














June 27, 2026
|
5 min read

Published: February 12, 2026

Blazingly fast way to build, track and deploy your models!
Wiring up a Generative AI platform on Microsoft Azure means stitching together distinct compute, identity, and AI primitives. You provision raw capacity via Azure Kubernetes Service (AKS) and Spot VMs, handle identity via Entra ID, and route requests to Azure OpenAI. Friction hits when your infrastructure teams have to orchestrate these connections manually for every new model deployment.
TrueFoundry deploys as an infrastructure overlay inside your Azure subscription. We handle the deployment lifecycle, identity federation, and autoscaling. This post breaks down the exact integration patterns we use to connect TrueFoundry with Azure, covering the split-plane deployment, network boundaries, and workload identity mechanics.
We use a split-plane architecture to isolate workload execution from platform management. If you build platforms on Amazon EKS, this model looks familiar: you separate the control surface from the data plane.
We connect the two planes using a secure, outbound-only gRPC stream or WebSocket. The cluster-side agent initiates the connection to the Control Plane to pull manifests and push logs. You do not open any inbound ports on your VNET Network Security Groups. Your VNET denies external ingress from the internet by default.
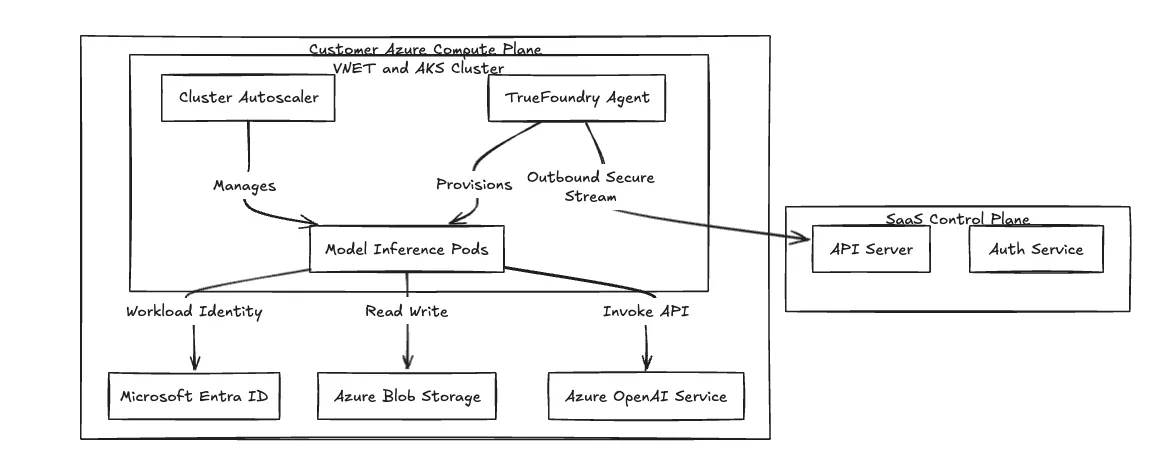
Fig 1: The Split-Plane Architecture isolates data processing within the customer VNET.
We configure the compute plane networking using Azure CNI for direct pod-level IP assignment. Your compute resources stay in private subnets.
For strict compliance boundaries, we route traffic over Azure Private Link. Connections from your inference pods to Azure OpenAI, Key Vault, and Blob Storage route entirely over the Microsoft backbone.
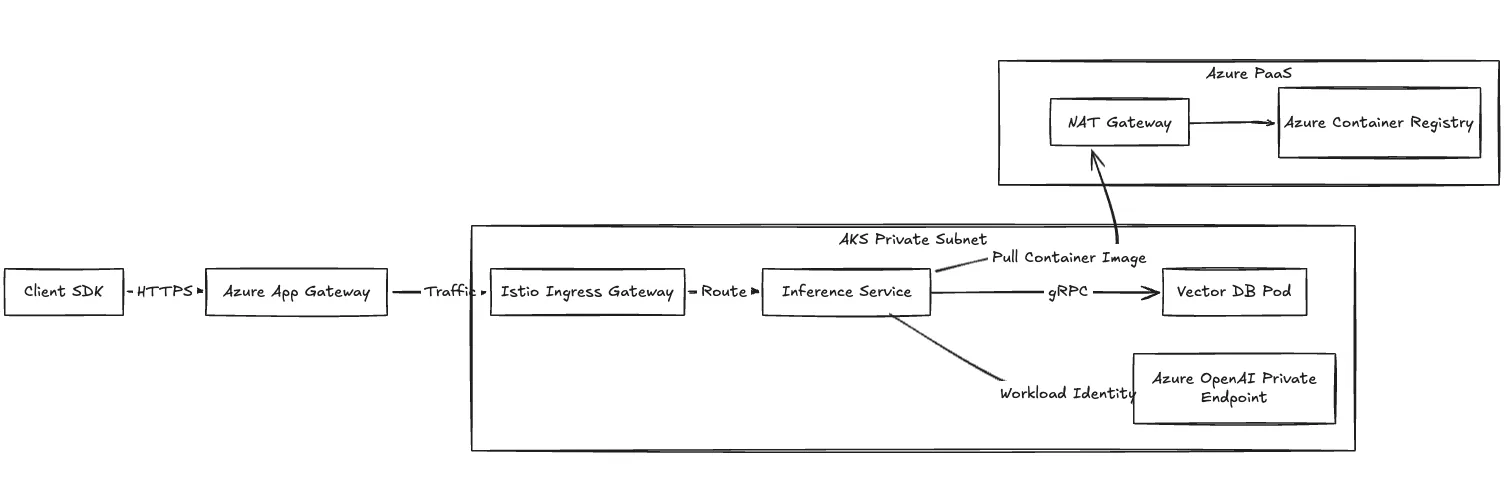
Fig 2: Network traffic flow detailing ingress and private connectivity to Azure PaaS.
