











Ajustez n'importe quel modèle
Ajustez les LLM et les modèles ML classiques à l'aide des intégrations Hugging Face et de modèles prêts à être utilisés en production
Ajustement sans code ou en code complet
Démarrez rapidement avec une interface utilisateur sans code ou apportez vos propres scripts d'entraînement pour un contrôle et une flexibilité complets.
PEFT et réglage complet
Supportez LoRa, QLoRa et optimisez entièrement les paramètres pour équilibrer les coûts, l'utilisation de la mémoire et les performances du modèle.
Pointage de contrôle et gestion des versions
Exécutions automatiques des points de contrôle, reprise de l'entraînement et version des modèles et des ensembles de données pour assurer la reproductibilité.
Suivi des expériences intégré
Suivez les hyperparamètres, les métriques, les ensembles de données et les sorties tout au long des cycles de réglage.
Gestion des adaptateurs
Entraînez, réutilisez, fusionnez et changez d'adaptateur LoRa pour accélérer le réglage et réduire les coûts.
.webp)
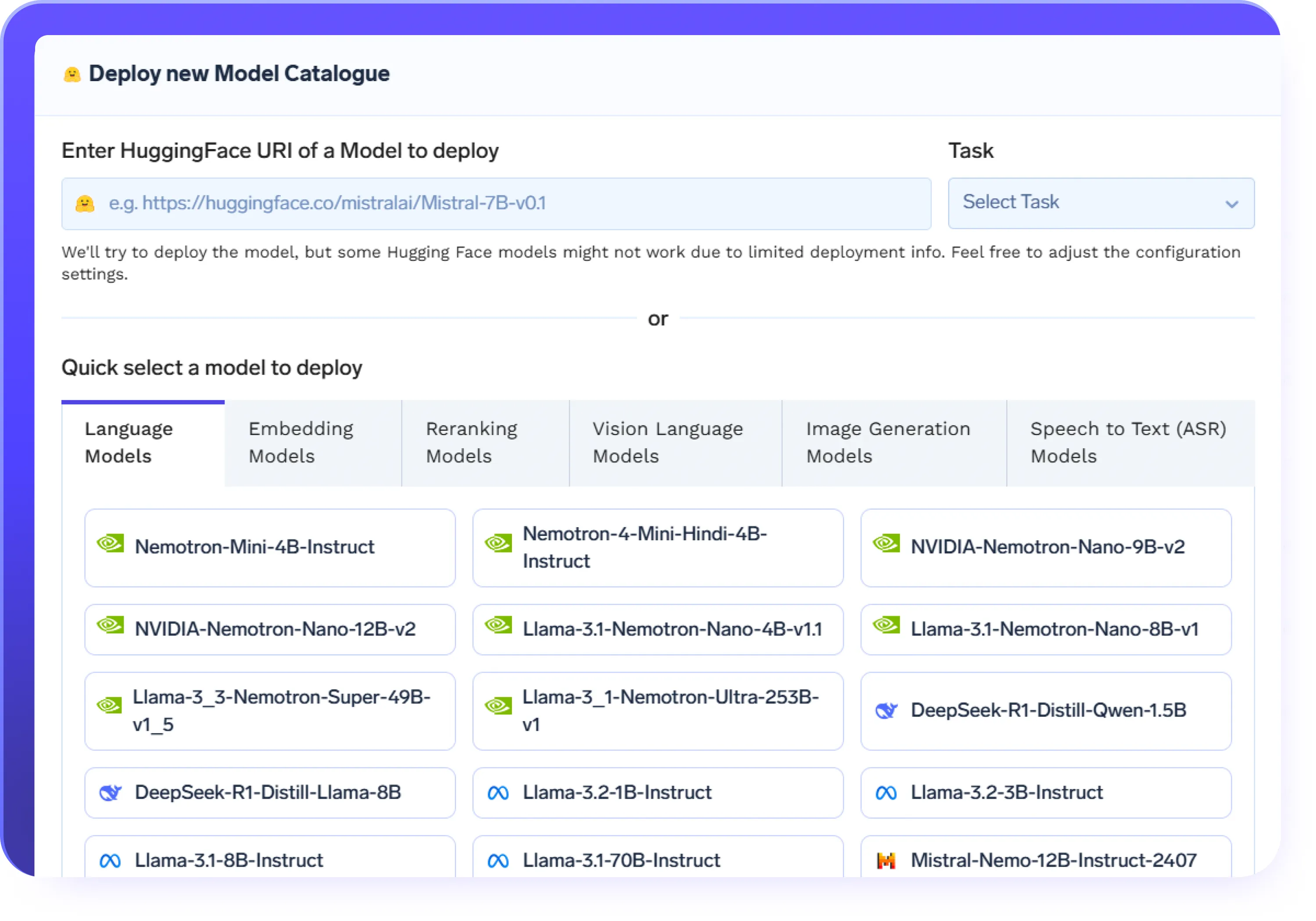
Ajustez n'importe quel modèle de visage étreint/modèle ML classique
- Supporte le réglage fin des LLM tels que LLama, Mistral, BERT, Falçon et GPT-J
- Commencez à peaufiner les LLM en quelques minutes à l'aide du hub de modèles Hugging Face intégré
- Les modèles préconfigurés simplifient le processus de réglage fin des grands modèles de langage
- L'infrastructure évolutive gère tout, des petites expériences au réglage fin de LLM de niveau production
Sans code ou code complet : à vous de choisir
- Ajustez les LLM à l'aide d'une interface utilisateur sans code pour une configuration et une itération rapides
- Apportez vos propres scripts d'entraînement avec un contrôle total en mode code
