July 25, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 11, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Bifrost is an open-source, single-binary Go gateway, self-hosted on infrastructure you run, that now handles LLM routing, MCP, and agent-mode auto-execution. TrueFoundry is an enterprise AI platform whose gateway is one layer of a larger control plane. Here's a hands-on, primary-source comparison.
If you're choosing an AI gateway in 2026, Bifrost and TrueFoundry will both land on your shortlist — and they look more alike on a feature grid than they are in practice. We ran Bifrost locally and read both vendors' documentation to write this from primary sources: Bifrost's runtime behavior comes from a running v1.5.7 instance, its enterprise, compliance, and deployment claims from Bifrost / Maxim's docs, and every TrueFoundry claim from its official docs.
Bifrost is a gateway you run: one Go binary, zero external dependencies to start (it boots on a local SQLite store), Apache-2.0 licensed, and self-hosted. TrueFoundry is a platform you adopt: an LLM + MCP + Agent gateway that's part of a Kubernetes-native stack which also deploys and trains models, hosts MCP servers, and runs agents — installable as SaaS, VPC, on-prem, or air-gapped. One is a single, self-contained tool; the other is the governed control plane for the whole AI lifecycle.

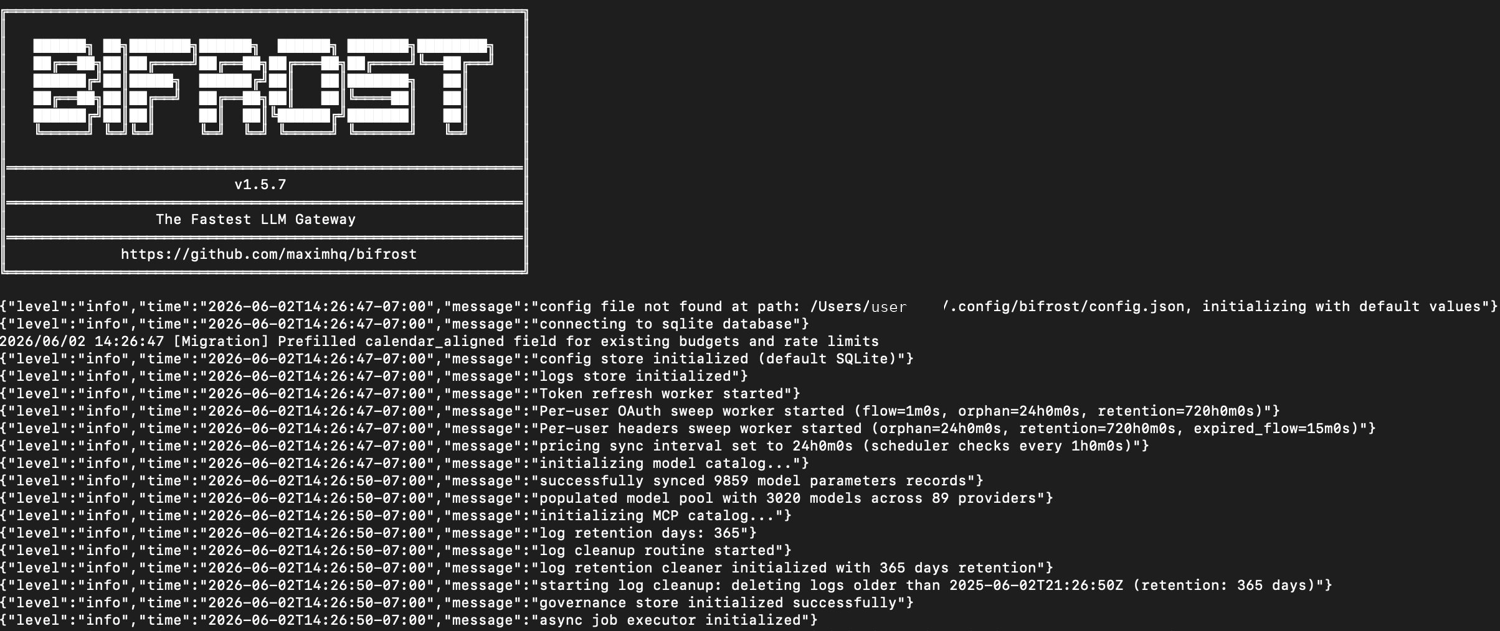
Bifrost's startup tells the story. On first run it finds no config and initializes defaults, connects to a local SQLite database, and stands up config, logs, and governance stores — no external database to begin. It starts workers for token refresh, a per-user OAuth sweep, and a pricing sync, then loads its catalog: in this build, 3,020 models across 89 providers, with 365-day default log retention.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet

.webp)