

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 8, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Las herramientas de codificación asistidas por IA, como OpenCode, cambian radicalmente la forma en que los desarrolladores interactúan con el código. En lugar de funcionar con fragmentos aislados, estos sistemas analizan los archivos, las dependencias y el contexto histórico. El resultado es un aumento significativo de la productividad, pero también un nuevo desafío de costos y escalabilidad que muchos equipos subestiman: uso de tokens.
A diferencia de las herramientas de desarrollo tradicionales con costos de licencia predecibles, el uso de OpenCode se rige por precios basados en tokens. Cada interacción, generación de código, refactorización, depuración o revisión, consume fichas. A medida que los equipos amplían el uso entre desarrolladores, repositorios y agentes automatizados, el consumo de tokens se convierte en el principal impulsor de costos.
Lo que hace que esto sea particularmente complicado es que el uso de tokens es a menudo no intuitivo. Los pequeños cambios en el tamaño del contexto, la estructura de los mensajes o el comportamiento de los agentes pueden provocar grandes cambios en el consumo de tokens. Sin un modelo mental claro sobre cómo se utilizan los tokens, los equipos tienen dificultades para predecir los costos, optimizar los flujos de trabajo o aplicar medidas de protección.
Este blog explica cómo funciona el uso de los tokens en OpenCode a nivel técnico, por qué las cargas de trabajo relacionadas con el código son especialmente pesadas en los tokens y qué deben entender los equipos de la plataforma antes de escalar el uso en producción.
En esencia, el uso de los tokens de OpenCode sigue la misma mecánica que la mayoría de los sistemas impulsados por LLM: los tokens se consumen tanto para las entradas como para las salidas. Sin embargo, la naturaleza de las cargas de trabajo de codificación introduce una complejidad adicional.
El uso de los tokens de OpenCode se puede dividir ampliamente en dos categorías:
En OpenCode, los tokens de aviso suelen incluir:
Los tokens de finalización incluyen:
Desde el punto de vista de los costos, los tokens rápidos suelen ser el factor dominante en el uso de OpenCode, especialmente a medida que aumentan los tamaños de los repositorios y los contextos.
Las tareas relacionadas con el código se comportan de manera muy diferente a las consultas en lenguaje natural. Hay varios factores que contribuyen a un mayor consumo de fichas:
A diferencia de los casos de uso basados en el chat, OpenCode suele enviar:
Incluso una base de código «pequeña» puede traducirse rápidamente en decenas o cientos de miles de tokens cuando se incluyen varios archivos.
El código fuente es denso. La sintaxis, la indentación, los símbolos y el formato se tienen en cuenta a la hora de calcular los símbolos. Unos pocos miles de líneas de código pueden consumir muchos más símbolos que una cantidad equivalente de texto sin formato.
Los flujos de trabajo de OpenCode suelen incluir:
Cada paso puede volver a enviar el contexto o las salidas intermedias, multiplicando el uso del token en una sola tarea.
Cuando OpenCode se usa mediante agentes o automatización (por ejemplo, al refactorizar en varios archivos o ejecutarlo en canalizaciones de CI), el uso de los tokens aumenta rápidamente:
Esto hace que el uso impulsado por agentes sea potente, pero también caro, si no limitado.
Uno de los mayores desafíos con el uso de los tokens de OpenCode es que los desarrolladores rara vez ven el contexto completo que se envía al modelo. Los editores y las herramientas resumen:
Como resultado, dos tareas aparentemente similares pueden tener huellas simbólicas muy diferentes. Sin un seguimiento explícito a nivel de solicitud, los equipos suelen descubrir problemas de costes solo después de los picos de uso.
Esta es la razón por la que entender la mecánica de los tokens no es suficiente por sí solo. Los equipos necesitan visibilidad del consumo real de tokens por tarea, por desarrollador y por flujo de trabajo para tomar decisiones de optimización informadas.

La mayoría de los picos en el uso de los tokens de OpenCode no se deben a un solo error evidente. Surgen de la forma en que se usa OpenCode en los flujos de trabajo de ingeniería del mundo real, especialmente cuando las herramientas y los agentes están profundamente integrados en los procesos de desarrollo y automatización.
A continuación se muestran los escenarios más comunes que aumentan desproporcionadamente el consumo de tokens.
