

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 19, 2026
.webp)
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In dem Maße, in dem Unternehmen generative KI und große Sprachmodelle (LLMs) in die Produktion integrieren, wird das Kostenmanagement immer wichtiger. Token-basierte Preisgestaltung, wie sie bei LLM-Anbietern üblich ist, bringt eine einzigartige Komplexität mit sich:
Ohne eine spezielle LLM-Lösung zur Kostenverfolgung mangelt es den Teams an Transparenz, bis die Kosten unerwartet in die Höhe schnellen. Dies bedroht die Budgets und behindert die Skalierung der Bemühungen.
Hier erfahren Sie, wie Sie durchgängige Nachverfolgung, Steuerung und Optimierung angehen — zusammen mit direkten, natürlichen Links zur TrueFoundry-Dokumentation für jedes Kernelement.
Der Aufbau einer robusten Kostenverfolgung beginnt mit der Erfassung umfassender, strukturierter Daten für jede LLM-Anfrage. Mit dem TrueFoundry KI-Gateway, Sie können den gesamten Inferenzverkehr weiterleiten, egal ob es sich um ein API-Modell (wie OpenAI, Claude oder Mistral) oder um ein selbst gehostetes Modell handelt, das Sie betreiben. Dieses Gateway dient als Ihre „zentrale Anlaufstelle“ für Beobachtbarkeit und Kostenzuweisung.
Bei jeder Anfrage sollten Sie:
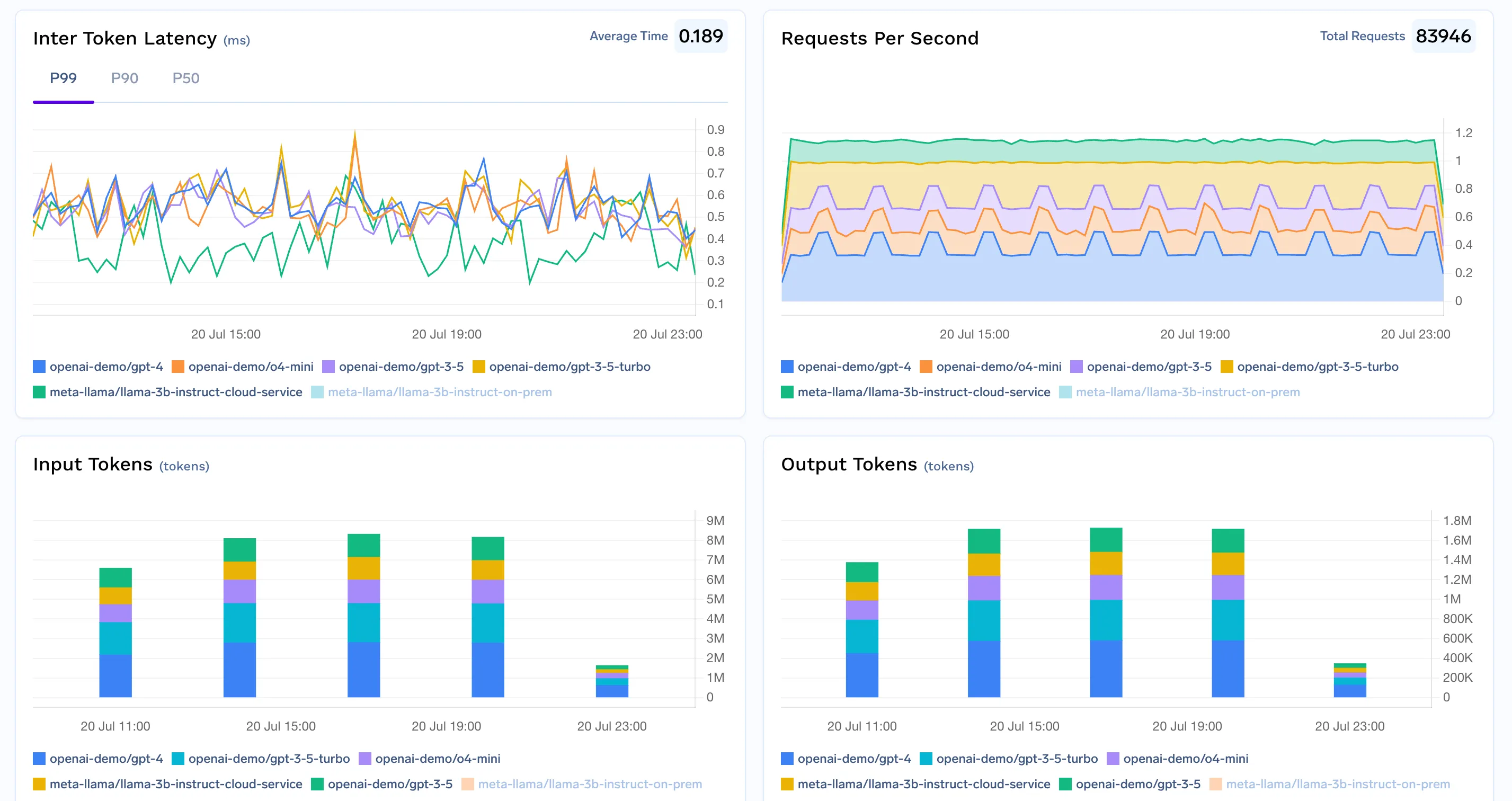
Eine umfassende LLM-Kostenverfolgungslösung muss es Ihnen ermöglichen, Grenzen durchzusetzen vor Budgets werden überschritten.