- Gérez automatiquement l'évolutivité de l'infrastructure et des ressources
- Bénéficiez d'une transparence totale sur chaque exécution de réglage, grâce à des journaux, des métriques et un contrôle de version intégrés.
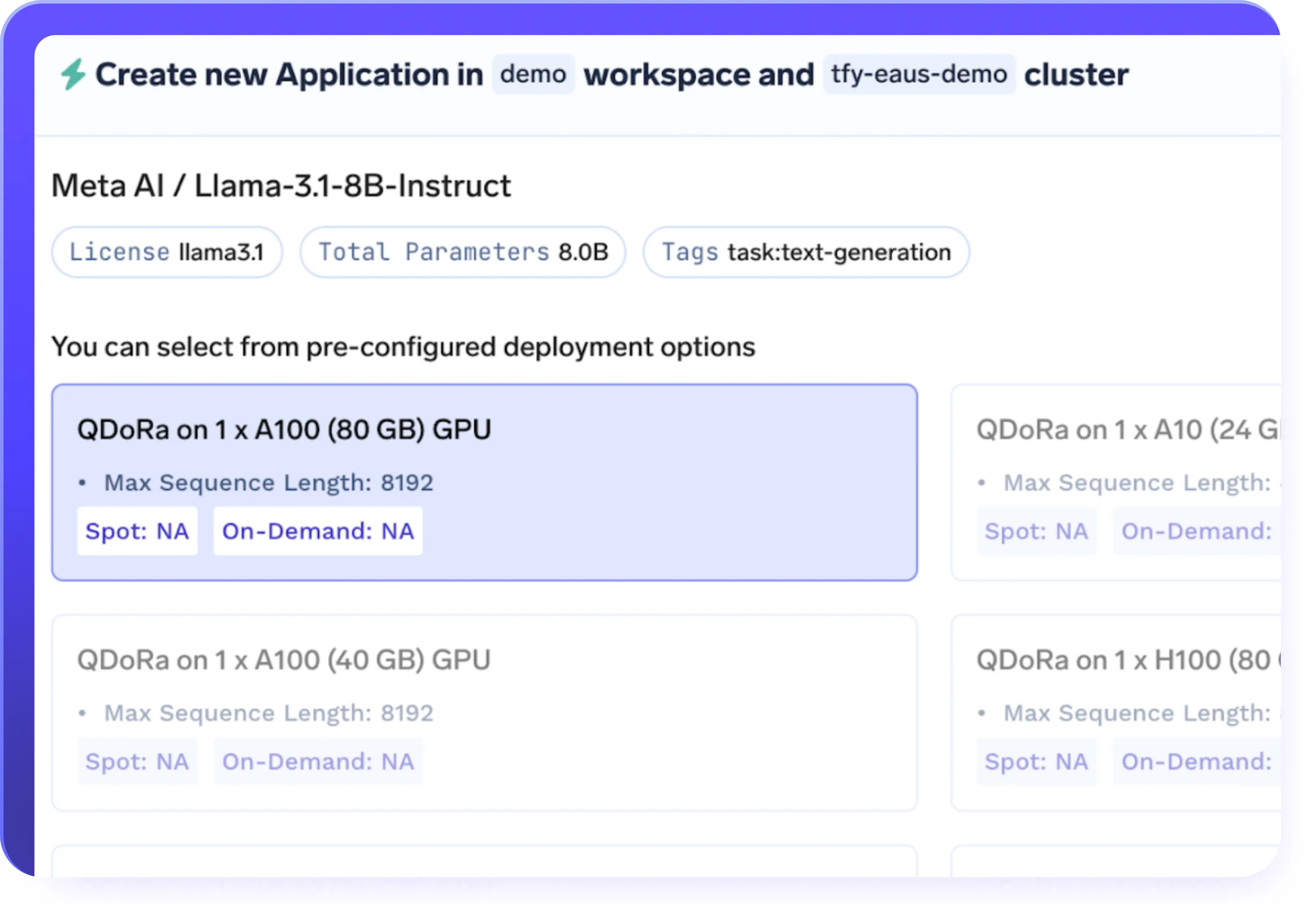
PEFT (LoRa/QLoRa) et support de réglage complet
- Supporte le réglage fin efficace des paramètres (LoRa, QLoRa) ainsi que le réglage fin complet du modèle
- Choisissez LoRa ou QLoRa pour un réglage plus rapide et plus rentable des LLM de grande taille
- Réduisez l'utilisation de la mémoire GPU tout en préservant la qualité et les performances du modèle
- Sélectionnez la bonne approche de réglage en fonction de la taille du modèle, du coût et des besoins en matière de charge de travail
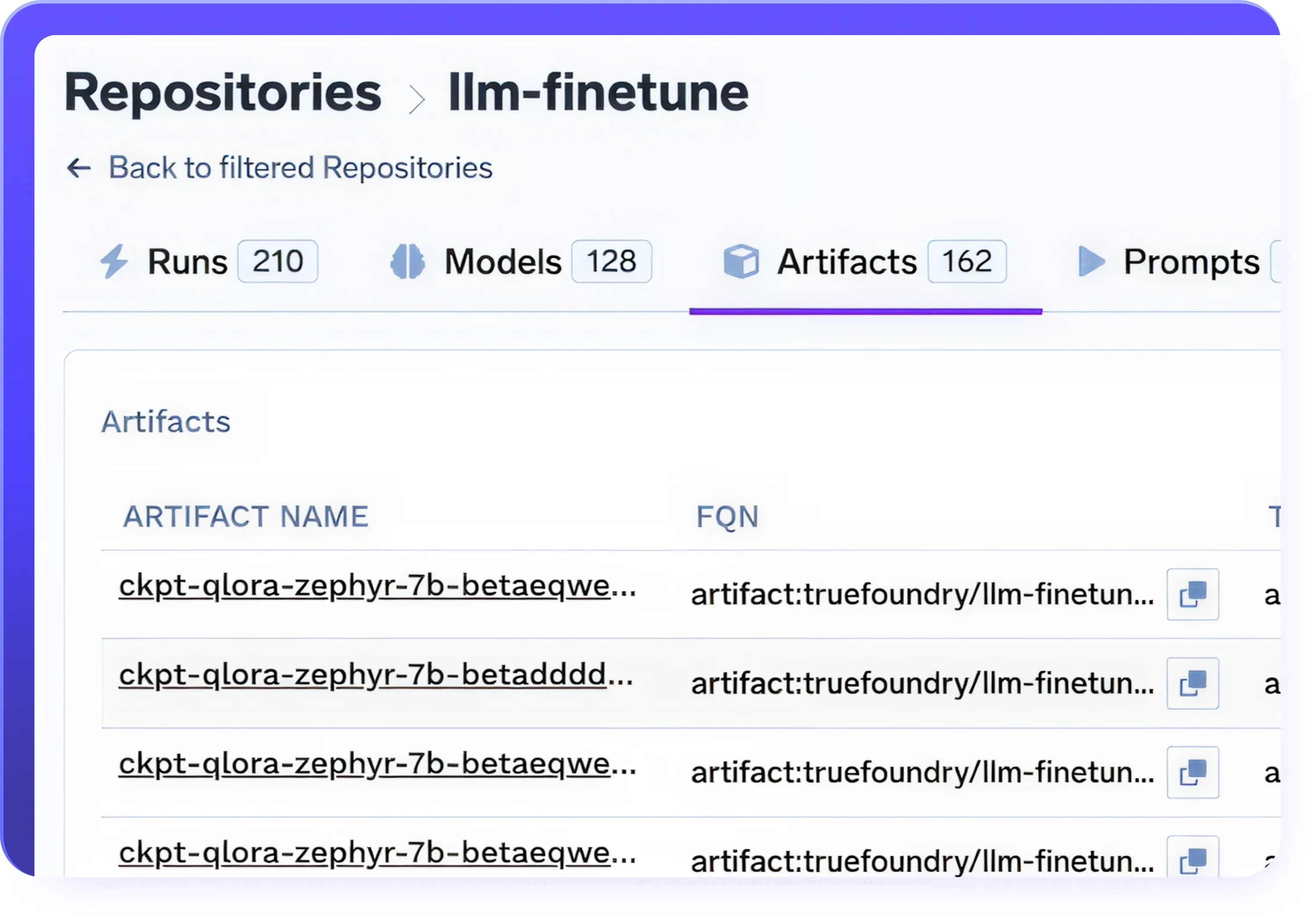
Pointage de contrôle et gestion des versions
- Enregistrez automatiquement les points de contrôle lors de la mise au point pour éviter toute perte de progression lors de l'entraînement
