Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
Los volúmenes proporcionan almacenamiento persistente a los contenedores dentro de los pods para que puedan leer y escribir datos en un disco central en varios pods. Son especialmente útiles en el aprendizaje automático cuando es necesario almacenar y acceder a datos, modelos y otros artefactos necesarios para las tareas de entrenamiento, entrega e inferencia.
En este blog, analizaremos cómo utilizar los volúmenes y las opciones disponibles en cada nube.
¿Cuándo usar los volúmenes de Kubernetes?
Algunos casos de uso en los que los volúmenes resultan muy útiles:
Comparte los datos de entrenamiento: Es posible que varios científicos de datos se estén capacitando con los mismos datos o que estemos realizando varios experimentos en paralelo en el mismo conjunto de datos. Lo más ingenuo sería duplicar los datos de varios científicos de datos; sin embargo, esto acabará costándonos mucho más. Una forma más eficiente de hacerlo consistiría en almacenar los datos de entrenamiento en un volumen y subirlo a los cuadernos de los distintos científicos de datos.
Almacenamiento de modelos: Si alojamos modelos como API en tiempo real, habrá varias réplicas del servidor de API para gestionar el tráfico. Aquí, cada réplica debe descargar el modelo del registro de modelos (por ejemplo, S3) al disco local. Si cada réplica lo hace repetidamente, tardará más tiempo en iniciarse y, además, generará más costos de acceso a S3. Con los volúmenes, puede almacenar los modelos entrenados de forma externa y montarlos en el servidor de inferencia. No es necesario descargar el modelo; el servidor de API solo tiene que encontrar el modelo en el disco, en la ruta de montaje.
Intercambio de artefactos: Podríamos tener un caso de uso en el que la producción de una etapa de canalización deba ser consumida por la siguiente etapa. Por ejemplo, después de ajustar un modelo, es posible que necesitemos alojarlo como una API solo para experimentar. Si bien podemos escribir el modelo en S3 y luego volver a descargarlo desde S3, el proceso de carga/descarga del modelo llevará mucho tiempo. En vez de eso, para experimentar más rápidamente, el trabajo de ajuste puede simplemente escribir el modelo en un volumen y el servicio de inferencia puede entonces montar el volumen con el modelo.
Puntos de control: Durante el entrenamiento de los modelos de aprendizaje automático, es habitual guardar los puntos de control periódicamente para reanudar el entrenamiento en caso de fallo o para ajustar los modelos. Los volúmenes se pueden usar para almacenar estos archivos de puntos de control, lo que garantiza que el progreso de la capacitación no se pierda cuando una tarea se reinicia debido a un error. Esto también le permite ejecutar instancias de formación in situ, lo que supone un gran ahorro de costes.
Ahora, hablando de casos de uso de ML. En la mayoría de los casos, los ingenieros de aprendizaje automático obtienen los datos en S3 Bucket, GCS Buckets o Azure Blob Storage. Ahora, si quieren entrenar modelos a partir de estos datos, tienen que descargarlos para incorporarlos a su carga de trabajo de formación (ya sea una tarea desplegada o un bloc de notas) o colocar el contenido de su depósito directamente en la carga de trabajo.
¿Cuándo usar el almacenamiento por volumen frente a almacenamiento por bloques como S3, GCS o Azure Container?
Es importante elegir cuándo elegir el almacenamiento en bloques, como S3, frente al volumen, desde el punto de vista del rendimiento, la confiabilidad y los costos.
Rendimiento
En la mayoría de los casos, la lectura de los datos de S3 será más lenta que la lectura directa de los datos de un volumen. Por lo tanto, si la velocidad de carga es crucial para usted, el volumen es la elección correcta. Un ejemplo excelente de esto es descargar y cargar el modelo en el momento de la inferencia en varias réplicas del servicio. Un volumen es la mejor opción, ya que no se pierde el tiempo necesario para descargar el modelo repetidamente y se puede cargar el modelo en la memoria desde el volumen mucho más rápido.
Fiabilidad
Los almacenamientos de blobs como S3/GCS/ACS suelen ser más confiables que los volúmenes. Por lo tanto, lo ideal es hacer siempre una copia de seguridad de los datos sin procesar en uno de los almacenamientos de blobs y utilizar los volúmenes solo para los datos intermedios. También debe guardar permanentemente una copia de los modelos en S3.
Coste
El acceso a volúmenes como EFS es un poco más económico que usar S3, por lo que si busca los mismos datos con bastante frecuencia, puede resultar útil almacenarlos en un volumen. Si lee o escribe con muy poca frecuencia, entonces S3 debería funcionar bien.