Hardcoded static secrets and Service Principals introduce severe rotation overhead. We authenticate workloads dynamically using Microsoft Entra Workload ID. If you manage AWS environments, this is the Azure equivalent of AWS IAM Roles for Service Accounts (IRSA).
When you deploy a pipeline, we execute this sequence:
We use DefaultAzureCredential in the application code. This scopes the blast radius strictly to the RBAC permissions granted to that specific Managed Identity.
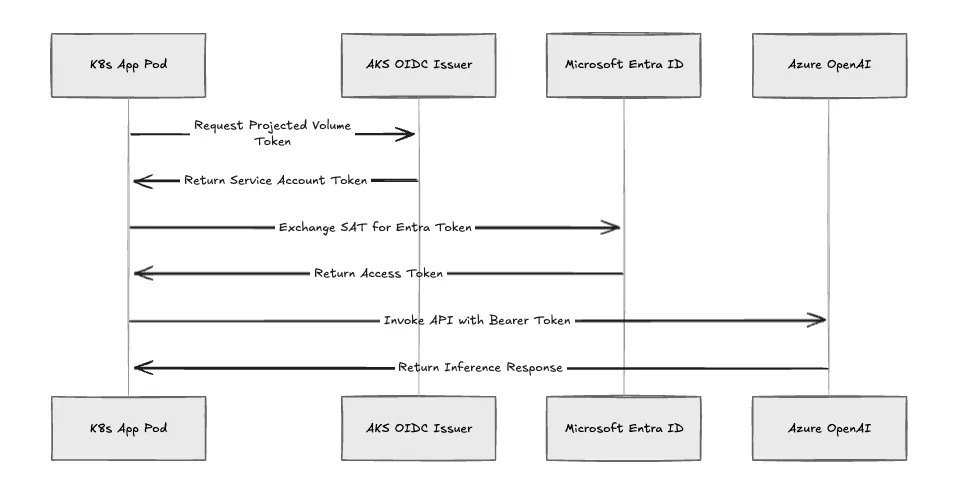
Fig 3: The Entra Workload ID authentication flow.
Running steady-state inference on On-Demand VMs often results in higher baseline costs. We integrate directly with AKS node pools to orchestrate Azure Spot Virtual Machines (similar to utilizing Amazon EC2 Spot Instances).
We manage Spot capacity using the following logic:
For teams running batch inference or fault-tolerant API serving, this setup—much like running Karpenter on AWS—can reduce compute instance costs by up to 80% depending on workload flexibility.
Managing distinct API keys and Token-Per-Minute (TPM) limits across multiple Azure regions creates operational drag. The TrueFoundry AI Gateway abstracts this. Similar to routing requests through Amazon Bedrock, developers hit a single internal API endpoint.
We align with standard GitOps and IaC practices. You provision the underlying Azure environment using our maintained Terraform modules.
Your Terraform state manages the VNETs, the AKS cluster, the OIDC issuers, and the underlying PostgreSQL databases. The TrueFoundry overlay simply maps to these native resources, keeping your infrastructure auditable and compliant.
Deploying TrueFoundry on Azure isolates your compute and data execution while we manage the application lifecycle. You maintain direct authority over your VNETs, NSGs, and data residency perimeters. We handle the orchestration. By abstracting the complex wiring between AKS, Entra ID, and Azure OpenAI, we let your engineering teams focus on shipping models instead of fighting infrastructure.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.




.webp)

.webp)
.webp)
.png)






.webp)
.webp)