Uno de los principales factores que contribuyen al alto uso de los tokens es inclusión de contexto demasiado amplia. Muchos flujos de trabajo de OpenCode incluyen directorios completos o subconjuntos grandes de un repositorio para «estar seguros», incluso cuando solo una pequeña parte del código es relevante.
Entre los ejemplos se incluyen:
Como los tokens de aviso escalan linealmente con el tamaño del contexto, este patrón por sí solo puede multiplicar los costos rápidamente.
OpenCode a menudo funciona de forma iterativa: genera código, revisa, ajusta, regenera. En muchas configuraciones, cada iteración reenvía el contexto completo, incluidos los archivos y las salidas anteriores.
Esto lleva a:
Sin almacenamiento en caché ni reutilización inteligente del contexto, la iteración se convierte en uno de los patrones más caros.
Cuando OpenCode se utiliza mediante agentes o flujos de trabajo automatizados, el uso de los tokens puede aumentar rápidamente si la ejecución no está limitada de forma explícita.
Entre las causas frecuentes se incluyen las siguientes:
Debido a que estos procesos suelen ejecutarse en segundo plano, es posible que los equipos no noten un uso descontrolado hasta que los costos aumenten.
Las tareas de refactorización y revisión tienden a consumir más tokens que la generación de código porque requieren:
Cuando estas tareas se aplican a bases de código de gran tamaño o a múltiples solicitudes de cambios, el uso de los tokens aumenta considerablemente.
El uso de OpenCode integrado en las canalizaciones de CI o los flujos de trabajo de automatización introduce un perfil de riesgo diferente. Estos sistemas:
Incluso el uso modesto de los tokens por ejecución puede resultar caro si se multiplica en muchas compilaciones o implementaciones.
Por último, uno de los factores más ignorados del alto uso de tokens es la ausencia de visibilidad. Cuando los equipos no pueden ver:
La optimización se convierte en conjeturas. Los equipos suelen responder restringiendo el uso a nivel mundial, en lugar de abordar los flujos de trabajo específicos que generan costos.
Una vez que los equipos entiendan de dónde proviene el uso de los tokens, el siguiente paso es la optimización. Es importante destacar que la optimización no consiste en limitar el uso arbitrariamente, sino en usar tokens intencionalmente para que las ganancias de productividad no se conviertan en costos incontrolados.
A continuación se presentan las mejores prácticas que reducen de manera consistente el uso de los tokens de OpenCode sin degradar la calidad de salida.
La palanca de optimización más eficaz es controlar qué contexto se envía al modelo. Más contexto no siempre es mejor, especialmente cuando es irrelevante.
Las técnicas prácticas incluyen:
Una buena regla general: si un archivo no es necesario para motivo del cambio, no debe formar parte del mensaje.
En lugar de enviar grandes cantidades de código por adelantado, los equipos deberían pasar a recuperación bajo demanda.
Ejemplos:
Este enfoque reduce el tamaño de los mensajes y, a menudo, mejora la calidad del razonamiento, ya que el modelo recibe información más específica.
Las indicaciones genéricas tienden a fomentar un razonamiento más amplio y resultados más amplios, lo que aumenta tanto los indicadores de rapidez como de finalización.
Mejores patrones:
Las indicaciones con ámbito de tarea no solo reducen el uso de los tokens, sino que también mejoran el determinismo.
Los flujos de trabajo basados en agentes amplifican el uso de los tokens si no se seleccionan. Todos los agentes deben operar dentro de límites claramente definidos.
Las barandillas clave incluyen:
Sin estos límites, los agentes pueden volver a procesar de forma involuntaria contextos de gran tamaño varias veces, lo que aumenta el uso.
Muchos flujos de trabajo de OpenCode repiten tareas similares entre iteraciones o usuarios. El almacenamiento en caché puede reducir considerablemente el consumo de tokens redundantes.
Escenarios aplicables:
Incluso el almacenamiento en caché parcial a nivel de flujo de trabajo puede generar ahorros significativos.
Si bien los tokens rápidos suelen dominar, los tokens de finalización también son importantes, especialmente en los flujos de trabajo de refactorización o con muchas explicaciones.
Entre las técnicas se incluyen:
Las restricciones de salida claras reducen la verbosidad innecesaria.
Por último, la optimización no debe ser reactiva. Los equipos deben instrumentar el uso de los tokens desde el primer día.
