

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
El ajuste fino es una técnica que se utiliza en el aprendizaje automático, especialmente en el aprendizaje profundo, en la que un modelo previamente entrenado se entrena más o se «ajusta» en un conjunto de datos más pequeño y específico adaptado a una tarea en particular.
Supongamos que está desarrollando un modelo que genera manuales técnicos para electrónica utilizando GPT-3 (un modelo de lenguaje grande con 175 mil millones de parámetros), pero la salida genérica del GPT-3 no cumple con la precisión técnica y el tono requeridos.
En este caso, puede pensar en volver a entrenar el modelo para su caso de uso específico, pero entrenar directamente un modelo como el GPT-3 desde cero para abordar esta tarea específica no es práctico debido a los requisitos de recursos computacionales y los datos especializados.
Aquí es donde entra en juego el ajuste fino.
El ajuste fino es como enseñarle un truco nuevo al GPT-3. Ya sabe mucho sobre idiomas gracias a su formación en numerosos textos, desde libros hasta sitios web. Su trabajo consiste en seguir capacitándolo en un conjunto de datos específico, en este caso, un corpus de manuales técnicos existentes y documentación específica sobre electrónica.
Algunos métodos básicos de ajuste:
El ajuste preciso con eficiencia de parámetros (PEFT) es una técnica destinada a minimizar la cantidad de parámetros adicionales necesarios durante el ajuste fino de los modelos de redes neuronales previamente entrenados,
Esto ayuda a reducir los gastos computacionales y el uso de memoria, a la vez que mantiene o incluso mejora el rendimiento. PEFT logra esto añadiendo incrustaciones rápidas como parámetros adicionales del modelo y ajustando solo una pequeña cantidad de parámetros adicionales.
Los PEFT también requieren un conjunto de datos mucho más pequeño en comparación con el ajuste fino tradicional.
Carga el modelo elegido con un marco de aprendizaje automático como TensorFlow, PyTorch o la biblioteca Transformers de Hugging Face. Estos marcos proporcionan API para descargar y cargar fácilmente modelos previamente entrenados.
Este es un ejemplo de código:
Antes de realizar ajustes, debe experimentar con diferentes indicaciones para guiar las respuestas del modelo. Pruebe varias indicaciones con el modelo previamente entrenado para ver cómo afectan al resultado y elija la más adecuada. También puedes cambiar diferentes parámetros como max_length, temperature, etc.
Es como encontrar la mejor manera de hacer una pregunta para que la modelo comprenda lo que quieres.
En un conjunto de datos para realizar ajustes, normalmente hay dos partes: preguntar (entrada) y responder (salida). La pregunta es como una pregunta o un punto de partida, y la respuesta es lo que quieres que genere el modelo en respuesta a esa pregunta. Puede tener la forma de columnas o de una secuencia de entradas de texto (lo más común).
Aquí se utilizará el mejor indicador identificado en el último paso y la respuesta será exactamente lo que queremos que produzca el modelo cuando se le dé ese mensaje.
Aquí es donde le enseñas a la modelo a mejorar en tu tarea. Usarás el conjunto de datos para ajustar ligeramente el «conocimiento» del modelo.
Esta es una descripción general simplificada de la configuración y ejecución del proceso de ajuste con PyTorch:
de transformers import AdamW
optimizer = adamW (model.parameters (), lr=5e-5) # lr es la tasa de aprendizaje
Al explorar las herramientas para una ingeniería rápida, es útil clasificarlas en dos dominios principales: plataformas de código y plataformas sin código. Esta distinción simplifica el proceso de selección
Las plataformas de código se refieren a las plataformas que proporcionan máquinas virtuales que se pueden usar para ejecutar su script de Python personalizado para realizar ajustes como el mencionado anteriormente. Mientras tanto, las plataformas sin código se refieren a herramientas que requieren un script de Python simple o nulo para ejecutarse. Cuenta con una interfaz de usuario dedicada en la que puedes empezar a entrenar con unos pocos clics.
Las plataformas sin código, por otro lado, están diseñadas para ofrecer simplicidad y facilidad de uso. Eliminan la necesidad de escribir scripts en Python y ofrecen una interfaz de usuario intuitiva en la que se puede iniciar el entrenamiento con solo unos pocos clics. Este dominio es adecuado para usuarios sin conocimientos de programación o para aquellos que prefieren un enfoque sencillo para la ingeniería rápida.
True Foundry es una herramienta que ayuda a los equipos de aprendizaje automático a poner en marcha sus modelos sin problemas. Se basa en Kubernetes, lo que significa que puede ejecutarse en diferentes nubes o incluso en tus propios servidores. Esto es importante para las empresas preocupadas por mantener sus datos seguros y controlar los costos
Para el ajuste fino, es una de las mejores herramientas que existen, tanto para principiantes como para expertos. Aquí tiene dos opciones: implementar un portátil de ajuste fino para experimentar o iniciar un trabajo de ajuste específico.
Los ordenadores portátiles ofrecen una configuración ideal para realizar ajustes detallados exploratorios e iterativos. Puede experimentar con un pequeño subconjunto de datos y probar diferentes hiperparámetros para determinar la configuración ideal para obtener el mejor rendimiento.
Una vez que haya identificado los hiperparámetros y la configuración óptimos mediante la experimentación, la transición a un trabajo de implementación le ayuda a ajustar todo el conjunto de datos y facilita una capacitación rápida y confiable.
Por lo tanto, se recomienda encarecidamente utilizar ordenadores portátiles para la exploración en las primeras etapas, y los trabajos de ajuste e implementación de hiperparámetros son la opción preferida para el ajuste fino de la LLM a gran escala, especialmente cuando la configuración óptima se ha establecido mediante experimentos previos.
Esta es una guía paso a paso para perfeccionar el uso de Notebook y Jobs:
Truefoundry admite dos formatos de datos diferentes:
Cada línea contiene una clave llamada mensajes. Cada clave de mensaje contiene una lista de mensajes, donde cada mensaje es un diccionario con claves de función y contenido. La clave de rol puede ser de usuario, asistente o sistema, y la clave de contenido contiene el contenido del mensaje.
