Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
9,9
Mapeando el mercado de la IA local: desde chips hasta aviones de control
A medida que las empresas introducen GenAI en la producción, muchas están redescubriendo los beneficios de las implementaciones locales, ya sea para reducir los costos de la nube, cumplir con los estrictos requisitos de cumplimiento o ofrecer una latencia ultrabaja. Sin embargo, una pila de IA local no es un dispositivo único que puedas almacenar en un rack y olvidarte. Se trata de un ecosistema estratificado de hardware, orquestación, plataformas de datos y marcos de servicio que deben funcionar en conjunto.
En esta guía, se describe cada capa del conjunto moderno de IA local y se muestra la propuesta de valor de cada componente.
Por qué la IA local está ganando terreno
Las empresas de los sectores financiero, sanitario, manufacturero y gubernamental se enfrentan a normativas de soberanía de datos más estrictas, facturas de nube en aumento y acuerdos de nivel de servicio de nivel de servicio de rendimiento que la nube pública no siempre puede cumplir. Juntas, estas capas forman la base de un plataforma de IA local que las empresas pueden escalar, gobernar y operar independientemente de las restricciones de la nube pública.
Control de datos y cumplimiento: Mantenga los datos confidenciales completamente detrás de su firewall. Cuando los datos se envían a una nube pública, su ubicación física exacta y la jurisdicción legal a la que pertenecen pueden volverse ambiguas, lo que crea importantes riesgos de cumplimiento y complica las auditorías. Una configuración local permite a una organización adaptar todo su arsenal de IA para cumplir con estas normativas, lo que proporciona un marco defendible que cumple con los estándares legales y evita la complejidad de los problemas de transferencia de datos transfronterizos.
Rendimiento y latencia: Ubique el procesamiento y el almacenamiento de forma conjunta para obtener inferencias en tiempo real. Al procesar los datos de forma local, la IA local puede ofrecer una latencia significativamente menor y, lo que es más importante, más predecible. Este rendimiento uniforme y de alto rendimiento es esencial para las aplicaciones que requieren una toma de decisiones instantánea e intermodal, como el análisis de un flujo de datos de sensores y su comparación con los registros históricos. Esta ventaja de rendimiento se extiende a la integración con los sistemas empresariales existentes. Las soluciones locales, debido a su flexibilidad y capacidad de personalización, a menudo se pueden integrar de manera más fácil y confiable con las bases de datos antiguas, los sistemas ERP y otras tecnologías operativas que pueden no ser compatibles con los entornos de nube estandarizados.
Previsibilidad de costos: Pase de tasas variables de pago por uso a inversiones en infraestructura fija. Las tarifas ocultas por la salida de datos, las llamadas a las API, la organización del almacenamiento en niveles y la fluctuación de los precios de la computación pueden erosionar rápidamente los beneficios iniciales de un bajo nivel de capital y generar lo que algunos análisis han denominado «puro derroche» de gastos en la nube. Por el contrario, una implementación local, a pesar de su elevado coste inicial, ofrece un OpEx predecible y gestionable a largo plazo. Para las organizaciones que utilizan la IA de forma sostenida, la infraestructura local suele ser la opción más rentable en un horizonte de tres a cinco años.
Integración personalizada: Conéctese sin problemas a sistemas heredados, dispositivos periféricos o hardware propietario.
Sin embargo, crear y operar este conjunto internamente conlleva gastos de capital, requisitos de talento especializado y gastos generales de mantenimiento continuos.
¿Qué es una pila moderna de IA local?
Una pila de IA local moderna es un sistema complejo de varios niveles en el que cada componente desempeña un papel crucial. No se trata de una entidad monolítica, sino de un ecosistema interdependiente de hardware y software diseñado para ofrecer capacidades de IA sólidas, escalables y eficientes. Comprender este conjunto requiere una deconstrucción capa por capa, desde la infraestructura física que proporciona la potencia bruta hasta las plataformas de alto nivel que permiten el flujo de trabajo de la IA
Cada capa debe diseñarse para maximizar la utilización, garantizar la confiabilidad y permitir un escalado sin problemas, sin tener que depender de un solo proveedor.