Como mínimo, esto significa rastrear:
Sin estos datos, los equipos no pueden distinguir entre el uso productivo y el desperdicio.
La mayoría de los equipos no tienen problemas con el uso de los tokens de OpenCode desde el primer día. Los problemas surgen gradualmente a medida que su uso se extiende entre los desarrolladores, los repositorios y los flujos de trabajo automatizados. Lo que comienza como una herramienta de productividad individual se convierte rápidamente en infraestructura compartida, y el uso de los tokens aumenta de forma que resulta difícil predecir o gestionar.
A gran escala, un solo desarrollador ya no usa OpenCode en un editor. Lo utilizan:
Cada uno de estos consumidores genera el uso de los tokens de forma independiente. Sin una visión centralizada, resulta difícil responder a preguntas básicas como quién usa los tokens, con qué propósito, y a qué precio.
Los primeros esfuerzos de optimización suelen implementarse en el nivel de la aplicación o la herramienta, los límites de mensajes personalizados, el recorte del contexto o la lógica de reintento. Si bien son útiles a nivel local, no se extienden de forma transversal:
Como resultado, las políticas se vuelven fragmentarias e inconsistentes. Un equipo optimiza agresivamente, mientras que otro aumenta los costos sin saberlo.
La automatización cambia las matemáticas. Un flujo de trabajo que consume una cantidad modesta de tokens por ejecución puede resultar caro si:
Debido a que estos trabajos se realizan sin visibilidad humana directa, las ineficiencias se agravan rápidamente. Los picos de uso de los tokens suelen deberse a la automatización más que al uso interactivo.
Sin una atribución detallada, los equipos solo ven las cifras de uso agregadas. Esto hace que la optimización sea reactiva y contundente.
Los modos de fallo comunes incluyen:
El control efectivo requiere saber qué flujos de trabajo generan valor y cuáles generan residuos algo que las métricas agregadas no pueden revelar.
En muchas organizaciones, la adopción de herramientas de IA supera a la gobernanza. El uso de OpenCode se extiende más rápido que:
Cuando el uso de los tokens se convierte en una preocupación, las herramientas ya están profundamente integradas en los flujos de trabajo, lo que hace que los controles retroactivos sean difíciles y disruptivos.
El problema central no es el mal uso, es uso descentralizado sin control centralizado. A medida que OpenCode se convierte en una infraestructura compartida, el uso de los tokens debe gestionarse de la misma manera que los equipos gestionan los recursos de computación, almacenamiento o CI.
Esto requiere:
Sin este cambio, el uso de los tokens sigue siendo impredecible y los esfuerzos de optimización siguen siendo reactivos.
Una vez que el uso de OpenCode alcanza la escala de producción, el seguimiento ad hoc y las optimizaciones manuales dejan de funcionar. En esta etapa, el uso de los tokens debe tratarse como cualquier otro recurso de infraestructura compartida - se mide de forma continua, se gobierna de forma centralizada y está vinculado a la propiedad.
Muchos equipos comienzan por hacer un seguimiento del uso de los tokens en herramientas o flujos de trabajo individuales. Si bien esto proporciona información local, se desglosa rápidamente cuando:
Cada integración informa sobre el uso de forma diferente y ninguna ofrece una visión holística. Como resultado, los equipos de la plataforma carecen de una única fuente veraz sobre el consumo de tokens.
A gran escala, el monitoreo debe realizarse en nivel de solicitud, no solo el nivel de la herramienta. Las configuraciones efectivas capturan:
Esto permite a los equipos responder a preguntas como:
Sin esta granularidad, los esfuerzos de optimización siguen siendo groseros y, a menudo, mal dirigidos.
La gobernanza comienza con la atribución. El uso de los tokens debe asignarse a los propietarios que puedan actuar en consecuencia.
Los modelos de atribución más comunes incluyen:
Una vez que la propiedad está clara, las conversaciones sobre los costos pasan de la presupuestación abstracta a las decisiones concretas sobre qué flujos de trabajo ofrecen un valor suficiente.
El monitoreo por sí solo no evita los sobrecostos. Los sistemas de producción requieren mecanismos de ejecución que funcionan en tiempo real.
Las barandillas típicas incluyen:
Estos controles deben aplicarse de forma centralizada para que todos los flujos de trabajo impulsados por OpenCode los hereden automáticamente.
