














November 5, 2025
|
5 min read

Published: July 4, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
企業が生成AIと大規模言語モデル(LLM)を本番環境に導入するにつれて、コスト管理は極めて重要になります。LLMプロバイダーで一般的なトークンベースの料金体系は、特有の複雑さをもたらします。
専用のLLMコスト追跡ソリューションがなければ、チームは可視性を欠き、コストが予期せず膨れ上がるまでその状況に気づきません。 これは予算を脅かし、スケーリングの取り組みを妨げます。
エンドツーエンドの追跡、ガバナンス、最適化へのアプローチ方法を説明します。各主要要素については、TrueFoundryのドキュメントへの直接的で自然なリンクも併せて提供します。
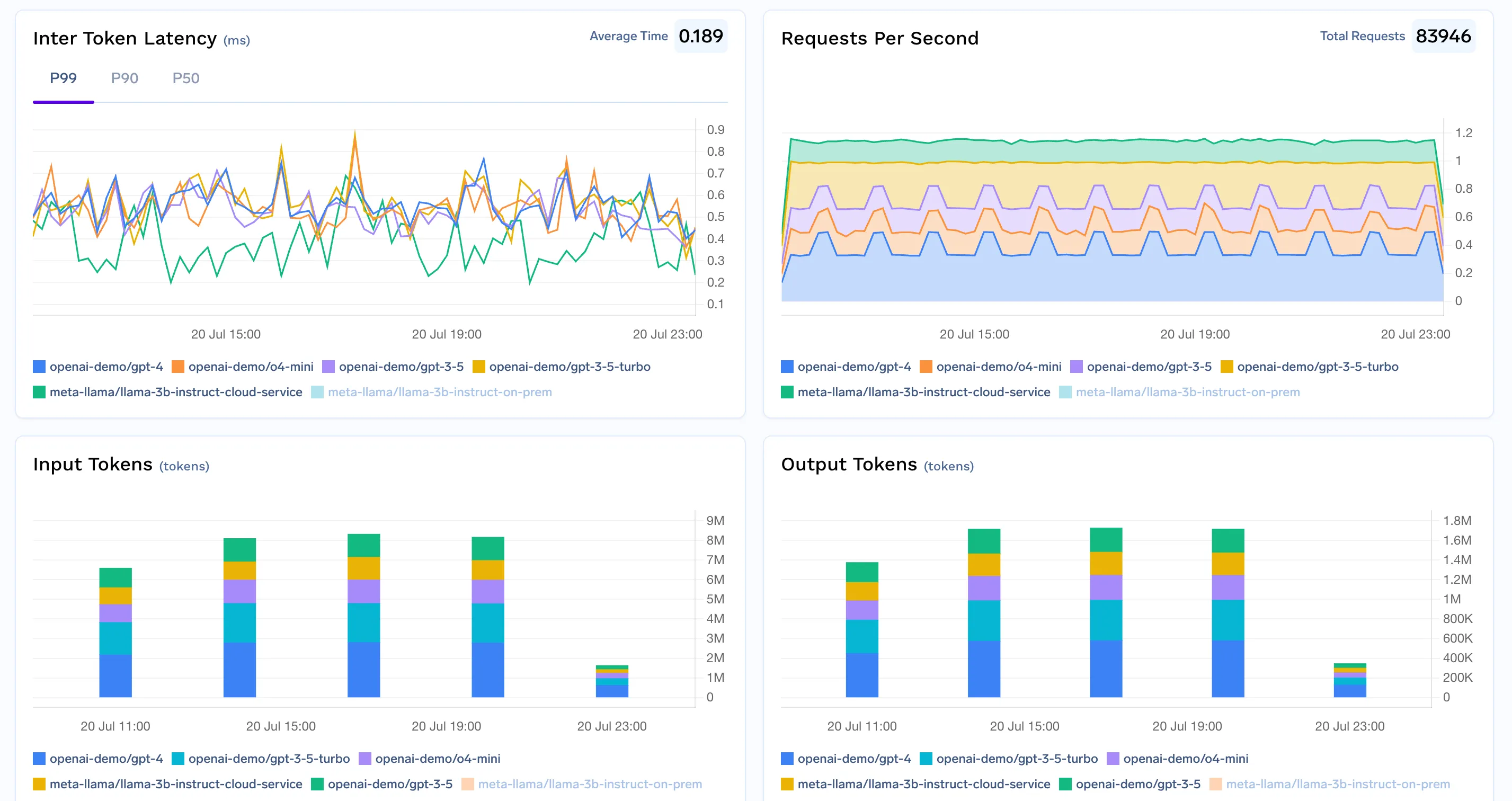
堅牢なコスト追跡を構築するには、すべてのLLMリクエストに対して包括的で構造化されたデータを取得することから始まります。 TrueFoundry AI Gatewayを使用すると、APIモデル(OpenAI、Claude、Mistralなど)であろうと、自社で運用するセルフホスト型モデルであろうと、すべての推論トラフィックをルーティングできます。このゲートウェイは、可観測性とコスト配分のための「シングルペインオブグラス」として機能します。
すべてのリクエストで、以下を行う必要があります。
包括的なLLMコスト追跡ソリューションは、予算が超過する 前に 制限を強制できるものでなければなりません。
これらのガバナンス機能が連携することで、ロギングは リアルタイムで強制力のあるコスト追跡ソリューション となり、事後報告だけでなく、設計段階からコスト超過を防ぎます。
可観測性とガバナンスの次に、 最適化 とは、パフォーマンスや品質を犠牲にすることなく支出を削減し続けるプロセスです。
コスト最適化を成功させるには、厳密な測定が不可欠です。スタック全体で監視すべき重要な項目は以下の通りです。
A modern LLM cost tracking solution is more than just after-the-fact reporting—it’s a strategic control plane for every phase of AI deployment, from daily governance to ongoing optimization. By leveraging the comprehensive features offered by TrueFoundry’s AI Gateway, teams unlock granular visibility, proactive spend controls, and cost-conscious routing for every LLM they use, whether via API or self-hosted clusters.
For a step-by-step technical deep dive, see:
An LLM cost tracking solution is a strategic control plane designed to monitor, manage, and optimize the unique expenses associated with Large Language Model operations. Unlike traditional cloud infrastructure, it specifically tracks token-based pricing, variable inference loads, and compute-intensive resources. These platforms provide real-time visibility into spending across multiple providers, models, and teams.
