



August 27, 2025
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Bienvenido a esta serie sobre cómo crear y configurar una infraestructura de aprendizaje automático escalable en un entorno de Kubernetes. En esta serie, abordaremos varios temas relacionados con el desarrollo, la implementación y la administración de modelos de aprendizaje automático en un clúster de Kubernetes.
Las operaciones de aprendizaje automático, comúnmente conocidas como MLOps, se refieren a las prácticas y técnicas que se utilizan para administrar el ciclo de vida de los modelos de aprendizaje automático. La infraestructura escalable de operaciones de aprendizaje automático permite a las organizaciones crear, implementar y gestionar modelos a escala, lo que aumenta el retorno de la inversión (ROI) de sus iniciativas de ciencia de datos.
Los beneficios de una infraestructura mLOps escalable incluyen:
Airbnb invirtió mucho en la creación de una práctica de MLOps escalable desde el principio. Utilizó modelos de aprendizaje automático para mejorar sus algoritmos de clasificación de búsquedas mediante búsquedas basadas en los datos de los usuarios, lo que se tradujo en una mejor experiencia de búsqueda y en un aumento estimado del 10% en las reservas. Airbnb también utilizó modelos de aprendizaje automático para ofrecer recomendaciones personalizadas a sus usuarios, ¡lo que ayudó a mejorar la experiencia y la participación de los usuarios!
Las organizaciones que confían en máquinas virtuales (VM), ya sea en AWS, Google Cloud Platform (GCP) o Microsoft Azure, para configurar su infraestructura de capacitación e implementación de aprendizaje automático pueden enfrentarse a varios desafíos:
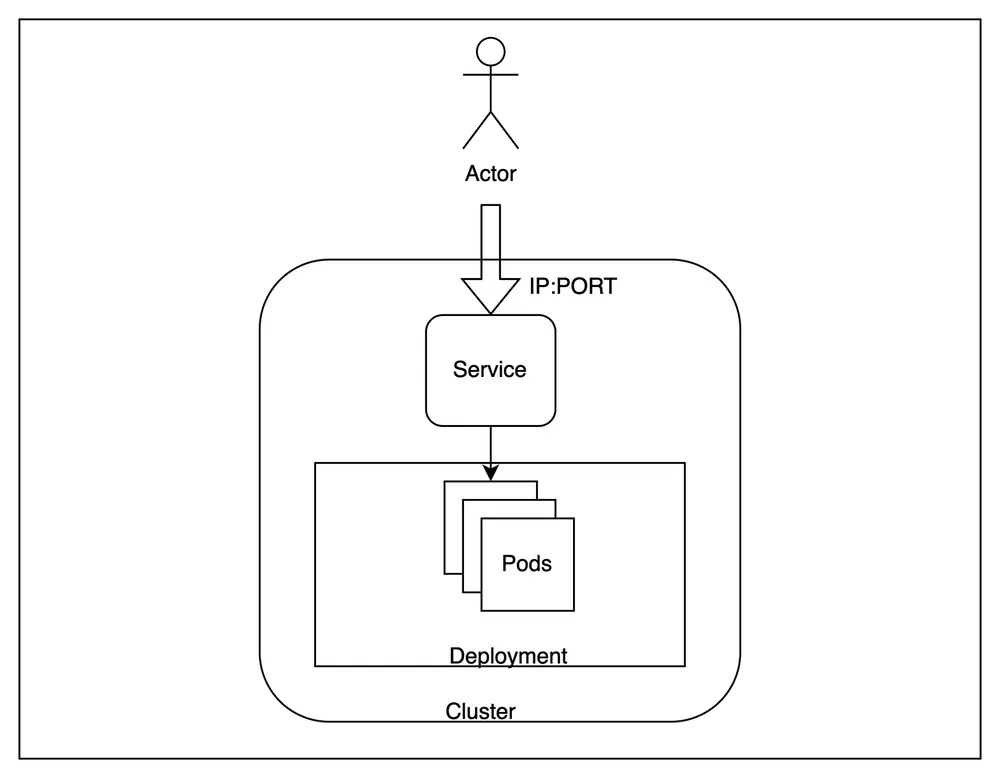
Kubernetes es una popular plataforma de orquestación de contenedores de código abierto que automatiza el despliegue, el escalado y la administración de aplicaciones en contenedores. Proporciona una API unificada y una configuración declarativa que simplifica la administración de las cargas de trabajo en contenedores, lo que permite a las organizaciones crear una infraestructura escalable, resiliente y portátil para entrenar e implementar modelos de aprendizaje automático. Kubernetes ofrece varias ventajas en comparación con las máquinas virtuales sin procesar, como una mejor utilización de los recursos, un control de versiones simplificado y un escalado eficiente. Además, Kubernetes ofrece funciones de seguridad integradas y capacidades centralizadas de monitoreo y registro, que pueden ayudar a las organizaciones a garantizar la seguridad y confiabilidad de su infraestructura de aprendizaje automático. Kubernetes es una excelente opción para las organizaciones que buscan crear canales de aprendizaje automático escalables a largo plazo.
Los proveedores de nube (AWS, GCP y Azure) ofrecen servicios gestionados de Kubernetes (EKS, GKE y AKS, respectivamente) que permiten a las organizaciones configurar, configurar y administrar fácilmente los clústeres de Kubernetes, lo que elimina la sobrecarga operativa asociada con la ejecución y el escalado de Kubernetes. Además, los proveedores de nube ofrecen integraciones con otros servicios en la nube, como almacenamiento, bases de datos y redes, lo que puede simplificar aún más la implementación y la administración de las cargas de trabajo de aprendizaje automático en Kubernetes. Al adoptar Kubernetes directamente o mediante un servicio gestionado, las organizaciones pueden crear una canalización de MLOps flexible y escalable que pueda gestionar sus crecientes cargas de trabajo de aprendizaje automático y acelerar la comercialización de sus modelos de aprendizaje automático.
Analicemos con más detalle los beneficios de usar Kubernetes para las canalizaciones de entrenamiento e implementación del aprendizaje automático
Ejemplo de caso de uso 1: AirBnB
Airbnb, el mercado en línea que permite a las personas alquilar sus casas o apartamentos a los viajeros. Con millones de usuarios y una enorme cantidad de datos que analizar, Airbnb necesitaba una infraestructura de aprendizaje automático sólida y escalable para analizar el comportamiento de los usuarios, mejorar las clasificaciones de búsqueda y ofrecer recomendaciones personalizadas a los usuarios.
Para lograrlo, Airbnb invirtió en la creación de una infraestructura de MLOps en Kubernetes, lo que permitió a su equipo de ciencia de datos desarrollar e implementar modelos de aprendizaje automático a escala. Con Kubernetes, Airbnb pudo contenedorizar sus modelos e implementarlos como microservicios, lo que facilitó la administración y el escalado de su infraestructura a medida que crecían sus necesidades. Como resultado, Airbnb pudo mejorar sus clasificaciones de búsqueda y ofrecer recomendaciones más relevantes a sus usuarios, lo que se tradujo en un aumento de las reservas y de los ingresos. Además, la empresa pudo mejorar la eficiencia de sus flujos de trabajo de ciencia de datos, lo que permitió a su equipo centrarse en desarrollar modelos de aprendizaje automático más avanzados.
Ejemplo de caso de uso 2: Lyft
Lyft, un importante proveedor de transporte como SaaS (TaaS), creó inicialmente su infraestructura de aprendizaje automático sobre AWS mediante una combinación de instancias EC2 y contenedores Docker. Utilizaron instancias EC2 para aprovisionar máquinas virtuales con distintos niveles de recursos de CPU, memoria y GPU, en función de los requisitos específicos de la carga de trabajo de aprendizaje automático. También usaron contenedores Docker para empaquetar e implementar sus cargas de trabajo de aprendizaje automático y garantizar la coherencia en los diferentes entornos.
Sin embargo, a medida que las cargas de trabajo de aprendizaje automático de Lyft crecían en complejidad y escala, se enfrentaron a varios desafíos, incluida la coherencia en diferentes entornos y equipos, y decidieron migrar su infraestructura de aprendizaje automático a una infraestructura basada en Kubernetes utilizando KubeFlow inicialmente y luego una plataforma interna. Al migrar a una infraestructura basada en Kubernetes, Lyft pudo crear una infraestructura de aprendizaje automático más eficiente y escalable, lo que les ayudó a acelerar sus procesos de desarrollo e implementación del aprendizaje automático. Además, pudieron aprovechar las ventajas de Kubernetes, como el escalado automático y la utilización eficiente de los recursos, para optimizar sus cargas de trabajo de aprendizaje automático y reducir los costos de infraestructura. ¡Utilizaron EKS de AWS como su servicio de Kubernetes administrado!
En general, la inversión en infraestructura de MLOps en Kubernetes permitió a Airbnb y Lyft lograr importantes aumentos de productividad y mejorar sus resultados, lo que demuestra el valor que los MLOps escalables sobre Kubernetes pueden aportar a las organizaciones que buscan aprovechar el aprendizaje automático a gran escala.
A pesar de los beneficios, el uso de Kubernetes para la infraestructura de aprendizaje automático conlleva su propio conjunto de desafíos y complejidades:
Si bien existen desafíos, al seguir las mejores prácticas y aprovechar las capacidades de Kubernetes, las organizaciones pueden superar estos desafíos y crear una infraestructura MLOps escalable, segura y confiable.
Kubernetes for Machine Learning ofrece numerosas ventajas para las organizaciones que buscan optimizar sus flujos de trabajo de aprendizaje automático. Si bien la configuración y la administración de la infraestructura de MLOps en Kubernetes plantean desafíos, como la administración de recursos, la seguridad y la supervisión, un conocimiento profundo de Kubernetes y las mejores prácticas puede ayudar a superar estos obstáculos.
En esta serie de ML on Kubernetes, trataremos varios temas relacionados con la creación y configuración de la infraestructura de ML en un entorno de Kubernetes, incluidos los siguientes:
y mucho más..
Al adoptar estas mejores prácticas y aprovechar el poder de Kubernetes, las organizaciones pueden escalar e implementar modelos de aprendizaje automático con coherencia, confiabilidad y seguridad. Esto, a su vez, reduciría el tiempo de comercialización, mejoraría la colaboración entre los equipos de ciencia de datos y de operaciones de TI y mejoraría el ROI de sus inversiones en ciencia de datos.
Descubra cómo Gong ha creado una infraestructura escalable de investigación de aprendizaje automático en Kubernetes
True Foundry es un PaaS de implementación de aprendizaje automático sobre Kubernetes para acelerar los flujos de trabajo de los desarrolladores y, al mismo tiempo, permitirles una flexibilidad total a la hora de probar e implementar modelos, al tiempo que garantiza una seguridad y un control totales para el equipo de Infra. A través de nuestra plataforma, permitimos a los equipos de aprendizaje automático implementar y supervisar modela en 15 minutos con un 100% de confiabilidad, escalabilidad y la capacidad de revertirse en segundos, lo que les permite ahorrar costos y lanzar los modelos a la producción más rápido, lo que permite obtener un verdadero valor empresarial.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