Hardware e infraestructura física
Esta es la base de todo el conjunto de IA, la manifestación física del poder computacional. Comprende los motores de cómputos que realizan los cálculos, los sistemas de almacenamiento que contienen los vastos conjuntos de datos y el tejido de red que lo conecta todo. El rendimiento y las limitaciones de esta capa determinan el potencial de todas las capas subsiguientes
Motores de computación
GPUs: Diseñadas originalmente para renderizar gráficos 3D, las GPU se han convertido en el caballo de batalla de la revolución de la IA debido a su arquitectura masivamente paralela. NVIDIA ha establecido una posición dominante en este mercado con sus GPU para centros de datos, como la A100, la H100 y la próxima serie B200. Estos chips, equipados con miles de núcleos especializados (por ejemplo, Tensor Cores), pueden ofrecer un rendimiento para el entrenamiento de la IA hasta 20 veces más rápido que el de las CPU tradicionales. Son el estándar de facto actual para crear clústeres de entrenamiento de IA in situ de alto rendimiento.
CPUs: Si bien las GPU se encargan del pesado trabajo del procesamiento paralelo, las CPU siguen siendo componentes esenciales del servidor de IA. Gestionan las operaciones generales del sistema, gestionan las tareas de procesamiento secuencial y organizan el flujo de datos hacia y desde las GPU. La última generación de CPU multinúcleo de Intel y AMD proporciona la potencia informática de uso general necesaria para soportar los aceleradores especializados
ASIC/TPU: La tendencia emergente y disruptiva en la computación de IA es el auge de los circuitos integrados para aplicaciones específicas (ASIC). Se trata de chips diseñados desde cero para un único propósito: ejecutar cargas de trabajo de IA. Las unidades de procesamiento tensorial (TPU) de Google son un buen ejemplo, ya que están optimizadas para las operaciones matriciales que son la base de las redes neuronales. En el mercado local, una nueva clase de empresas emergentes desafía el monopolio de las GPU con ASIC especializados. Empresas como Crecer están desarrollando chips para inferencias de latencia ultrabaja, mientras Sistemas SambaNova y Cerebras están creando arquitecturas novedosas (unidades de flujo de datos reconfigurables y motores a escala de oblea, respectivamente) que prometen un mayor TCO y una mayor eficiencia energética para el entrenamiento y la inferencia a gran escala. Estos aceleradores especializados representan el futuro del hardware de inteligencia artificial, ya que permiten superar las limitaciones de potencia y coste de las GPU de uso general.
Servidores y almacenamiento empresariales
Servidores de alto rendimiento: Los principales proveedores de hardware empresarial, como Hewlett Packard Enterprise (HPE) con sus líneas ProLiant y Apollo, Tecnologías Dell con sus servidores PowerEdge, Supermicro, y IBM con sus sistemas de alimentación, proporcionan el chasis del servidor para la IA local. No se trata de servidores estándar; están diseñados específicamente para alojar varias GPU de alta potencia, proporcionar enormes cantidades de memoria de alta velocidad (RAM) e incorporar soluciones de refrigeración avanzadas para gestionar la potencia térmica de los aceleradores.
Almacenamiento de alto rendimiento: La IA se alimenta de datos, y la capa de almacenamiento debe proporcionar un acceso rápido y simultáneo a conjuntos de datos masivos sin crear un cuello de botella. Esto requiere ir más allá del almacenamiento tradicional. Soluciones de almacenamiento de alto rendimiento y baja latencia, como SSD NVMe (memoria exprés no volátil) y sistemas de archivos distribuidos son imprescindibles. Los datos en sí mismos suelen organizarse en lagos de datos para almacenar grandes cantidades de datos sin procesar y no estructurados (imágenes, texto, registros) y almacenes de datos para obtener datos estructurados y listos para el análisis. Un componente emergente fundamental, especialmente para la IA generativa, es el base de datos vectorial, que está optimizado para almacenar y consultar las incrustaciones vectoriales de alta dimensión que representan datos no estructurados.