Restricciones de acceso
Lo ideal es que solo puedan acceder a los datos en volúmenes las cargas de trabajo de la misma región y clúster. Se ha diseñado para acceder a S3 de forma global y en entornos de nube, por lo que los volúmenes no son una buena opción si desea acceder a los datos en una región o proveedor de nube diferente.
Modos de aprovisionamiento de volúmenes
Para admitir todos los tipos de volúmenes, TrueFoundry proporciona dos modos de aprovisionamiento de volúmenes que se adaptan a diferentes casos de uso:
Dinámica
Se trata de volúmenes que se crean de forma dinámica y se aprovisionan a medida que se implementa un volumen en truefoundry. Por ejemplo, EBS, EFS en AWS y AzureFiles en Azure se pueden aprovisionar dinámicamente en Truefoundry.
Estática
Se trata de volúmenes para los que ya existe un volumen de almacenamiento y queremos montar los datos de ese volumen de almacenamiento en nuestro servicio/trabajo. Los ejemplos incluyen el montaje de cubos S3 y cubos de GCS en las cargas de trabajo implementadas en la plataforma.
Por lo tanto, comprendamos cómo funcionan estas dos y qué opciones están disponibles en cada nube:
Volúmenes aprovisionados dinámicamente
Los volúmenes aprovisionados dinámicamente requieren que especifiques una clase de almacenamiento. Un volumen se aprovisiona de forma dinámica según la clase de almacenamiento y el tamaño proporcionados por el usuario.
Por lo tanto, entendamos qué es una clase de almacenamiento y las diferentes clases de almacenamiento disponibles en cada nube:
Clases de almacenamiento
Las clases de almacenamiento proporcionan una forma de especificar el tipo de almacenamiento que se debe aprovisionar para un volumen. Estas clases de almacenamiento difieren en sus características, como el rendimiento, la durabilidad y el costo. Puedes seleccionar la clase de almacenamiento adecuada para tu volumen en el menú desplegable Clases de almacenamiento mientras lo creas.
Las clases de almacenamiento específicas disponibles dependerán del proveedor de nube que esté utilizando y de lo que esté preconfigurado por el equipo de Infra. Por lo general, verás las siguientes opciones en las clases de almacenamiento según el proveedor de la nube:
Clases de almacenamiento de AWS
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
efs-sc
Elastic File System (EFS)
efs.csi.aws.com
A fully managed, scalable, and highly durable elastic file system that offers high availability, automatic scaling, and cost-effective general file sharing. It's suitable for workloads with varying capacity needs.
Clases de almacenamiento de GCP
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
standard-rwx
Google Basic HDD Filestore
filestore.csi.storage.gke.io
A cost-effective and scalable file storage solution ideal for general-purpose file storage and cost-sensitive workloads. It offers lower cost but also lower performance due to its HDD-based nature.
premium-rwx
Google Premium Filestore
filestore.csi.storage.gke.io
Provides higher performance and throughput compared to Basic HDD, making it suitable for I/O-intensive file operations and demanding workloads. It's SSD-based, offering higher performance at a higher cost.
enterprise-rwx
Google Enterprise Filestore
filestore.csi.storage.gke.io
Delivers the highest performance, throughput, advanced features, multi-zone support, and high availability, making it ideal for mission-critical workloads and applications with strict availability requirements. It comes with the highest cost.
Clases de almacenamiento de Azure
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
azurefile
Azure File Storage (Standard)
file.csi.azure.com
Uses Azure Standard storage to create file shares for general file sharing across VMs or containers, including Windows apps. It offers cost-effective performance.
azurefile-premium
Azure File Storage (Premium)
file.csi.azure.com
Uses Azure Premium storage for higher performance, making it suitable for I/O-intensive file operations.
azurefile-csi
Azure File Storage (StandardCSI)
file.csi.azure.com
Leverages Azure Standard storage with CSI for dynamic provisioning, potentially offering better performance and CSI features.
azurefile-csi-premium
Azure File Storage (PremiumCSI)
file.csi.azure.com
Combines Azure Premium storage with CSI for dynamic provisioning and high-performance file operations.
azureblob-nfs-premium
Azure Blob Storage (NFS Premium)
blob.csi.azure.com
Uses Azure Premium storage with NFS v3 protocol for accessing large amounts of unstructured data and object storage, catering to demanding workloads with NFS access.
azureblob-fuse-premium
Azure Blob Storage (Fuse Premium)
blob.csi.azure.com
Uses Azure Premium storage with BlobFuse for accessing large amounts of unstructured data and object storage, suitable for workloads that require BlobFuse access.
