














November 5, 2025
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
As machine learning adoption continues to accelerate across industries, the need for robust, scalable, and automated ML pipelines has never been greater. In 2026, MLOps platforms have become foundational to operationalizing AI, from model training and deployment to monitoring and governance.
These platforms streamline the end-to-end lifecycle, helping teams manage complexity, ensure reproducibility, and accelerate time-to-value. Whether you’re a startup scaling your first model or an enterprise deploying hundreds, choosing the right MLOps platform is critical.
In this guide, we explore what MLOps is, why it matters, and the best MLOps tools shaping the landscape in 2026.
MLOps (Machine Learning Operations) is a discipline that merges the principles of machine learning, DevOps, and data engineering to enable the development, deployment, monitoring, and maintenance of reliable ML systems at scale. It ensures that models built in experimental environments can be safely and efficiently transitioned into production, where they must perform consistently, adapt to change, and remain accountable.
Traditional DevOps workflows focus on version control, CI/CD pipelines, automated testing, and system reliability. MLOps inherits these, but extends them to tackle the unique challenges of machine learning: managing constantly evolving data, retraining models to account for drift, evaluating non-deterministic results, and maintaining reproducibility across model iterations.
As machine learning moves from experimentation to enterprise-scale deployment. MLOps tools have become essential for ensuring consistency, reliability, and speed across the model lifecycle. Without a centralized MLOps solution, teams often end up with fragmented tools, manual processes, and inconsistent workflows that slow down innovation and introduce operational risk.
MLOps platforms solve these challenges by providing a unified interface to manage data pipelines, training workflows, model tracking, deployment, and monitoring, all in one place. This consolidation enables tighter collaboration between data scientists, ML engineers, and DevOps teams, reducing handoff friction and improving reproducibility across environments.
When selecting the MLOps tools in 2026, it's important to evaluate not just features, but how well the platform supports your ML workflow, scales with your infrastructure, and aligns with your team’s operational goals. Below are some essential criteria to consider::
An ideal MLOps platform should cover the full machine learning lifecycle, from data versioning and training to deployment and monitoring. Fragmented toolchains can create inefficiencies and inconsistencies across teams. Platforms that unify these stages into a single workflow help improve reproducibility, reduce handoffs, and accelerate iteration.
As ML workloads scale, so must the platform. A good MLOps solution should support everything from local experimentation to distributed training across multiple GPUs or nodes. It should also offer flexibility in deployment, supporting cloud-native, on-premise, and hybrid environments without locking you into a specific stack.
Usability is often overlooked but critical. A strong platform offers clean interfaces, both UI and CLI, along with comprehensive SDKs that integrate with popular frameworks like PyTorch, TensorFlow, and Hugging Face. A platform that’s intuitive for both data scientists and ML engineers promotes better collaboration and faster onboarding.
MLOps doesn’t exist in isolation. Your platform should integrate seamlessly with existing systems for storage (like S3 or GCS), CI/CD tools (like GitHub Actions or Jenkins), observability platforms (like Prometheus or Grafana), and model registries. Strong integration ensures smooth data and model flow across your pipeline.
For organizations working in regulated environments, governance features are a must. The platform should support role-based access control (RBAC), audit logs, and lineage tracking. Compliance with standards like SOC 2, HIPAA, or GDPR helps ensure data privacy, trust, and long-term viability in enterprise settings.
The MLOps landscape in 2026 is rich with platforms catering to different needs, from lightweight experiment tracking to enterprise-grade model deployment and monitoring. Below are the 25 best MLOps tools helping teams streamline their ML workflows, optimize infrastructure, and operationalize models at scale. Each platform has its strengths depending on your tech stack, team maturity, and business goals.
TrueFoundry is a modern MLOps and LLMOps platform built for teams that want to deploy, scale, and monitor machine learning and generative AI models in production. It abstracts away infrastructure complexity while offering complete control, allowing teams to move from experimentation to deployment in minutes.
Unlike legacy systems, TrueFoundry is optimized for performance, developer productivity, and GenAI-first workflows, including support for agents, RAG pipelines, and advanced tracing. Its enterprise-grade security and modular design make it one of the best MLOps tools, suitable for organizations of all sizes.
Key Features:
Best For:
AI-driven teams building LLM-backed products, especially where performance, security, and observability are critical. Excellent fit for fast-moving teams or enterprises needing scalable GenAI deployment. Here are some of the best LLM gateway tools.
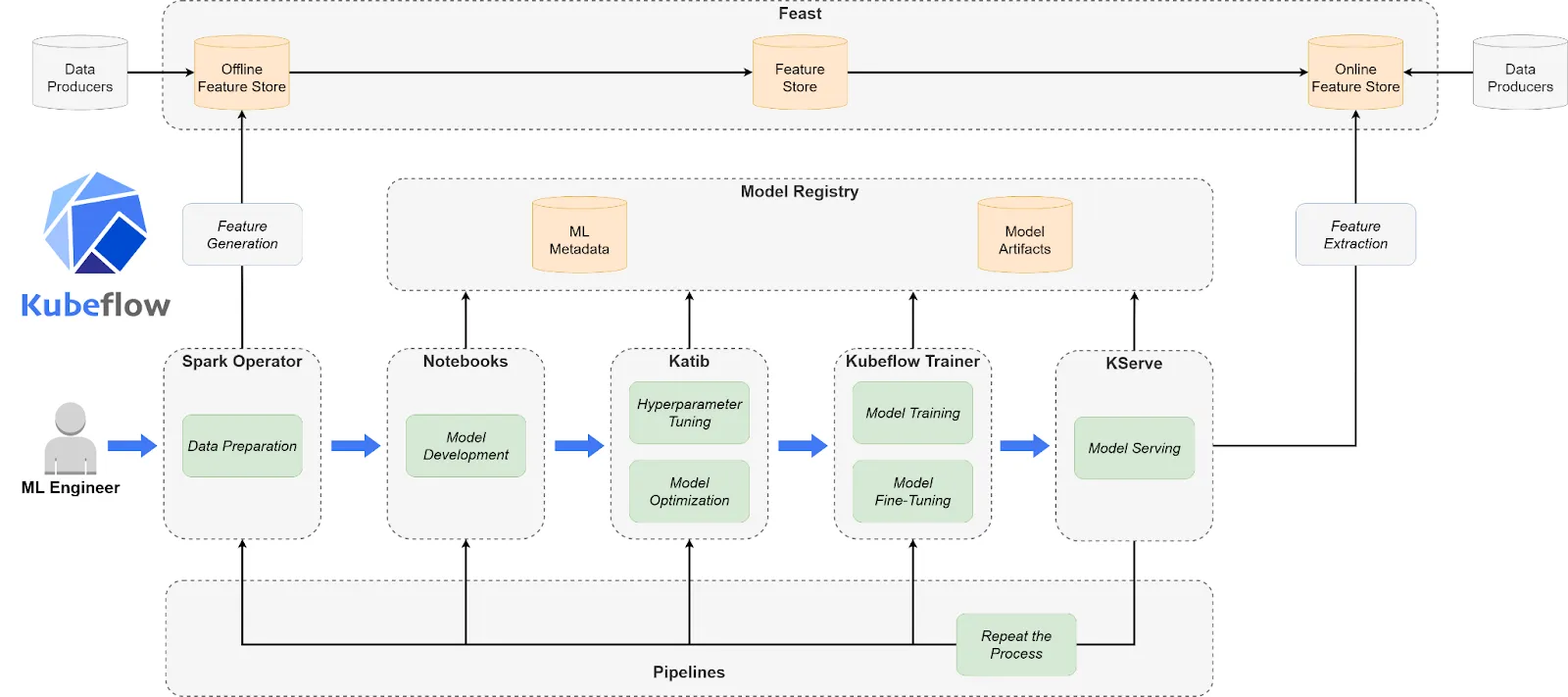
Kubeflow is a Kubernetes-native, open-source and one of the best MLOps tools for building and managing portable, composable ML workflows. It provides the flexibility to orchestrate training, tuning, and serving using familiar Kubernetes abstractions. Though powerful, Kubeflow requires deep infrastructure knowledge and isn’t ideal for teams without dedicated DevOps support. It shines when customized, scalable, and secure ML pipelines are a necessity.
Key Features:
Best For:
Teams with strong Kubernetes expertise looking to fully customize and control their MLOps workflows, especially in regulated or hybrid cloud environments.
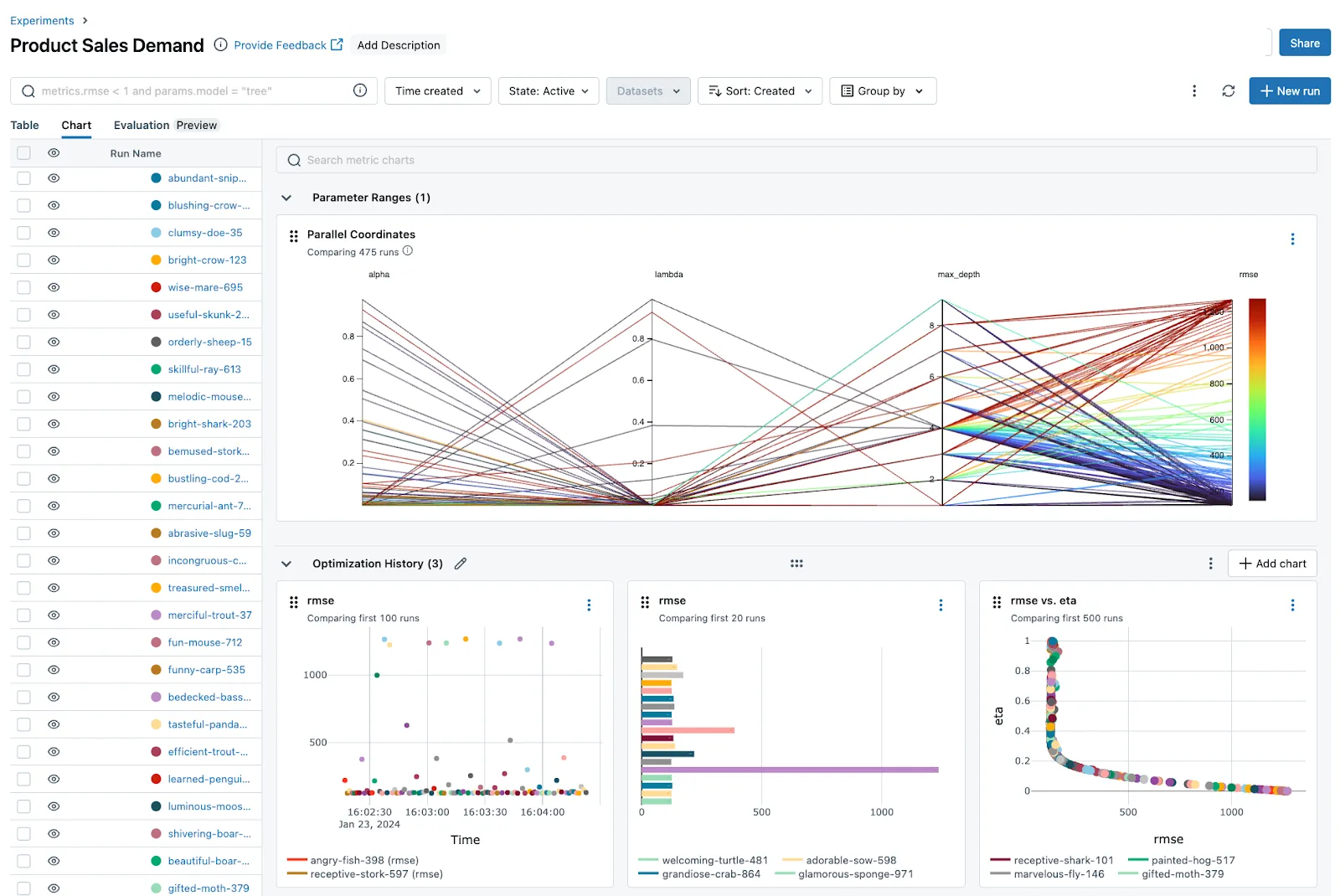
MLflow is a lightweight, open-source MLOps platform created by Databricks, focused on managing ML experimentation and model versioning. Its modular components let teams integrate tracking, registry, and deployment into their existing workflows.
