












Passerelle d'intelligence artificielle et plateforme de déploiement agentic prêtes à l'emploi pour les entreprises : sécurisées, évolutives et gérées.
Cloud sur site, VPC, hybride ou public


Gérez, déployez, faites évoluer et suivez l'IA agentic sur une seule plateforme unifiée
.svg)
.avif)
Orchestrez l'IA agentique avec AI Gateway
Activez le raisonnement intelligent en plusieurs étapes, l'utilisation des outils et la mémoire avec un contrôle et une visibilité complets sur vos agents d'IA et vos flux de travail.
Passerelle IA
Gérez la mémoire des agents, l'orchestration des outils et la planification des actions grâce à un protocole centralisé qui prend en charge des flux de travail complexes et contextuels.

Registre des MCP et des agents
Tenez à jour un registre structuré et détectable d'outils et d'API accessibles aux agents, avec validation des schémas et contrôle d'accès.
.webp)
Gestion rapide du cycle de vie
Versionnez, gérez et surveillez les invites pour garantir un comportement reproductible et de haute qualité entre les agents et les cas d'utilisation.
.avif)
Déployez et faites évoluer n'importe quelle charge de travail d'IA agentic
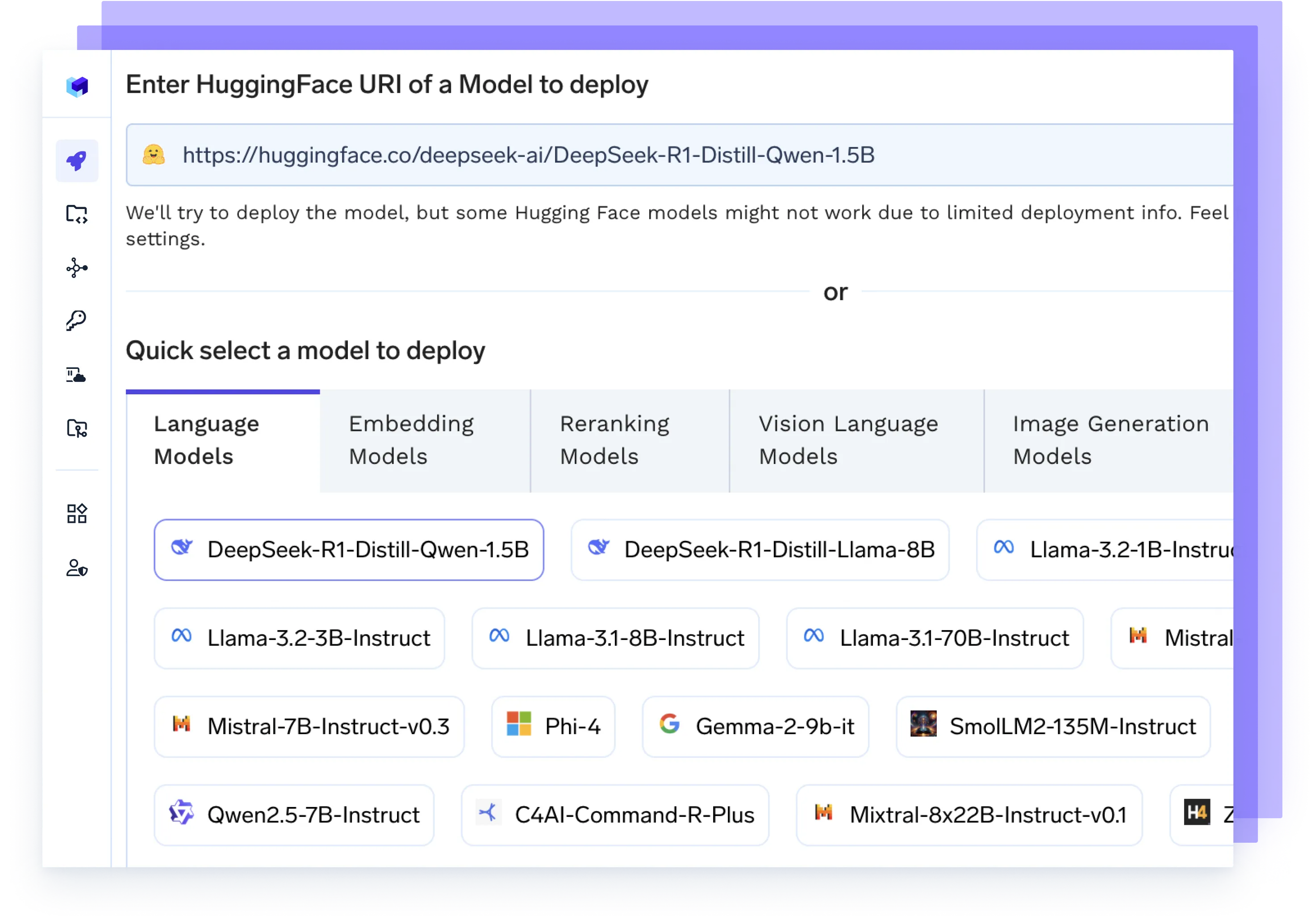
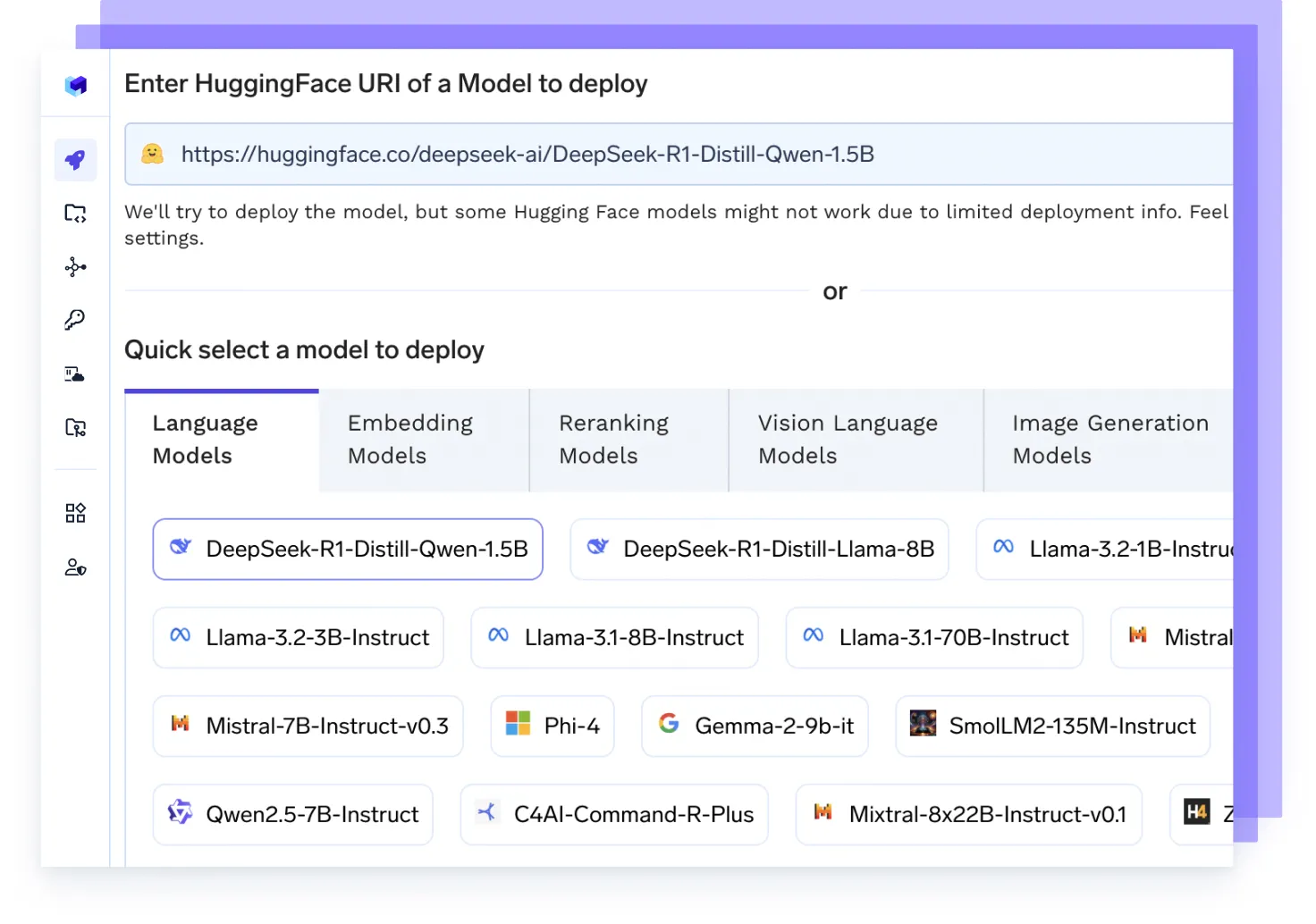
Hébergez n'importe quel modèle d'IA
Exécutez n'importe quel LLM, modèle d'intégration ou modèle personnalisé à l'aide de backends hautes performances tels que vLLM, TGI ou Triton, optimisés pour la vitesse et l'évolutivité.