2. Ajuste fino
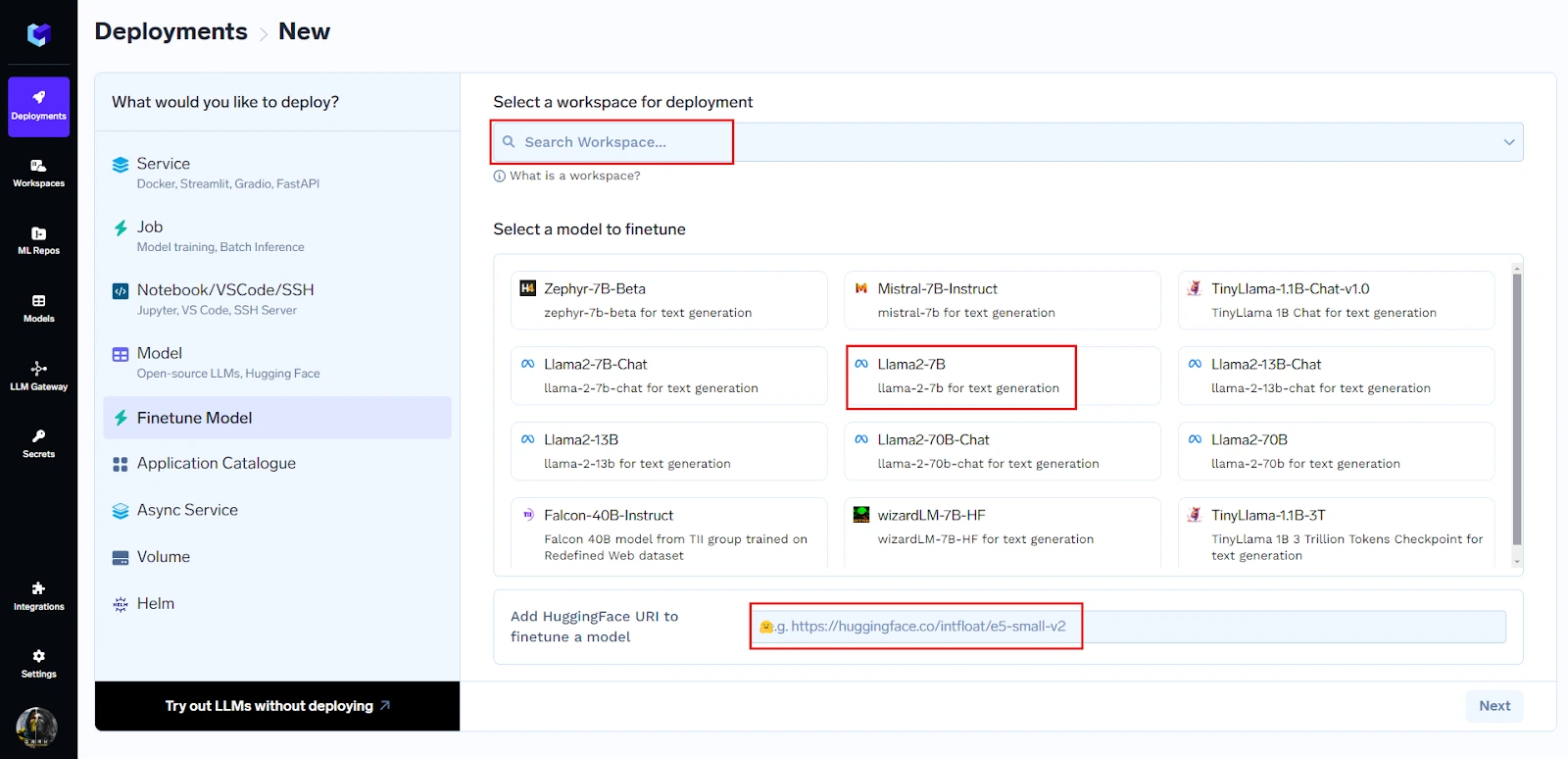
Puede comenzar a realizar ajustes con solo tres clics:
Puede elegir el modelo de la lista completa presente o simplemente puede pegar la URL de huggingface para comenzar a ajustarlo.
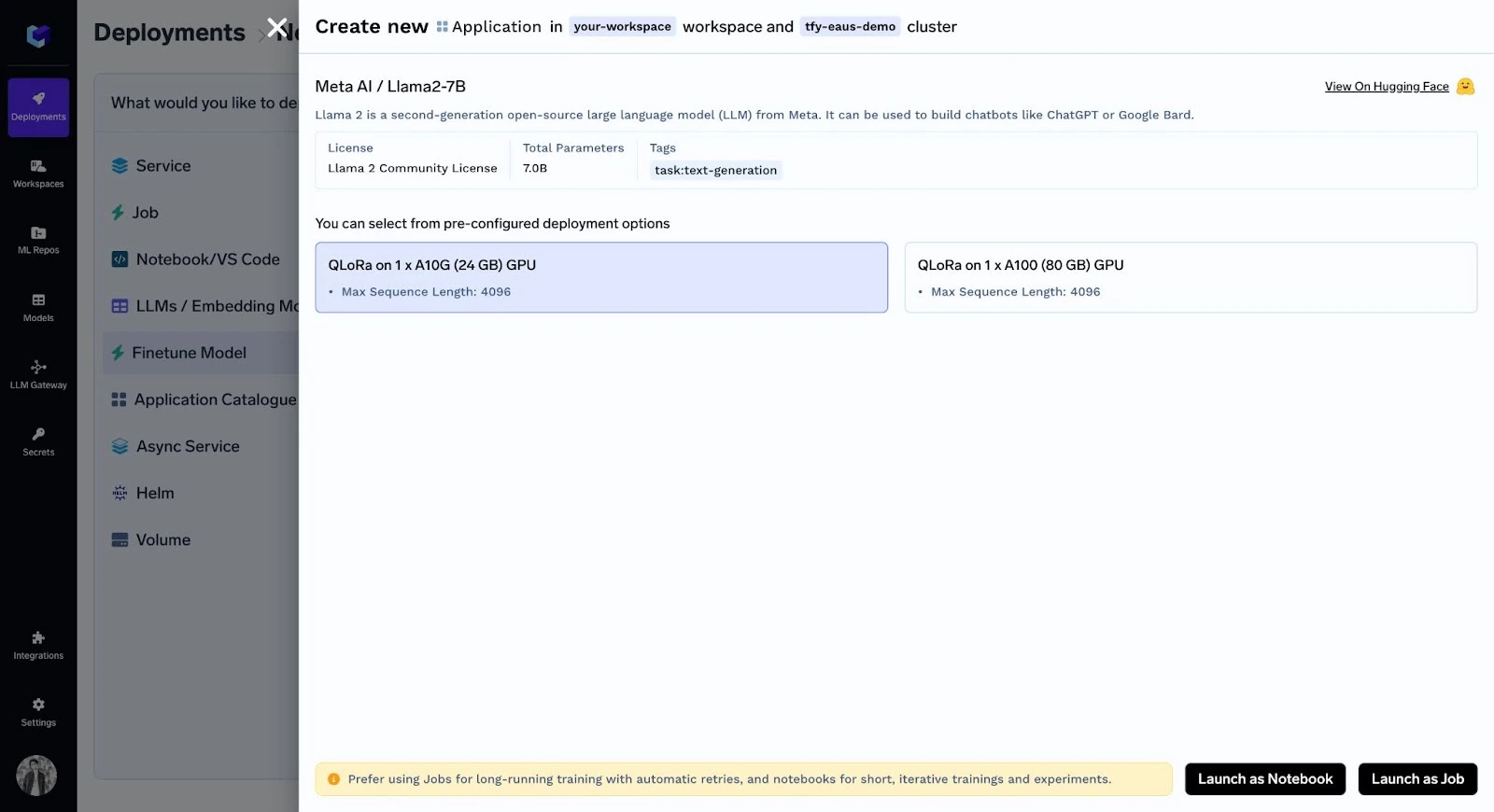
Ahora, después de seleccionar la GPU deseada, tiene dos opciones: Ejecutar como portátil o Job.
3. Ajuste fino con un portátil
Tras seleccionar «Iniciar como bloc de notas» y seleccionar los valores predeterminados para los hiperparámetros, puede ver su bloc de notas:

4. Afinar como trabajo:
Antes de empezar, primero tendrás que crear un repositorio de ML (que se utilizará para almacenar tus métricas y artefactos de entrenamiento, como tus puntos de control y modelos) y dar acceso a tu espacio de trabajo al repositorio de ML. Puedes obtener más información sobre los repositorios de ML en la documentación de Truefoundry.
Ahora tiene que elegir «Iniciar como tarea» y seleccionar los valores predeterminados de los hiperparámetros para iniciar el ajuste fino.
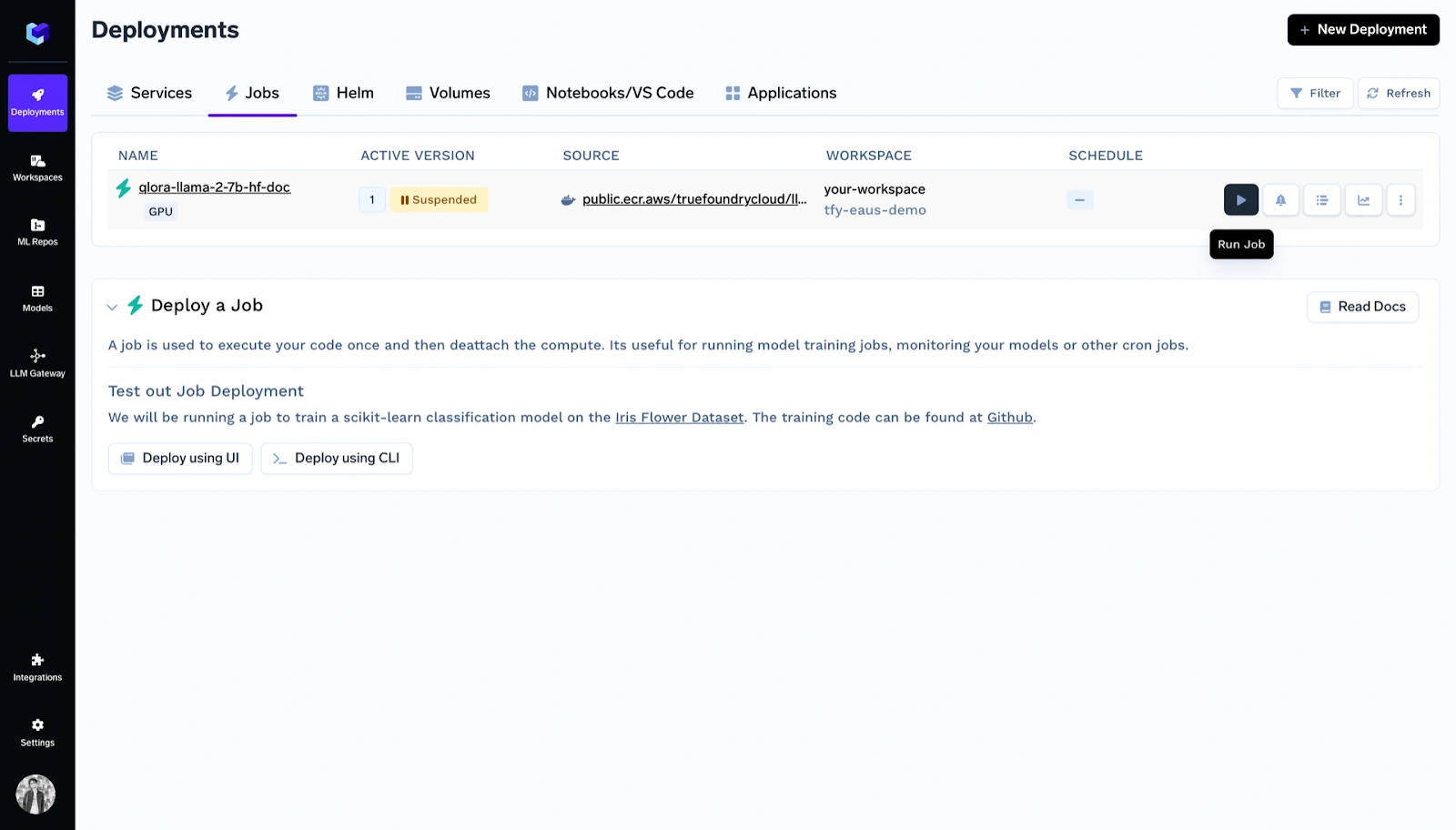
Dentro de las implementaciones, puede ver la lista de tareas y hacer clic en ejecutar la tarea.