- Reprenez les tâches de réglage interrompues ou en pause à partir de n'importe quel point de contrôle
- Modèles de version, ensembles de données et cycles d'entraînement pour une reproductibilité totale
- Revenez aux points de contrôle précédents et comparez les performances entre les versions
Suivi des expériences intégré
- Enregistrez automatiquement toutes les métadonnées d'entraînement : hyperparamètres, mesures, ensembles de données et sorties
- Comparez plusieurs séries pour affiner les LLM plus efficacement
- Intégrez-le à votre stack LLMops ou utilisez notre interface visuelle native
- Le contrôle de version intégré garantit la reproductibilité et l'auditabilité
Gestion des adaptateurs pour un réglage fin efficace du LLM
- Tirez parti des adaptateurs LoRa pour affiner les modèles en ne mettant à jour qu'un petit ensemble de paramètres.
- Réutilisez des adaptateurs préformés dans tous les projets et domaines
- Fusionnez ou changez d'adaptateur pour différentes tâches, ce qui permet une expérimentation rapide et une conception de modèles modulaires
- Accélérez l'entraînement et réduisez les coûts en utilisant des modules adaptateurs compacts plutôt que des haltères LLM complètes
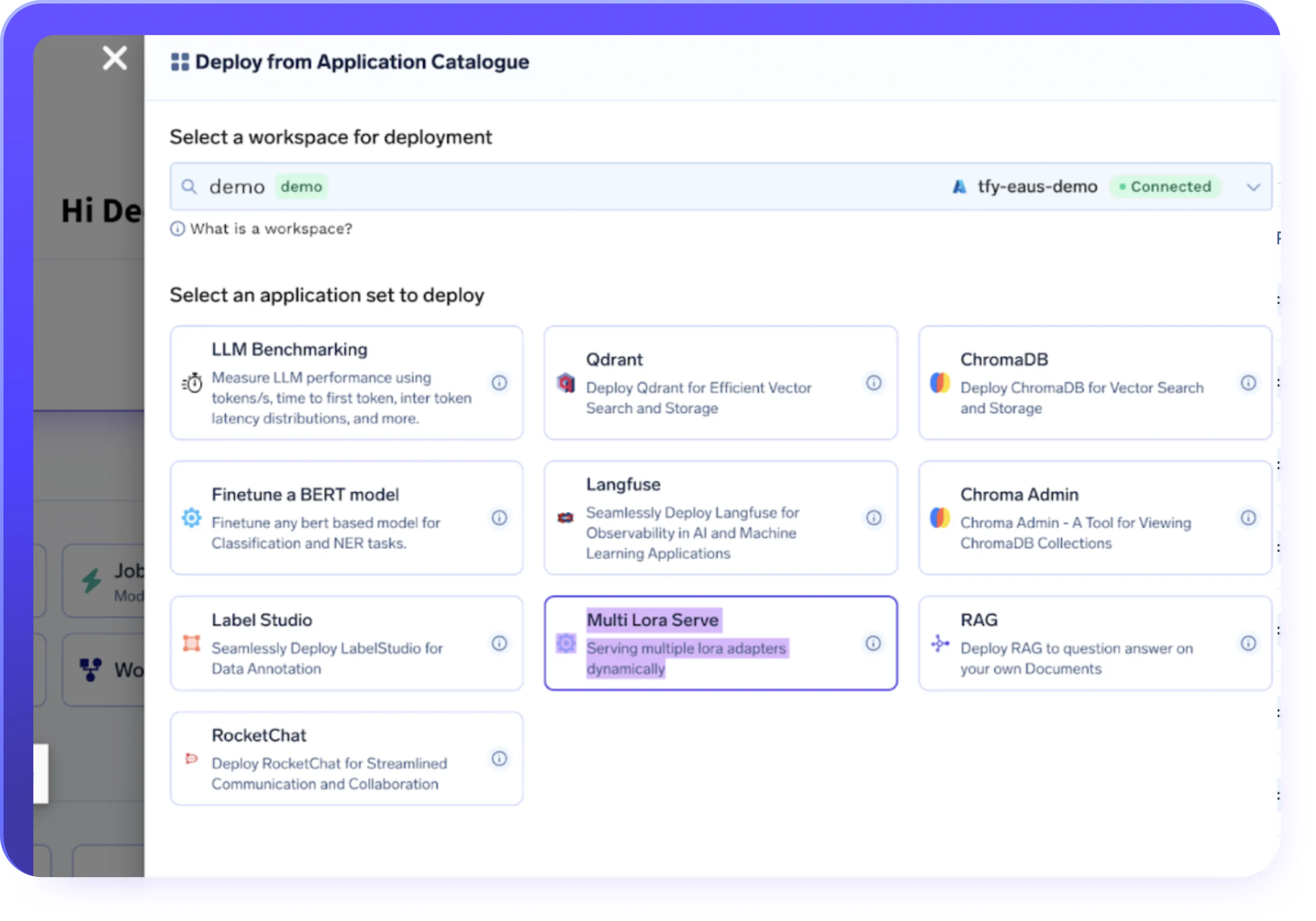
Intégrations de données et d'infra
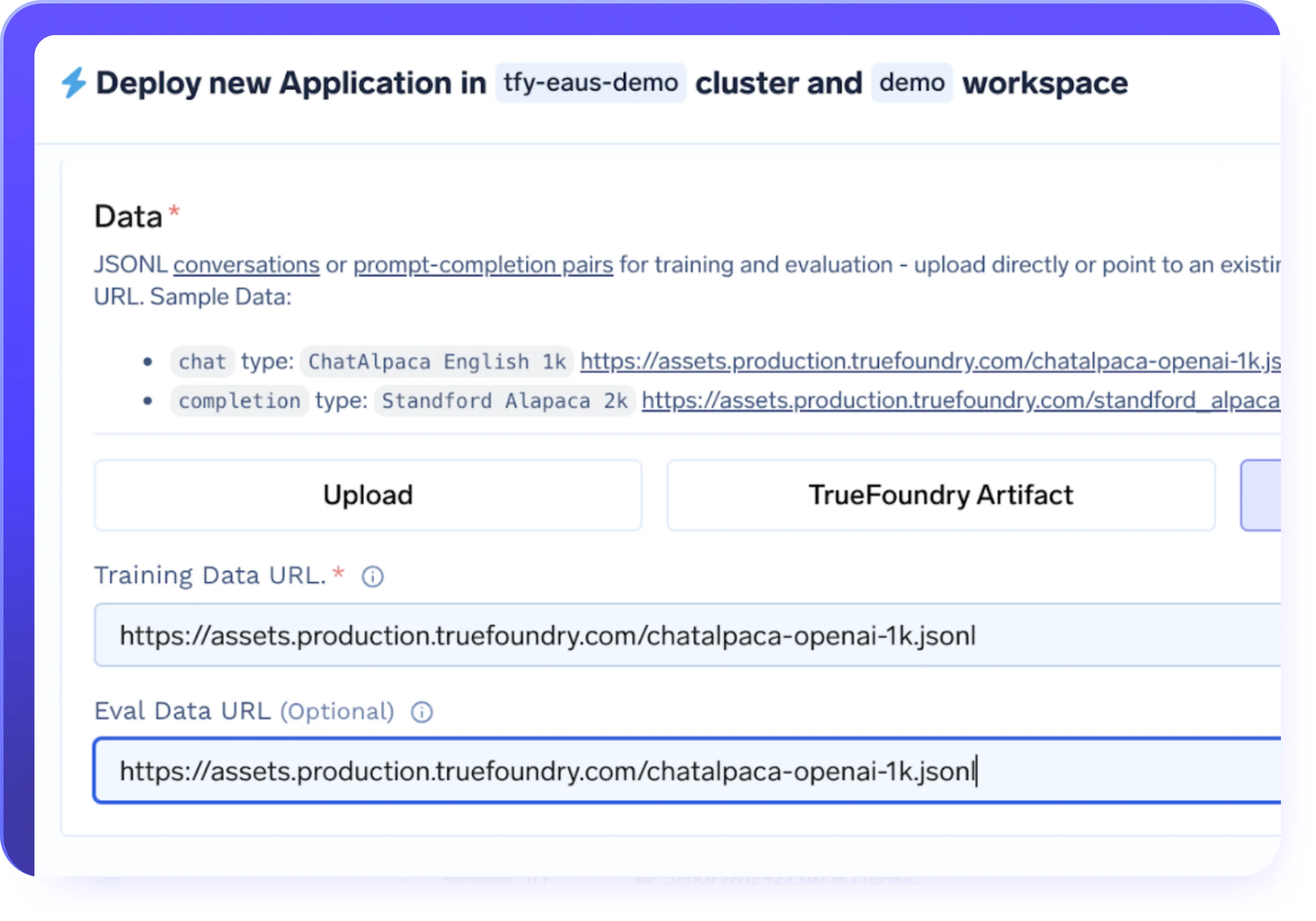
- Importez des ensembles de données depuis S3, GCS, Azure Blob ou Hugging Face Datasets
- Exécutez des tâches de réglage sur une infrastructure entièrement gérée ou sur vos propres clusters
- Déployez des charges de travail dans des environnements cloud, hybrides ou sur site
- Utilisez par défaut la mise à l'échelle automatique du GPU, le découpage en temps et le provisionnement tenant compte des coûts
