.webp)
July 24, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 9, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
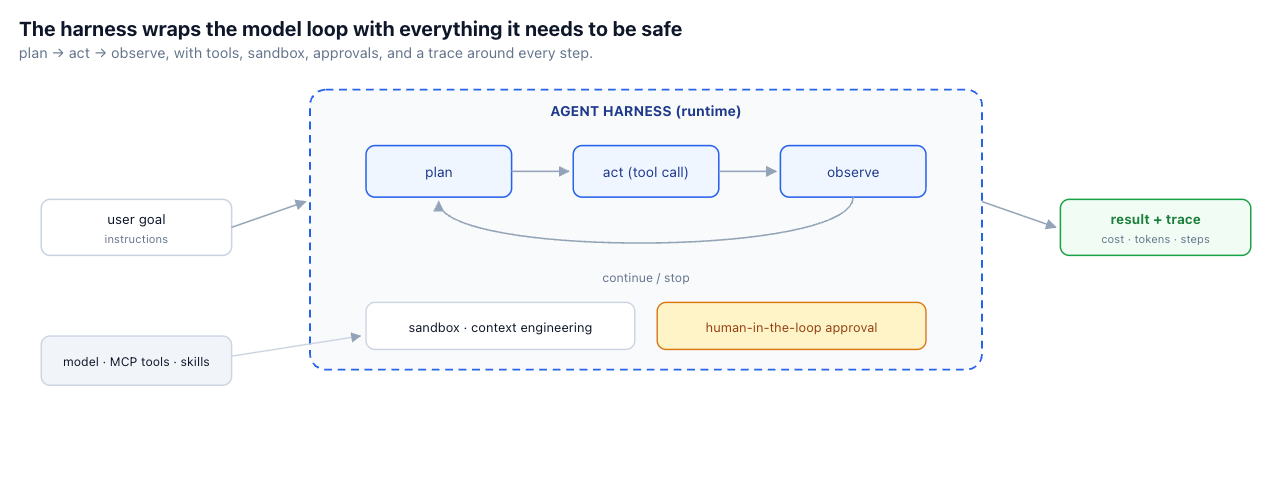
Picking a model is the easy part. Picking the tools is the next easy part. The hard part — the part that decides whether your agent is reliable or a liability — is everything around the model: the loop that plans, acts, and observes; the sandbox that runs its code; the gates that stop it before a destructive action; the trace that explains what it did. That runtime layer is the agent harness, and it's the real build-versus-buy decision in agentic AI. This post is what a harness is, what makes one production-ready, and why a managed harness keeps credentials out of agent definitions.
Sofia, a platform engineer, inherited three teams' worth of agents and a request to make them production-ready. Each team had built its own runtime around the model. One hand-rolled an orchestration loop in Python; another wrapped a framework; the third called the model directly in a cron job. Provider API keys were pasted into agent configs and committed to repos. Approvals for sensitive actions ranged from a Slack message to nothing at all. Two of the three had no usable trace of what an agent actually did on a given run. Sofia's job wasn't to give these agents better models or more tools — they had those. It was to give them the thing none of them had built well: a common, governed runtime. She was missing a harness.
This is where most teams arrive after the first agent demo works. The demo proves the model and the tools; production demands the runtime around them — and that runtime is large, security-sensitive, and almost entirely undifferentiated from one agent to the next. Building it three different ways, as Sofia's teams did, is how you end up with three different sets of problems. This post is about the layer that solves all three at once.
An agent harness is the runtime layer around an LLM that turns it from a text generator into a reliable, long-running agent. Instead of a single model call, the harness manages the full execution loop: it plans, calls a tool, observes the result, and decides whether to continue or stop — repeating until the goal is met or a limit is hit. Around that loop sits everything the loop needs to be safe and useful: tool routing and execution for APIs, MCP tools, and code; memory and context controls for long tasks; security boundaries like sandboxing, credentials, and permissions; human-in-the-loop gates for sensitive actions; and tracing, logs, metrics, and cost visibility.
The word "harness" is well chosen: it's the rigging that lets you put a powerful, somewhat unpredictable thing to work without it running away. None of these pieces is the model, and none is the tool — they're the scaffolding that makes the model-plus-tools combination dependable. That scaffolding is what Sofia's teams each rebuilt, badly, in isolation.
.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet