



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 24, 2026

Blazingly fast way to build, track and deploy your models!
Parte 1 fez o diagnóstico: tokenmaxxing não é um problema de uso de IA; é um problema do plano de controle. Se tokens brutos se tornam um alvo, as pessoas otimizarão para tokens brutos. Se a alavancagem de IA governada se tornar o modelo operacional, a plataforma pode incentivar a adoção enquanto limita custos, riscos e ruído operacional. Esta parte torna essa arquitetura concreta.
A tese é simples. Cada solicitação de IA que sai de uma aplicação empresarial é, quer você a trate assim ou não, um evento de tempo de execução com consequências de custo, segurança e auditoria. O único lugar de maior alavancagem para anexar controles a esses eventos é o gateway — a camada que se situa entre cada aplicação e cada backend de modelo e ferramenta. Um painel construído a jusante pode descrever o que aconteceu. Somente o gateway pode decidir o que acontece a seguir.
Um painel relata um problema. Um gateway previne o próximo. A arquitetura abaixo é o que torna essa distinção operacional.
Uma solicitação de IA governada precisa de quatro invólucros ao seu redor antes de sair da aplicação. Pense nisso como o modelo OSI para IA empresarial — cada camada tem uma responsabilidade específica e um modo de falha específico quando está ausente.
Esses invólucros precisam estar no caminho da solicitação, não em um relatório que alguém lê na sexta-feira. Um painel construído após o fato pode descrever um problema; apenas um invólucro na solicitação ativa pode moldar a próxima chamada. Este é o princípio arquitetônico que separa uma plataforma de IA governada de um complemento de análise.
O primeiro padrão de implementação é um contrato de metadados rigoroso. Use chaves com valores de string, envie-as em cada solicitação e torne-as obrigatórias em seus wrappers de SDK, bibliotecas de cliente internas, frameworks de bot e modelos de agente. O custo de um campo ausente aparece mais tarde como uma linha de fatura ausente, um pico não atribuível ou um evento de guardrail que ninguém consegue direcionar a um proprietário.
// JSON — minimum metadata contract
// Treat as a strict schema, not a suggestion.
{
"team": "payments-platform", // maps to FinOps cost center
"project_id": "proj-agentic-refactor", // rate/budget scoping key
"workflow": "repo-understanding", // routing and policy selector
"surface": "ide-agent", // hourly rate-limit selector
"environment": "production", // budget tier selector
"cost_center": "eng-core", // accounting integration
"ticket_id": "ENG-18472", // outcome join key — THE most important field
"policy_version": "ai-leverage-v1" // audit trail
}
// Python SDK — never skip the metadata header:
// extra_headers={"X-TFY-METADATA": json.dumps(metadata)}A marcação é o trabalho de engenharia mais barato em toda esta arquitetura e a primeira coisa que falha quando as equipes a ignoram.
No gateway da TrueFoundry, isso viaja como o cabeçalho X-TFY-METADATA. O mesmo namespace de chave então alimenta tudo a jusante: orçamentos se aplicam por projeto, limites de taxa se aplicam por fluxo de trabalho, painéis agrupam por equipe, rastreamentos se juntam a tickets e as finanças alocam gastos por centro de custo. Não há uma segunda fonte de verdade.

O objetivo arquitetônico não é adicionar complexidade. É manter um mapeamento rigoroso entre cada modo de falha realista e o controle específico que o impede. Aqui está a taxonomia completa:
Se o código da aplicação nomeia um modelo de provedor específico, você perdeu a capacidade de migrar, testar, fazer A/B ou realizar failover sem alterações no código. O padrão correto é expor capacidades lógicas — nomes como prod/engineering-assistant ou prod/frontier-reasoning — e deixar o gateway resolvê-los para alvos físicos com base em metadados, prioridade, peso ou latência medida.
Na TrueFoundry, é para isso que servem os Modelos Virtuais e a configuração de roteamento. As mesmas regras cobrem lançamentos canary, preferência regional, on-premise com fallback para a nuvem e substituições de prompt específicas do provedor. Esta é a capacidade mais subestimada na pilha de governança — ela torna a conformidade, a otimização de custos e a migração de modelos invisíveis para os desenvolvedores de aplicações.