Redes de alta velocidad
InfiniBand y RDMA las estructuras ofrecen hasta 400 Gbps de rendimiento de baja latencia, lo que garantiza que las GPU se mantengan alimentadas con datos durante el entrenamiento distribuido o la inferencia paralela. La capa de red es el «sistema nervioso» del centro de datos de inteligencia artificial, responsable de la transferencia fluida de datos entre los sistemas de almacenamiento y los nodos de procesamiento. En el caso de la IA a gran escala, especialmente en el caso de la formación distribuida, en la que un único modelo se entrena en cientos o miles de GPU, las redes Ethernet estándar son insuficientes y pueden convertirse en un importante obstáculo para el rendimiento. Para evitar que las potentes GPU permanezcan inactivas mientras esperan recibir los datos, los clústeres de IA locales se basan en estructuras de red de gran ancho de banda y baja latencia. Tecnologías como InfiniBand y RDMA (acceso remoto directo a la memoria) son fundamentales. InfiniBand, por ejemplo, puede soportar un rendimiento de hasta 400 gigabits por segundo, lo que garantiza que los datos se puedan mover entre los servidores y el almacenamiento a la velocidad requerida para mantener los motores de procesamiento en pleno uso. Esta interconexión de alta velocidad es un componente no negociable de cualquier infraestructura de IA local seria.
La capa de orquestación y administración
Situada sobre el hardware físico, la capa de orquestación y administración consiste en el software que abstrae, divide y administra los recursos subyacentes. Esta capa transforma una colección rígida de servidores físicos en una plataforma flexible, escalable y eficiente para desarrollar y ejecutar aplicaciones de inteligencia artificial.
El papel de la virtualización y la contenedorización
Las tecnologías fundamentales para la administración de recursos son la virtualización y la contenedorización. Permiten la partición y el aislamiento eficientes de las cargas de trabajo.
Máquinas virtuales (VM): La virtualización ha sido un elemento básico del centro de datos durante décadas. Un hipervisor crea varias máquinas virtuales en un único servidor físico, cada una con su propio sistema operativo completo. Si bien son sólidas y fáciles de entender, las máquinas virtuales ocupan más recursos y tardan más en iniciarse en comparación con los contenedores. Sin embargo, siguen siendo relevantes, especialmente para modernizar las aplicaciones antiguas junto con las nuevas cargas de trabajo de inteligencia artificial. Las plataformas como IBM Fusion y Vates VMS están diseñadas específicamente para proporcionar una plataforma local unificada que pueda gestionar tanto máquinas virtuales como contenedores, a menudo con funciones como la GPU directa.
Contenedores (p. ej., Docker): La contenedorización es el enfoque moderno y ligero para el aislamiento de la carga de trabajo. Un contenedor empaqueta una aplicación y todas sus dependencias (bibliotecas, archivos de configuración) en una sola unidad portátil que comparte el núcleo del sistema operativo anfitrión. Esto se traduce en un espacio mucho más reducido, tiempos de inicio más rápidos y una mayor eficiencia de los recursos que las máquinas virtuales. Para la IA, esto significa que un modelo y su entorno específico se pueden encapsular en un imagen de contenedor inmutable. Luego, esta imagen se puede implementar de manera uniforme en el portátil del desarrollador, en un servidor de pruebas y en el clúster de producción, lo que elimina el problema de que «funcionó en mi máquina» y garantiza la reproducibilidad.
Kubernetes: el sistema operativo de centros de datos de IA
Si bien Docker proporciona el formato contenedor, Kubernetes proporciona la administración a escala. Kubernetes es una plataforma de código abierto que automatiza la implementación, el escalado, la creación de redes y la administración de aplicaciones en contenedores en un clúster de máquinas. Se ha convertido en el estándar indiscutible para la organización de contenedores y es el motor detrás de la mayoría de las aplicaciones nativas de la nube modernas, ya sea en la nube pública o en las instalaciones.
Para la IA local, Kubernetes es el enlace fundamental entre la capa de aplicación y el hardware. Distribuciones de Kubernetes de nivel empresarial como Red Hat OpenShift están diseñados específicamente para despliegues en la nube híbrida y local, y brindan la seguridad, la administración y el soporte que necesitan las empresas.
