perrinel
Responsable du ML


Soma Dhavala
Directeur de l'apprentissage automatique


Rajesh Chaganti
CTO


Summit Rao
Vice-président de la science des données


Vivek Suyambu
Ingénieur logiciel senior