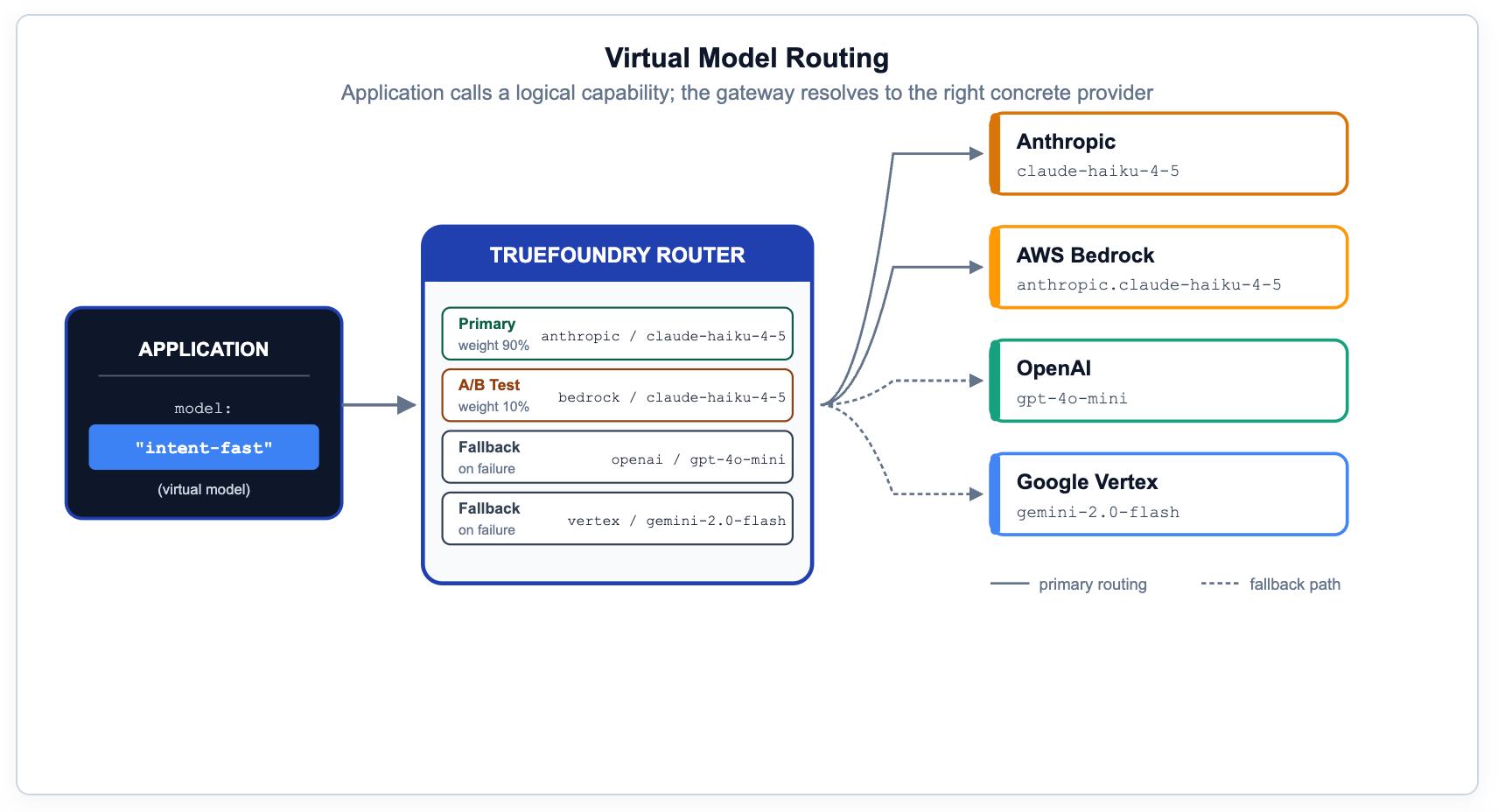
# YAML — gateway-load-balancing-config
# Evaluated top-to-bottom; first match wins.
name: engineering-agent-routing
type: gateway-load-balancing-config
rules:
# Simple repo questions: cheap-first with frontier fallback.
- id: 'simple-repo-questions'
type: priority-based-routing
when:
models: ['prod/engineering-assistant']
metadata:
workflow: 'repo-understanding'
load_balance_targets:
- target: openai-main/gpt-4o-mini
priority: 0
retry_config: {attempts: 2, delay: 100, on_status_codes: ['429','500']}
fallback_status_codes: ['429', '500', '502', '503']
