

July 23, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 8, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
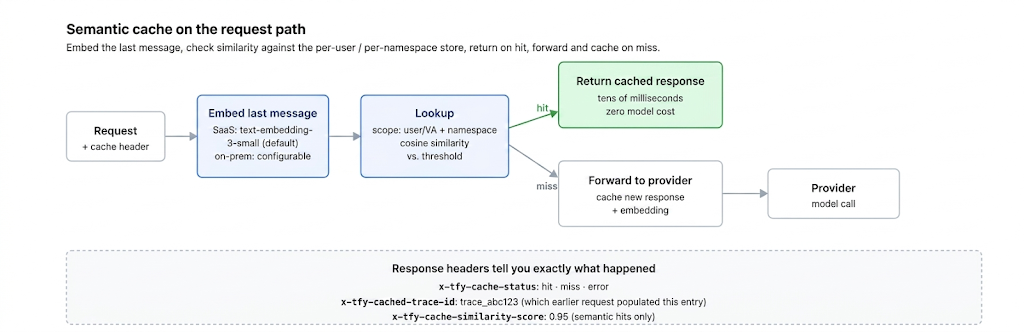
Prefix caching reuses identical prompts. Semantic caching reuses similar ones — embed the incoming request, and if a near-identical question was answered recently, serve the stored answer instead of calling the model. It's one of the highest-leverage cost and latency levers a gateway can pull, and one where "it works in the demo" and "it's safe in production" are very different claims. This post is how it works, the single knob that governs it, the cases where it quietly serves the wrong answer, and where the cache should live.
Kabir, a backend engineer, had a good week and then a bad one. The good week: he'd put a semantic cache in front of Northwind's support assistant — embed each incoming question, and if a near-identical question had been answered recently, return the stored answer instead of calling the model. Model-call volume dropped 35%. Latency on cache hits fell from roughly 900 ms to under 40 ms. The bad week: a customer asked "where's my delivery?" and got a confident, detailed answer — about someone else's order. Two customers had asked semantically identical questions minutes apart; the cache embedded both to nearly the same vector, scored a hit, and served the first customer's answer to the second.
The cache was working exactly as designed. It just had no idea that "where's my delivery?" means something different depending on who is asking. Semantic caching trades a model call for a similarity match, and the entire safety of that trade lives in two places: the threshold you match on, and what you allow into the cache in the first place. This post is both.
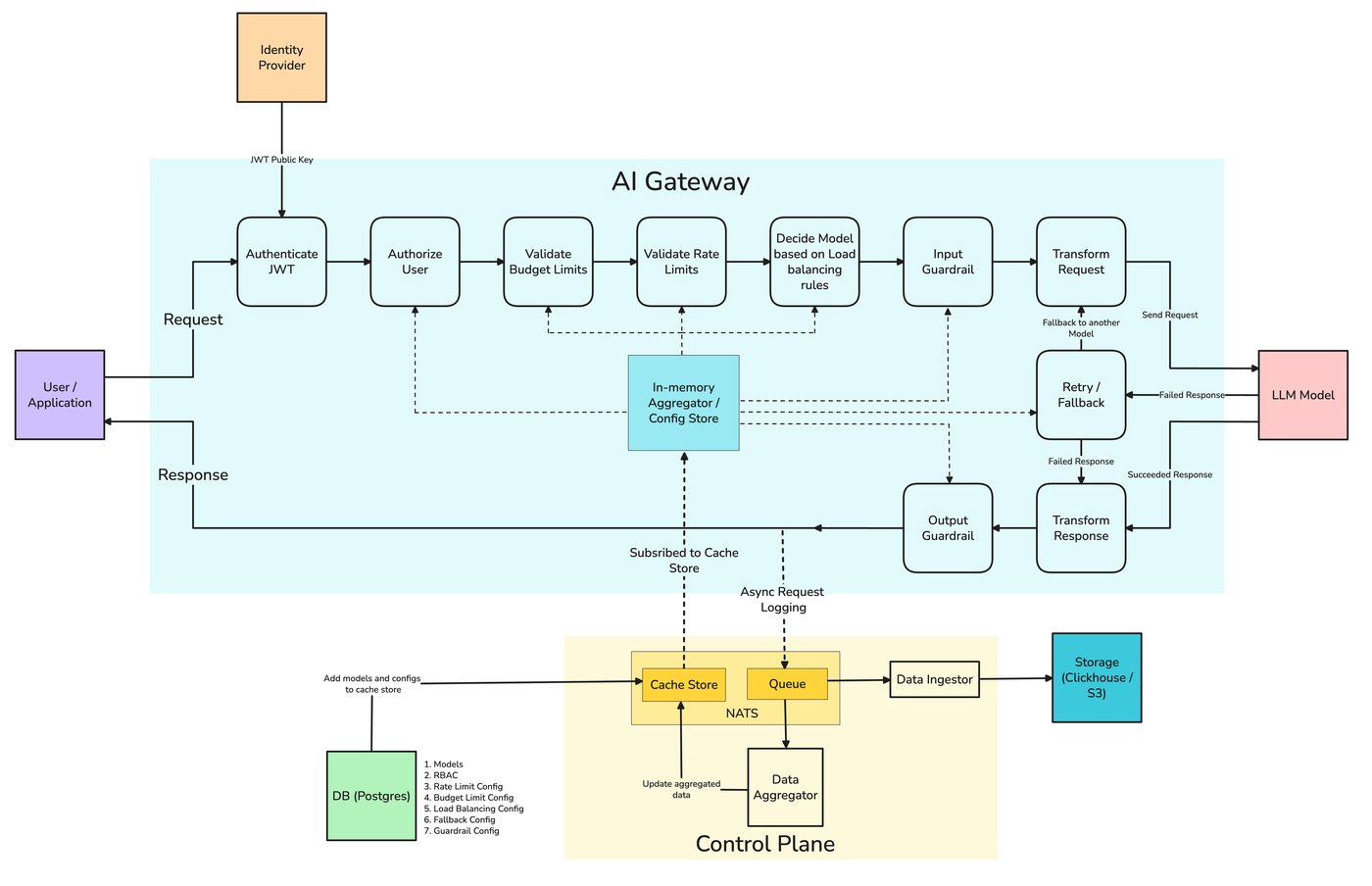
Everything in this post — exact-match and semantic caching, the similarity threshold as a per-route knob, per-tenant scoping so Kabir's bug from the cold open never happens, and the hit-rate / cost-saved telemetry that tells you whether the cache is actually paying off — is something TrueFoundry's AI Gateway caching expresses as gateway configuration. A single header on the request turns it on; the gateway hashes the request (or embeds the last message for semantic), compares against a Redis-backed store, and returns the cached response on a hit. On a miss, the request goes to the provider and the new response and embedding are cached for next time.
The correctness story — making sure two semantically similar requests from different users never return each other's answers — is built in via two-level namespacing. Level 1 is automatic: every cache entry is scoped to the calling user or virtual account, so User A's request can never hit User B's entry, full stop. Level 2 is optional: a namespace field in the cache config partitions further (per tenant, per environment, per system-prompt version), which is what the post's namespace argument needs in practice. Together, they're what makes a gateway-level semantic cache safe to share across services without each one re-implementing isolation.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)





