

August 27, 2025
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En el último número analizamos el flujo de trabajo de un científico de datos y vimos dónde exactamente Kubernetes puede resultar una base útil sobre la que construir una plataforma para ello.
En este número, veamos un ejemplo sencillo para ganar experiencia práctica con lo mismo.
Antes de empezar necesitamos un patio de recreo para realizar la demo. Para ello, configuraremos un clúster de Kubernetes en la máquina local. Si bien un clúster debe contener varios nodos para garantizar la tolerancia a los errores y la alta disponibilidad, imitaremos ese comportamiento con una herramienta increíble amable (kubernetes en Docker).
Al final de esta sección, tendremos varios contenedores ejecutándose y cada contenedor actuará como un nodo de clúster independiente.
Siga las instrucciones proporcionadas aquí
Pruebe la instalación ejecutando
$ kind --version
kind versión 0.14.0
Ahora iniciamos un clúster local usando amable. Crearemos un plano de control y dos nodos de trabajo. Es posible tener varios de ambos.
<aside>💡 Kubernetes puede tener varios planos de control y nodos de trabajo. Todos los componentes de administración de clústeres centralizados se encuentran en los nodos del plano de control, mientras que la carga de trabajo de los usuarios se ejecuta en los nodos de trabajo. Lea más aquí
</aside>
En primer lugar, crea un amable configuración en un archivo llamado kind-config.yaml. Puedes encontrarlo aquí. Esto definirá la estructura de nuestro clúster -
tipo: Clúster
Versión de API: kind.x-k8s.io/v1alpha4
nodos:
- rol: plano de control
- rol: trabajador
- rol: trabajador
Aquí, hemos definido tres nodos, uno en la función de plano de control y otros dos como nodos de trabajo.
Lanza un clúster con esta configuración. Esto puede llevar algún tiempo. Asegúrese de que el daemon de Docker esté activo en su sistema antes de ejecutar esto -
$ kind create cluster --config kind-config.yaml
...
¡Gracias por usar kind! 😊
kubectl para asegurarnos de que nuestro clúster esté activo -Información del clúster $ kubectl
El plano de control de Kubernetes se ejecuta en < https://127.0.0.1:63122 >