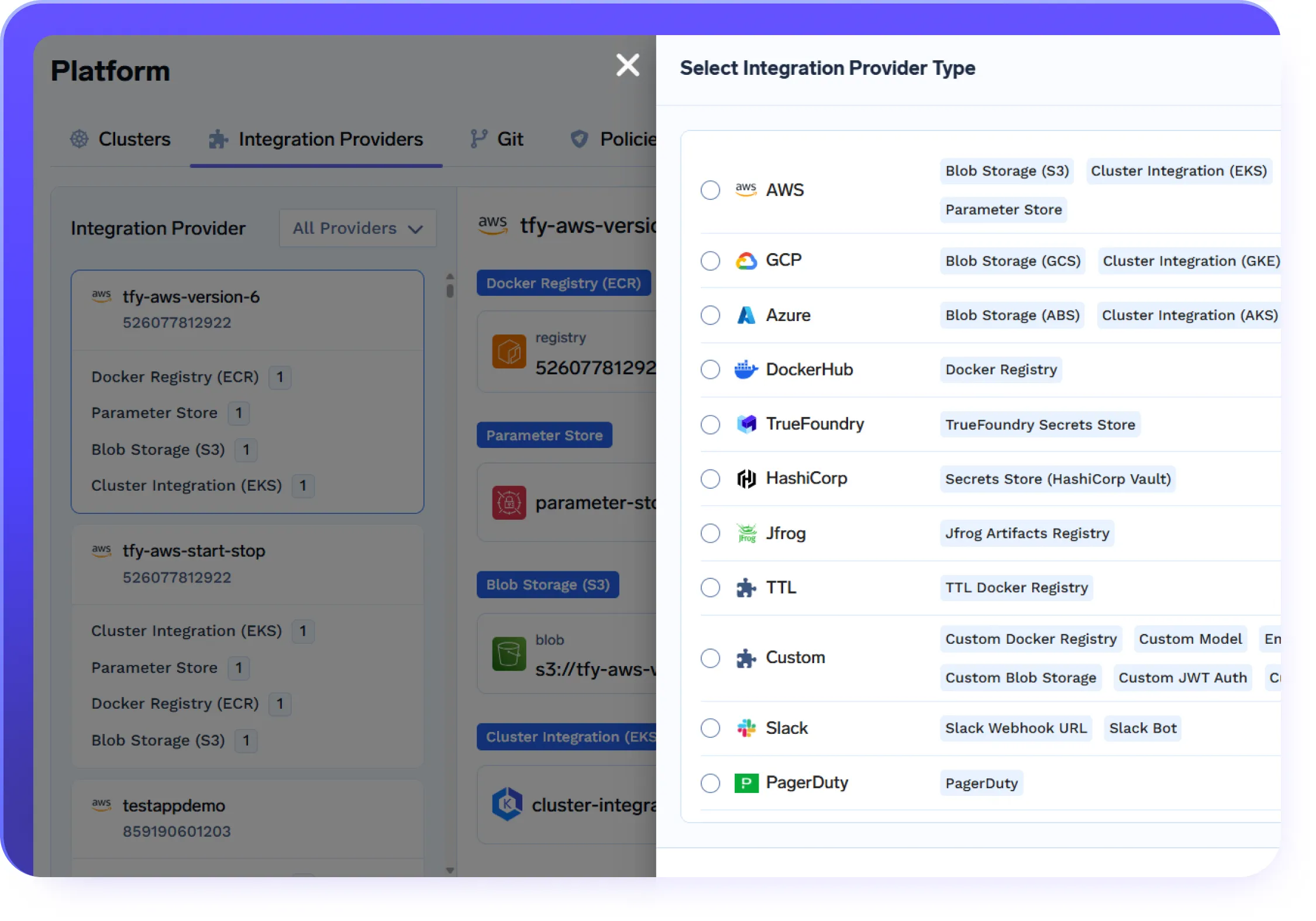
Conçu pour une IA à grande échelle dans le monde réel
Prêt pour les entreprises
Déployez une passerelle IA sécurisée qui maintient vos données et modèles au sein de votre infrastructure cloud / sur site.


Conformité et sécurité
Normes SOC 2, HIPAA et GDPR pour garantir une protection robuste des donnéesGouvernance et contrôle d'accès
SSO + Contrôle d'accès basé sur les rôles (RBAC) et journalisation des auditsSupport et fiabilité pour les entreprises
Assistance 24 h/24 et 7 j/7 avec support SLA SLA de réponse
VPC, sur site, en espace isolé ou sur plusieurs clouds.
Aucune donnée ne quitte votre domaine. Profitez d'une souveraineté totale, d'un isolement et d'une conformité de niveau professionnel partout où TrueFoundry fonctionne

Des résultats concrets chez TrueFoundry
Pourquoi les entreprises choisissent TrueFoundry






3 fois
rentabilisation plus rapide grâce à des agents LLM autonomes
80 %
utilisation accrue du cluster GPU après optimisation automatique des agents

Aaron Erickson
Fondateur d'Applied AI Lab
TrueFoundry a transformé notre parc de processeurs graphiques en un moteur autonome à optimisation automatique, ce qui nous a permis d'augmenter de 80 % le taux d'utilisation et d'économiser des millions de dollars en temps de calcul inactif.
5x
accélération de la mise en production de la plateforme interne d'IA/ML
50 %
réduire les dépenses liées au cloud après la migration des charges de travail vers TrueFoundry

Pratik Agrawal
Directeur principal de la science des données et de l'innovation en matière d'IA
TrueFoundry nous a aidés à passer de l'expérimentation à la production en un temps record. Ce qui aurait pris plus d'un an a été réalisé en quelques mois, avec une meilleure adoption par les développeurs.