Los beneficios de usar Kubernetes para las cargas de trabajo de IA son enormes:
Escalado y equilibrio de carga automatizados: Kubernetes puede aumentar o reducir automáticamente la cantidad de réplicas de contenedores en función de la demanda computacional y distribuir las solicitudes de inferencia entre ellas, lo que garantiza una alta disponibilidad y rendimiento.
Gestión de recursos y programación: Kubernetes tiene capacidades de programación compatibles con la GPU, lo que le permite colocar de forma inteligente las cargas de trabajo de IA en nodos que tienen disponible el hardware de aceleración necesario, lo que maximiza la utilización de estos costosos recursos.
Resiliencia y autocuración: Si un contenedor o un nodo fallan, Kubernetes puede reiniciarlo automáticamente o reprogramarlo en un nodo en buen estado, lo que proporciona la resiliencia necesaria para los trabajos de entrenamiento de modelos de larga duración y los servicios de inferencia de misión crítica.
En esencia, Kubernetes proporciona el sistema operativo dinámico, automatizado y resiliente para el centro de datos de IA local.
Habilitación de datos y aprendizaje automático
Plataformas de datos y gobernanza
Esta es la capa de software más alta del conjunto, que contiene las herramientas y plataformas especializadas que los científicos de datos y los ingenieros de aprendizaje automático utilizan para ejecutar el ciclo de vida de la IA de principio a fin. Esta capa aprovecha el hardware y la orquestación subyacentes para administrar los datos y crear, entrenar, implementar y monitorear modelos de IA.
El tejido de datos (plataformas de datos)
Antes de crear cualquier modelo, se deben administrar los datos. Las plataformas de datos proporcionan un entorno unificado para todo el ciclo de vida de los datos, desde la ingestión y el procesamiento hasta el almacenamiento y la gobernanza.
Plataforma de datos (CDP) de Cloudera: Cloudera, un actor dominante en el panorama de los datos locales e híbridos, ha evolucionado desde sus raíces en el ecosistema de Hadoop hasta convertirse en una plataforma integral de datos empresariales. El Nube privada de CDP la oferta está diseñada específicamente para ejecutarse en las instalaciones, normalmente sobre un clúster de Kubernetes como Red Hat OpenShift. Proporciona un sistema unificado Lakehouse de datos abiertos arquitectura que puede gestionar datos estructurados y no estructurados a escala de petabytes. Fundamentalmente para la IA empresarial, integra una seguridad sólida y centralizada mediante Apache Ranger y un marco unificado de gobernanza y metadatos denominado Experiencia de datos compartidos (SDX), garantizando que se apliquen políticas de seguridad coherentes a todos los datos y análisis del entorno híbrido.
Databricks y conectividad híbrida: Si bien Databricks es principalmente una plataforma nativa de la nube, su importancia en el espacio de la IA significa que muchas organizaciones están creando soluciones para conectar sus fuentes de datos locales, como un clúster de Cloudera, a su entorno de Databricks. Esta realidad subraya la naturaleza híbrida de la IA empresarial moderna, donde la gravedad de los datos a menudo requiere mantener grandes conjuntos de datos en las instalaciones y, al mismo tiempo, aprovechar las herramientas basadas en la nube para determinadas tareas de análisis o colaboración.
MLOP y experimentación
Las MLOps (operaciones de aprendizaje automático) son un conjunto de prácticas que tienen como objetivo implementar y mantener los modelos de aprendizaje automático en producción de manera confiable y eficiente. Las plataformas MLOps son las herramientas que permiten estas prácticas, automatizan todo el ciclo de vida del aprendizaje automático y cierran la brecha entre la ciencia de datos (creación de modelos) y las operaciones de TI (ejecutarlos en producción).
Las funciones clave de una plataforma mLOps incluyen: el seguimiento de experimentos (registro de todos los parámetros, métricas y artefactos), el control de versiones y el registro de modelos, la creación de canalizaciones automatizadas de CI/CD (integración continua/implementación continua) para los modelos, la administración de la implementación de los modelos y la supervisión del rendimiento de los modelos para problemas como la desviación de datos.