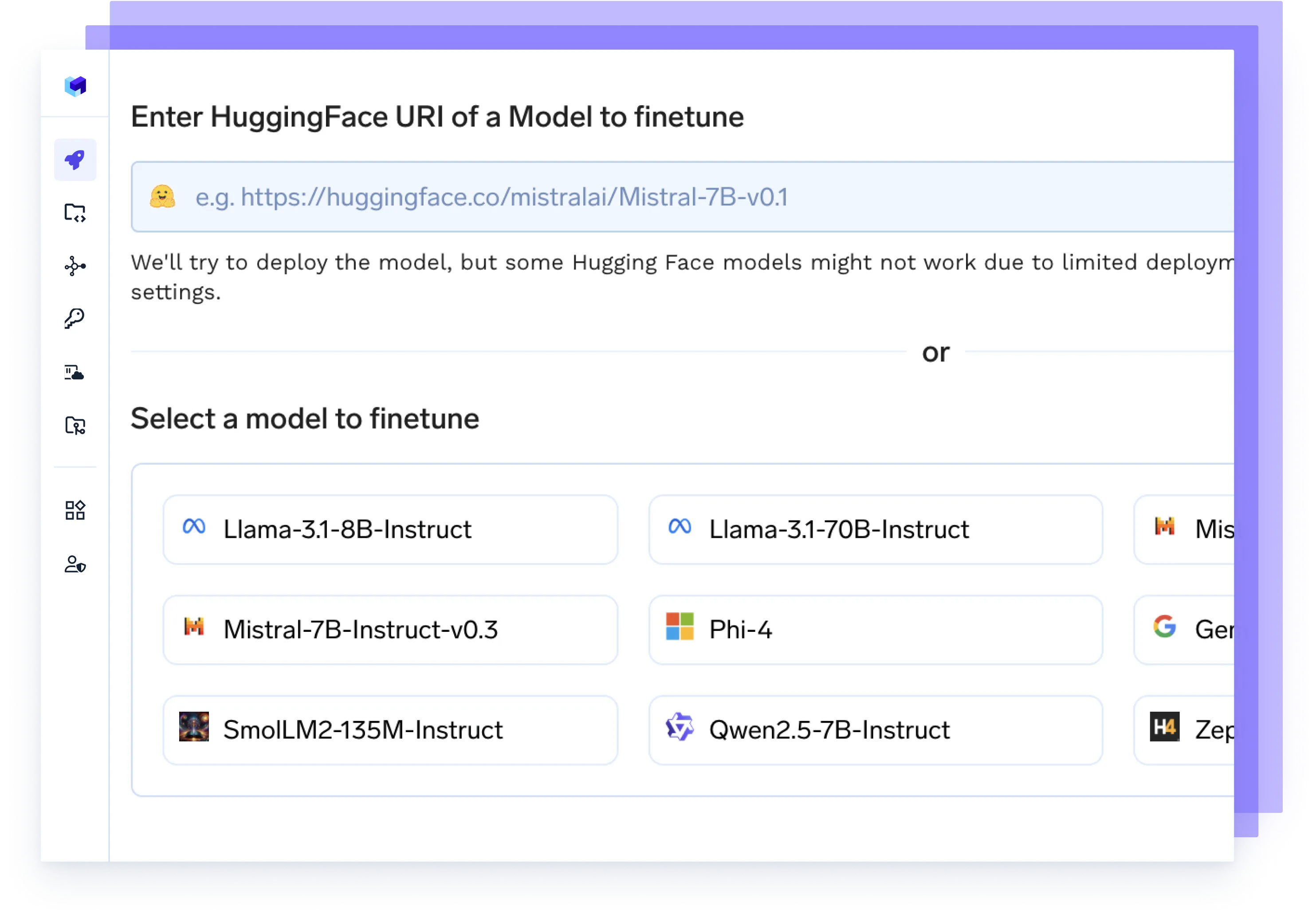
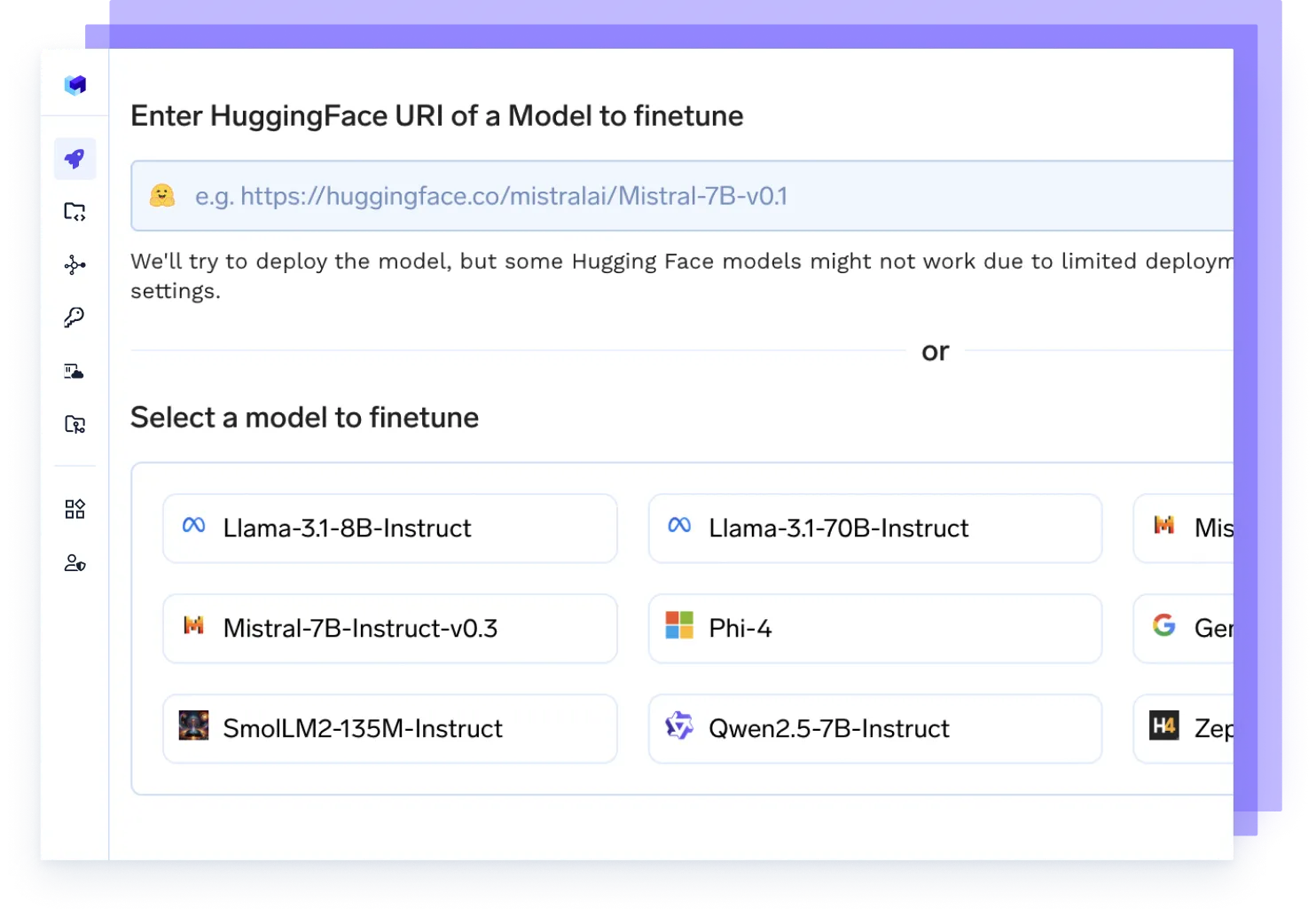
Réglez n'importe quel modèle
Lancez des tâches de réglage sur vos données, suivez les expériences et déployez des points