- target: anthropic-main/claude-sonnet
priority: 1
# Security-critical: strongest reasoner first.
- id: 'security-critical-review'
type: priority-based-routing
when:
metadata:
workflow: 'security-review'
load_balance_targets:
- target: anthropic-main/claude-opus
priority: 0
- target: openai-main/gpt-4.1
priority: 1
# Cost-sensitive batch: on-prem first, cloud as overflow.
- id: 'batch-processing-jobs'
type: priority-based-routing
when:
metadata:
surface: 'batch-pipeline'
load_balance_targets:
- target: on-prem/llama-3.1-70b
priority: 0
- target: openai-main/gpt-4o-mini
priority: 1
Documentação de roteamento: truefoundry.com/docs/ai-gateway/load-balancing-overview
Uma vez que as aplicações de IA entram em produção, elas lidam com dados reais de usuários e, em configurações de agente, tomam ações reais através de ferramentas. O perímetro de segurança não é uma coisa só. São quatro ganchos, situados nos quatro momentos em que o gateway pode intervir antes que uma requisição se torne um dano.
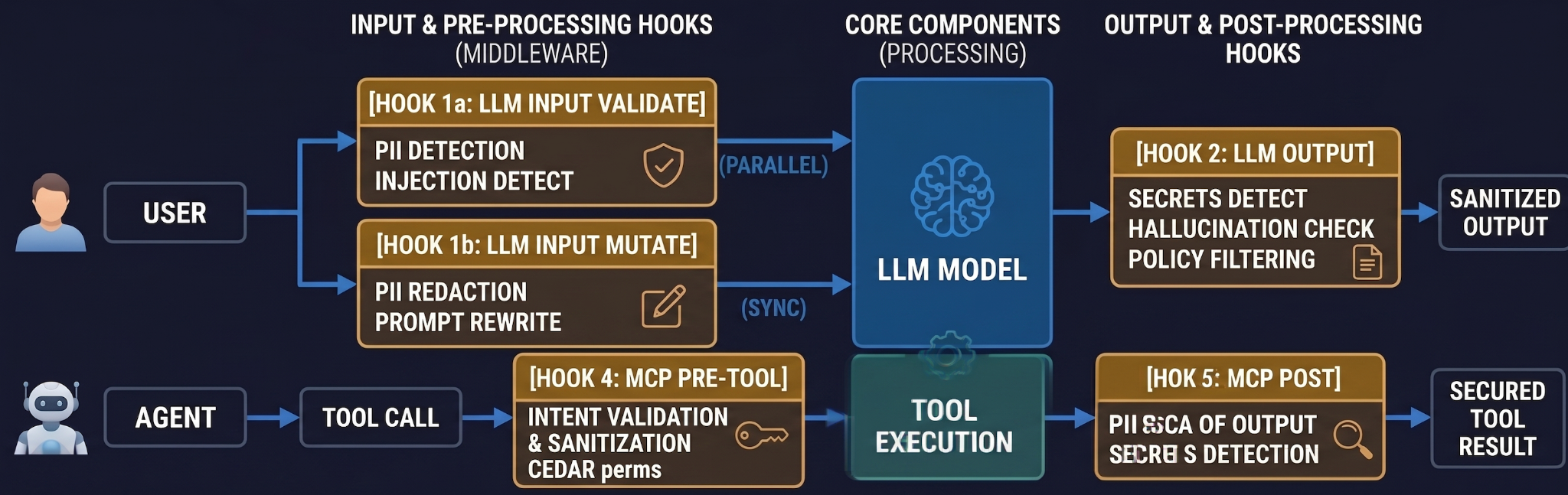
# Per-request guardrails — passed via X-TFY-GUARDRAILS header.
# For org-wide enforcement: AI Gateway → Controls → Guardrails.
X-TFY-GUARDRAILS: {
"llm_input_guardrails": [
"global/pii-redaction",
"global/prompt-injection-detection"
],
"llm_output_guardrails": [
"global/secrets-detection",
"global/hallucination-check"
],
"mcp_tool_pre_invoke_guardrails": [
"global/sql-sanitizer",
"global/cedar-permissions"
],
"mcp_tool_post_invoke_guardrails": [
"global/secrets-detection",
"global/pii-redaction"
]
}
# Rollout strategy — never go straight to blocking in production:
# Phase 1: mode=audit (log violations, let requests through)
# Phase 2: mode=enforce (block on fail, fail-open on provider errors)
# Phase 3: mode=strict (block on fail AND on provider errors)
Implemente os mecanismos de segurança em três etapas: Auditoria → Impor-mas-ignorar-em-erro → Rígido. A configuração intermediária é a que o salvará no dia em que um provedor de segurança de terceiros tiver uma interrupção.