80 %
réduction des délais de production des modèles
35 %
économies sur les coûts liés au cloud par rapport à la configuration précédente de SageMaker
.webp)
Vibhas Gejji
Ingénieur ML du personnel
Nous avons allégé la charge DevOps et simplifié les déploiements de production entre les équipes. TrueFoundry a accéléré la diffusion du machine learning grâce à une infrastructure qui s'adapte aussi bien aux expériences qu'à des services robustes.
50 %
déploiement plus rapide de la pile RAG/agent
60 %
réduction des frais de maintenance pour les pipelines RAG/agent
.webp)
Indronel G.
Leader intelligent des processus
TrueFoundry nous a aidés à déployer une pile RAG complète, y compris des pipelines, des bases de données vectorielles, des API et une interface utilisateur, deux fois plus rapidement, tout en contrôlant totalement l'infrastructure auto-hébergée.
60 %
des déploiements d'IA plus rapides
~ 40 à 50 %
Réduction efficace des coûts dans tous les environnements de développement
.webp)
Nilav Ghosh
Directeur principal, IA
Grâce à TrueFoundry, nous avons réduit les délais de déploiement de plus de moitié et réduit les frais d'infrastructure grâce à une interface MLOps unifiée, ce qui a accéléré la création de valeur.
<2
semaines pour migrer tous les modèles de production
75 %
réduction du temps de coordination de la science des données, accélération des mises à jour des modèles et du déploiement des fonctionnalités
.webp)
Rajat Bansal
CTO
Nous avons réalisé d'importantes économies sur les coûts d'infrastructure et avons réduit le temps de coordination du DS de 75 %. TrueFoundry a accéléré la vitesse de déploiement de nos modèles au sein des équipes.
Questions fréquemment posées
Qu'est-ce que le réglage fin du LLM et pourquoi est-ce important ?
Comment TrueFoundry simplifie-t-il le réglage fin du LLM ?
- Flux de travail sans code et code complet : utilisez une interface utilisateur intuitive ou des scripts de formation personnalisés
- Suivi des expériences intégré : journalisation automatique des hyperparamètres, des métriques et des versions de modèles
- Orchestration de l'infrastructure : exécutez des tâches sur une infrastructure gérée par TrueFoundry ou sur votre propre Cloud/VPC
- Prise en charge des méthodes PEFT : support natif pour le réglage fin basé sur LoRa et QLoRa
- Contrôles et gestion des versions : reprenez la formation en toute fluidité et maintenez la reproductibilité
- Gestion des adaptateurs : réutilisez, fusionnez ou déployez des adaptateurs sur plusieurs tâches/modèles
Quels types de modèles puis-je peaufiner sur TrueFoundry ?
- LLM basés sur un décodeur (par exemple, LLama, GPT-J, Falçon, Mistral)
- Modèles d'encodeurs (par exemple BERT, Roberta, DisLibert)
- Modèles d'encodeurs-décodeurs (par exemple, T5, FLAN-T5)
Puis-je apporter mon propre jeu de données et mon code de formation ?
- Importez vos propres ensembles de données depuis S3, GCS, Azure, Hugging Face Hub ou des fichiers locaux
- Apportez votre propre code via des scripts de formation personnalisés (PyTorch, Transformers, PEFT, etc.)
- Ou utilisez des modèles prédéfinis pour les flux de travail de réglage précis courants
Comment TrueFoundry prend-il en charge le réglage fin LoRa et QLoRa ?
- Utilisez notre interface utilisateur pour configurer les couches LoRa et les hyperparamètres
- Enregistrez et déployez des adaptateurs LoRa indépendamment des modèles de base
- Fusionnez des adaptateurs avec des modèles de base à des fins de déploiement ou d'inférence hors ligne
- Réduisez considérablement l'utilisation de la mémoire GPU, idéal pour les entreprises qui optimisent leurs dépenses d'infrastructure
Puis-je déployer des modèles affinés depuis TrueFoundry en production ?
- Déployez des modèles avec vLLM, SGlang ou d'autres serveurs d'inférence
- Exposez votre modèle sous la forme d'une API avec limitation de débit intégrée et RBAC
- Surveillez la latence, l'utilisation des jetons et les performances en temps réel
- Utilisez des adaptateurs pour un déploiement rapide ou fusionnez avec le modèle de base pour une inférence autonome

GenAI infra- simple, plus rapide et moins cher
Plus de 30 entreprises et sociétés du Fortune 500 nous font confiance