El hilo conductor de las configuraciones de gobierno eficaces es centralización. Las políticas de uso, los límites y la visibilidad de los tokens deben estar en un punto de control compartido en lugar de volver a implementarse en todas las herramientas.
Aquí es donde las plataformas orientadas a la infraestructura, como True Foundry encajan de forma natural. Al centralizar el tráfico, la observabilidad y la aplicación de políticas de la IA, los equipos de la plataforma pueden gestionar el uso de los tokens de OpenCode de forma coherente entre desarrolladores, agentes y sistemas automatizados, sin ralentizar a los equipos individuales.
Desde el punto de vista de la plataforma, el principal desafío con el uso de los tokens de OpenCode es no entender cómo los tokens se consumen, pero donde deberían residir el control y la visibilidad.
TrueFoundry aborda este problema tratando el uso de la IA y la LLM, incluidas las herramientas para desarrolladores como OpenCode, como una infraestructura compartida que debe ser observable, gobernable y rentable de forma predeterminada. En el centro de este enfoque se encuentra la Puerta de enlace de IA, que actúa como plano de control para todo el tráfico de LLM de la organización.
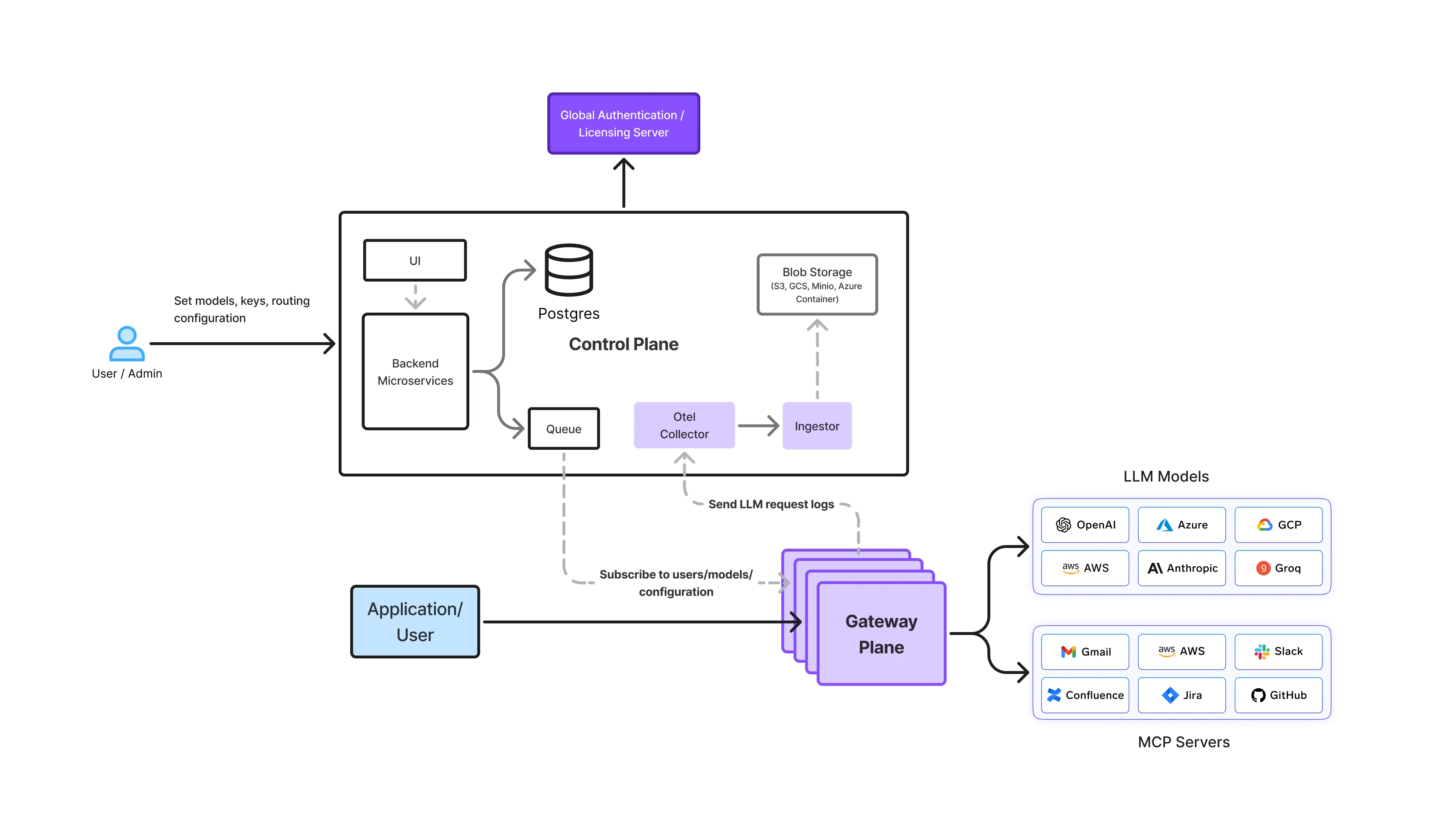
En una configuración de TrueFoundry, OpenCode no interactúa directamente con los proveedores de LLM subyacentes. En cambio, todas las solicitudes fluyen a través del AI Gateway, que proporciona una interfaz única y coherente para la inferencia.