Visão geral das Guardrails: truefoundry.com/docs/ai-gateway/guardrails-overview
Detecção de PII/PHI: truefoundry.com/docs/ai-gateway/tfy-pii
Detecção de segredos: truefoundry.com/docs/ai-gateway/secrets-detection
Duas perguntas dominam as operações uma vez que o uso de IA governado está em produção: 'por que esta requisição se comportou desta forma?' e 'o custo que estamos pagando corresponde ao trabalho que estamos obtendo?' Nenhuma delas pode ser respondida a partir de um gráfico de contagem de tokens.
O conjunto mínimo de informações necessário para respondê-las — e o que o gateway da TrueFoundry oferece de imediato:
Documentação de análise: truefoundry.com/docs/ai-gateway/analytics
Exportação OpenTelemetry: truefoundry.com/docs/ai-gateway/export-opentelemetry-data
Os quatro envelopes acima foram projetados assumindo requisições no estilo chat: uma aplicação envia um prompt, o modelo retorna texto. As cargas de trabalho de IA modernas superaram essa suposição. Agentes chamam ferramentas. Ferramentas chamam outras ferramentas. Uma única requisição de usuário pode gerar uma trajetória de agente de 50 etapas que acessa meia dúzia de servidores MCP. A superfície de custo, a superfície de segurança e a superfície de auditoria mudaram todas do prompt para a chamada de ferramenta.
É por isso que o gateway TrueFoundry comunica-se nativamente tanto com a API LLM quanto com o Protocolo de Contexto de Modelo (MCP). O mesmo envelope de identidade, os mesmos disjuntores e os mesmos ganchos de observabilidade se aplicam a uma chamada de ferramenta, assim como a uma conclusão de chat. A identidade OAuth 2.0 é injetada nas chamadas de ferramenta MCP para que um agente atue como um usuário específico, e não como uma conta de serviço, ao consultar um banco de dados ou registrar um ticket no Jira. Servidores MCP virtuais permitem compor um 'servidor de agente financeiro' lógico a partir de ferramentas distribuídas em três servidores MCP reais, com controle de acesso e limites de taxa aplicados à composição.
O Protocolo de Contexto de Modelo é importante para o custo, não apenas para a arquitetura. A TrueFoundry relata uma economia de até 99% de tokens de inferência quando os agentes usam recuperação ativa de ferramentas em vez de inserir contexto em prompts — e uma sobrecarga de chamada de ferramenta medida em aproximadamente 10ms.
É tentador empurrar esses controles para o código da aplicação: um wrapper aqui, um decorador Python ali, uma classe auxiliar no framework do agente. Isso funciona até que você tenha três equipes de aplicação, dois provedores de modelo, uma aquisição, uma auditoria PCI e um incidente de limite de taxa em uma terça-feira.
Nesse ponto, você descobre que construiu quatro planos de controle ligeiramente diferentes que divergem, e que nenhum deles pode parar uma requisição de uma equipe que não importou o wrapper. O gateway existe pela mesma razão que os gateways de API existiam há uma década: é o único lugar onde cada requisição, de cada aplicação, em cada ambiente, pode ser observada e moldada uniformemente.
A objeção a um gateway é sempre 'mais um salto no caminho da requisição'. O TrueFoundry AI Gateway adiciona aproximadamente 5ms de sobrecarga p50 e lida com mais de 350 requisições por segundo em uma única vCPU. A objeção não resiste ao contato com os números.
O gateway é também o único lugar que pode abranger toda a superfície da infraestrutura de IA moderna: mais de 1000 LLMs em mais de 19 provedores, além dos servidores MCP que seus agentes chamam, e dos modelos auto-hospedados por trás de sua VPC. A TrueFoundry foi mencionada no relatório da Gartner '10 Melhores Práticas para Otimizar Custos de IA Generativa e Agêntica 2026' — porque a única maneira de as empresas realmente otimizarem nessa superfície é executando cada requisição através de uma camada governada.
→ Arquitetura do Plano de Gateway
Tokenmaxxing é um sintoma da adoção de IA não gerenciada. A arquitetura acima é a cura. A identidade define quem está perguntando. A política define o que é permitido. A segurança define o que é aceitável. A observabilidade define o que realmente aconteceu. Juntos, eles convertem a atividade bruta de tokens em um ciclo de vida de requisição governado — responsável, útil, seguro, ajustável.
O objetivo não é diminuir o uso de IA. O objetivo é tornar cada linha dele explicável.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