This MLOps tool is ideal for smaller teams or organizations that want flexibility without the overhead of full-scale infrastructure or Kubernetes.
Key Features:
Best For:
ML teams seek lightweight, customizable tooling for tracking experiments, sharing models, and managing versions without relying on a large-scale platform.
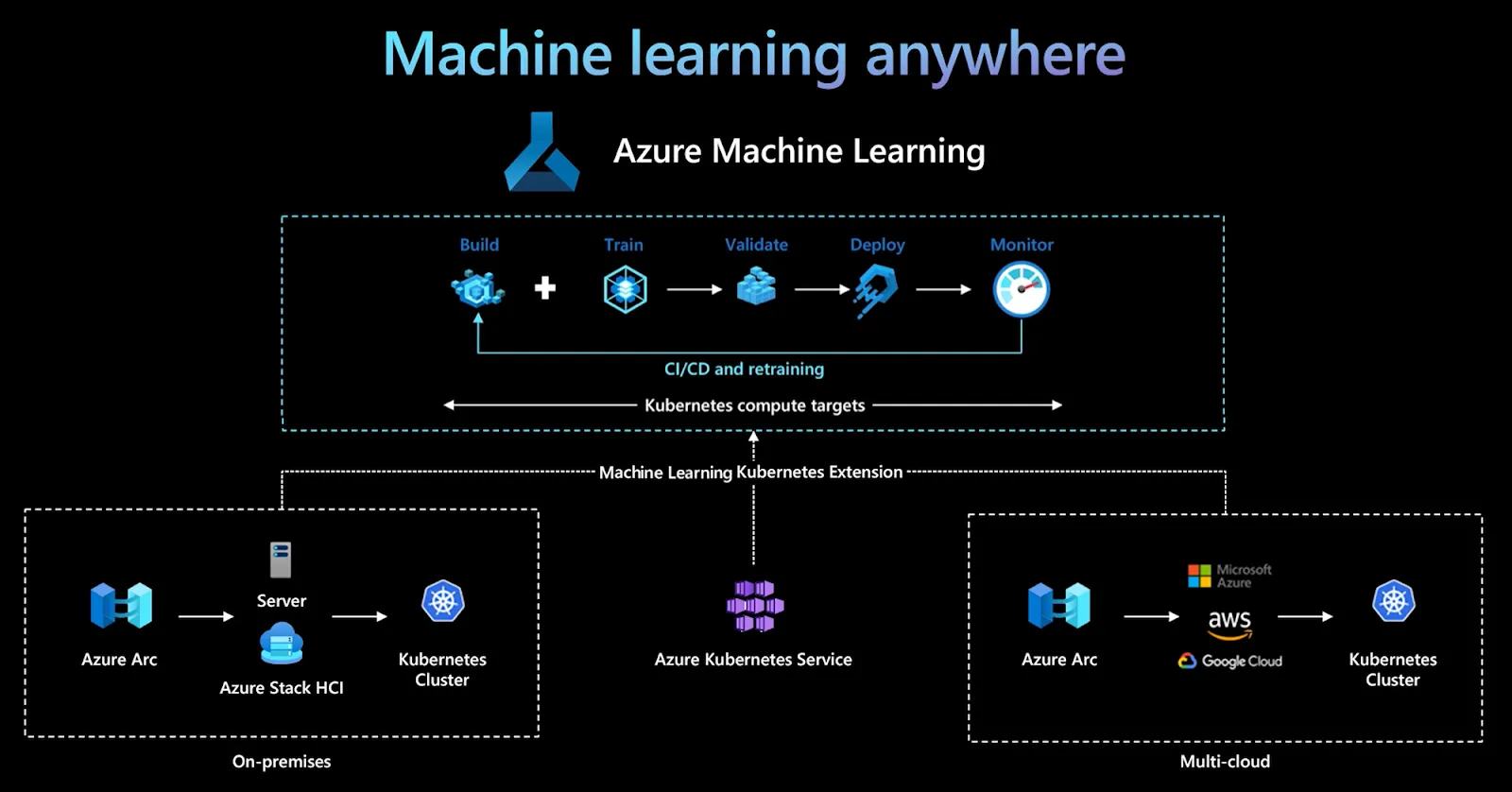
Azure Machine Learning is Microsoft’s fully managed MLOps platform designed for building, training, deploying, and monitoring machine learning models at enterprise scale. It integrates tightly with the Azure ecosystem, offering a powerful suite of tools for model management, AutoML, and responsible AI. Azure ML is ideal for organizations already invested in Microsoft’s cloud and looking for security, scalability, and compliance.
Key Features:
Best For:
Enterprises operating on Microsoft Azure need a highly secure, scalable, and fully integrated MLOps platform with enterprise compliance baked in.
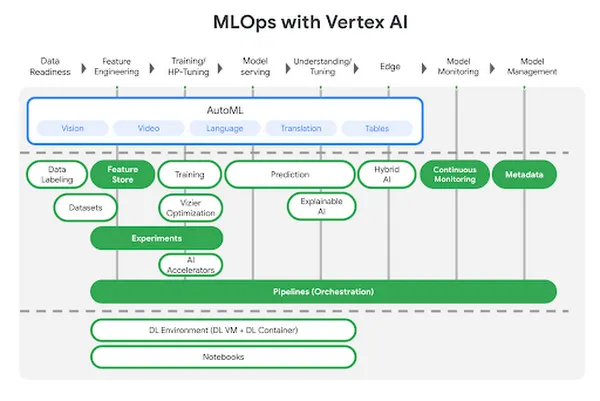
Vertex AI is Google Cloud’s unified platform for ML development, combining AutoML and custom model training under one interface. It abstracts infrastructure while offering advanced services like feature stores, pipelines, and experiment tracking.