El mercado local de MLOps presenta una combinación de potentes plataformas comerciales y de código abierto:
Código abierto:MLFlow es una plataforma líder de MLOps de código abierto, ampliamente adoptada por su flexibilidad, su enfoque independiente del marco y sus funciones integrales para el seguimiento de experimentos y la gestión de modelos. Permite a los equipos crear flujos de trabajo de mLOps sólidos sin depender de un proveedor.
Plataformas comerciales: Plataformas gestionadas de extremo a extremo como Robot de datos, Iguazio (adquirido por McKinsey), ofrecen soluciones integrales que cubren todo el ciclo de vida, a menudo centrándose en la facilidad de uso, la automatización y el soporte de nivel empresarial.
Aumente las opciones de plataforma con el RBAC, las barandillas y los presupuestos de AI Gateway de TrueFoundry para garantizar que las políticas se apliquen sin problemas en todos los equipos y modelos
Prestación de servicios y escalamiento de la IA en la producción
Una vez que se entrena y valida un modelo, se debe implementar en un entorno de producción donde pueda recibir datos de entrada y devolver predicciones, un proceso denominado inferencia. La entrega de modelos es una tarea especializada que requiere un software optimizado para un alto rendimiento y una baja latencia.
Servidor de inferencia NVIDIA Triton: Un servidor de inferencia de código abierto de alto rendimiento de NVIDIA. Sus principales puntos fuertes son su capacidad para ejecutar modelos desde prácticamente cualquier marco (TensorFlow, PyTorch, ONNX, etc.) y su capacidad de ejecutar modelos de forma simultánea, lo que permite ejecutar varios modelos o varias instancias del mismo modelo en una sola GPU, lo que maximiza la utilización del hardware.
K Serve: Un estándar para el servicio de modelos en Kubernetes. KServe proporciona una plataforma escalable y ampliable para implementar modelos. Entre sus características más destacadas se incluyen las funciones de inferencia sin servidor (con escalado automático que permite reducir los módulos a cero cuando no están en uso, lo que ahorra recursos) y un «InferenceGraph» que admite estrategias de despliegue avanzadas, como las implementaciones en canarias, las pruebas A/B y los conjuntos de modelos.
Núcleo de Seldon: Otra potente plataforma de servicio de modelos de código abierto para Kubernetes. Seldon Core también es conocida por su sólida compatibilidad con patrones de despliegue avanzados, como las pruebas A/B, los despliegues canarios y los ataques multiarmados (MAB), lo que la convierte en una opción ideal para las organizaciones que necesitan probar y optimizar rigurosamente los modelos en producción.
Otros marcos: El ecosistema también incluye otras poderosas herramientas de código abierto como Pajar, que es un marco para construir oleoductos complejos de agencias y RAG, y Rayo, un motor de cómputos distribuidos que se utiliza a menudo como columna vertebral para el entrenamiento y el servicio de aplicaciones de IA a gran escala.
TrueFoundry funciona como pasarela/control se sitúan por encima de estos servidores, por lo que puede combinarlos (Triton para los modelos CV, vLLM para los LLM, KServe para los bordes sin servidor) y, al mismo tiempo, mantener una capa de interfaz, política y telemetría coherente.
La capa de aplicación y control: AI Gateway y MCP
Las capas descritas hasta ahora proporcionan la base para crear y ejecutar modelos de IA. Sin embargo, para que estos modelos sean accesibles de manera segura y eficiente para las aplicaciones de los usuarios finales y para permitir flujos de trabajo complejos y basados en agencias, se requiere una capa de software final: la capa de aplicación y control. Esta capa actúa como el sistema nervioso central para todas las interacciones de la IA, proporcionando gobernanza, seguridad y una interfaz estandarizada para la comunicación. Consta de dos componentes críticos y emergentes: la puerta de enlace de inteligencia artificial y el protocolo de contexto modelo (MCP).