Desde el punto de vista arquitectónico, esto permite:
Al eliminar el acceso directo al modelo de las herramientas individuales, los equipos de la plataforma obtienen una visibilidad total de cómo se usa realmente OpenCode entre los desarrolladores, los agentes y la automatización.
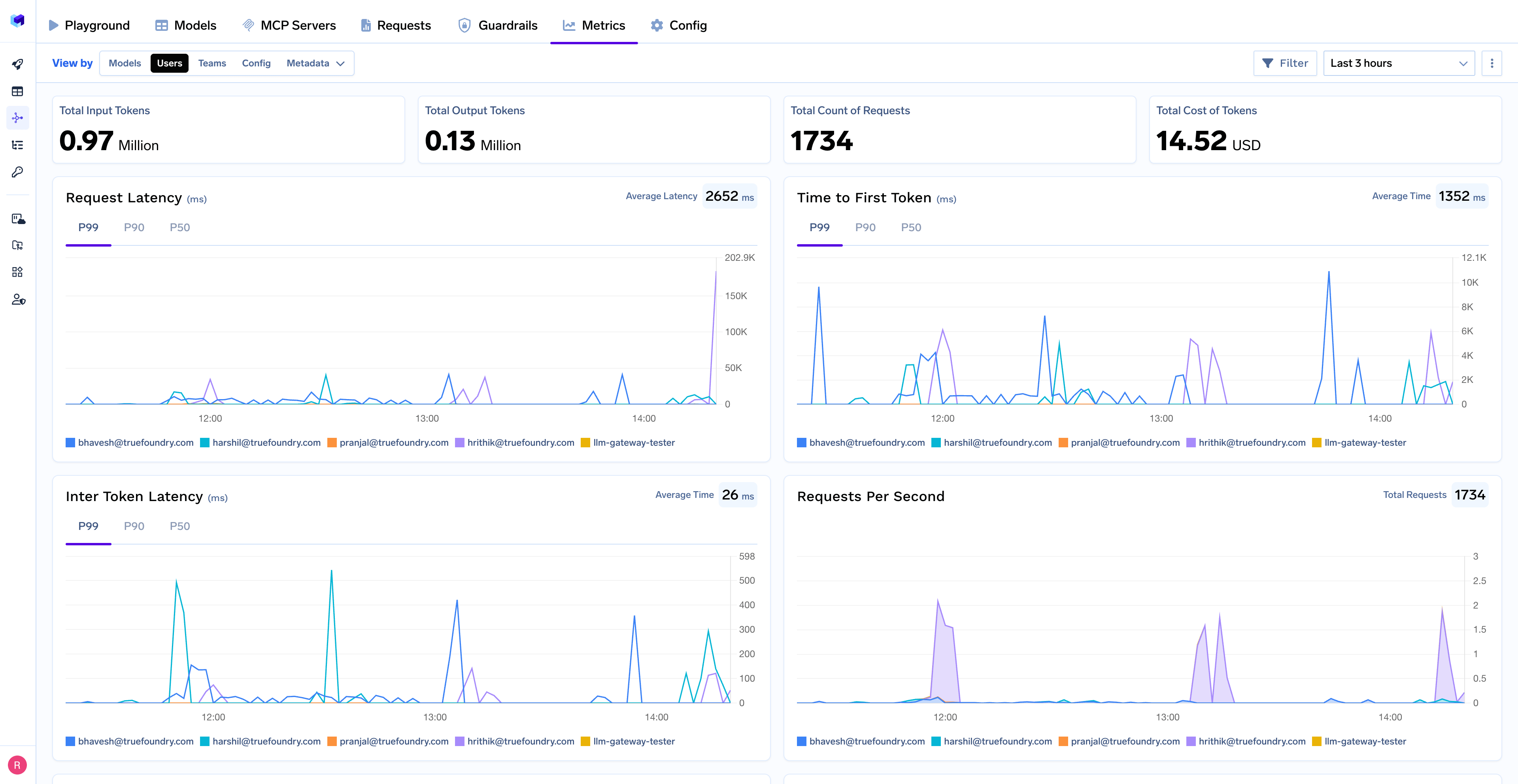
AI Gateway de TrueFoundry captura uso de tokens a nivel de solicitud, que incluye:
Fundamentalmente, esta telemetría no está bloqueada en un sistema controlado por el proveedor. Los registros y las métricas se conservan en la nube y el almacenamiento propios del cliente, lo que permite a los equipos:
Esto evita el problema de la «caja negra» común en las herramientas de IA y hace posible la optimización a largo plazo.
