













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
パート1 は次のように診断しました。トークン最大化はAI利用の問題ではなく、コントロールプレーンの問題であると。生のトークンが目標となれば、人々は生のトークンを最適化しようとします。統制されたAI活用が運用モデルとなれば、プラットフォームはコスト、リスク、運用上のノイズを制限しつつ、導入を促進できます。このパートでは、そのアーキテクチャを具体化します。
その命題は単純です。企業アプリケーションから発せられるすべてのAIリクエストは、そう扱うかどうかにかかわらず、コスト、安全性、監査に関する結果を伴うランタイムイベントです。これらのイベントに制御を適用する最も効果的な場所は、すべてのアプリケーションとすべてのモデルおよびツールバックエンドの間に位置するレイヤーであるゲートウェイです。ダウンストリームで構築されたダッシュボードは、何が起こったかを説明できますが、次に何が起こるかを決定できるのはゲートウェイだけです。
ダッシュボードは問題を報告します。ゲートウェイは次の問題を防止します。以下のアーキテクチャは、その区別を運用可能にするものです。
統制されたAIリクエストは、アプリケーションを離れる前に4つのエンベロープで包まれる必要があります。これをエンタープライズAIのOSIモデルと考えてください。各レイヤーには特定の責任があり、それが欠けている場合には特定の障害モードがあります。
これらのエンベロープは、誰かが金曜日に読むレポートの中ではなく、リクエストパス上に存在する必要があります。事後に構築されたダッシュボードは問題を説明できますが、ライブリクエスト上のエンベロープだけが次の呼び出しを形成できます。これが、統制されたAIプラットフォームをアナリティクスアドオンから区別するアーキテクチャ原則です。
最初の実装標準は、厳格なメタデータ契約です。文字列値のキーを使用し、すべてのリクエストでそれらを送信し、SDKラッパー、内部クライアントライブラリ、ボットフレームワーク、エージェントテンプレートで必須とします。1つのフィールドが欠落すると、後で請求書明細の欠落、原因不明のスパイク、または所有者にルーティングできないガードレールイベントとして現れます。
// JSON — minimum metadata contract
// Treat as a strict schema, not a suggestion.
{
"team": "payments-platform", // maps to FinOps cost center
"project_id": "proj-agentic-refactor", // rate/budget scoping key
"workflow": "repo-understanding", // routing and policy selector
"surface": "ide-agent", // hourly rate-limit selector
"environment": "production", // budget tier selector
"cost_center": "eng-core", // accounting integration
"ticket_id": "ENG-18472", // outcome join key — THE most important field
"policy_version": "ai-leverage-v1" // audit trail
}
// Python SDK — never skip the metadata header:
// extra_headers={"X-TFY-METADATA": json.dumps(metadata)}タグ付けは、このアーキテクチャ全体で最も安価なエンジニアリング作業であり、チームがそれをスキップすると最初に破綻するものです。
TrueFoundryゲートウェイでは、これはX-TFY-METADATAヘッダーとして伝達されます。同じキーネームスペースが、ダウンストリームのすべてを動かします。予算はプロジェクトごとに適用され、レート制限はワークフローごとに適用され、ダッシュボードはチームごとにグループ化され、トレースはチケットに結合され、財務はコストセンターごとに支出を割り当てます。第二の真実の情報源はありません。

アーキテクチャの目的は、複雑な設定を増やすことではありません。あらゆる現実的な障害モードと、それを防ぐ特定の制御との間に密接なマッピングを維持することです。完全な分類は以下の通りです。
アプリケーションコードが特定のプロバイダーモデルを直接指定すると、コード変更なしに移行、テスト、A/Bテスト、フェイルオーバーを行う能力が失われます。正しいパターンは、prod/engineering-assistant や prod/frontier-reasoning のような論理的な機能(ケイパビリティ)を公開し、ゲートウェイがメタデータ、優先度、重み、または測定されたレイテンシに基づいて、それらを物理的なターゲットに解決するようにすることです。
TrueFoundryでは、仮想モデルとルーティング設定がこの目的のためにあります。同じルールで、カナリアリリース、地域設定、オンプレミスとクラウドのフォールバック、プロバイダー固有のプロンプトオーバーライドがカバーされます。これはガバナンススタックにおいて最も過小評価されている機能であり、コンプライアンス、コスト最適化、モデル移行をアプリケーション開発者にとって意識されないものにします。
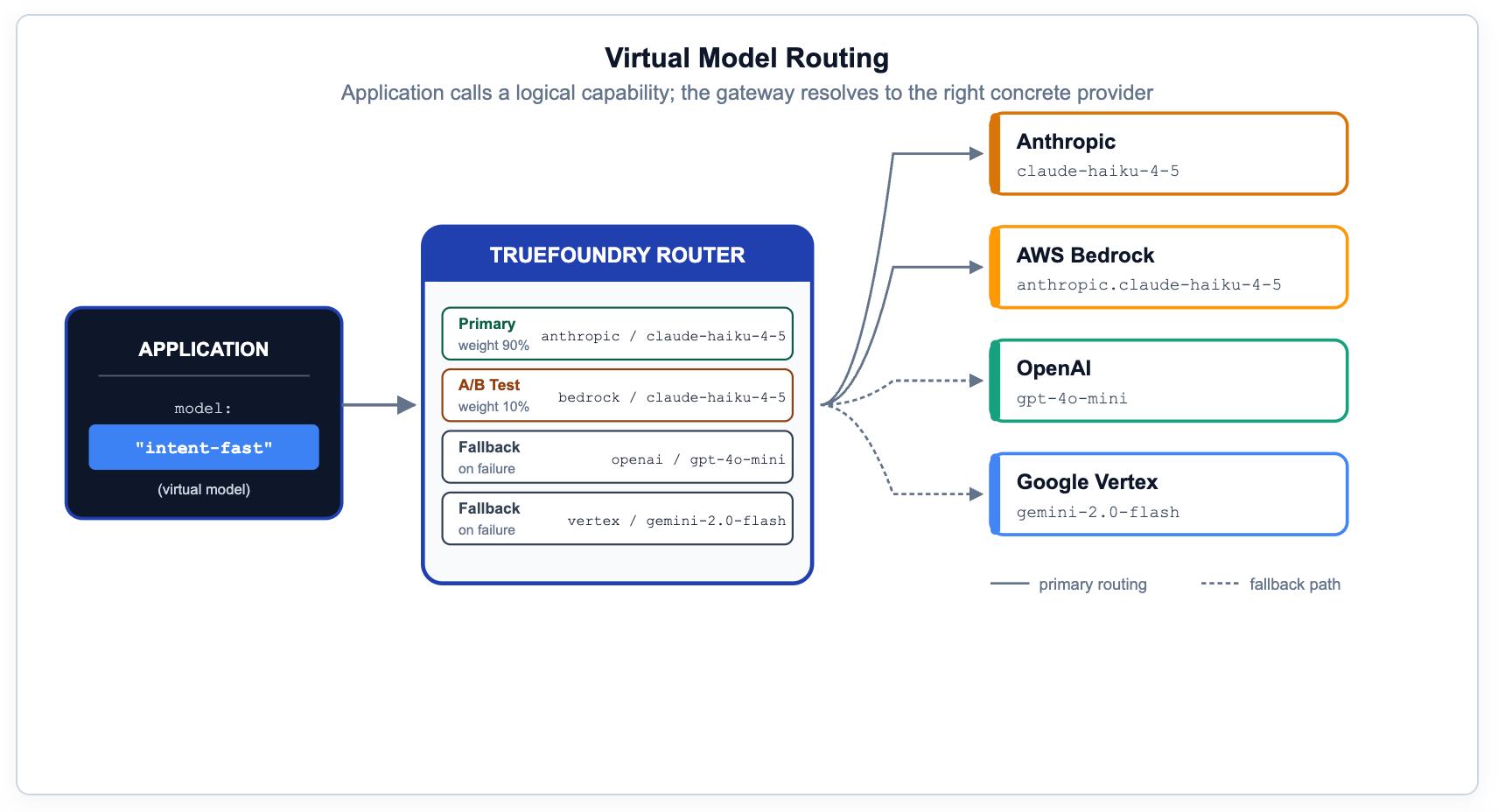
# YAML — gateway-load-balancing-config
# Evaluated top-to-bottom; first match wins.
name: engineering-agent-routing
type: gateway-load-balancing-config
rules:
# Simple repo questions: cheap-first with frontier fallback.
- id: 'simple-repo-questions'
type: priority-based-routing
when:
models: ['prod/engineering-assistant']
metadata:
workflow: 'repo-understanding'
load_balance_targets:
- target: openai-main/gpt-4o-mini
priority: 0
retry_config: {attempts: 2, delay: 100, on_status_codes: ['429','500']}
fallback_status_codes: ['429', '500', '502', '503']