de contrôle mis à jour directement en production, le tout dans un seul flux.
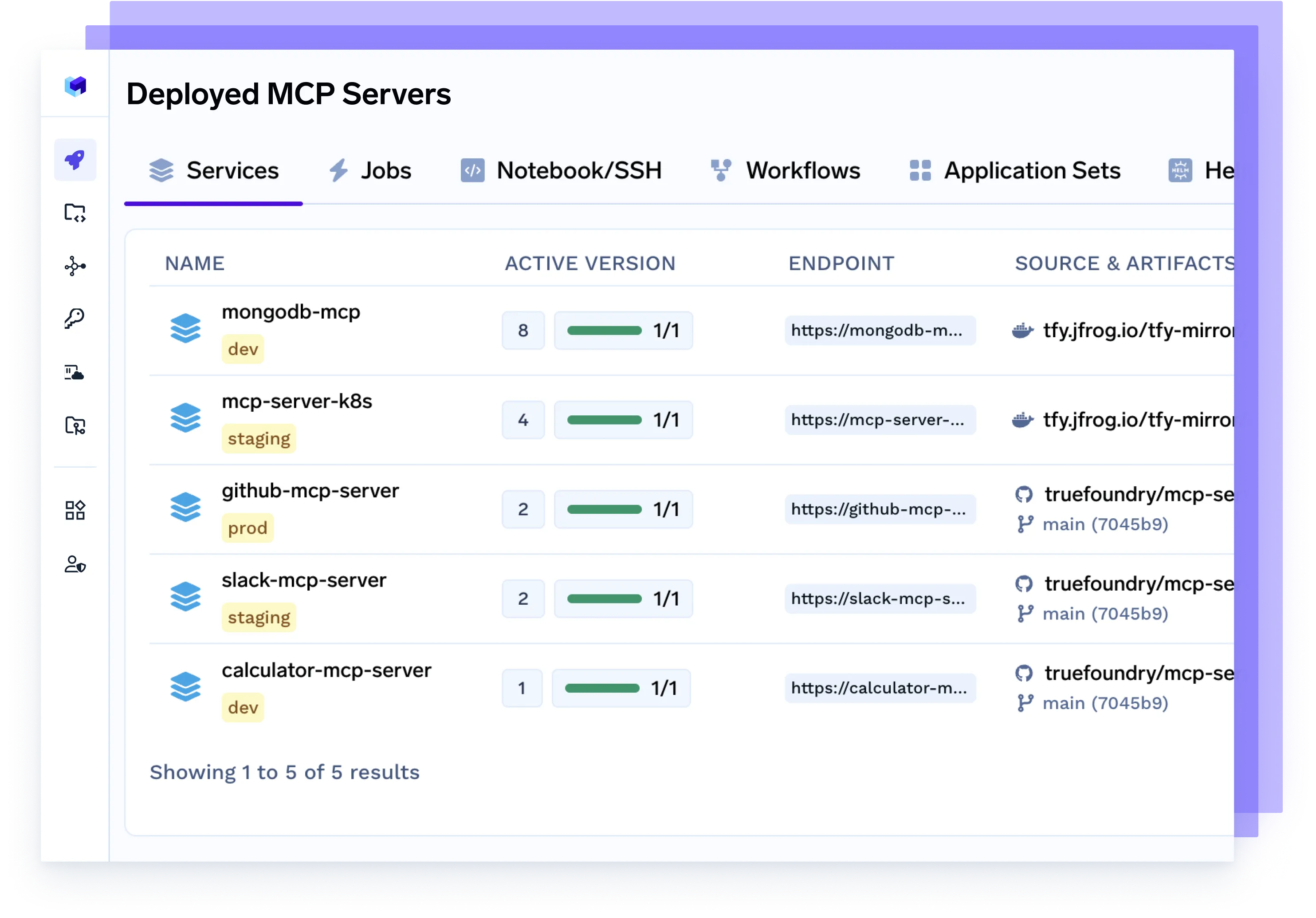
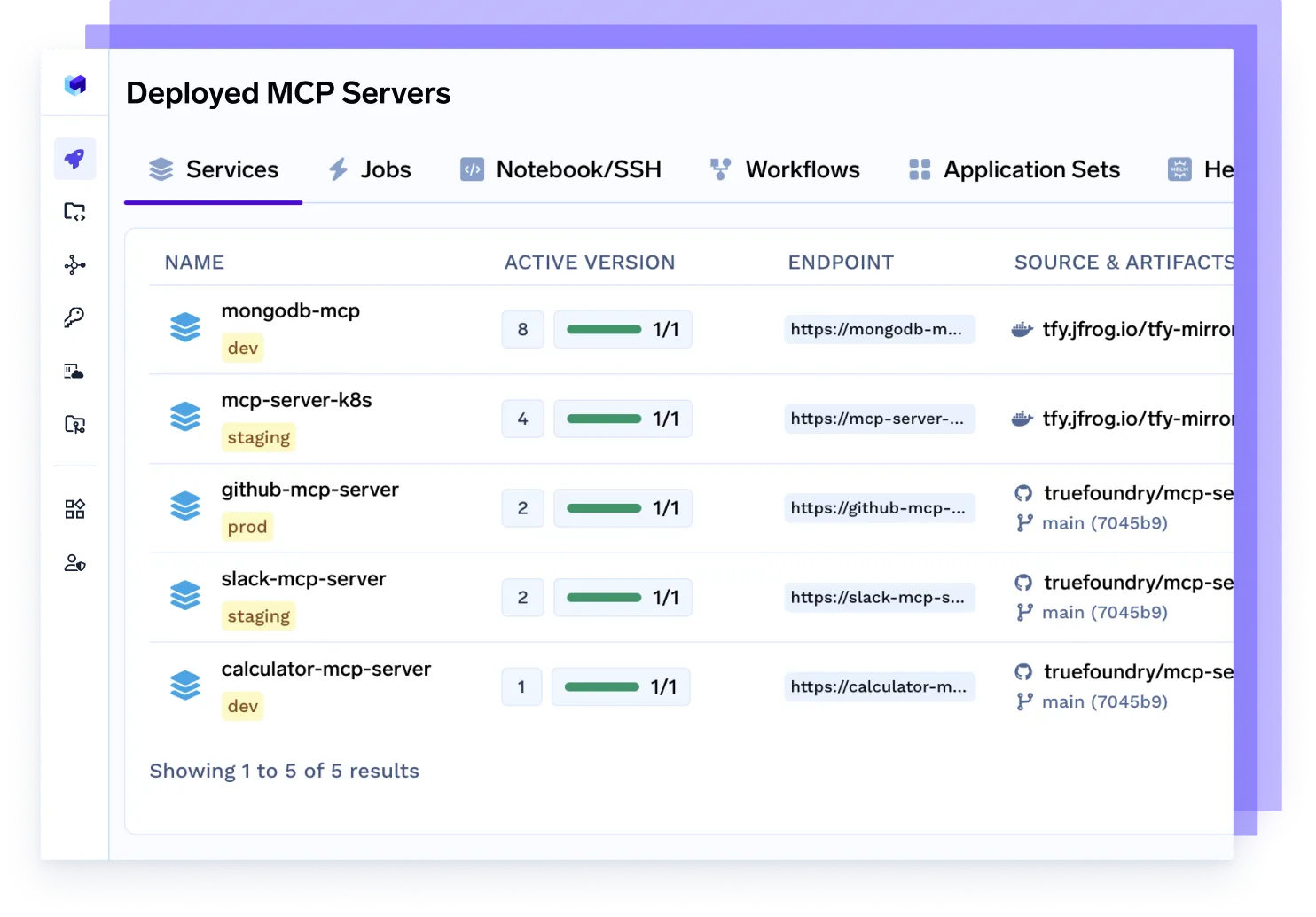
Déploiement du serveur MCP
Fournissez des serveurs MCP (Model Control Protocol) dédiés pour gérer le trafic des agents, dimensionner l'accès aux modèles, appliquer des limites de débit et isoler les charges de travail par équipe ou par projet.