Built for scalability and integration with Google’s ecosystem, this MLOps tool is optimized for production-level ML deployment and data-driven workflows.
Key Features:
Best For:
Teams building and scaling machine learning on Google Cloud who want a managed, scalable MLOps platform with full data and deployment integration.
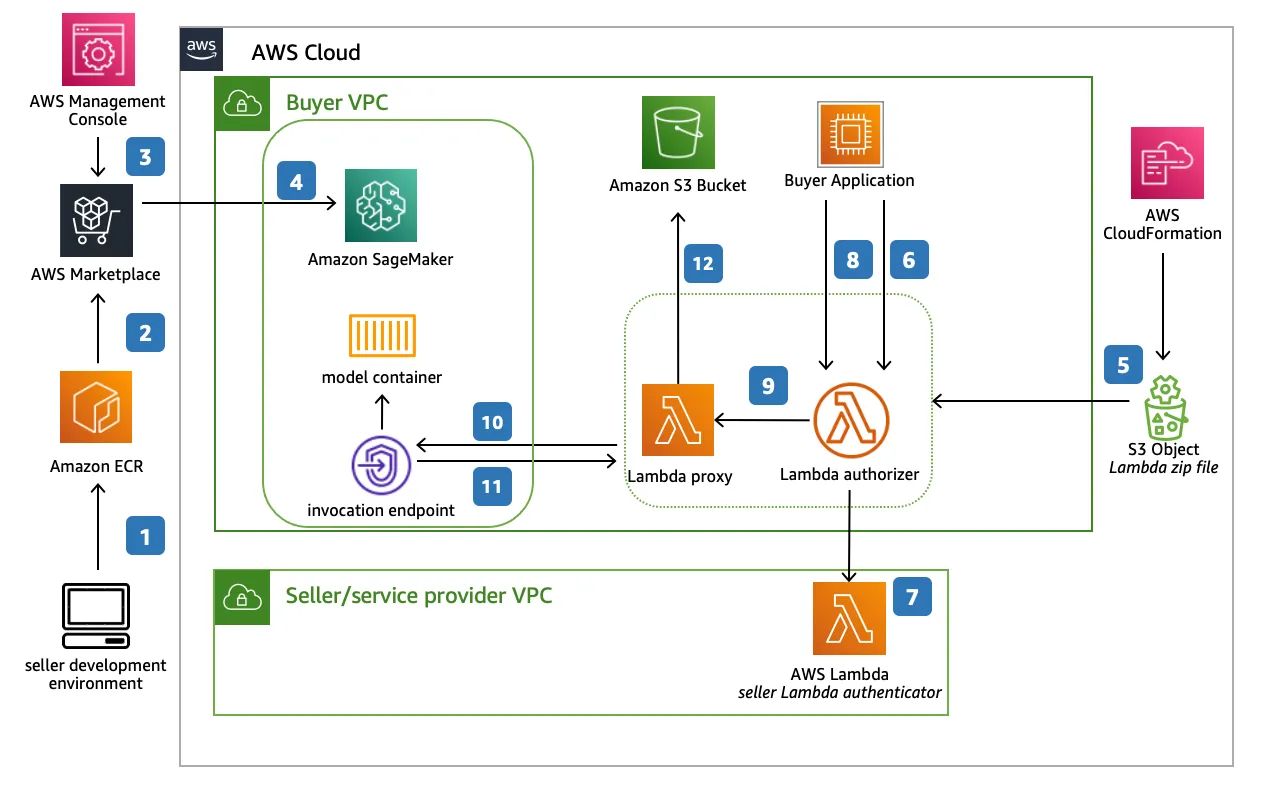
Amazon SageMaker is AWS’s flagship MLOps platform that offers everything from data preprocessing to real-time model deployment. Known for its broad functionality, SageMaker supports custom model development, AutoML, model hosting, and advanced monitoring tools. It’s tightly integrated with the AWS ecosystem, making it a go-to choice for cloud-native enterprises.
Key Features:
Best For:
Organizations already using AWS for infrastructure who need a robust, scalable MLOps platform with deep integration and full lifecycle support.
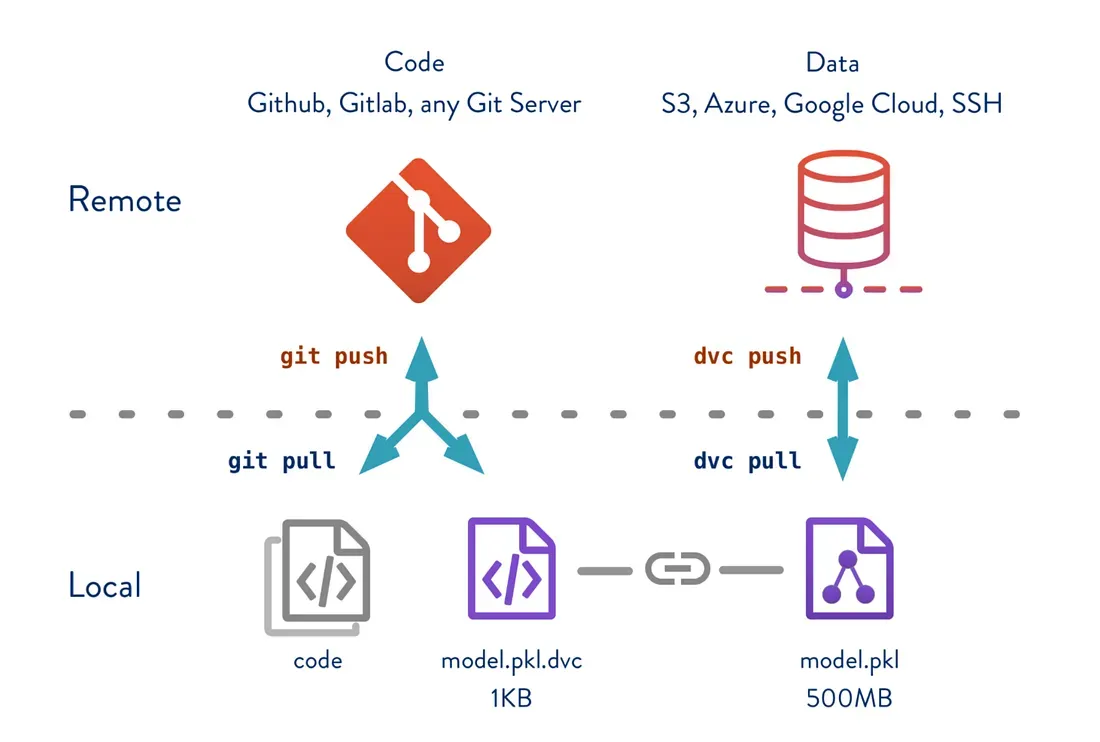
DVC is an open-source tool that brings version control to machine learning projects by tracking datasets, models, and experiments—similar to how Git manages code. It doesn’t aim to be a full-stack MLOps platform, but instead focuses on reproducibility, collaboration, and model tracking through Git-compatible workflows. DVC integrates seamlessly into existing pipelines and gives ML practitioners more control over experiment management.
