











LLM
Déployez et servez des LLM open source ou propriétaires avec une accélération GPU et une fiabilité de niveau production.
Agents
Exécutez des agents d'IA de longue durée avec de la mémoire, l'exécution d'outils et une intégration fluide avec les serveurs AI Gateway et MCP
Serveurs MCP
Déployez des serveurs MCP pour exposer en toute sécurité les outils, les API et les systèmes d'entreprise aux agents d'IA.
Workflows
Orchestrez des flux de travail d'IA en plusieurs étapes entre les modèles, les agents et les services à partir d'un plan de contrôle unique.
Offres d'emploi
Exécutez des tâches par lots, des charges de travail de formation et des tâches d'IA planifiées à la demande.
Modèles ML classiques
Déployez et diffusez des modèles d'apprentissage automatique traditionnels aux côtés des LLM en utilisant la même plateforme.
.webp)
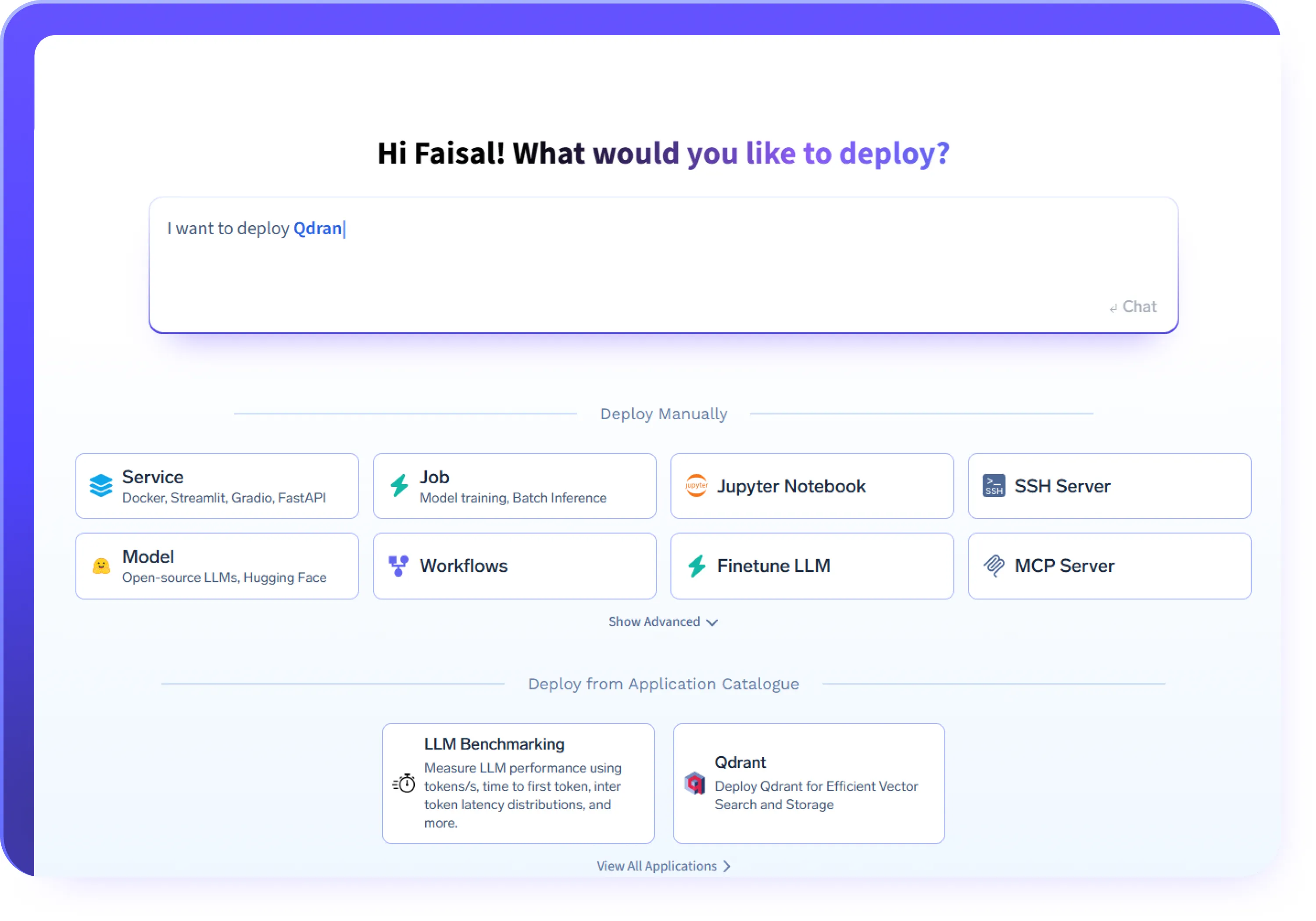
Déployez toute charge de travail d'IA
- Déployez des LLM et des charges de travail d'inférence basées sur des GPU à l'aide de frameworks tels que vLLM, Triton, KServe ou des conteneurs personnalisés
- Déployez des agents et des services d'agents IA avec une exécution et une mise en réseau cohérentes
- Déployez des serveurs MCP pour exposer en toute sécurité les outils et les systèmes internes
- Exécutez des tâches par lots, des API et des services d'IA de longue durée sur la même plateforme