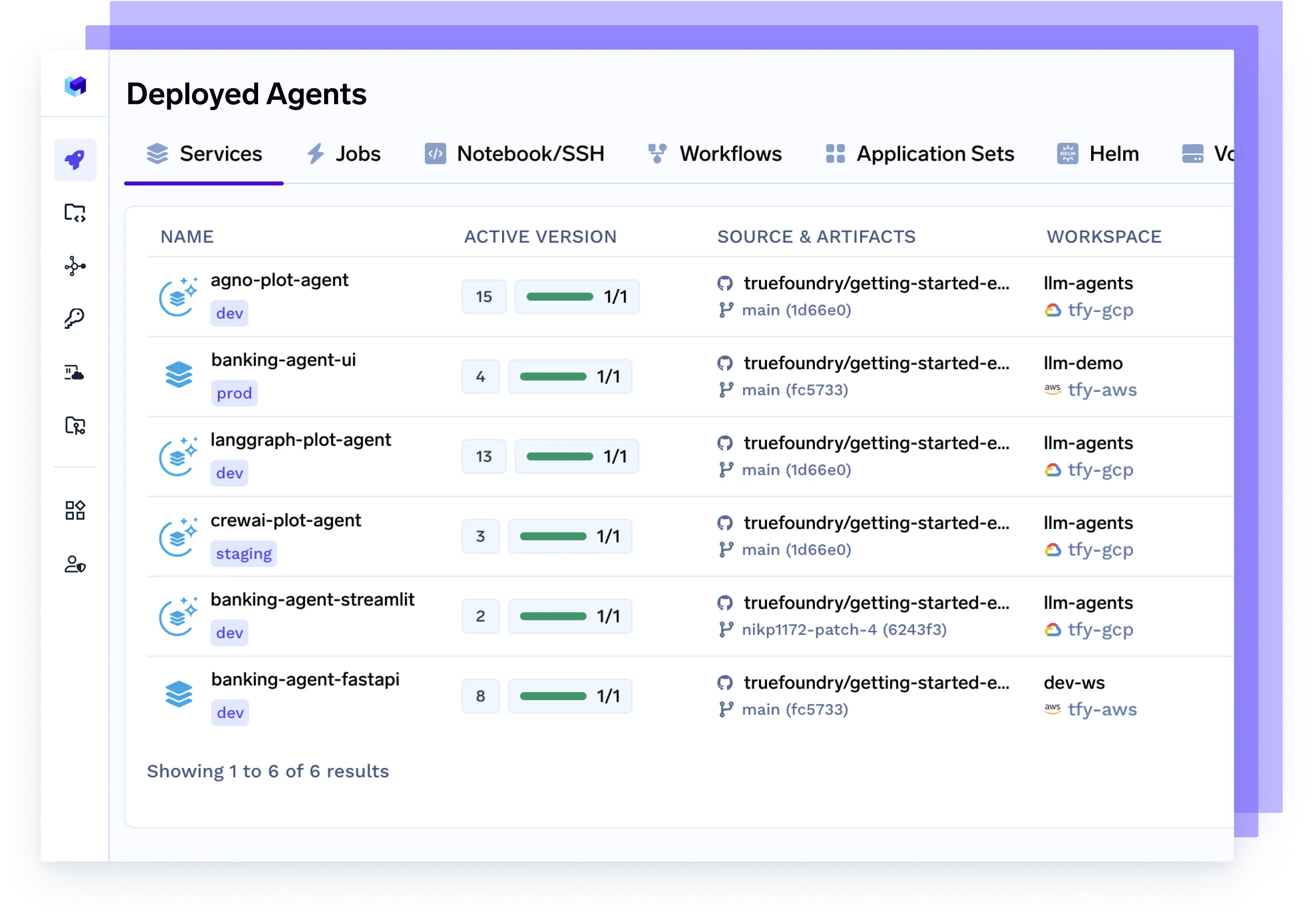
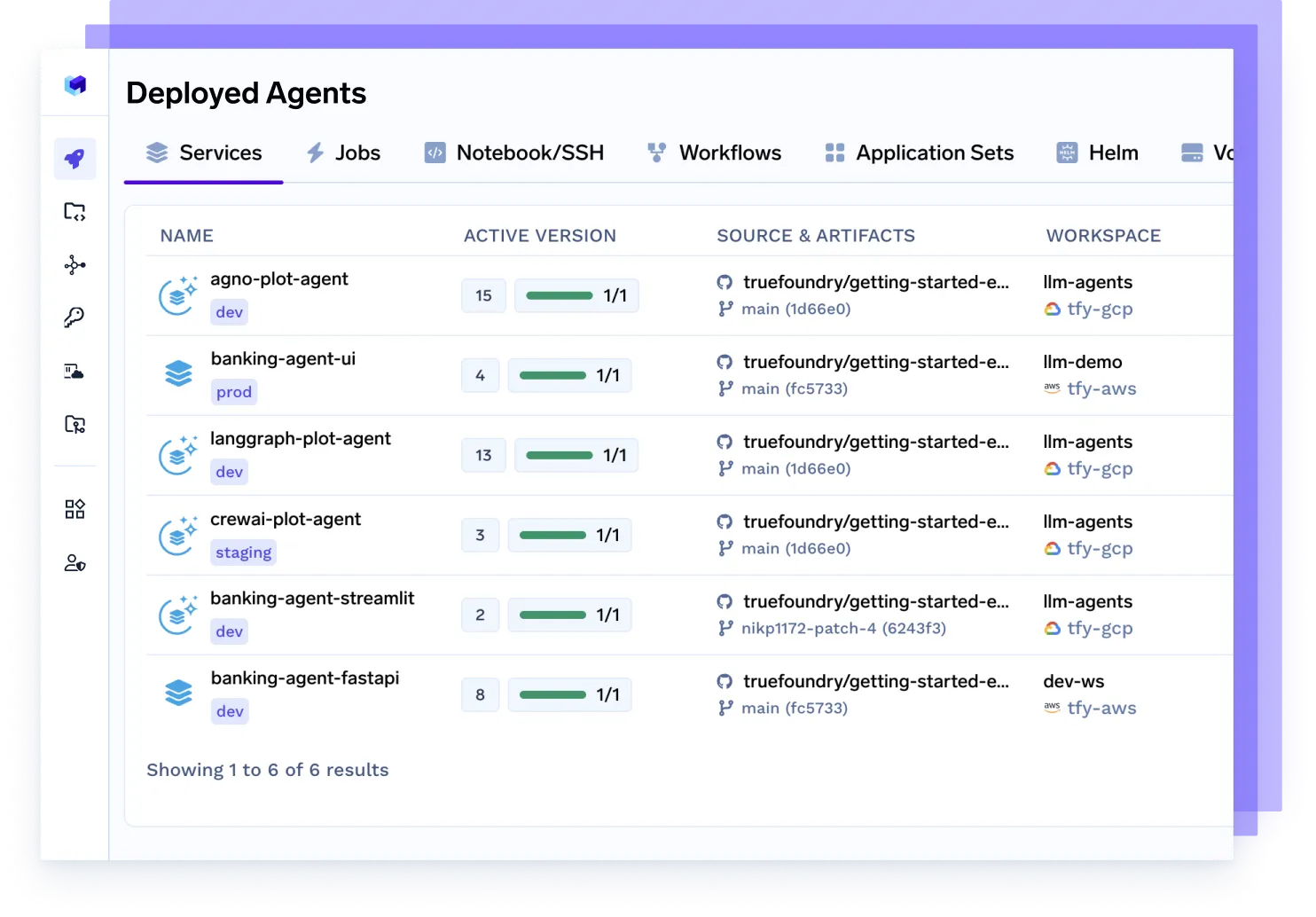
Déployez n'importe quel agent, n'importe quel framework
Servez en toute fluidité des agents conçus avec Langgraph, CrewAI, AutoGen ou votre propre orchestration. Ils sont entièrement conteneurisés, observables et prêts pour la production.
VPC, sur site, en espace isolé ou sur plusieurs clouds.
Aucune donnée ne quitte votre domaine. Profitez d'une souveraineté totale, d'un isolement et d'une conformité de niveau professionnel, quel que soit l'endroit où TrueFoundry fonctionne.


Prêt pour les entreprises
Déployez une passerelle IA sécurisée qui maintient vos données et modèles au sein de votre infrastructure cloud / sur site.


Conformité et sécurité
Normes SOC 2, HIPAA et GDPR pour garantir une protection robuste des donnéesGouvernance et contrôle d'accès
SSO + Contrôle d'accès basé sur les rôles (RBAC) et journalisation des auditsSupport et fiabilité pour les entreprises
Assistance 24 h/24 et 7 j/7 avec support SLA SLA de réponse
Observez les agents et l'infrastructure sous-jacente
Traçage indépendant du framework pour tout, de l'exécution rapide aux performances du GPU.
Observabilité complète des agents
Suivez chaque étape, de l'exécution de l'invite à l'exécution de l'outil/du modèle, grâce aux métriques, à la latence et aux résultats
.avif)
Intégration fluide avec les outils internes
Compatible avec OpenTelemetry ; branchez-le à Grafana, Datadog, Prometheus ou à votre stack d'observabilité préféré




Observabilité infrarouge (GPU, CPU, cluster)
Surveillez l'utilisation des ressources dans le cloud et sur site, y compris la mémoire GPU, l'état des nœuds et le comportement de dimensionnement
.avif)
Gouvernez et renforcez la conformité grâce à l'IA de niveau entreprise
Instaurez la confiance et la discipline opérationnelle grâce à des contrôles d'accès robustes, à l'application de politiques et à une observabilité complète, intégrées de manière native dès le premier jour.