Key Features:
Best For:
Teams looking for lightweight, code-first MLOps capabilities centered around reproducibility, Git-based workflows, and experiment management—especially in research and iterative ML projects.
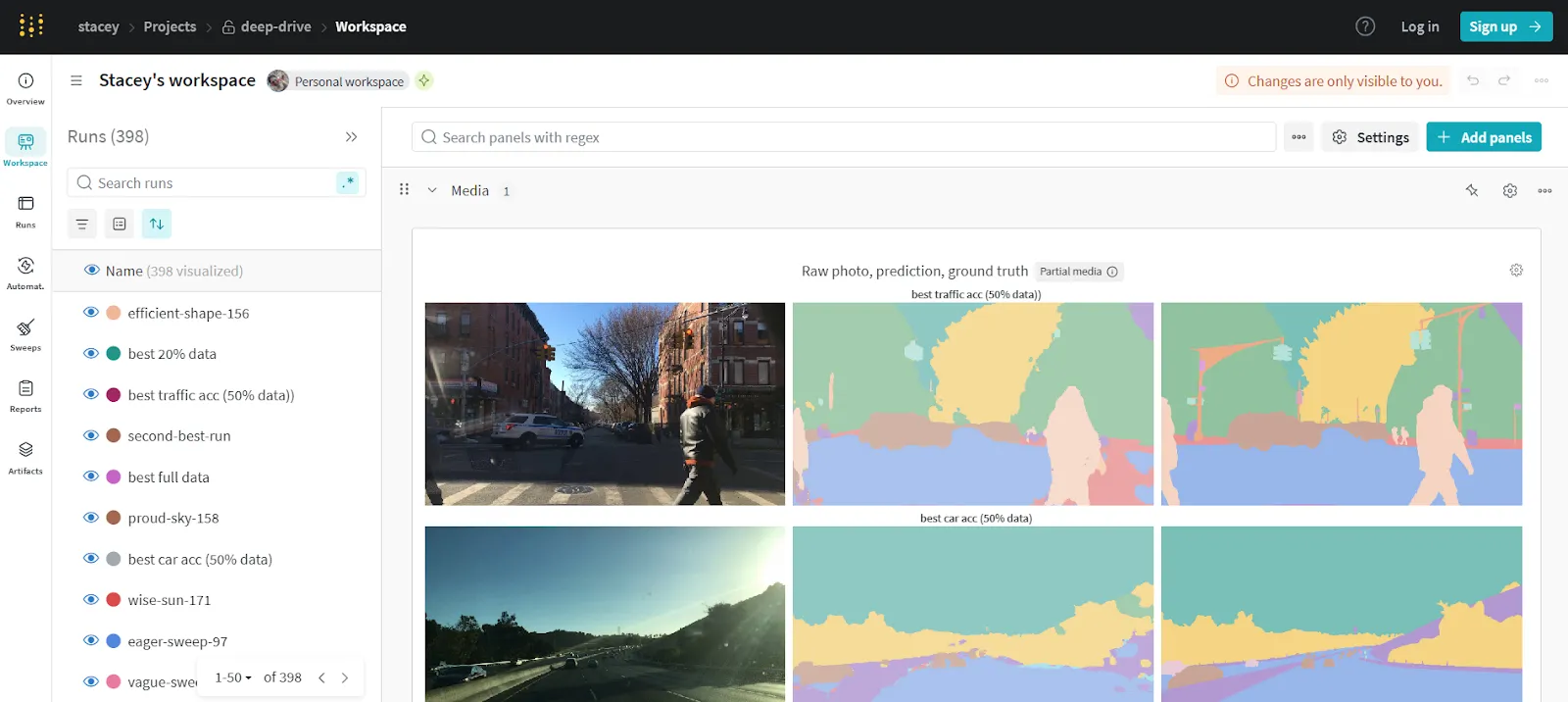
Weights & Biases (W&B) is one of the best MLOps tools for experiment tracking, collaboration, and model visualization. It’s widely adopted in both research and production environments, offering simple integration with most ML frameworks. W&B focuses on observability, enabling real-time insight into training performance, hyperparameters, and system metrics.
Key Features:
Best For:
ML teams focused on rapid iteration, visualization, and collaboration. Ideal for research-driven environments and teams that want better insight into training performance.