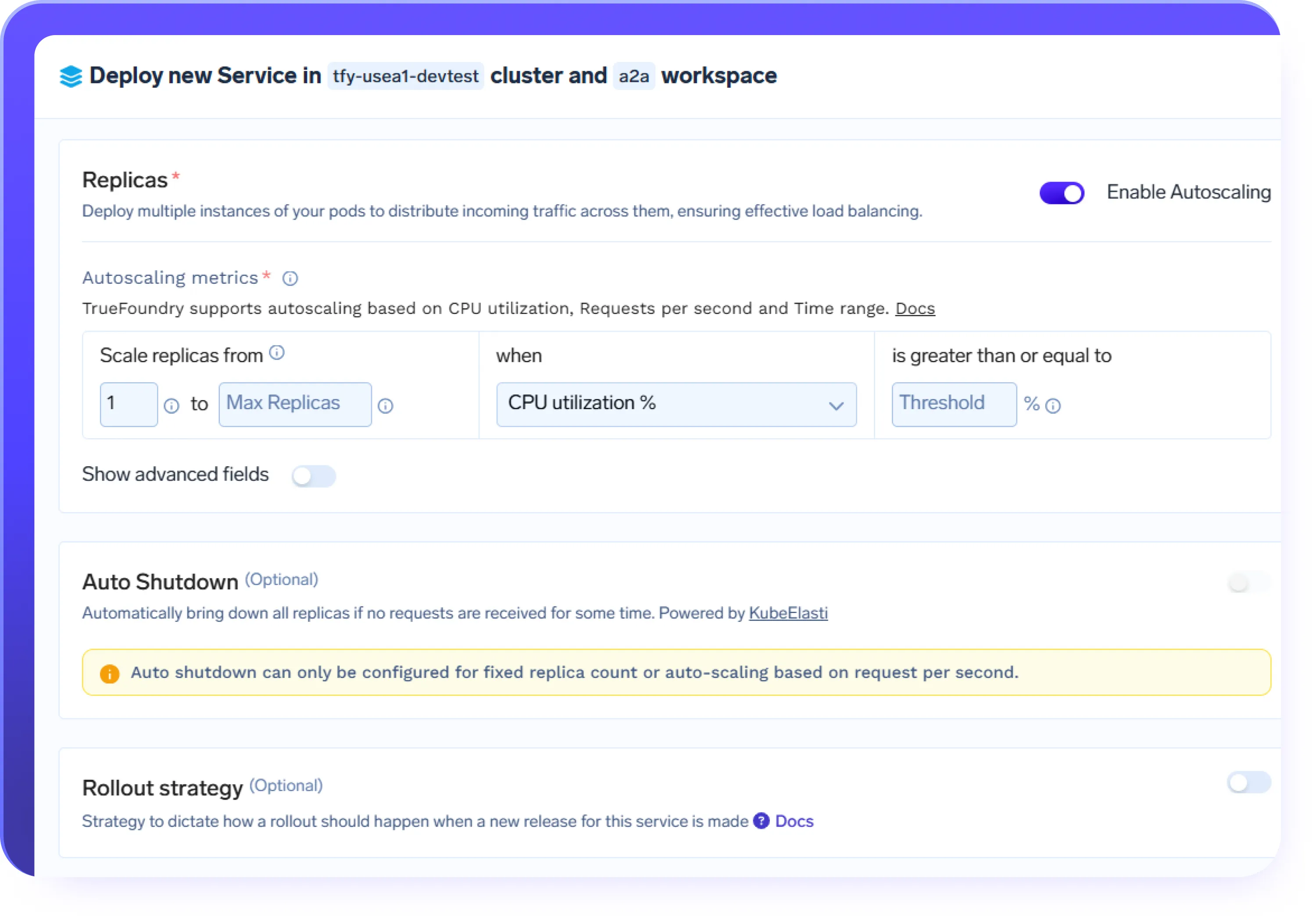
Mise à l'échelle automatique pour les charges de travail d'IA
demande.
- Adaptez automatiquement les terminaux d'inférence et les services des agents en fonction du volume de demandes
- Augmentez les charges de travail du GPU pendant les pics de demande et diminuez lorsque le trafic diminue
- Prenez en charge des charges de travail surchargées telles que le chat, le RAG et les flux de travail pilotés par des agents
- Maintenez des performances prévisibles pendant les pics de trafic
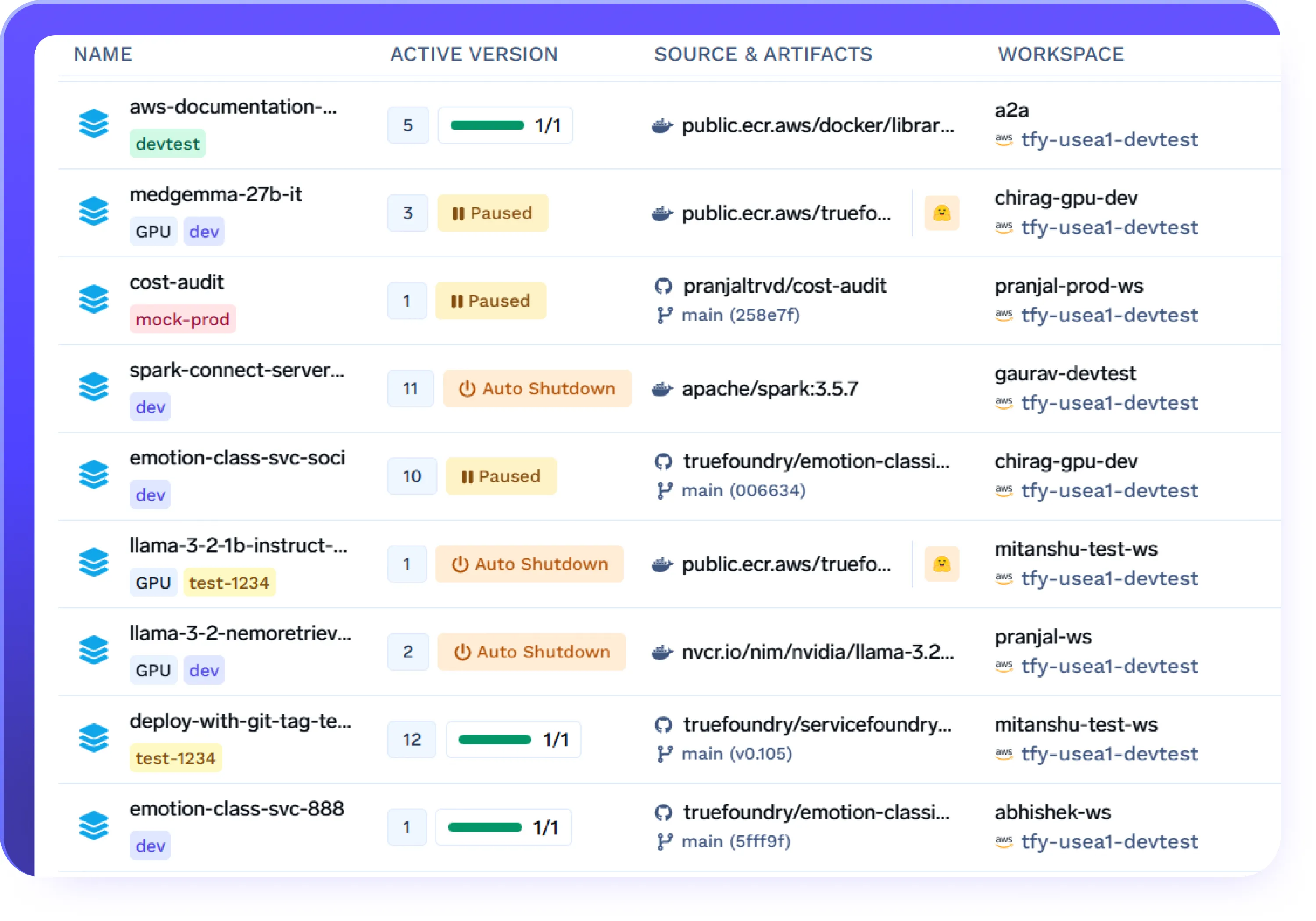
Arrêt automatique pour contrôler les coûts
