Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
9,9
Cómo pensar en la arquitectura de AI Gateway en la pila de IA generativa
En los sistemas modernos de IA generativa, el Puerta de enlace de IA funciona como capa de proxy crítica entre aplicaciones y proveedores de modelos de lenguaje (LLM). Desempeña un papel fundamental en la gestión de la fiabilidad, la observabilidad, el control de acceso y la rentabilidad de cada solicitud que pasa a la fase de producción.
Porque la puerta de entrada se encuentra en la ruta crítica del tráfico de producción, debe diseñarse teniendo en cuenta los siguientes principios básicos:
Prioridades arquitectónicas clave:
Alta disponibilidad: La puerta de enlace no debe convertirse en un único punto de falla. Incluso en caso de problemas de dependencia (como interrupciones en las bases de datos o en las colas), debe seguir gestionando el tráfico correctamente.
Baja latencia: Dado que se encuentra en línea con cada solicitud de inferencia, la puerta de enlace debe agregar gastos generales mínimos para garantizar una experiencia de usuario ágil.
Alto rendimiento y escalabilidad: El sistema debe escalar linealmente con la carga y ser capaz de gestionar miles de solicitudes simultáneas con un uso eficiente de los recursos.
No hay dependencias externas en la ruta activa: Todas las operaciones vinculadas a la red o a un disco deben descargarse a sistemas asincrónicos para evitar cuellos de botella en el rendimiento.
Toma de decisiones en memoria: Las comprobaciones críticas, como la limitación de velocidad, el equilibrio de carga, la autenticación y la autorización, deben realizarse en la memoria para obtener la máxima velocidad y confiabilidad.
Separación del plano de control y el plano proxy: Los cambios de configuración y la administración del sistema deben desvincularse del enrutamiento del tráfico en vivo, lo que permite las implementaciones globales con aislamiento de fallas regionales.
Arquitectura de puerta de enlace de IA de TrueFoundry
True Foundry Puerta de enlace de IA incorpora todos los principios de diseño anteriores, diseñados específicamente para ofrecer una baja latencia, una alta confiabilidad y una escalabilidad perfecta
Arquitectura Gateway de TrueFoundry
Características clave de la arquitectura AI Gateway
Basado en Hono Framework: La puerta de enlace aprovecha Hono, un marco minimalista y ultrarrápido optimizado para entornos periféricos. Esto garantiza una sobrecarga de tiempo de ejecución mínima y una gestión de solicitudes extremadamente rápida.
Sin llamadas externas en la ruta de solicitud: Una vez que una solicitud llega a la puerta de enlace, no desencadena ninguna llamada externa (a menos que esté habilitado el almacenamiento en caché semántico). Toda la lógica operativa se gestiona internamente, lo que reduce el riesgo y aumenta la fiabilidad.
Aplicación en memoria: Todas las decisiones de autenticación, autorización, limitación de velocidad y equilibrio de carga se toman mediante configuraciones en memoria, lo que garantiza tiempos de respuesta inferiores a un milisegundo.
Registro asincrónico: Los registros y las métricas de solicitudes se envían a una cola de mensajes de forma asincrónica, lo que garantiza que la observabilidad de los datos no bloquee ni ralentice la ruta de la solicitud.
Comportamiento a prueba de fallos: Incluso si la cola de registro externa está inactiva, la puerta de enlace no fallar cualquier solicitud. Esto garantiza el tiempo de actividad y la resiliencia en caso de fallos parciales del sistema.
Escalable horizontalmente: La puerta de enlace está vinculada a la CPU y no tiene estado, lo que facilita la escalabilidad horizontal. Funciona de manera eficiente en condiciones de alta simultaneidad y bajo uso de memoria.