La puerta de enlace de IA: un plano de control centralizado
Un AI Gateway es un middleware especializado que sirve como un punto de control único y centralizado para todo el tráfico relacionado con la IA entre las aplicaciones y los modelos de IA subyacentes. Al implementarse en el entorno local, a menudo en Kubernetes, proporciona un conjunto fundamental de funciones para gestionar la IA a escala empresarial.
Acceso unificado y enrutamiento inteligente: La puerta de enlace ofrece un punto final de API único y coherente para los desarrolladores, lo que elimina la complejidad de interactuar con varios modelos diferentes (por ejemplo, una combinación de modelos de código abierto ajustados y modelos comerciales especializados). Puede realizar un enrutamiento basado en el contexto, dirigiendo las solicitudes al modelo más apropiado en función de factores como el costo, los requisitos de rendimiento o el caso de uso específico, optimizando tanto la eficiencia como los resultados.
Seguridad y gobernanza sólidas: Para la IA local, la seguridad es primordial. El AI Gateway actúa como un punto de aplicación de políticas y se integra con la arquitectura de seguridad empresarial para gestionar la autenticación, la autorización y el control de acceso basado en roles (RBAC). Inspecciona tanto las indicaciones entrantes como las respuestas salientes en tiempo real para evitar ataques rápidos y la filtración de datos confidenciales, como la información de identificación personal (PII), y garantizar el cumplimiento de normativas como el RGPD y la HIPAA.
Observabilidad y control de costos integrales: La puerta de enlace proporciona un panel unificado para monitorear todas las interacciones de la IA y rastrear métricas clave como la latencia, las tasas de error y el uso de tokens. Esta capacidad de observación centralizada es crucial para la resolución de problemas y la optimización del rendimiento. Además, permite un control granular de los costos al aplicar presupuestos de uso y límites de tarifas basados en fichas, lo que evita los costos desorbitados y permite reembolsar cargos precisos a las diferentes unidades de negocio.
El protocolo de contexto modelo (MCP): el lenguaje universal para los agentes de IA
Mientras que AI Gateway gestiona el flujo de solicitudes, el Model Context Protocol (MCP) es un estándar abierto que revoluciona qué esas solicitudes pueden funcionar. MCP proporciona una forma estandarizada para que los modelos de IA descubran herramientas, datos y servicios externos e interactúen con ellos, lo que los convierte de «cerebros» aislados en agentes capaces e integrados.
Una interfaz estandarizada para herramientas: En lugar de crear un código frágil y personalizado para cada integración, MCP permite que los sistemas empresariales (como bases de datos, CRM o API internas) anuncien sus capacidades a través de un «servidor MCP» ligero. La aplicación de IA, que actúa como un «host MCP», puede entonces consultar estos servidores para saber qué herramientas están disponibles y cómo usarlas, creando de manera efectiva un ecosistema listo para usar para los agentes de IA.
Habilitación de la IA de agencia local: Una ventaja clave de MCP es que es un protocolo abierto y auditable que se puede implementar por completo dentro del firewall de una organización. Esto permite a las empresas crear agentes de inteligencia artificial potentes y autónomos que puedan interactuar de forma segura con los sistemas internos patentados sin exponer los datos confidenciales a los servicios externos.
Prevención del bloqueo de proveedores: Dado que MCP es un estándar independiente del modelo compatible con actores importantes como Anthropic, OpenAI y Microsoft, desvincula el modelo de IA de las integraciones de herramientas. Esto brinda a las empresas la flexibilidad de cambiar el LLM subyacente (por ejemplo, pasar de una API comercial a un modelo optimizado y autohospedado) sin tener que reconstruir todo el sistema de integración, preservando así la soberanía tecnológica.
Juntos, AI Gateway y MCP forman una potente capa de control y aplicación que hace que la IA local no solo sea posible, sino que también sea segura, administrable y verdaderamente integrada en la estructura de la empresa.
El MCP Gateway de TrueFoundry combina la gobernanza y la observabilidad para cada solicitud, además de una llamada segura y auditada a las herramientas a través de MCP para que los agentes puedan actuar en sus sistemas internos sin que los datos salgan de su red.