- target: anthropic-main/claude-sonnet
priority: 1
# Security-critical: strongest reasoner first.
- id: 'security-critical-review'
type: priority-based-routing
when:
metadata:
workflow: 'security-review'
load_balance_targets:
- target: anthropic-main/claude-opus
priority: 0
- target: openai-main/gpt-4.1
priority: 1
# Cost-sensitive batch: on-prem first, cloud as overflow.
- id: 'batch-processing-jobs'
type: priority-based-routing
when:
metadata:
surface: 'batch-pipeline'
load_balance_targets:
- target: on-prem/llama-3.1-70b
priority: 0
- target: openai-main/gpt-4o-mini
priority: 1
ルーティングに関するドキュメント:truefoundry.com/docs/ai-gateway/load-balancing-overview
AIアプリケーションが本番環境に投入されると、実際のユーザーデータを処理し、エージェント型の設定ではツールを通じて実際のアクションを実行します。安全性の境界は一つではありません。それは、リクエストが損害となる前にゲートウェイが介入できる4つのタイミングに配置された、4つのフックで構成されます。
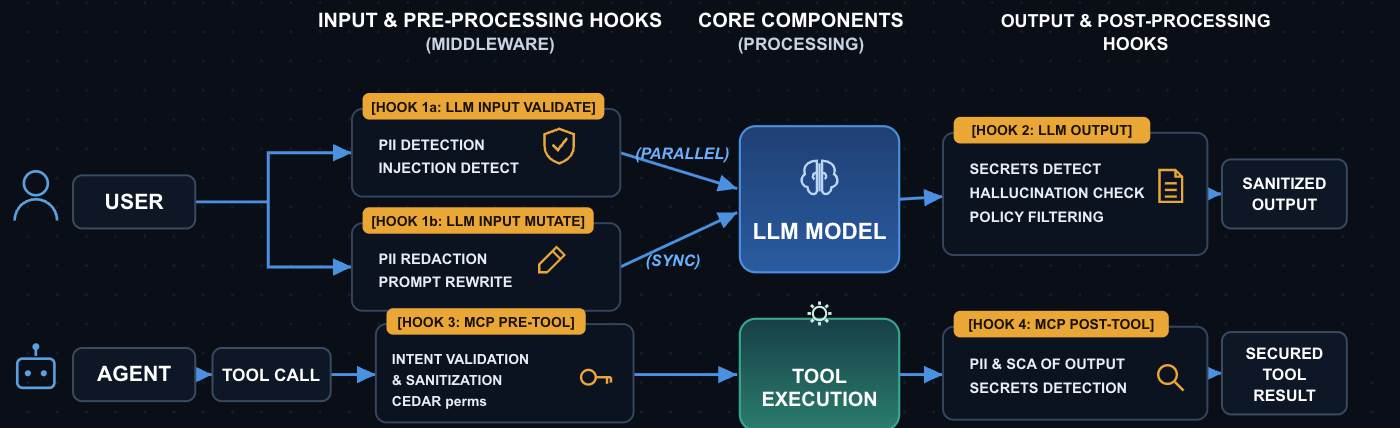
# Per-request guardrails — passed via X-TFY-GUARDRAILS header.
# For org-wide enforcement: AI Gateway → Controls → Guardrails.
X-TFY-GUARDRAILS: {
"llm_input_guardrails": [
"global/pii-redaction",
"global/prompt-injection-detection"
],
"llm_output_guardrails": [
"global/secrets-detection",
"global/hallucination-check"
],
"mcp_tool_pre_invoke_guardrails": [
"global/sql-sanitizer",
"global/cedar-permissions"
],
"mcp_tool_post_invoke_guardrails": [
"global/secrets-detection",
"global/pii-redaction"
]
}
# Rollout strategy — never go straight to blocking in production:
# Phase 1: mode=audit (log violations, let requests through)
# Phase 2: mode=enforce (block on fail, fail-open on provider errors)
# Phase 3: mode=strict (block on fail AND on provider errors)
ガードレールは、監査 → エラー時に無視して強制 → 厳格、の3つのステップで展開します。中間の設定は、サードパーティのセキュリティプロバイダーが停止した際に役立つでしょう。
ガードレール概要:truefoundry.com/docs/ai-gateway/guardrails-overview
PII/PHI検出:truefoundry.com/docs/ai-gateway/tfy-pii
シークレット検出:truefoundry.com/docs/ai-gateway/secrets-detection
ガバナンスされたAI利用が本番環境に導入されると、「なぜこのリクエストはこのように振る舞ったのか?」と「支払っているコストに見合う成果が得られているのか?」という2つの疑問が運用を支配します。どちらもトークン数のグラフだけでは答えられません。