- Arrêtez automatiquement les terminaux, les agents ou les services après des périodes d'inactivité configurables
- Réduisez le gaspillage de GPU pendant les heures creuses ou pendant les expériences
- Redémarrez les charges de travail à la demande sans intervention manuelle
- Appliquez la discipline des coûts à toutes les équipes et
environnements
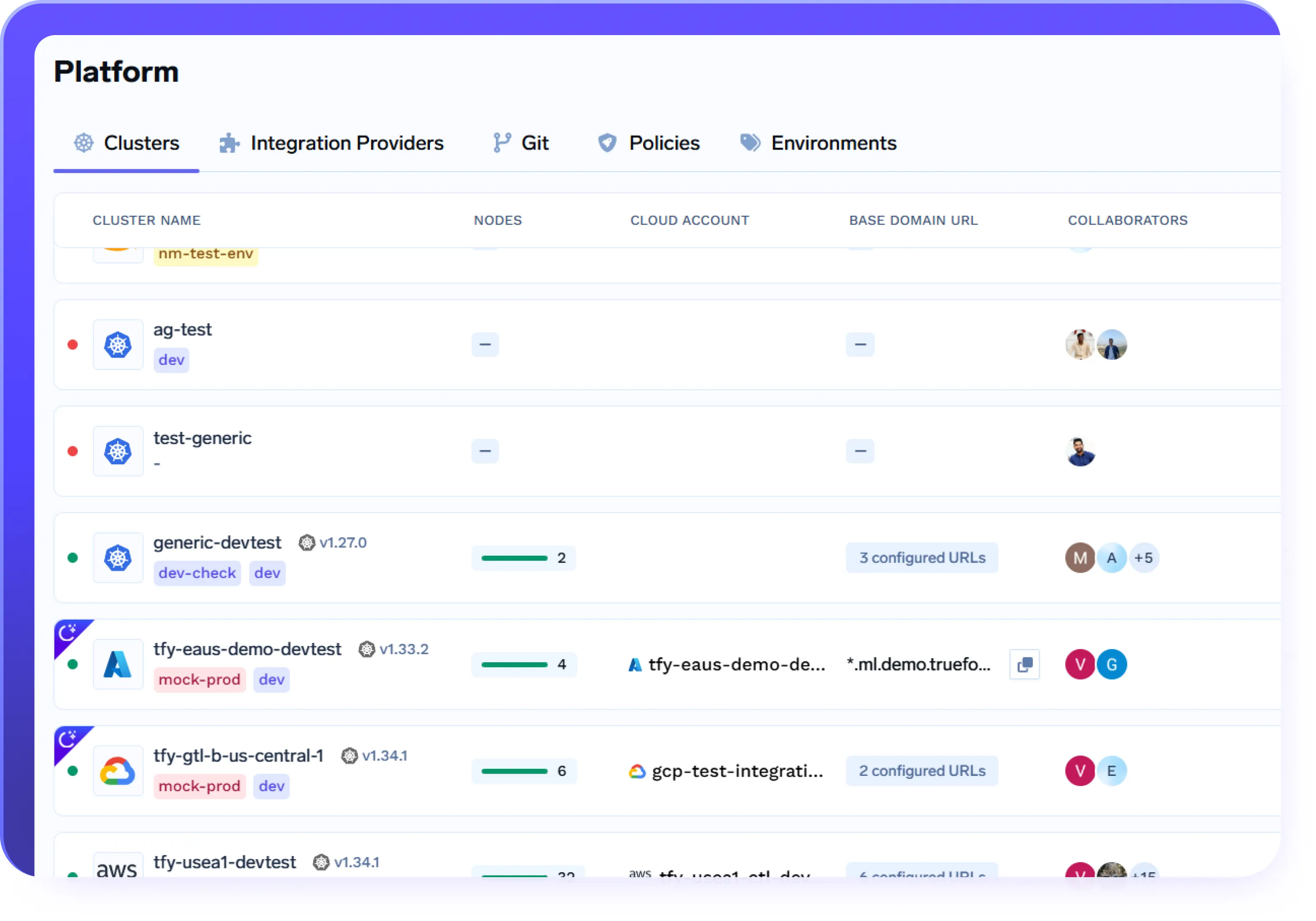
Expérience de déploiement unifiée dans le cloud et sur site
- Connectez et gérez AWS, Azure, GCP et des clusters sur site à partir d'un plan de contrôle unique
- Déployez la même charge de travail dans différents environnements à l'aide de flux de travail et d'API identiques
- Éliminez la complexité propre au cloud tout en conservant un contrôle et une isolation complets
- Profitez de la même expérience de déploiement pour le développement, le staging et la production, quelle que soit l'infrastructure
Conçu pour offrir une expérience de premier ordre aux développeurs
- Journaux, mesures et événements intégrés pour chaque déploiement
- Surveillance et alertes natives pour détecter et résoudre rapidement les problèmes
- Fonctionnalités de déploiement prêtes pour la production, telles que les bilans de santé et les stratégies de déploiement
- Gestion sécurisée des secrets et intégrations CI/CD fluides
Fonctionne parfaitement avec AI Gateway et Agent Gateway
au-dessus.