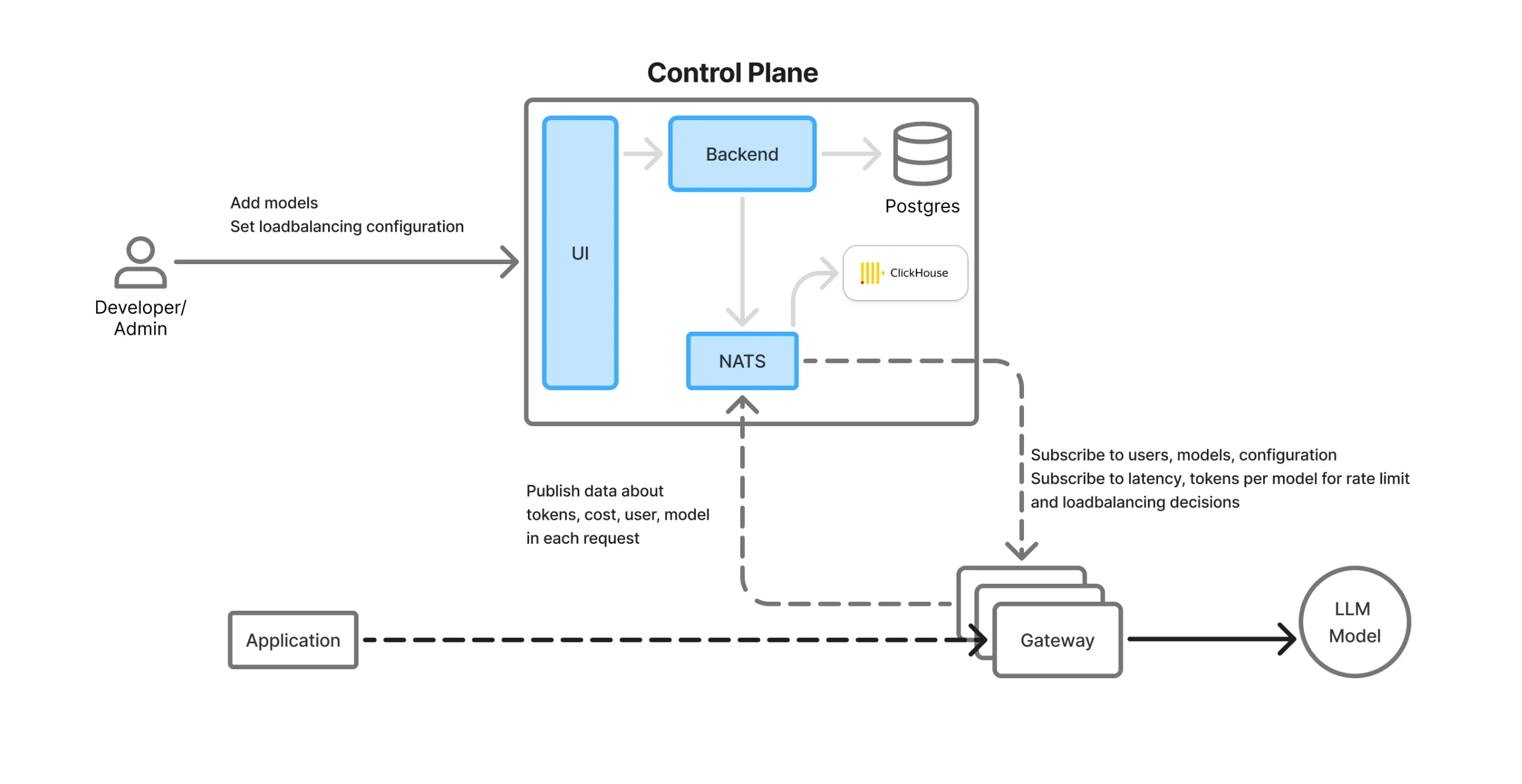
Plano de control y flujo de datos
TrueFoundry separa los plano de control (gestión) desde el plano de datos (enrutamiento del tráfico en tiempo real) para ofrecer escalabilidad y flexibilidad.
Descripción general de los componentes del AI Gateway:
INTERFAZ DE USUARIO: Interfaz web con un área de LLM, paneles de monitoreo y paneles de configuración para modelos, equipos, límites de tarifas, etc.
Base de datos Postgres: Almacena datos de configuración persistentes (usuarios, equipos, claves, modelos, cuentas virtuales, etc.)
Haga clic en House: Base de datos columnar de alto rendimiento utilizada para almacenar registros, métricas y análisis de uso.
Cola NATS: Actúa como un bus de sincronización en tiempo real entre el plano de control y los pods de puerta de enlace distribuidos. Todas las actualizaciones de configuración y estado se envían a través de NATS y están disponibles al instante en todas las regiones.
Servicio de backend: Organiza la sincronización de la configuración, las actualizaciones de las bases de datos y la ingesta de análisis.
Cápsulas Gateway: Proxies livianos, sin estado y dentro de la región que manejan el tráfico real de LLM. Consumen mensajes NATS y ejecutan toda la lógica en memoria, sin dependencias externas.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Puntos de referencia de rendimiento para AI Gateway de TrueFoundry
El Gateway de TrueFoundry se ha comparado minuciosamente para determinar su rendimiento en cargas similares a las de producción:
250 RPS en 1 CPU/1 GB de RAM con solo Latencia añadida de 3 ms.
Se amplía de manera eficiente hasta 350 RPS por pod antes de alcanzar la saturación de la CPU, más allá de la cual puede agregar réplicas.
Soportes decenas de miles de RPS con escalamiento horizontal entre regiones.
Sin latencia adicional incluso con múltiples reglas de límite de velocidad, autenticación y equilibrio de carga.
Por qué es importante
Si ejecuta cargas de trabajo de GenAI a escala o planea integrar varios LLM (OpenAI, Claude, código abierto, etc.), la puerta de enlace se convierte en la base de su paquete.
El diseño de TrueFoundry garantiza:
Puedes enrute y escale de forma segura entre proveedores.
Aplica controles detallados a nivel de usuario/equipo.
Mantenga la observabilidad y la gobernanza en todo el sistema mientras controla la coste de la IA generativa.
Haz todo esto sin afectar a la latencia ni a la fiabilidad.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga

































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