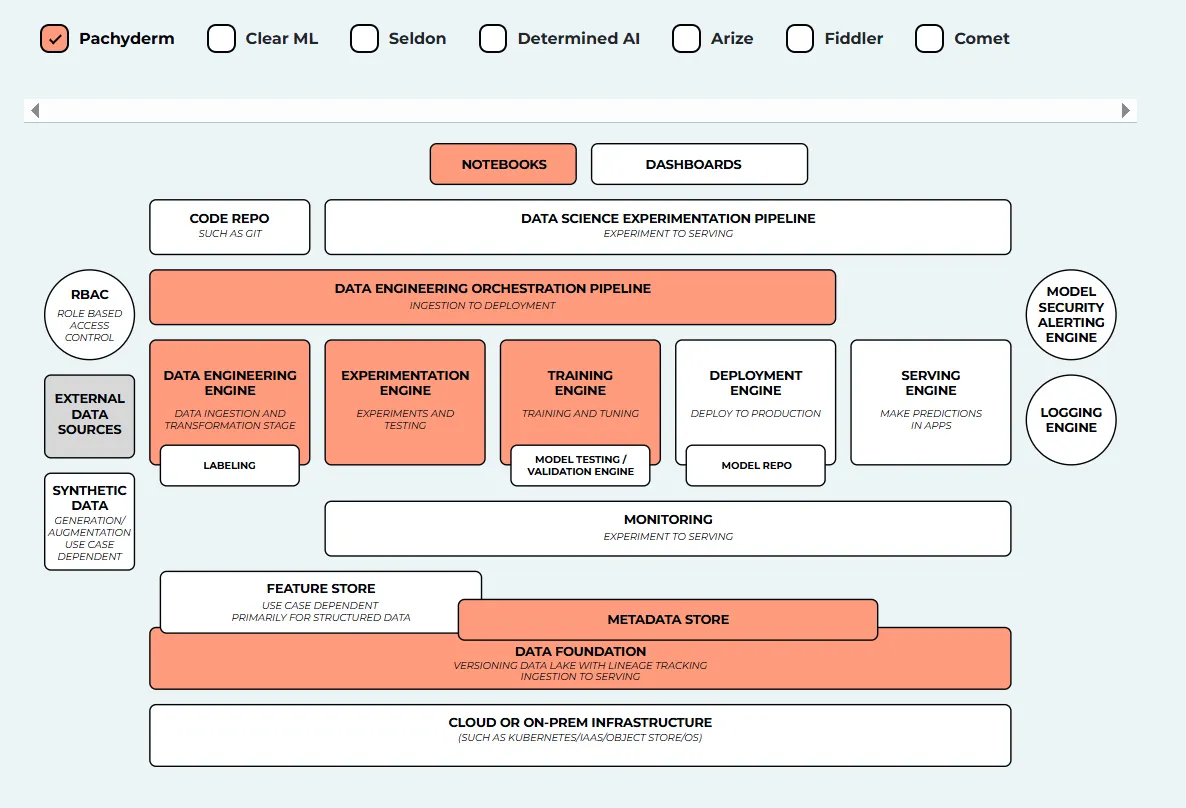
Pachyderm is an open-source data science platform built for data lineage, version control, and reproducible pipelines. Unlike traditional MLOps tools, Pachyderm uses a Git-like approach for data, making it highly suitable for teams handling complex data dependencies or regulated environments. It combines containerization with data pipeline orchestration to ensure versioned, traceable workflows.
Key Features:
Best For:
Teams in regulated industries or data-intensive workflows that need strong version control and lineage tracking for compliance, reproducibility, and scale.
Allegro AI is an MLOps platform designed specifically for managing deep learning workflows at scale—particularly in computer vision and edge AI environments. It focuses on improving reproducibility, collaboration, and traceability across the AI lifecycle.
With strong capabilities in dataset management, model versioning, and experiment tracking, this MLOps tool offers a secure, end-to-end infrastructure for teams building and deploying high-performance models in production or regulated environments.
Key Features:
Best For:
Teams working on computer vision, deep learning, or edge deployment use cases—especially in industries like automotive, manufacturing, healthcare, or defense, where traceability and control over data and models are essential.
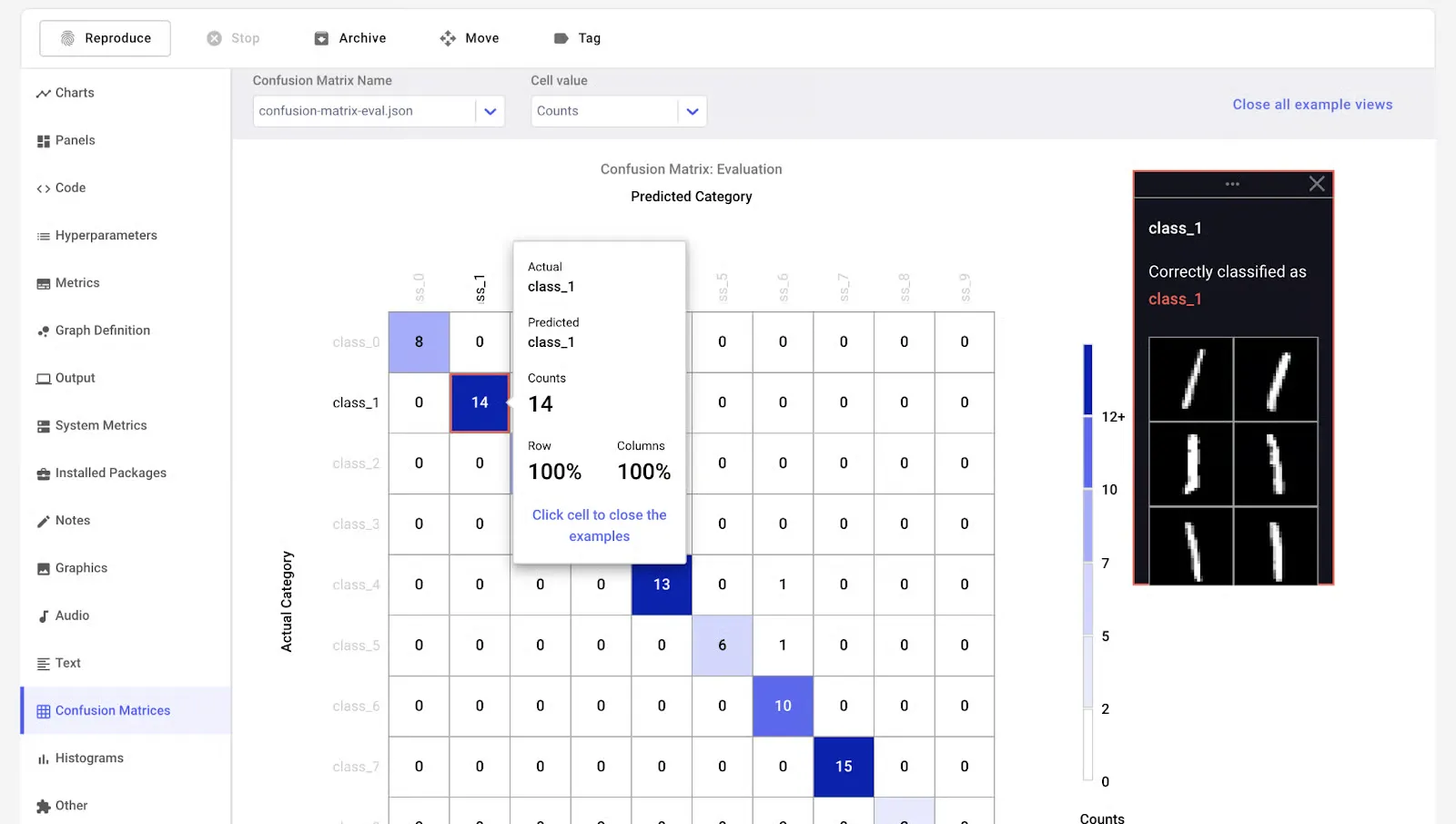
Comet ML is a machine learning platform designed to help you monitor, analyze, and refine models and experiments. It works seamlessly with popular libraries such as Scikit-learn, PyTorch, TensorFlow, and Hugging Face.
Comet MLOps tool makes it easy to explore and compare experiment results, while also providing rich visualizations for data samples, including images, audio, text, and structured tables.
Key Features:
Best For:
Best for data scientists, machine learning engineers, and teams who want an easy way to track experiments, compare results, and improve model performance.

Prefect is a modern workflow orchestration tool designed to monitor, coordinate, and manage data pipelines across applications. It is an open-source, lightweight solution built to support end-to-end machine learning and data workflows.
You can use either Prefect Orion UI or Prefect Cloud for managing and visualizing workflows. Prefect Orion UI is an open-source, locally hosted orchestration engine and API server that provides insights into local workflow runs and system activity.
Prefect Cloud, on the other hand, is a hosted service that lets you visualize flows, runs, and deployments while also managing accounts, workspaces, and team collaboration.
Key Features:
Best For:
Data engineers, ML engineers, and teams that need reliable workflow orchestration, visibility into pipelines, and scalable collaboration for data and machine learning projects.
Metaflow is a workflow management tool for data science and machine learning that simplifies building, running, and deploying models. This MLOps tool helps teams manage pipelines at scale while automatically handling experiment tracking, data versioning, and production deployment.
Key Features:
Best For:
Data scientists and ML teams who want a simple, scalable workflow tool that handles orchestration, tracking, and deployment while minimizing MLOps overhead.
Dagster is a cloud-native orchestration platform that helps data teams define, run, and monitor complex data pipelines efficiently. It focuses on reliability, observability, and a modern development experience for managing data workflows.