Características principales:
La API OpenAI proporciona acceso a modelos avanzados de inteligencia artificial desarrollados por OpenAI, incluidas las últimas versiones de GPT (Generative Pre-trained Transformer). Una de las características más destacadas de la API OpenAI es su capacidad para ajustar los modelos en conjuntos de datos personalizados.
De este modo, puede adaptar el comportamiento de modelos como el GPT-3 o las versiones más recientes a aplicaciones específicas o a estilos y preferencias de contenido particulares.
Ya que me refiero a la API, no es exactamente «Sin código», aun así, se puede configurar fácilmente para el entrenamiento en comparación con otras herramientas de la sección anterior.
Código de ejemplo para un ajuste fino:
Para ajustar un modelo, primero debes preparar tu conjunto de datos en un formato que la API de OpenAI pueda entender. Por lo general, tendrías que crear un archivo JSON con el siguiente aspecto:
Puede cargar fácilmente el conjunto de datos mediante Open AI CLI (interfaz de línea de comandos).
openai tools fine_tunes.prepare_data -f your_dataset.jsonl
Una vez que el conjunto de datos esté preparado y cargado, puede iniciar un proceso de ajuste. El siguiente es un ejemplo en el que se utiliza la biblioteca Python de OpenAI:
Una vez finalizado el proceso de ajuste, puede usar su modelo ajustado para generar texto u otras tareas especificando el ID del modelo ajustado:
También puede implementar su modelo perfeccionado.