それらの疑問に答えるために必要な最小限のインターフェース、そしてTrueFoundryのゲートウェイがすぐに提供するインターフェースは以下の通りです。
分析に関するドキュメント:truefoundry.com/docs/ai-gateway/analytics
OpenTelemetryエクスポート:truefoundry.com/docs/ai-gateway/export-opentelemetry-data
上記の4つの枠組みは、アプリケーションがプロンプトを送信し、モデルがテキストを返すというチャット形式のリクエストを想定して設計されていました。しかし、現代のAIワークロードはその前提を超えています。エージェントはツールを呼び出し、ツールはさらに別のツールを呼び出します。1つのユーザーリクエストが、数個のMCPサーバーにアクセスする50ステップのエージェントの軌跡を生み出すこともあります。コスト、安全性、監査の各対象はすべて、プロンプトからツール呼び出しへと移行しました。
これが、TrueFoundryゲートウェイがLLM APIとModel Context Protocol (MCP) の両方にネイティブに対応している理由です。ツール呼び出しにもチャット完了と同様に、同じIDエンベロープ、同じサーキットブレーカー、同じ可観測性フックが適用されます。OAuth 2.0のIDがMCPツール呼び出しに注入されるため、エージェントはデータベースを照会したりJiraチケットを起票したりする際に、サービスアカウントとしてではなく、特定のユーザーとして動作します。仮想MCPサーバーを使用すると、3つの実際のMCPサーバーに分散しているツールから論理的な「財務エージェントサーバー」を構成でき、その構成にアクセス制御とレート制限を適用できます。
Model Context Protocolは、アーキテクチャだけでなくコスト面でも重要です。TrueFoundryの報告によると、エージェントがプロンプトにコンテキストを詰め込む代わりにアクティブなツール検索を使用すると、推論トークンを最大99%削減でき、ツール呼び出しのオーバーヘッドは約10ミリ秒と測定されています。
これらの制御をアプリケーションコードに押し込みたくなるものです。ここにラッパー、あそこにPythonデコレーター、エージェントフレームワークにヘルパークラス、といった具合に。しかし、3つのアプリケーションチーム、2つのモデルプロバイダー、1つの買収、PCI監査、そして火曜日のレート制限インシデントが発生するまでは機能します。
その時点で、互いに矛盾する4つのわずかに異なるコントロールプレーンを構築してしまったことに気づくでしょう。そして、それらのどれもがラッパーをインポートしなかったチームからのリクエストを停止できないことも。ゲートウェイが存在する理由は、10年前のAPIゲートウェイと同じです。つまり、あらゆる環境のあらゆるアプリケーションからのあらゆるリクエストを、一貫して監視し、制御できる唯一の場所だからです。
ゲートウェイに対する異論は常に「リクエストパスにホップが1つ増える」というものです。TrueFoundry AIゲートウェイは、p50オーバーヘッドを約5ミリ秒追加し、単一のvCPUで毎秒350以上のリクエストを処理します。この異論は、実際の数値に照らし合わせると成り立ちません。
ゲートウェイは、現代のAIインフラストラクチャの全範囲に対応できる唯一の場所でもあります。19以上のプロバイダーにわたる1000以上のLLM、エージェントが呼び出すMCPサーバー、そしてVPCの背後にある自己ホスト型モデルなどです。TrueFoundryは、Gartnerの「生成AIおよびエージェントAIのコスト最適化に関する10のベストプラクティス 2026」レポートで取り上げられました。なぜなら、企業がこの広範な領域で実際に最適化を行う唯一の方法は、すべてのリクエストを単一の統制されたレイヤーを介して実行することだからです。
トークンマキシングは、管理されていないAI導入の兆候です。上記のアーキテクチャがその解決策です。IDは誰が要求しているかを定義します。ポリシーは何が許可されているかを定義します。安全性は何が許容されるかを定義します。可観測性は実際に何が起こったかを定義します。これらが一体となって、生のトークンアクティビティを、説明責任があり、有用で、安全で、調整可能な、統制されたリクエストライフサイクルへと変換します。
AIの使用量を減らすことが目的ではありません。そのすべての行を説明可能にすることが目的です。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