CoreDNS se ejecuta en < https://127.0.0.1:63122/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy >
...
Esto nos indica que el clúster está realmente activo. También podemos ver los contenedores individuales actuando como nodos al ejecutar Docker PS.
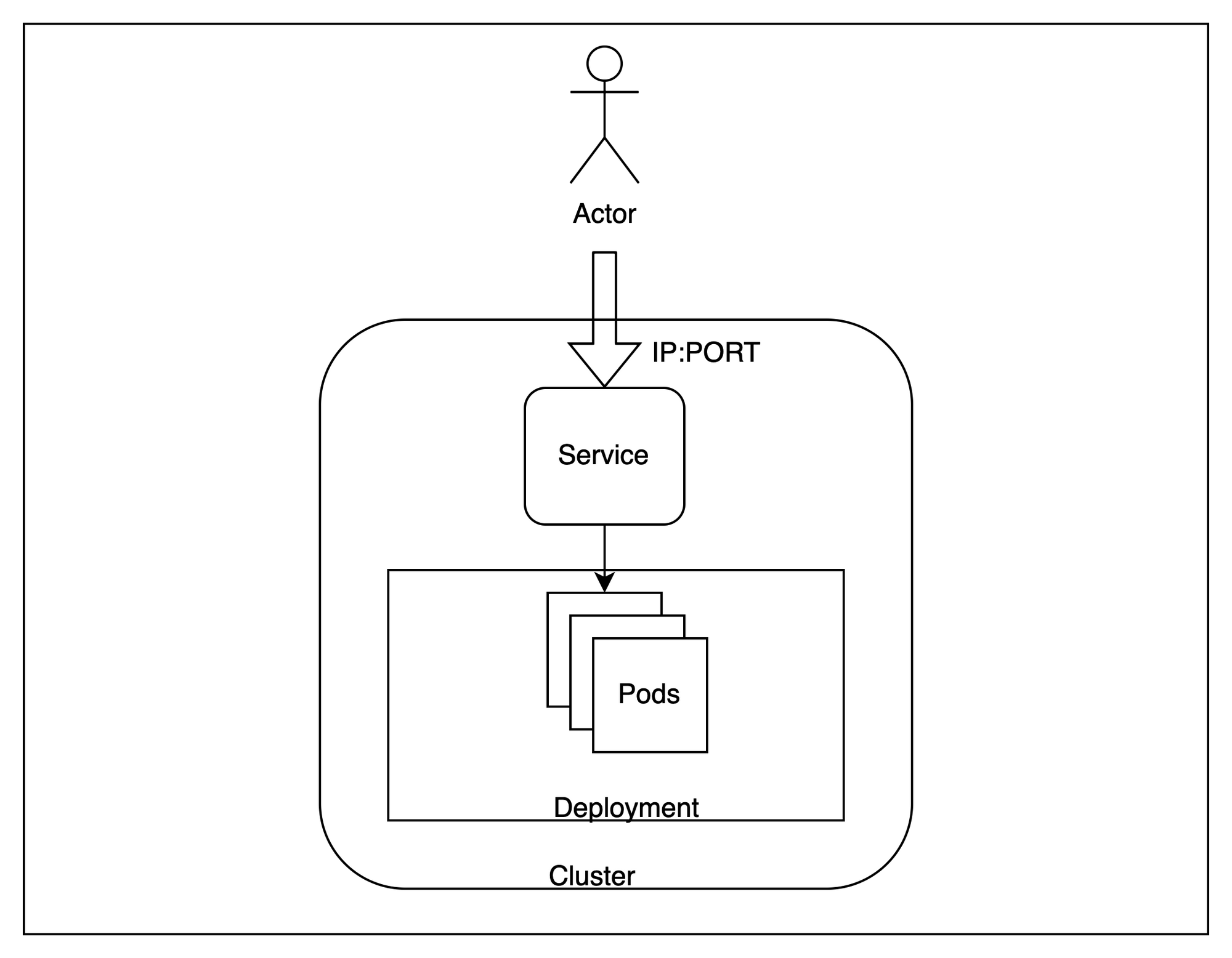
Con nuestro clúster en funcionamiento, analicemos una arquitectura amplia de lo que estamos a punto de aprovisionar.
En términos generales, alojaremos varias réplicas de nuestra aplicación dentro del clúster e intentaremos acceder a ellas desde fuera, equilibrando la carga de las solicitudes en las distintas instancias.
Para lograr esto, hay algunos términos específicos de Kubernetes que debemos conocer:
Cápsula - Los pods son las unidades informáticas desplegables más pequeñas que se pueden crear y administrar en Kubernetes. En nuestro caso, una instancia de la aplicación se ejecutará dentro de un pod independiente. Se trata de recursos efímeros y el plano de control puede moverlos entre los nodos si es necesario.Despliegue - Una implementación es útil cuando queremos tener más de una réplica para una aplicación. Kubernetes intenta mantener siempre la cantidad de réplicas igual a la que se proporciona en una implementación. Crearemos tres réplicas idénticas para nuestra aplicación.Servicio - Un servicio es útil para equilibrar la carga en un conjunto de pods que se ejecutan en el clúster. Como los pods son esencialmente efímeros y se pueden reemplazar en cualquier momento, el servicio proporciona una interfaz estable para acceder a los pods que se encuentran detrás de él. Usaremos un servicio para probar nuestra aplicación.Estos tres recursos nos permitirán alojar un punto final escalable para atender nuestra aplicación.
Con el clúster activo, ahora podemos implementar una aplicación y probarla. Crearemos una aplicación utilizando el popular conjunto de datos clasificadores de iris.
El repositorio está disponible en https://github.com/shubham-rai-tf/iris-classifier-kubernetes. Ya contiene el código para crear y publicar predicciones en /iris/classify_iris punto final usando API rápida.
Necesitamos empaquetar este código en una imagen de Docker para prepararlo para kubernetes. UN Archivo Docker se proporciona en el repositorio para hacer eso - aquí.
Esto Archivo Docker especifica la imagen que necesitaremos para crear un contenedor que aloje los puntos finales de predicción en un uvicornio servidor en el puerto 5000. Hay más detalles disponibles sobre la sintaxis aquí.
Ejecute este comando para crear una imagen local -
$ docker build. -t iris-classifier: poc
...
$ docker image ls
TAMAÑO CREADO DEL IDENTIFICADOR DE IMAGEN DE LA ETIQUETA DEL REPOSITORIO
iris-classifier poc 549913d5b1f9 Hace 12 segundos 737MB
Podemos ver que la imagen se ha creado correctamente con el nombre clasificador iris y etiqueta poc. Ahora cargaremos esta imagen en el clúster para usarla dentro del clúster
<aside>💡 Este paso solo es necesario porque no tenemos un registro de imágenes del que extraer la imagen recién creada. En producción, la imagen debe alojarse en un registro privado, como Dockerhub o AWS ECR, y luego introducirse directamente en el clúster
</aside>
Ejecute este comando para cargar la imagen creada localmente en el clúster -
$ kind load docker-image iris-classifier:poc
La imagen: «iris-classifier:poc» con ID «sha 256:549913 d5b1f9456a4beedc73e04c3c0ad70da8691a8745a6b56a4f483c4f0862» aún no está presente en el nodo «kind-worker2", cargando...
La imagen: «iris-classifier:poc» con ID «sha 256:549913 d5b1f9456a4beedc73e04c3c0ad70da8691a8745a6b56a4f483c4f0862», aún no está presente en el nodo «kind-control-plane», cargando...
...
Puedes comprobar que las imágenes se han cargado publicándolas en cualquiera de los tres contenedores -
$ docker exec -it kind-worker imágenes críticas
ETIQUETA DE IMAGEN TAMAÑO DE IDENTIFICACIÓN DE IMAGEN
docker.io/library/iris-classifier poc 549913d5b1f94 753 MB
Kubernetes es esencialmente un sistema declarativo. Es decir, describimos los contornos de lo que queremos hacer y los componentes del plano de control impulsan constantemente al sistema para que alcance ese estado.
Para implementar la arquitectura de la que hablamos anteriormente, describiremos nuestra intención en forma de yaml archivo que actúa como registro de intenciones. En el lenguaje de Kubernetes, estos se denominan manifiesta.
Todos los manifiestos de Kubernetes tienen los siguientes campos:
Versión API - Se agrupan varios recursos en las mismas versiones de la API. Esto proporciona una forma estandarizada de desaprobar o promover un recurso en todas las versiones de Kubernetes.amable - Identifica el tipo de objeto exacto que se va a crearmetadatos - Contiene campos que actúan como metadatos para el objeto creado. - El Versión API, amable y metadata.name los campos juntos identifican un recurso único dentro de un espacio de nombresespecificaciones - Este campo contiene la especificación del objeto que se va a crear. Cada tipo define su propia estructura para este campo con su propia implementación.Usaremos los manifiestos presentes en el repositorio en los archivos del manifiesta directorio aquí.
Define dos recursos de Kubernetes, Despliegue y Servicio en deployment.yaml y servicio.yaml respectivamente. Repasemos ambas secciones.
Versión de API: aplicaciones/v1
tipo: Despliegue
especificación:
# número de réplicas
réplicas: 3
plantilla:
especificación:
contenedores:
# nombre de la imagen
- imagen: iris-classifier:poc
nombre: iris-classifier
El manifiesto de despliegue en deployment.yaml define principalmente la especificación del pod que queremos implementar en términos del nombre de la imagen y la cantidad de réplicas. Una vez que apliquemos esto, Kubernetes tomará medidas constantemente para mantener la cantidad de réplicas según lo que especificamos aquí.
Versión de API: v1
tipo: Servicio
especificación:
# Tipo de servicio
tipo: ClusterIP
puertos:
# Puerto donde se podrá acceder al servicio
- puerto: 8080
# Puerto del contenedor al que se va a reenviar el tráfico
Puerto objetivo: 5000
protocolo: TCP
selector:
aplicación: iris-classifier
El manifiesto de servicio en servicio.yaml define cómo equilibrar la carga en las réplicas creadas por la implementación. Aquí hemos definido cómo se asignará el puerto en servicio al puerto de los contenedores. Como nuestra aplicación se ejecuta en el puerto 5000, el Puerto de destino está establecido en 5000. El servicio está expuesto en el puerto 8080. El tráfico TCP enviado al 8080 se equilibrará en cuanto a la carga en el puerto 5000 de los contenedores.
Ejecute el siguiente comando para aplicar los manifiestos a kubernetes:
$ kubectl apply -f manifests/
Se creó el clasificador deployment.apps/iris
servicio/clasificador de iris creado
Ambos recursos se crearon correctamente en el clúster. Podemos verificar la ejecución de los siguientes comandos:
$ kubectl get service iris-classifier
TIPO DE NOMBRE CLUSTER-IP PUERTO (S) IP EXTERNO EDAD
<none>clasificador iris ClusterIP 10.96.107.238 8080/TCP 37 m
$ kubectl get deployment iris-classifier
NOMBRE LISTO EDAD DISPONIBLE ACTUALIZADA
clasificador iris 3/3 3 3 38m
$ kubectl consigue cápsulas
EL ESTADO DE NOMBRE LISTO REINICIA LA EDAD
iris-classifier-5d97498ff9-77wqw 1/1 Corriendo 0 39 m
iris-classifier-5d97498ff9-8twjm 1/1 Corriendo 0 39 m
iris-classifier-5d97498ff9-znrz8 1/1 Corriendo 0 39 m
Como podemos ver, el servicio está expuesto en el puerto 8080 y se han creado tres pods como especificamos.
Modificar deployment.yaml tener 2 réplicas en lugar de 3 y volver a solicitarlas. Kubernetes eliminará una de las réplicas para que coincida con la especificación.
Ahora que los recursos se han creado en el clúster, podemos verificar nuestra implementación llamando al modelo mediante el punto final del servicio. Como estamos usando una configuración local, tendremos que puerto hacia adelante el servicio a un puerto de la máquina local.
<aside>💡 En la configuración de un proveedor de nube, este servicio estará vinculado a un balanceador de cargas externo al que se puede acceder desde Internet si es necesario.
</aside>
Ejecute el siguiente comando para realizar el reenvío de puertos para el servicio:
$ kubectl port-forward services/iris-classifier 8080
Reenvío desde 127.0.0. 1:8080 -> 5000
Reenviar desde [::1] :8080 -> 5000
Podemos verificarlo llamando al /chequeo de estado punto final en el modelo -
< http://localhost:8080/healthcheck >$ curl ''
«¡El clasificador Iris está listo!»
Para realizar una predicción de prueba, enviaremos una entrada de muestra para obtener una predicción -
$ curl ''< http://localhost:8080/iris/classify_iris > -X POST\\
-H 'Tipo de contenido: aplicación/json'\\
-d '{"longitud del sépalo»: 2, «ancho del sépalo»: 4, «longitud del pétalo»: 2, «ancho del pétalo»: 4}'
{"class» :"setosa», "probabilidad» :0.99}
Obtenemos una predicción de la clase setosa con una probabilidad del 99%. Al ejecutar varias de estas predicciones, podemos verificar que las solicitudes se están dirigiendo efectivamente a diferentes grupos de forma rotatoria.
Eliminemos primero todos los recursos de Kubernetes que habíamos instalado -
$ kubectl delete -f manifests/
Esto limpiará todos los recursos de Kubernetes que habíamos creado en las secciones anteriores. Ahora también podemos eliminar el clúster -
$ kind eliminar clúster
Eliminando el «tipo» de clúster...
En este número, analizamos cómo alojar un modelo como un servicio invocable en Kubernetes. Si bien este fue un ejemplo de juguete en el que creamos una imagen de Docker localmente y la ejecutamos en un clúster que se ejecuta en la misma máquina, una configuración de producción típica funciona según principios similares. Se puede lograr mucho con solo estos dos recursos.
En los números siguientes, exploraremos otras funciones más avanzadas, como la tenencia múltiple y el control de acceso, que se vuelven esenciales a medida que avanzamos hacia las operaciones del segundo día.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