Características principales:
Microsoft Azure es una plataforma de computación en la nube que ofrece una amplia gama de servicios, que incluyen computación, almacenamiento, análisis y más. Proporciona a los usuarios las herramientas para crear, implementar y administrar aplicaciones de manera eficiente.
Una característica destacable es su interfaz intuitiva, que facilita la navegación de los principiantes sin tener amplios conocimientos de codificación. Con unos simples clics en lugar de una codificación compleja, los usuarios pueden ajustar sus aplicaciones con precisión, lo que convierte a Azure en una herramienta accesible para un desarrollo sin estrés.
Este es un tutorial sencillo sobre cómo configurar un «trabajo» de ajuste en Azure:
Obviamente, este es el requisito básico para todas las herramientas. Los datos de entrenamiento pueden estar en formato JSON Lines (JSONL), CSV o TSV. Los requisitos de tus datos varían en función de la tarea específica para la que pretendas ajustar tu modelo.
Para la clasificación de texto:
Dos columnas: Oración (cadena) y Etiqueta (entero/cadena)
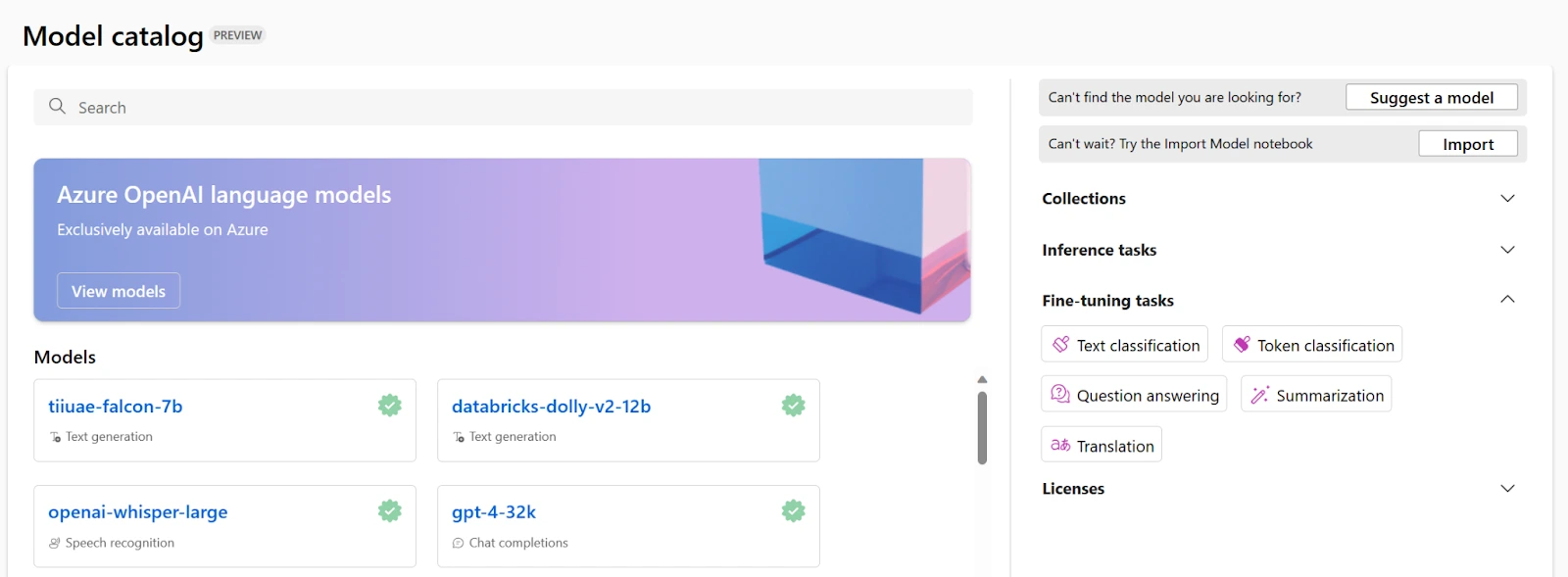
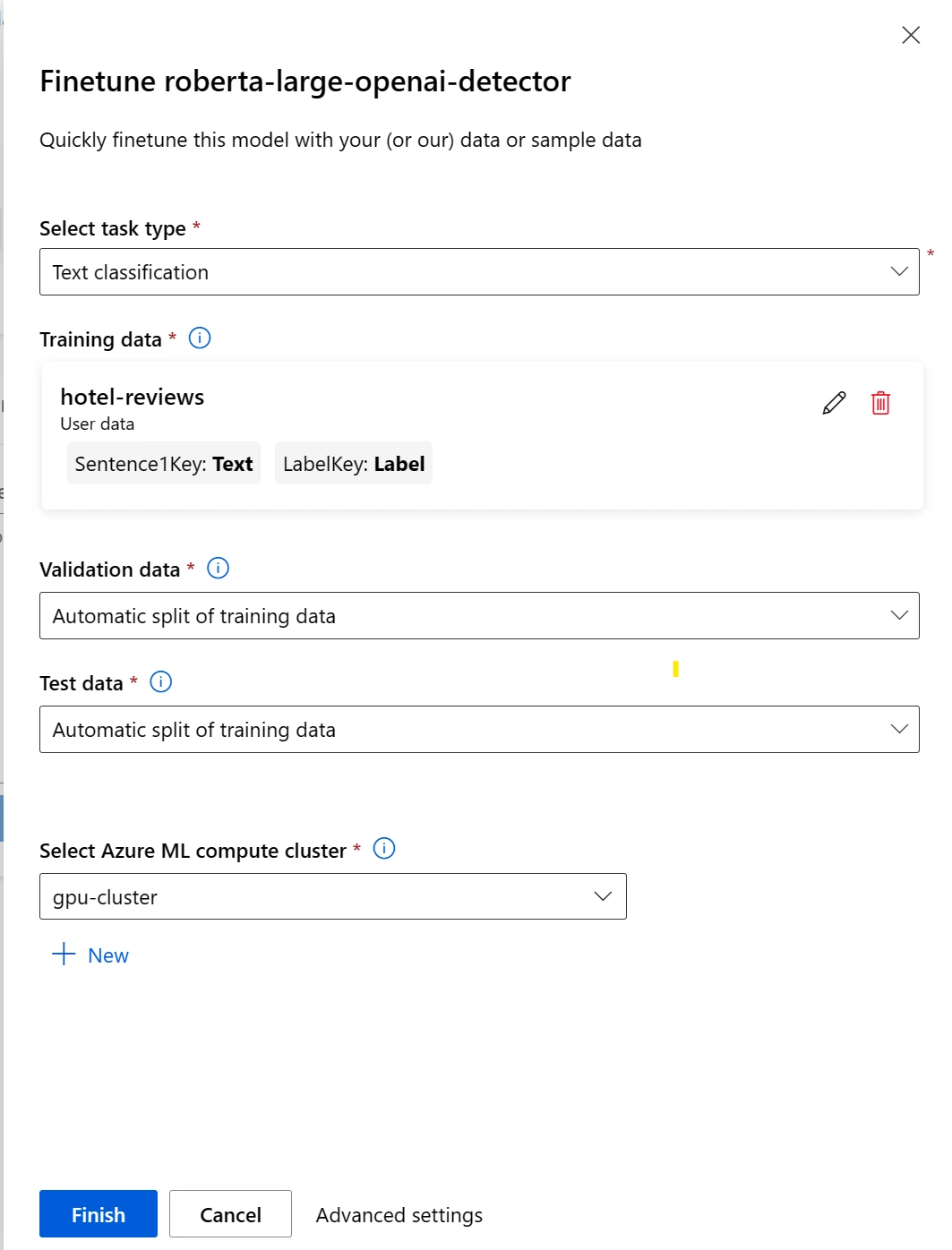
Después de enviar el trabajo de ajuste, se creará un trabajo de canalización para entrenar el modelo. Puede revisar todas las entradas y recopilar el modelo a partir de los resultados del trabajo.
Para decidir si su modelo ajustado funciona según lo esperado, puede revisar las métricas de entrenamiento y evaluación.