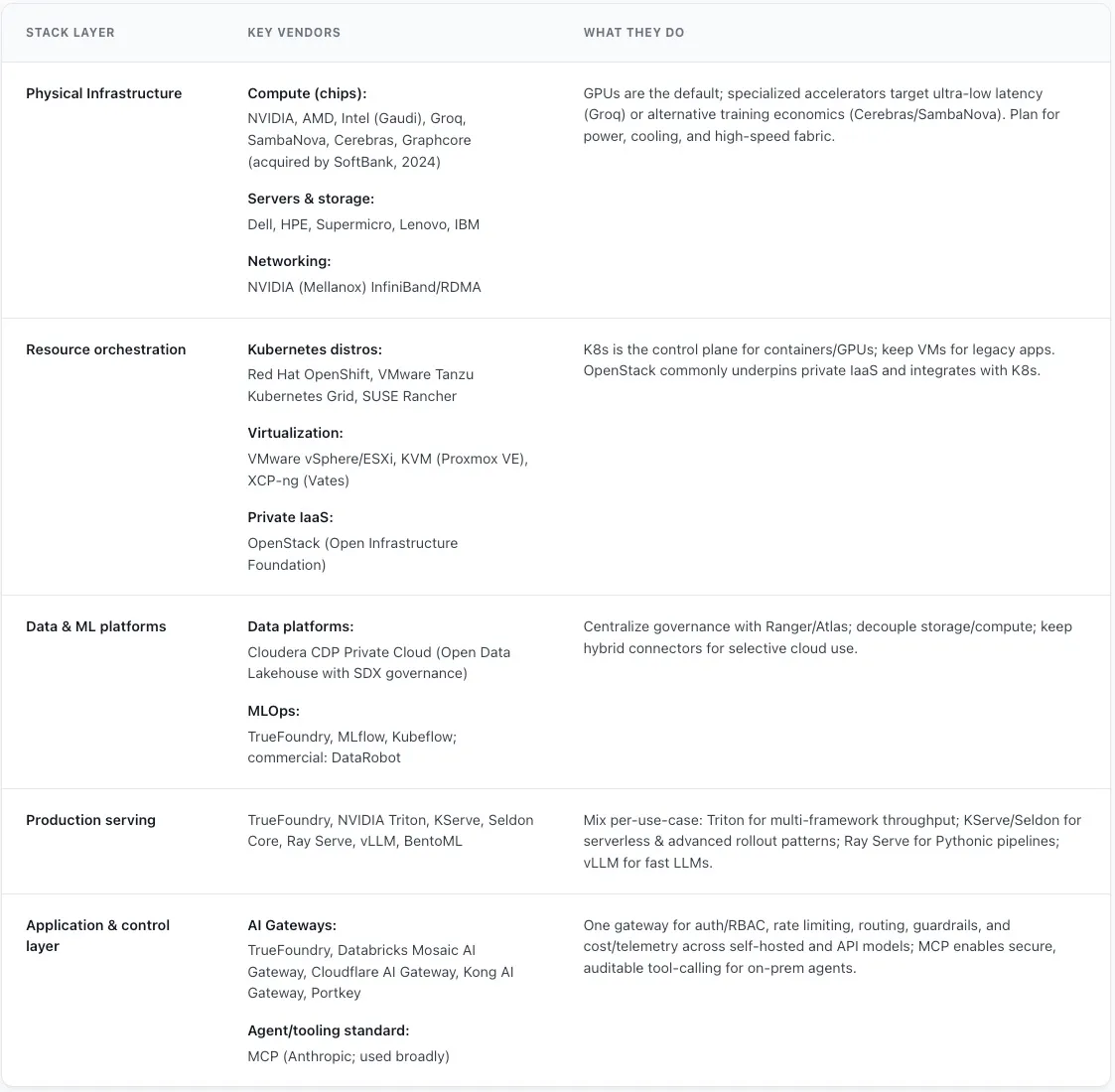
Mapeo de proveedores en todo el conjunto de IA local
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga

































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