Volúmenes aprovisionados estáticamente
Los volúmenes aprovisionados estáticamente le permiten montar lo siguiente como un volumen:
Cucharón GCS
Cucharón S3
EFS existente
Cualquier volumen general sobre Kubernetes
Para usar volúmenes aprovisionados de forma estática, debes crear un «PersistentVolume» que haga referencia a tu almacenamiento (S3/GCS, etc.). Para ello, tendrás que instalar los controladores CSI necesarios en el clúster o configurar las cuentas de servicio pertinentes para obtener los permisos. En la siguiente sección, analizaremos cómo puede crear volúmenes aprovisionados de forma estática.
Montar un cubo GCS como volumen
Para montar un cubo de GCS como volumen en truefoundry, debes seguir los siguientes pasos. Puedes hacer referencia a esto documento para obtener más información:
Crear un bucket de GCS
Crea un bucket de GCS y asegúrate de lo siguiente:
Debe ser de una sola región (varias regiones funcionarán, pero la velocidad será más lenta y los costos serán más altos)
La región debe ser la misma que la de tu clúster de Kubernetes
Crear una cuenta de servicio y conceder los permisos pertinentes
Debe ejecutar el siguiente script. Esto hace lo siguiente:
Habilita el controlador GCS Fuse en el clúster
Crea una política de IAM para acceder a tu bucket
Cree la cuenta de servicio de K8 y agregue la política a esta cuenta de servicio
Permite la vinculación de funciones de la cuenta de servicio al espacio de nombres K8s deseado.
Crear una cuenta de servicio en Workspace desde la interfaz de usuario de Truefoundry
Ahora necesitamos crear una cuenta de servicio en TrueFoundry en el mismo espacio de trabajo con el nombre: TARGET_NAMESPACE y la cuenta de servicio debe tener el nombre GCP_SA_NAME.
Ve a Espacios de trabajo -> Elige tu espacio de trabajo, haz clic en los tres puntos de la derecha y haz clic en Editar:
Abre Opciones avanzadas en la parte inferior izquierda del formulario y rellena el Cuenta de servicio sección:
Nota
El nombre de la cuenta de servicio y el espacio de trabajo deben ser exactamente los mismos que en el paso anterior.
Crear un objeto PersistentVolume
Crea un objeto de volumen persistente con el siguiente paso. (haciendo una aplicación de kubectl)
Para montar un bucket S3 como volumen en Truefoundry, debes seguir los siguientes pasos:
Configuración de políticas de IAM y funciones relevantes
Por favor, sigue esto documento de AWS para configurar el punto de montaje de S3 en un clúster de EKS.
Esto lo guiará para hacer lo siguiente:
Cree una política de IAM para conceder permisos para que el punto de montaje acceda al bucket s3
Cree un rol de IAM.
Instale el controlador Mountpoint for Amazon S3 CSI y adjunte la función que se creó anteriormente.
Creación de un volumen persistente en el clúster de Kubernetes
Crea un PV con la siguiente especificación (haciendo una aplicación de kubectl):
YAML
apiVersion: v1
kind: PersistentVolume
metadata:
name:
spec:
capacity:
storage: 100Gi
csi:
driver: s3.csi.aws.com
volumeHandle: s3-csi-driver-volume # must be unique
volumeAttributes:
bucketName:
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: s3-test # put any value here
mountOptions:
- allow-delete
- region
- allow-other
- uid=1000
volumeMode: Filesystem
Montar un EFS existente como volumen
Para montar un bucket S3 como volumen en TrueFoundry, debes seguir los siguientes pasos:
Instale el controlador EFS CSI en su clúster
Para instalar el controlador EFS CSI en su clúster, vaya a la interfaz de usuario de Truefoundry -> clústeres-> Aplicaciones instaladas-> Administrar
Desde el Volúmenessección, haga clic en instalar el controlador AWS EFS CSI y haga clic en Instalar.