Tracking LLM usage costs is critical because AI infrastructure expenses can grow exponentially and silently due to consumption-based token pricing. Without granular monitoring, organizations face massive budget overruns, unpredictable monthly billing, and a lack of financial accountability. Effective tracking ensures sustainable growth by tying every dollar spent back to measurable business value and ROI.
There are several specialized tools and platforms that currently lead the market in managing and tracking LLM costs. TrueFoundry offers a unified AI Gateway for multi-model spend management and governance. Other prominent solutions include LiteLLM, which provides a lightweight proxy for real-time spend visibility, and Portkey, which focuses on detailed cost attribution for generative AI applications.
Yes, most advanced LLMOps platforms natively integrate an LLM cost tracking solution to manage the full model lifecycle. Platforms like TrueFoundry and Weights & Biases capture detailed telemetry data across production environments, displaying token costs alongside performance metrics. This native integration allows developers to optimize both accuracy and financial efficiency within a single, unified workflow.
LLM cost tracking solutions use real-time monitoring to trigger automated notifications via email, Slack, or webhooks when usage hits predefined percentages of a budget. These systems can be configured with automated enforcement rules that throttle traffic or block requests once a hard cap is reached. This proactive alerting prevents "runaway" workloads and ensures financial guardrails remain in place.
TrueFoundry is an ideal LLM cost tracking solution because it combines real-time cost attribution with deep metadata-driven context. It allows enterprises to define custom pricing per model and set granular budget thresholds for specific teams, projects, or environments. Its AI Gateway further optimizes spend through smart routing, semantic caching, and automatic model fallbacks, ensuring high performance at the lowest possible price point.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)




.png)








.webp)
.webp)