Como todo el tráfico de OpenCode pasa por la puerta de enlace, se pueden aplicar controles de costos. de manera consistente y en tiempo real.
Los equipos de plataforma pueden:
Estas políticas se aplican una vez en la puerta de enlace y se aplican automáticamente a todos los flujos de trabajo impulsados por Opencode sin necesidad de realizar cambios en los editores, complementos o herramientas internas.
La arquitectura de TrueFoundry está diseñada para entornos en los que el uso de OpenCode se extiende más allá del IDE. Las canalizaciones de CI, los trabajos en segundo plano y los agentes suelen generar el mayor y menos visible consumo de tokens.
Al enrutar estas cargas de trabajo a través del mismo AI Gateway, los equipos pueden:
Esto permite escalar el uso de OpenCode en toda la organización sin perder la previsibilidad ni el control.
El uso de tokens OpenCode es la verdadera restricción de escala para la codificación asistida por IA. A medida que el uso se extiende entre los desarrolladores, los repositorios, la automatización y los agentes, el consumo de tokens se vuelve difícil de predecir y controlar sin una visibilidad y una gobernanza centralizadas.
Administrar esto a nivel de herramienta o aplicación no es escalable. El uso de los tokens requiere una observabilidad a nivel de solicitud, una atribución clara y una aplicación en tiempo real, y tratar la codificación asistida por IA como una infraestructura compartida, no como una función aislada.
Plataformas como True Foundry reflejan este enfoque al centralizar el tráfico de OpenCode a través de una puerta de enlace de IA, lo que permite a los equipos monitorear, gobernar y optimizar el uso de los tokens de manera consistente. Para los líderes de plataformas e ingeniería, la conclusión es simple: si OpenCode es fundamental para la creación del software, el uso de los tokens debe gestionarse con el mismo rigor que cualquier otro recurso de infraestructura crítica.
La verificación precisa del uso de los tokens de código abierto requiere un seguimiento e instrumentación explícitos a nivel de solicitud. Dado que las herramientas suelen abstraer todo el contexto que se envía al modelo, obtener visibilidad del consumo real de tokens por tarea, desarrollador y flujo de trabajo es crucial para predecir los costos y optimizar el uso de manera eficaz.
El uso de tokens Opencode es el modelo de precios basado en tokens para herramientas de codificación asistidas por IA como OpenCode. Cada interacción, desde las instrucciones de entrada y el contexto del código hasta el código generado y las explicaciones, consume tokens. Gestionar el uso de estos tokens de código abierto es crucial, ya que se convierte en el principal factor de costes para los equipos de desarrollo de EE. UU.
Para reducir el uso de tokens de código abierto, limita la inyección de contexto solo a los archivos esenciales, evitando la inclusión generalizada de repositorios. Evite la rehidratación repetida del contexto reutilizando los resultados de forma inteligente en todas las iteraciones. Divida las tareas complejas en pasos más pequeños y utilice indicaciones precisas. La supervisión del consumo de fichas para cada tarea proporciona información fundamental para optimizar los costos y la eficiencia.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