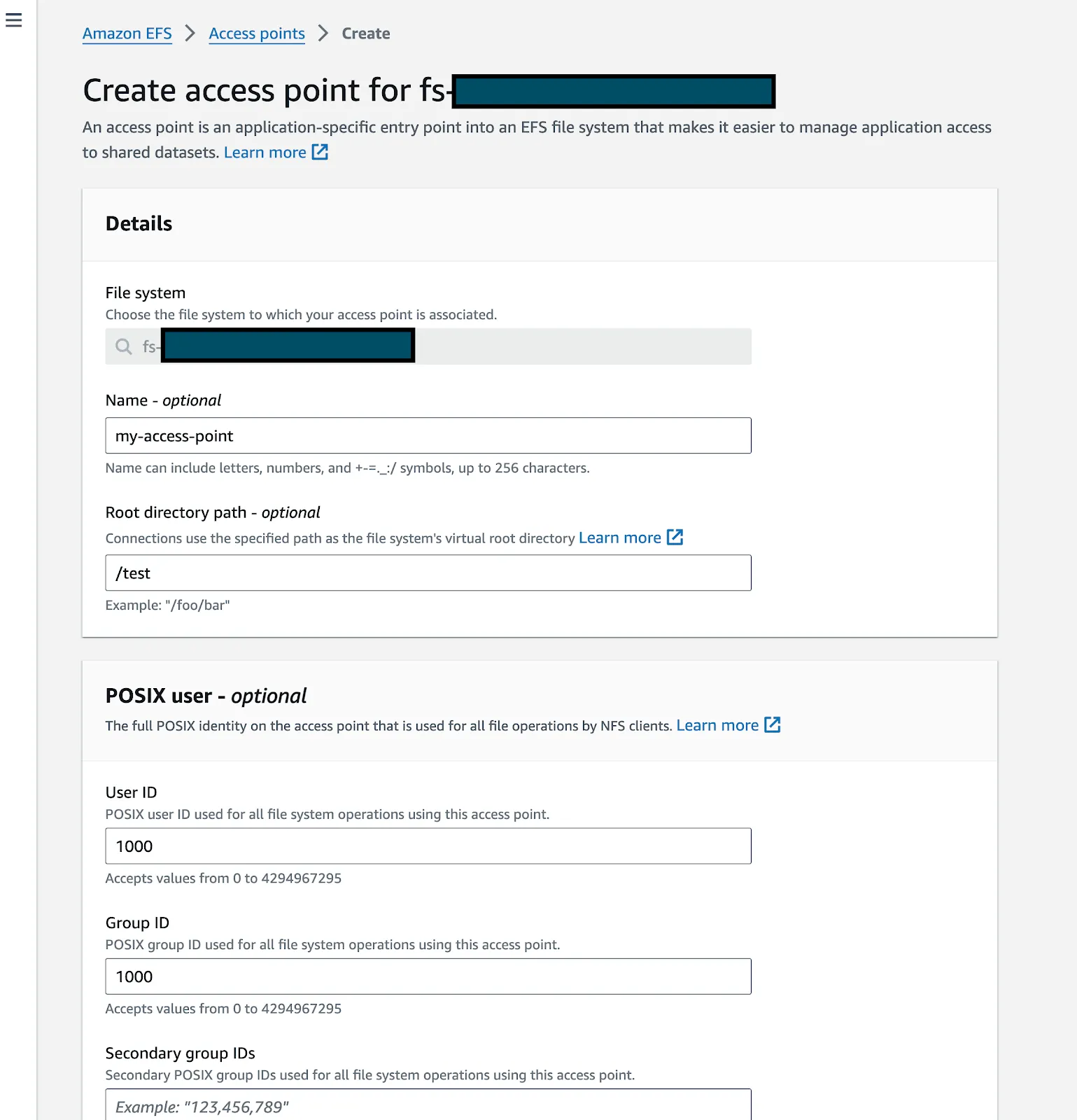
Cree un punto de acceso para su EFS
Localice su EFS en la consola de AWS y ábrala. Asegúrese de que el EFS y el clúster K8S estén en la misma VPC. Haga clic en «Crear punto de acceso»
Ingresa detalles como el nombre y la ruta del directorio raíz (asegúrate de completar la sección de permisos de creación del directorio raíz, puedes completarla con UID:1000 GID:1000 si quieres adjuntarlo al cuaderno)
Haz clic en crear.
Crear un PersistentVolume en el clúster
Crea un PV con la siguiente especificación (haciendo una aplicación de kubectl):
YAML
apiVersion: v1
kind: PersistentVolume
metadata:
name:
spec:
capacity:
storage: 5Gi # this number doesn't matter for EFS, any number will work
csi:
driver: efs.csi.aws.com
volumeHandle: :: # e.g. fs-036e93cbb1fabcdef::fsap-0923ac354cqwerty
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
volumeMode: Filesystem
Crear un volumen en TrueFoundry
Por favor, sigue esto sección para crear volumen en TrueFoundry
Uso de volúmenes en Truefoundry
Con las guías anteriores, puede aprovisionar volúmenes fácilmente o usar los contenedores de almacenamiento existentes como volúmenes. Ahora, estos volúmenes se pueden montar en cualquier carga de trabajo en Kubernetes. Si lo usa, puede montar fácilmente su volumen para cualquier carga de trabajo en TrueFoundry. Puede montarlo fácilmente en un servicio o, de manera similar, cualquier carga de trabajo implementada en Truefoundry. También puedes habilitar un explorador de archivos para explorar el contenido del volumen con solo unos pocos clics utilizando nuestro explorador de volúmenes.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga






































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