- AI Gateway régit l'accès aux modèles, le routage et le contrôle des coûts
- MCP Gateway régit l'accès aux outils et leur exécution
- Agent Gateway orchestre et gère les flux de travail des agents
- Les déploiements d'IA unifiés alimentent l'exécution et l'infrastructure réelles
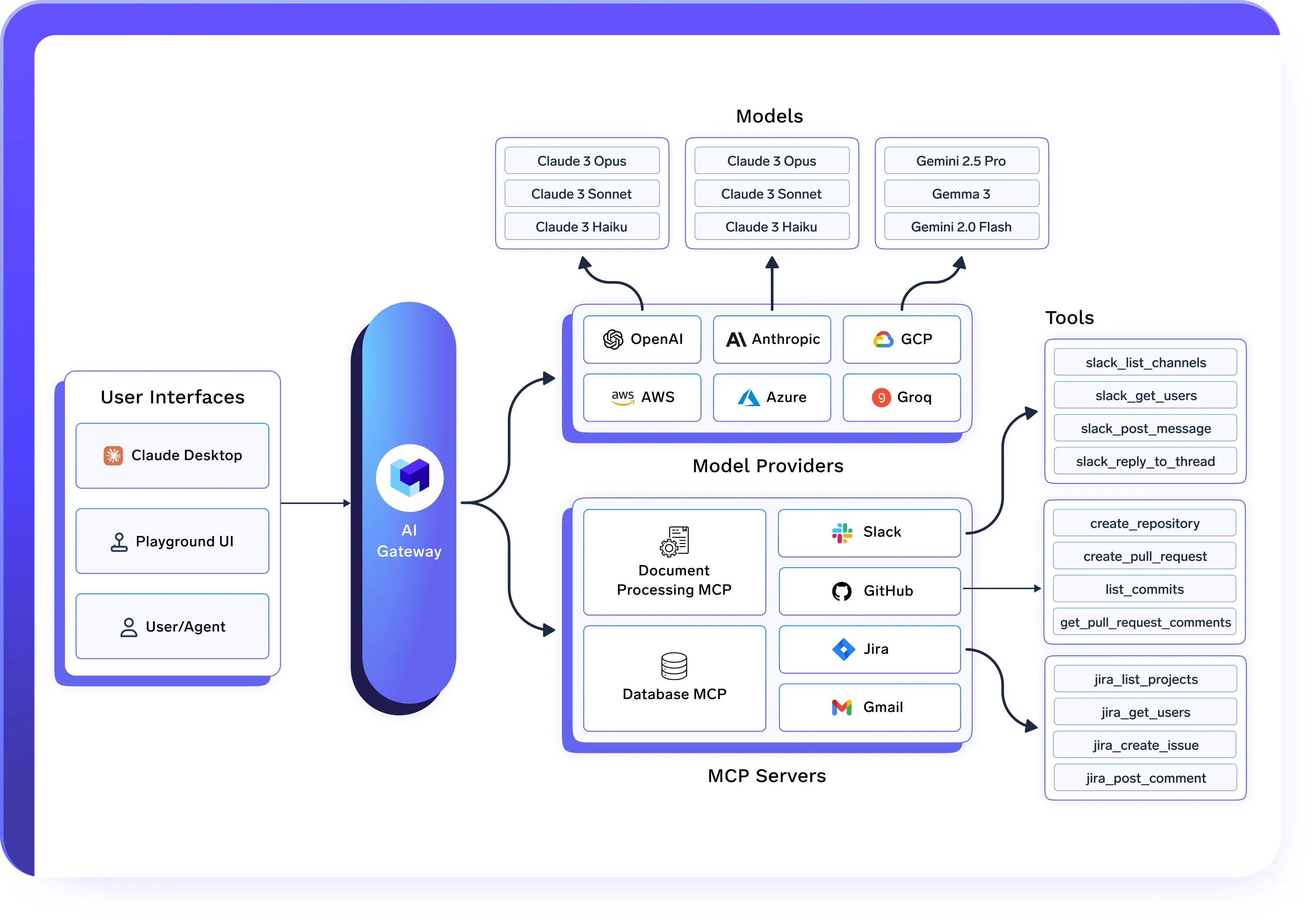
Conçu pour une IA à grande échelle dans le monde réel
Prêt pour les entreprises
Déployez une passerelle IA sécurisée qui maintient vos données et modèles au sein de votre infrastructure cloud / sur site.