Key Features:
Best For:
Data engineers and data teams who need reliable, testable, and observable data pipeline orchestration with strong integration support and a modern development workflow.

Kedro is a Python-based workflow orchestration tool that helps build reproducible, maintainable, and modular data science projects. It brings software engineering best practices, like modularity, separation of concerns, and versioning, into machine learning workflows.
Key Features:
Best For:
Data scientists and teams who want structured, maintainable, and reproducible data science workflows using software engineering best practices.
TruEra is a platform focused on improving machine learning model quality through testing, explainability, and root cause analysis. This MLOps tool helps teams debug models, understand performance issues, and ensure fairness across the ML lifecycle.
Key Features:
Best For:
ML engineers, data scientists, and organizations that need deeper model insights, fairness checks, and reliable performance monitoring across the model lifecycle.
BentoML is a Python-first platform that simplifies deploying, serving, and monitoring machine learning models in production. It helps teams ship ML applications faster with scalable, high-performance model serving.
Key Features:
Best For:
ML engineers and teams that need a fast, scalable, and reliable way to deploy and manage machine learning models in production environments.
Evidently AI is an open-source Python library for monitoring machine learning models across development, validation, and production. It helps ensure data and model quality by detecting drift, performance issues, and other potential problems.
Key Features:
Best for:
Data scientists and ML engineers who need reliable model monitoring, drift detection, and performance tracking throughout the ML lifecycle.
DagsHub is a collaboration platform for machine learning projects that helps teams track, version, and manage data, models, experiments, pipelines, and code in one place. Often described as “GitHub for machine learning,” it provides tools to streamline the end-to-end ML workflow.
Key Features:
Best For:
ML teams and organizations that need a collaborative, version-controlled environment to manage the full machine learning lifecycle with strong integration and reproducibility support.

The Iguazio MLOps Platform is an end-to-end solution that automates the entire machine learning lifecycle, from data ingestion and preparation to training, deployment, and production monitoring. This MLOps tool offers both an open-source framework (MLRun) and a fully managed platform, with flexible deployment across cloud, hybrid, or on-premises environments.
Key Features:
Best For:
Enterprises and regulated industries (e.g., healthcare, finance) that need a flexible, scalable, and governed MLOps platform with strong automation and deployment control.

Qdrant is an open-source vector database and similarity search engine that enables you to store, manage, and query vector embeddings through a production-ready service and simple API. It is designed for high-performance semantic search and AI-powered applications.
Key Features:
Best For:
Developers and ML teams building semantic search, recommendation systems, and AI applications that require fast, scalable vector search and filtering.

LakeFS is an open-source data version control system that brings Git-like operations to object storage, allowing teams to manage data lakes with the same workflows used for code. It enables scalable, reliable data versioning for large-scale data environments.
Key Features:
Best For:
Data engineers and organizations managing large data lakes who need reliable version control, safe experimentation, and reproducible data workflows at scale.

Fiddler AI is a model monitoring and explainability platform that helps teams understand, debug, and track machine learning models in production. It provides clear insights into model behavior, performance, and data quality through an intuitive interface.
Key Features:
Best For:
ML engineers, data scientists, and organizations that need transparent model monitoring, explainability, and proactive alerts to maintain reliable production ML systems.
Ray is a distributed computing framework that helps developers scale AI and Python applications with ease. It provides a flexible runtime and a suite of AI libraries for building, training, and deploying machine learning systems at scale.
Key Features:
最適な用途:
分散環境全体で学習、データ処理、モデルサービングをスケーリングするための、柔軟で高性能なフレームワークを必要とする開発者、MLエンジニア、AIチーム。
Nuclioは、データ、I/O、計算負荷の高いワークロード向けに設計された、高性能なサーバーレスフレームワークです。サーバー管理なしでリアルタイム処理を可能にし、データサイエンスツールやMLプラットフォームとよく統合されます。
主要機能:
最適な用途:
クラウドおよびエッジ環境全体で、リアルタイムデータ処理、ストリーミング、スケーラブルなAIワークロードに対応するサーバーレスで高性能なプラットフォームを必要とする組織およびMLチーム。
最高のMLOpsツールは、組織がエンドツーエンドの機械学習ライフサイクルをより効率的に管理するのに役立ちます。これらは、MLシステムの構築、デプロイ、保守に自動化、コラボレーション、信頼性をもたらします。
MLOpsツールは、データ準備、実験追跡、パイプラインオーケストレーションなどの反復的なタスクを自動化します。これにより、チームはより迅速に反復作業を行い、手作業によるエラーを減らし、アイデアから本番環境へモデルをより速く移行できるようになります。
これらのツールは、共有ワークスペース、バージョン管理されたアセット、明確なドキュメントを提供し、データサイエンティスト、エンジニア、関係者がチーム間で協力し、変更をレビューし、洞察を共有することを容易にします。
組み込みの監視、テスト、検証機能により、MLOpsツールはデータドリフト、バイアス、パフォーマンスの低下などの問題を検出するのに役立ちます。これにより、モデルが正確で信頼性が高く、ビジネス目標に合致していることが保証されます。
MLOpsプラットフォームは、データ、コード、モデル、実験のバージョンを追跡し、チームが結果を再現し、変更を監査し、環境全体で一貫性を維持することを可能にします。
これらは、自動化、CI/CDパイプライン、スケーラブルなインフラストラクチャを通じてモデルの本番環境へのデプロイを簡素化し、組織が増加するワークロードに対応し、変化する要求に効率的に適応できるようにします。
MLOpsは、ニッチな実践から現代の機械学習ワークフローの基盤となるコンポーネントへと進化しました。2026年には、組織はMLOpsが必要かどうかを問うのではなく、どのプラットフォームが自社の目標、インフラストラクチャ、規模に最も合致するかを問うようになっています。
これまで見てきたように、この分野では、MLflowやDVCのような軽量でモジュール式のツールから、Azure ML、Vertex AI、SageMakerのようなフルマネージドのエンタープライズソリューションまで、あらゆるものが提供されています。
GenAI、ファインチューニング、リアルタイム推論に注力するチームにとって、TrueFoundryのような新しいプラットフォームは、現代のAI課題のために構築された最先端の機能を提供します。
MLOpsはDevOpsより優れているわけではありません。機械学習に特化したDevOpsの拡張です。DevOpsがソフトウェアデリバリーとインフラ自動化に焦点を当てる一方で、MLOpsは、データ管理、実験追跡、モデル監視、再現性の機能を追加し、本番環境でのMLシステムの構築、デプロイ、保守における固有の課題に対処します。
企業にとって最適なMLOpsツールとは、開発者のスピードと厳格なインフラガバナンスのバランスが取れたものです。大手クラウドプロバイダーは幅広いサービスを提供していますが、データ主権とマルチクラウドの柔軟性を求めるチームにとって、TrueFoundryは理想的な選択肢となることが多いです。プライベートVPC内でネイティブに動作する統合コントロールプレーンを提供し、セキュリティやインフラ制御を損なうことなく、トレーニングからデプロイメントまでのライフサイクル全体を自動化できます。
Dockerはコンテナ化の基盤技術であり、MLOpsツールスタックの重要な要素です。モデルの監視やバージョン管理のような高レベルのタスクは管理しませんが、開発環境と本番環境でモデルが一貫して動作することを保証します。TrueFoundryは、Dockerイメージを自動的に構築し、Kubernetes上でオーケストレーションすることでコンテナ化プロセスを簡素化し、データサイエンティストがDevOpsの専門家になる必要なくコードをデプロイできるようにします。
TrueFoundryは、既存のクラウドインフラストラクチャの上に位置する、開発者中心の抽象化レイヤーとして機能します。Kubernetesクラスターに直接接続し、リソースプロビジョニング、CI/CD、モデルサービングなどの複雑なタスクを自動化します。実験と本番ワークロードを管理するための単一インターフェースを提供することで、デプロイ時間を数週間から数分に短縮し、自動GPU最適化とスポットインスタンスサポートによりコストを削減します。
MLOpsに最適な単一のクラウドはありません。適切な選択は、ニーズ、ツール、予算によって異なります。AWS、Azure、Google Cloudはすべて、自動化されたパイプライン、スケーラブルなトレーニング、モデル監視など、強力なMLOpsサービスを提供しています。チームは、既存のインフラストラクチャ、コンプライアンス要件、データエコシステムとの統合に基づいて選択することがよくあります。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)




.png)








.webp)
.webp)