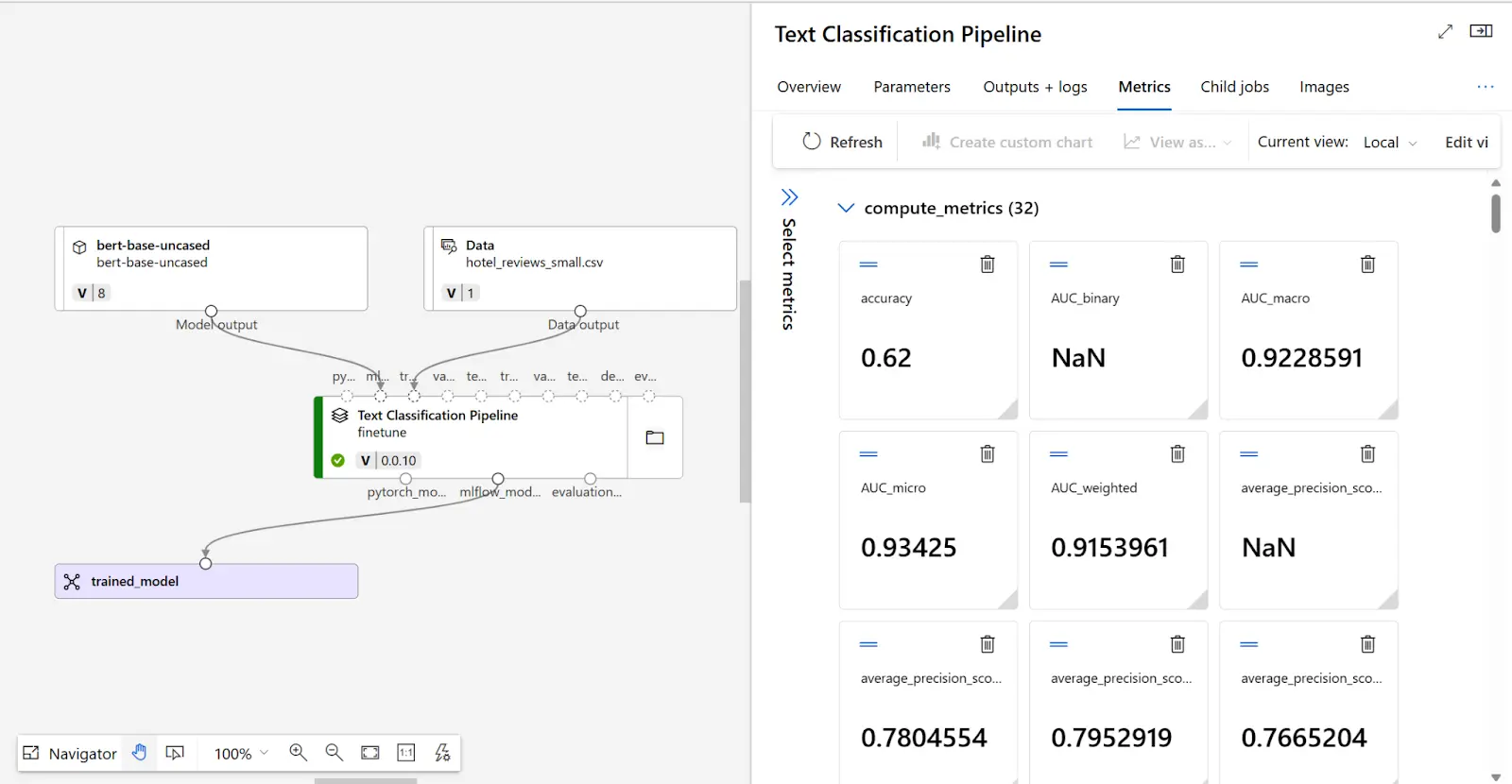
Características principales:
Replicate es una herramienta versátil diseñada para ajustar varios aspectos de las aplicaciones de software. Las aplicaciones de Replicate como herramienta de ajuste fino incluyen la optimización del rendimiento, el ajuste de las configuraciones y la mejora de la funcionalidad con un mínimo esfuerzo. Simplifica el proceso al gestionar la configuración de la GPU. Al igual que la API Open AI, no es exactamente «sin código» como otras herramientas de la lista, pero se puede configurar fácilmente para el entrenamiento en comparación con otras herramientas de la sección anterior.
Los datos de entrenamiento deben estar en formato JSONL. A continuación se muestra un ejemplo de cómo puedes estructurar este archivo:
Debes configurar tu token de API de Replicate como una variable de entorno en tu terminal:
exportar REPLICATE_API_TOKEN= <your-token-here>
Puedes subir tus datos a un bucket de s3 o directamente a Replicate mediante los comandos curl:
Debe crear un modelo vacío en Replicate para su modelo entrenado. Cuando termine tu entrenamiento, se publicará como una nueva versión de este modelo.
Debes crear un trabajo de formación en tu IDE, como se muestra a continuación:
Para supervisar el progreso mediante programación, puede utilizar:
Una vez finalizada la formación, puede ejecutar su modelo con la API:
Características principales:
En Gen AI Studio, tienes ambas opciones para configurar trabajos de ajuste, a través de la API o del sitio web, aquí hablaré solo del método API. Tiene el proceso más simplificado en comparación con las herramientas mencionadas anteriormente.
El conjunto de datos debe estar en formato JSONL, y cada línea debe ser un objeto JSON con las claves «input_text» y «output_text». Puede empezar a entrenarse con solo 10 ejemplos, pero se recomiendan al menos 100 ejemplos.
Debes subir tu conjunto de datos al depósito de Google Cloud Storage (GCS). Si no tienes uno, puedes crear uno en Google Drive.
Ahora tiene que proporcionar sus credenciales para establecer la conexión:
Debe definir una función para ajustar con los parámetros necesarios.
Llame a la función de ajuste especificada anteriormente, con sus parámetros específicos. El parámetro training_data puede ser una URI de GCS o un DataFrame de Pandas.
Características principales:
Predibase es una plataforma especializada diseñada para facilitar el ajuste de grandes modelos lingüísticos (LLM), como el GPT-4, para tareas o aplicaciones específicas. Proporciona acceso a las capacidades avanzadas de los LLM al proporcionar un entorno simplificado y fácil de usar para personalizar estos modelos de acuerdo con las necesidades individuales.
Predibase le ofrece la opción de usar tanto el SDK como la interfaz de usuario de Python para realizar trabajos de ajuste.
Esta es una guía paso a paso para ajustar mistral-7b-instruct:
Primero, regístrese para obtener una cuenta en Predibase y deposite para agregar créditos. Después, genere su clave de API.
Vaya a Modelos y, a continuación, haga clic en «Nuevo repositorio de modelos» como se muestra a continuación:
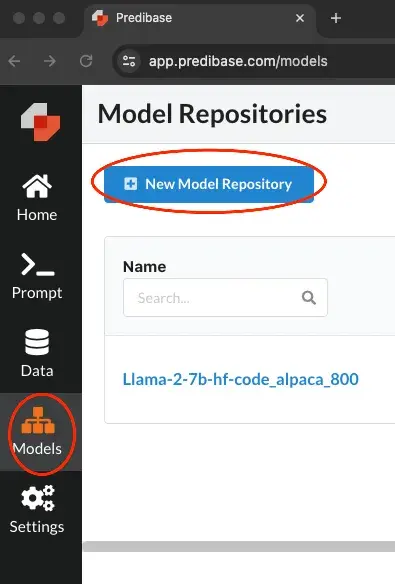
Ahora, asigne un nombre a su repositorio y añada una descripción.