Conformité et sécurité
Normes SOC 2, HIPAA et GDPR pour garantir une protection robuste des donnéesGouvernance et contrôle d'accès
SSO + Contrôle d'accès basé sur les rôles (RBAC) et journalisation des auditsSupport et fiabilité pour les entreprises
Assistance 24 h/24 et 7 j/7 avec support SLA SLA de réponse
VPC, sur site, en espace isolé ou sur plusieurs clouds.
Aucune donnée ne quitte votre domaine. Profitez d'une souveraineté totale, d'un isolement et d'une conformité de niveau professionnel partout où TrueFoundry fonctionne

Des résultats concrets chez TrueFoundry
Pourquoi les entreprises choisissent TrueFoundry






3 fois
rentabilisation plus rapide grâce à des agents LLM autonomes
80 %
utilisation accrue du cluster GPU après optimisation automatique des agents

Aaron Erickson
Fondateur d'Applied AI Lab
TrueFoundry a transformé notre parc de processeurs graphiques en un moteur autonome à optimisation automatique, ce qui nous a permis d'augmenter de 80 % le taux d'utilisation et d'économiser des millions de dollars en temps de calcul inactif.
5x
accélération de la mise en production de la plateforme interne d'IA/ML
50 %
réduire les dépenses liées au cloud après la migration des charges de travail vers TrueFoundry

Pratik Agrawal
Directeur principal de la science des données et de l'innovation en matière d'IA
TrueFoundry nous a aidés à passer de l'expérimentation à la production en un temps record. Ce qui aurait pris plus d'un an a été réalisé en quelques mois, avec une meilleure adoption par les développeurs.
80 %
réduction des délais de production des modèles
35 %
économies sur les coûts liés au cloud par rapport à la configuration précédente de SageMaker
.webp)
Vibhas Gejji
Ingénieur ML du personnel
Nous avons allégé la charge DevOps et simplifié les déploiements de production entre les équipes. TrueFoundry a accéléré la diffusion du machine learning grâce à une infrastructure qui s'adapte aussi bien aux expériences qu'à des services robustes.
50 %
déploiement plus rapide de la pile RAG/agent
60 %
réduction des frais de maintenance pour les pipelines RAG/agent
.webp)
Indronel G.
Leader intelligent des processus
TrueFoundry nous a aidés à déployer une pile RAG complète, y compris des pipelines, des bases de données vectorielles, des API et une interface utilisateur, deux fois plus rapidement, tout en contrôlant totalement l'infrastructure auto-hébergée.
60 %
des déploiements d'IA plus rapides
~ 40 à 50 %
Réduction efficace des coûts dans tous les environnements de développement
.webp)
Nilav Ghosh
Directeur principal, IA
Grâce à TrueFoundry, nous avons réduit les délais de déploiement de plus de moitié et réduit les frais d'infrastructure grâce à une interface MLOps unifiée, ce qui a accéléré la création de valeur.
<2
semaines pour migrer tous les modèles de production
75 %
réduction du temps de coordination de la science des données, accélération des mises à jour des modèles et du déploiement des fonctionnalités
.webp)
Rajat Bansal
CTO
Nous avons réalisé d'importantes économies sur les coûts d'infrastructure et avons réduit le temps de coordination du DS de 75 %. TrueFoundry a accéléré la vitesse de déploiement de nos modèles au sein des équipes.
Questions fréquemment posées
Quels types de charges de travail d'IA puis-je déployer avec les déploiements d'IA unifiés ?
Les déploiements d'IA unifiée prennent-ils en charge la mise à l'échelle automatique ?
Comment fonctionne l'arrêt automatique pour les charges de travail d'IA ?
Puis-je déployer des charges de travail basées sur l'IA dans mon propre environnement ?
Comment les déploiements d'IA unifiée s'intégrent-ils à AI Gateway ?

GenAI infra- simple, plus rapide et moins cher
Plus de 30 entreprises et sociétés du Fortune 500 nous font confiance