.webp)
Contrôle d'accès granulaire basé sur les rôles (RBAC)
Contrôlez précisément qui peut accéder aux modèles, aux environnements ou aux API en fonction des équipes, des rôles et des fonctions.
.webp)
Journalisation d'audit immuable
Enregistrez toutes les activités, y compris l'utilisation du modèle, l'accès des utilisateurs et les modifications de configuration pour garantir une préparation complète à l'audit.

Architecture prête à être mise en conformité
Conçu pour répondre aux normes de sécurité et de conformité les plus strictes, notamment SOC 2, HIPAA et GDPR.
.avif)
Surveillance et alertes unifiées
Suivez la latence, le débit, l'utilisation des jetons, les coûts et l'utilisation du GPU sur l'ensemble de votre stack d'IA via des tableaux de bord et des alertes centralisés.

Application des politiques en temps réel
Appliquez les politiques relatives à la résidence des données, aux quotas d'utilisation, aux limites de débit et au contrôle des coûts de manière dynamique au fur et à mesure de l'exécution des charges de travail.
Nous envisageons une infrastructure d'IA optimisée et sans gestion
Optimisation automatique des ressources sans frais d'exploitation

Orchestration et mise à l'échelle automatique du GPU
Planifiez et adaptez automatiquement les charges de travail du GPU en fonction de la demande, en optimisant les performances sans surprovisionnement.
Support GPU fractionné
(MIG et Time Slicing)
Permettez un partage rentable des ressources GPU entre plusieurs charges de travail à l'aide de NVIDIA MIG et du découpage temporel.
Ressource en temps réel
Optimisation
Ajustez en permanence les allocations de processeur et de mémoire en fonction du trafic réel et des besoins de calcul.
Redimensionnement automatique de l'infrastructure
Détectez et corrigez l'infrastructure surprovisionnée afin de réduire le gaspillage dans le cloud tout en maintenant les SLA et les performances des modèles.
Des résultats concrets chez TrueFoundry
Pourquoi les entreprises choisissent TrueFoundry






3 fois
rentabilisation plus rapide grâce à des agents LLM autonomes
80 %
utilisation accrue du cluster GPU après optimisation automatique des agents

Aaron Erickson
Fondateur d'Applied AI Lab
TrueFoundry a transformé notre parc de processeurs graphiques en un moteur autonome à optimisation automatique, ce qui nous a permis d'augmenter de 80 % le taux d'utilisation et d'économiser des millions de dollars en temps de calcul inactif.
5x
accélération de la mise en production de la plateforme interne d'IA/ML
50 %
réduire les dépenses liées au cloud après la migration des charges de travail vers TrueFoundry

Pratik Agrawal
Directeur principal de la science des données et de l'innovation en matière d'IA
TrueFoundry nous a aidés à passer de l'expérimentation à la production en un temps record. Ce qui aurait pris plus d'un an a été réalisé en quelques mois, avec une meilleure adoption par les développeurs.
80 %
réduction des délais de production des modèles
35 %
économies sur les coûts liés au cloud par rapport à la configuration précédente de SageMaker
.webp)
Vibhas Gejji
Ingénieur ML du personnel
Nous avons allégé la charge DevOps et simplifié les déploiements de production entre les équipes. TrueFoundry a accéléré la diffusion du machine learning grâce à une infrastructure qui s'adapte aussi bien aux expériences qu'à des services robustes.
50 %
déploiement plus rapide de la pile RAG/agent
60 %
réduction des frais de maintenance pour les pipelines RAG/agent
.webp)
Indronel G.
Leader intelligent des processus
TrueFoundry nous a aidés à déployer une pile RAG complète, y compris des pipelines, des bases de données vectorielles, des API et une interface utilisateur, deux fois plus rapidement, tout en contrôlant totalement l'infrastructure auto-hébergée.
60 %
des déploiements d'IA plus rapides
~ 40 à 50 %
Réduction efficace des coûts dans tous les environnements de développement
.webp)
Nilav Ghosh
Directeur principal, IA
Grâce à TrueFoundry, nous avons réduit les délais de déploiement de plus de moitié et réduit les frais d'infrastructure grâce à une interface MLOps unifiée, ce qui a accéléré la création de valeur.
<2
semaines pour migrer tous les modèles de production
75 %
réduction du temps de coordination de la science des données, accélération des mises à jour des modèles et du déploiement des fonctionnalités
.webp)
Rajat Bansal
CTO
Nous avons réalisé d'importantes économies sur les coûts d'infrastructure et avons réduit le temps de coordination du DS de 75 %. TrueFoundry a accéléré la vitesse de déploiement de nos modèles au sein des équipes.
Intégrations
Des intégrations indépendantes du framework pour tout, des créateurs d'agents low-code à l'évaluation des performances au niveau du GPU.

GenAI infra- simple, plus rapide et moins cher
Les meilleures équipes lui font confiance pour faire évoluer GenAI
- © 2022 ENSEMBLE Technologies






Abonnez-vous à notre newsletter
Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception