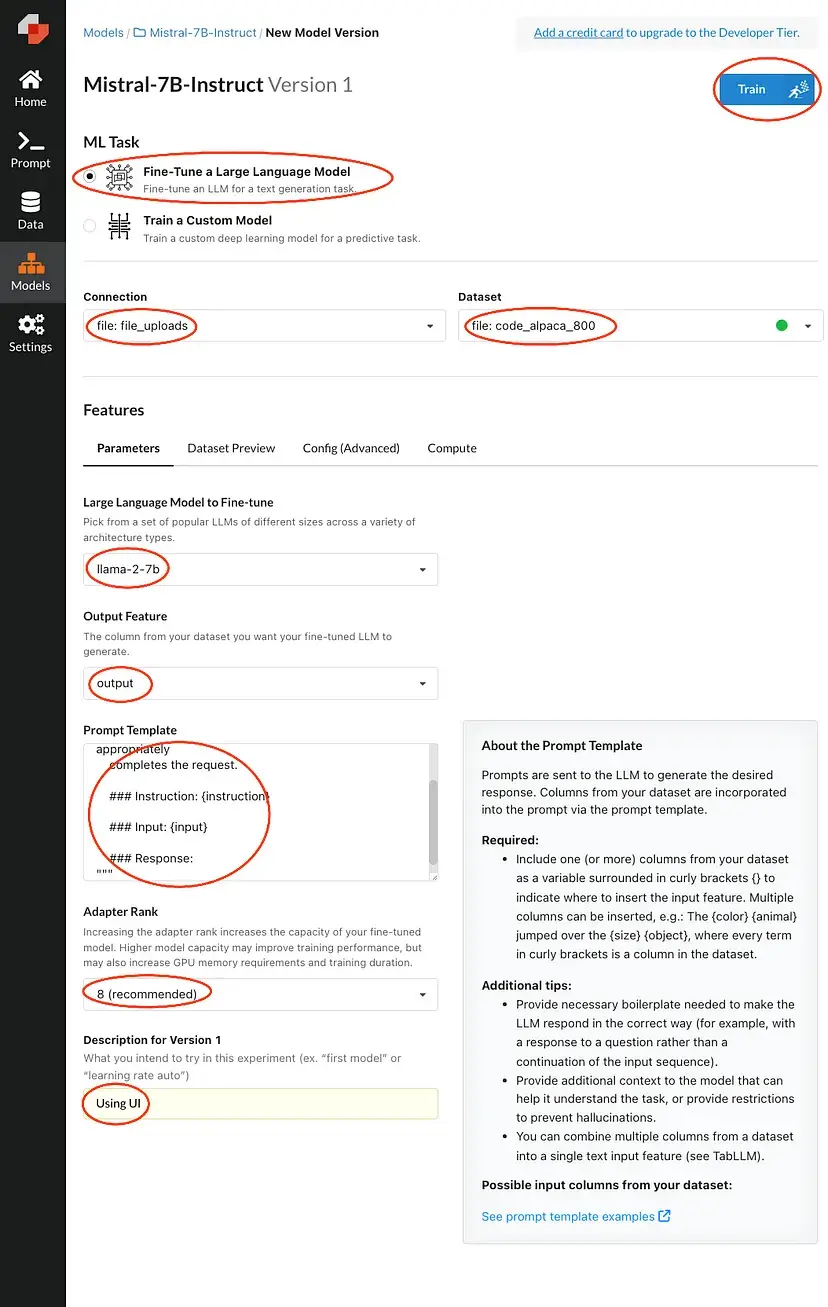
Rellene las áreas resaltadas y, a continuación, pulse entrenar. Esto hará que tu solicitud quede en cola hasta que haya un procesamiento disponible.
Las plataformas de código están diseñadas para usuarios con una sólida formación en programación. Estas plataformas proporcionan máquinas virtuales que permiten ejecutar scripts de Python personalizados para tareas como el ajuste. Estas plataformas son perfectas para proyectos que exigen una alta personalización y un control complejo de las fases de formación e implementación.
Amazon SageMaker es un servicio totalmente administrado que brinda a los desarrolladores y científicos de datos la capacidad de crear, entrenar e implementar modelos de aprendizaje automático con rapidez.
Amazon SageMaker no cuenta con una función de «ajuste» dedicada e integrada etiquetada específicamente como tal para modelos lingüísticos de gran tamaño. En su lugar, proporciona una plataforma potente y flexible que le permite ejecutar scripts de Python personalizados para realizar tareas de ajuste.
Este es un ejemplo sencillo de cómo puede iniciar un trabajo de ajuste para un modelo de lenguaje con Hugging Face en SageMaker. Esto supone que ya ha configurado una cuenta de AWS y la CLI de AWS. (puede usar TensorFlow o PyTorch directamente en Amazon SageMaker para ajustar las tareas)
Por lo general, escribirías un script de ajuste (train.py) que pasarías al estimador. Este script debe incluir la lógica de carga, ajuste y guardado del modelo.
Características principales:
Google Colab es un popular servicio de cuadernos Jupyter basado en la nube que ofrece acceso gratuito a los recursos informáticos, incluidas las GPU y las TPU, lo que lo convierte en una plataforma excelente para ajustar los modelos lingüísticos grandes (LLM)
Es especialmente apto para principiantes. Los cuadernos Colab se ejecutan en la nube, directamente desde su navegador, sin necesidad de ninguna configuración local.