Zusammen machen diese Governance-Funktionen das Einloggen zu einem Live-, durchsetzbare Lösung zur Kostenverfolgung das verhindert bewusst Überschreitungen — nicht nur durch rückwirkende Berichterstattung.
Nach Beobachtbarkeit und Unternehmensführung Optimierung ist der fortlaufende Prozess der Kostensenkung ohne Einbußen bei Leistung oder Qualität.
Eine erfolgreiche Kostenoptimierung hängt von wachsamen Messungen ab. Folgendes ist wichtig, um Ihren gesamten Stack im Auge zu behalten:
Ein moderner LLM-Lösung zur Kostenverfolgung ist mehr als nur nachträgliche Berichterstattung — es ist eine strategische Kontrollebene für jede Phase des KI-Einsatzes, von der täglichen Steuerung bis hin zur laufenden Optimierung. Durch die Nutzung der umfassenden Funktionen von Das KI-Gateway von TrueFoundry, profitieren Teams von granularer Transparenz, proaktiver Ausgabenkontrolle und kostenbewusstem Routing für jedes von ihnen verwendete LLM, unabhängig davon, ob es sich um eine API oder selbst gehostete Cluster handelt.
Einen detaillierten technischen Überblick finden Sie Schritt für Schritt unter:
Eine LLM-Kostenverfolgungslösung ist eine strategische Kontrollebene zur Überwachung, Verwaltung und Optimierung der individuellen Ausgaben, die mit Large Language Model-Operationen verbunden sind. Im Gegensatz zu herkömmlichen Cloud-Infrastrukturen verfolgt sie speziell die Token-basierte Preisgestaltung, variable Inferenzlasten und rechenintensive Ressourcen. Diese Plattformen bieten einen Überblick über die Ausgaben mehrerer Anbieter, Modelle und Teams in Echtzeit.
Die Erfassung der LLM-Nutzungskosten ist von entscheidender Bedeutung, da die Ausgaben für die KI-Infrastruktur aufgrund der verbrauchsabhängigen Token-Preisgestaltung exponentiell und unbemerkt steigen können. Ohne eine detaillierte Überwachung sehen sich Unternehmen mit massiven Budgetüberschreitungen, unvorhersehbaren monatlichen Abrechnungen und mangelnder finanzieller Rechenschaftspflicht konfrontiert. Eine effektive Nachverfolgung gewährleistet ein nachhaltiges Wachstum, indem jeder ausgegebene Dollar an einen messbaren Geschäftswert und ROI gebunden wird.
Es gibt mehrere spezialisierte Tools und Plattformen, die derzeit marktführend bei der Verwaltung und Verfolgung von LLM-Kosten sind. TrueFoundry bietet ein einheitliches KI-Gateway für das Ausgabenmanagement und die Steuerung mehrerer Modelle. Weitere herausragende Lösungen sind LitelLM, das einen schlanken Proxy für die Ausgabentransparenz in Echtzeit bietet, und Portkey, das sich auf die detaillierte Kostenzuweisung für generative KI-Anwendungen konzentriert.
Ja, die meisten fortschrittlichen LLMOps-Plattformen integrieren nativ eine LLM-Kostenverfolgungslösung, um den gesamten Modelllebenszyklus zu verwalten. Plattformen wie TrueFoundry und Weights & Biases erfassen detaillierte Telemetriedaten in allen Produktionsumgebungen und zeigen neben Leistungskennzahlen auch die Token-Kosten an. Diese native Integration ermöglicht es Entwicklern, sowohl die Genauigkeit als auch die finanzielle Effizienz innerhalb eines einzigen, einheitlichen Workflows zu optimieren.
LLM-Lösungen zur Kostenverfolgung verwenden Echtzeitüberwachung, um automatische Benachrichtigungen per E-Mail, Slack oder Webhooks auszulösen, wenn die Nutzung vordefinierte Prozentsätze eines Budgets erreicht. Diese Systeme können mit automatisierten Durchsetzungsregeln konfiguriert werden, die den Traffic drosseln oder Anfragen blockieren, sobald eine feste Obergrenze erreicht ist. Diese proaktive Warnmeldung verhindert, dass „außer Kontrolle geratene“ Arbeitslasten entstehen, und stellt sicher, dass die finanziellen Schutzmaßnahmen eingehalten werden.
TrueFoundry ist eine ideale LLM-Lösung zur Kostenverfolgung, da sie die Kostenzuweisung in Echtzeit mit einem umfassenden, metadatengestützten Kontext kombiniert. Es ermöglicht Unternehmen, benutzerdefinierte Preise pro Modell zu definieren und granulare Budgetschwellenwerte für bestimmte Teams, Projekte oder Umgebungen festzulegen. Das KI-Gateway optimiert die Ausgaben durch intelligentes Routing, semantisches Caching und automatische Modell-Fallbacks weiter und gewährleistet so eine hohe Leistung zum niedrigstmöglichen Preis.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