Este es el sencillo fragmento de código para ajustar un modelo de Transformer con Hugging Face, Transformers y PyTorch en Google Colab
! pip install torch torchvision transformers
model.save_pretrained («/Content/drive/My Drive/Colab Models/my_finetuned_model»)
Características principales:
Paperspace Gradient es un conjunto de herramientas diseñadas para simplificar el proceso de desarrollo, entrenamiento e implementación de modelos de aprendizaje automático en la nube.
Gradient es particularmente eficaz para tareas como el ajuste de modelos de grandes lenguajes (LLM) debido a su infraestructura escalable y su compatibilidad con contenedores, lo que lo convierte en una opción sólida para los científicos de datos y los profesionales del aprendizaje automático.
Este es un ejemplo de cómo ajustar un modelo de transformador con PyTorch en Paperspace Gradient.
model.save_pretrained (». /my_finetuned_model «)
Características principales:
Run.AI es una plataforma diseñada para optimizar los recursos de la GPU para las cargas de trabajo de aprendizaje automático, lo que facilita a los científicos de datos y a los investigadores de IA la ejecución y la gestión de modelos de IA complejos, incluido el ajuste fino de los modelos de lenguaje grande (LLM).
Se basa en Kubernetes, una herramienta que organiza los recursos informáticos de manera eficiente. Por lo tanto, facilita la ejecución de proyectos complejos de IA y permite a los equipos hacer crecer sus proyectos sin problemas.
Puede consultar la documentación de Run.AI para obtener información detallada. Este es un ejemplo simplificado basado en el flujo de trabajo general para ajustar un modelo como LLama-2 en la plataforma Run.AI.
runai submit my-fine-tuning-job -p my-project --gpu 2 --image my-llama2-fine-tuning-image train.py
Su script train.py debe incluir la lógica para cargar LLama-2 (o el modelo que elija), su conjunto de datos y ejecutar el proceso de ajuste. Esto puede implicar el uso de bibliotecas como Hugging Face Transformers para cargar modelos y TensorFlow o PyTorch para el ciclo de entrenamiento.
desde transformadores import llama para generación condicional, llama a kenizer
Run.AI proporciona herramientas para monitorear el uso de la GPU y el progreso de sus trabajos de entrenamiento, y administrar los recursos computacionales de manera efectiva. Utilice el panel de control o la CLI de Run.AI para realizar un seguimiento del estado y el rendimiento de su trabajo.
puestos de trabajo de Runai
Este comando muestra todos los trabajos actuales, lo que le permite supervisar el progreso y el uso de los recursos de la tarea de ajuste.
Características principales:
Elegir la herramienta adecuada para usted:
Facilidad de uso: Elige herramientas que sean sencillas, especialmente si no te gusta mucho la codificación. ¡Algunas herramientas ni siquiera requieren que escribas código!
Escalabilidad: Asegúrese de que la herramienta pueda crecer con su proyecto, manejando conjuntos de datos más grandes y modelos más complejos sin problemas.
Soporte de modelos y conjuntos de datos: Elija herramientas que funcionen bien con los tipos específicos de datos y modelos que utiliza.
Recursos computacionales: Busca acceso a GPU o TPU si tu proyecto necesita una gran potencia informática.
Coste: Considera cuánto estás dispuesto a gastar. Algunas herramientas son gratuitas; otras cobran en función de los recursos que utilices.
Personalización y control: Si sabes manejar el código, es posible que prefieras herramientas que te permitan modificarlo todo.
Integración: Es más fácil si la herramienta se adapta perfectamente a su flujo de trabajo y herramientas existentes.
Comunidad y soporte: Una comunidad de apoyo y una buena documentación pueden ahorrarle muchos dolores de cabeza.
Las principales herramientas de ajuste fino incluyen Hugging Face para el acceso a modelos, SiliconFlow para la formación basada en la nube y TrueFoundry para la orquestación de nivel empresarial. Las bibliotecas de código abierto como Axolotl y Llama-factory también admiten técnicas avanzadas como LoRa. TrueFoundry unifica de manera única el acceso a los modelos, el seguimiento de los experimentos y la gobernanza de la implementación en una única plataforma segura.
Los costos de optimización de la nube dependen de las horas de procesamiento de la GPU, el tamaño del modelo y los requisitos de almacenamiento. Entrenar un modelo de 7 000 millones de parámetros suele costar entre 100 y 400 dólares, mientras que los modelos de 70 000 millones pueden superar los 10 000 dólares. El uso de métodos eficientes desde el punto de vista de los parámetros, como QLoRa, reduce significativamente estos gastos, que se sitúan entre 50 y 300 dólares por sesión de formación.
Las herramientas de ajuste de PEFT utilizan técnicas como LoRa para ajustar solo una pequeña fracción de los parámetros de un modelo. Esto reduce los requisitos de memoria de la GPU, lo que permite a los equipos entrenar modelos masivos en hardware de consumo o en una sola GPU. Estas herramientas aceleran la velocidad de entrenamiento y, al mismo tiempo, ofrecen una precisión comparable a la del reentrenamiento de modelos completos.
Las herramientas de ajuste perfeccionado vuelven a entrenar los modelos en conjuntos de datos especializados y ajustan los parámetros para mejorar el rendimiento en las tareas específicas del dominio. La ingeniería rápida modifica el texto de entrada para guiar las salidas sin cambiar el peso interno del modelo. Si bien la ingeniería rápida es más rápida, el ajuste fino proporciona un control más profundo y una precisión superior para casos de uso empresarial complejos.
TrueFoundry simplifica el ajuste al proporcionar una interfaz unificada para la integración de datos, el seguimiento de experimentos y la implementación de modelos. Los usuarios cargan datos propios e inician trabajos de ajuste en una infraestructura optimizada mediante backends de alto rendimiento. Una vez finalizada la formación, los equipos pueden implementar puntos de control actualizados directamente en la producción con un solo clic.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








%20(11).webp)


.png)

.webp)
.webp)
.webp)



.webp)
.webp)


