













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
LLMが多くのチームでパイロット運用から本番環境に移行すると、ガバナンスはもはやオプションではなくなります。誰がどのモデルを、どの予算で、誰のデータに対して呼び出せるのか、そしてすべての呼び出しが監査のために再構築できるのか、という疑問が必ず生じます。この記事は、それらの疑問に答えるためのコントロールプレーンです。プロバイダーの認証情報からアクセスを分離する仮想キー、RBACとポリシーアズコード、ガバナンスとしての予算とクォータ、コンプライアンス対応の監査ログ、データレジデンシー、そしてこれらのゲートウェイ制御がEU AI法のような義務にどのように対応するかについて説明します。これらは、義務の達成を支援するものであり、コンプライアンスを保証するものではないという観点から説明します。
ノースウィンド社の四半期末。 プラットフォームリーダーのメイは、セキュリティおよびコンプライアンスチームから、彼女には答えられない質問を受けました。過去四半期にどのチームがどのモデルプロバイダーに顧客データを送信したか、そしてその記録を提示できるか、という質問です。彼女にはできませんでした。すべてのサービスは、数年前に設定に組み込まれた1つの共有APIキーを通じてモデルプロバイダーを呼び出していました。チームごとの帰属情報も、どのリクエストが顧客データを運んだかの記録もなく、全員のキーをローテーションせずに特定のチームのアクセスを取り消す方法もなく、プロバイダー自身の不透明な請求書以外に監査証跡もありませんでした。LLMの利用は1つのプロトタイプから十数個の本番サービスへと拡大していましたが、ガバナンスはそれに伴って成長していませんでした。
厳密には何も問題は起きていませんでした。侵害も、誰も気づかなかった過剰支出もありませんでした。しかし、「その質問には答えられない」という事実自体が問題であり、それが通常の監査を大がかりなプロジェクトに変えてしまうのです。この記事は、誰かが質問する前にその質問に答えられるようにするコントロールプレーンです。
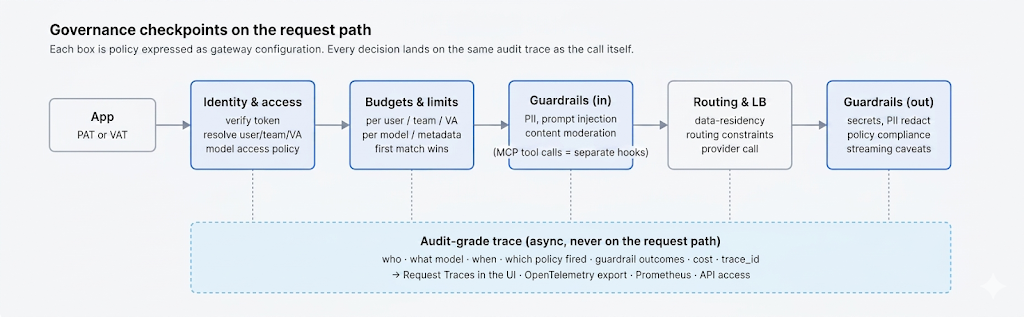
この記事で説明するすべて — 仮想キー、RBAC、予算、レート制限、監査ログ、レジデンシー規則、そして強制ポリシーとしてのガードレール — は、 TrueFoundryのAIゲートウェイが 1つのコントロールプレーンで設定として表現されます。 アクセス制御は 誰(ユーザー、チーム、仮想アカウント)がどのプロバイダーアカウントとモデルを呼び出せるかを定義し、 個人アクセストークンと仮想アカウントトークンは 生のプロバイダーキーを保持する代わりに、アプリケーションがゲートウェイに認証する方法であり、 レート制限と予算の設定は ユーザー、チーム、仮想アカウント、モデル、または任意のカスタムメタデータキーごとに適用され、 ガードレールは — MCPツール境界でのポリシーアズコードとしてCedarとOPAを含め — 4つのライフサイクルフックで強制ルールとして実行されます。
すべてのリクエストは同じパスをたどります。認証、呼び出し元の識別子の解決、アクセスポリシーとキーごとの予算の評価、レート制限ルールの順次評価(最初の一致が優先)、入力ガードレールの実行、プロバイダーへのルーティング、監査グレードのトレースの出力、そして出力ガードレールの実行です。この同じビューが、監査人が必要とする記録となります。誰が、何を、いつ、どのポリシーに対して、どのようなガードレール結果で呼び出したか、という記録です。 リクエストトレース と OpenTelemetry エクスポート クエリできないベンダーダッシュボードではなく、トレイルをSIEMに記録しましょう。
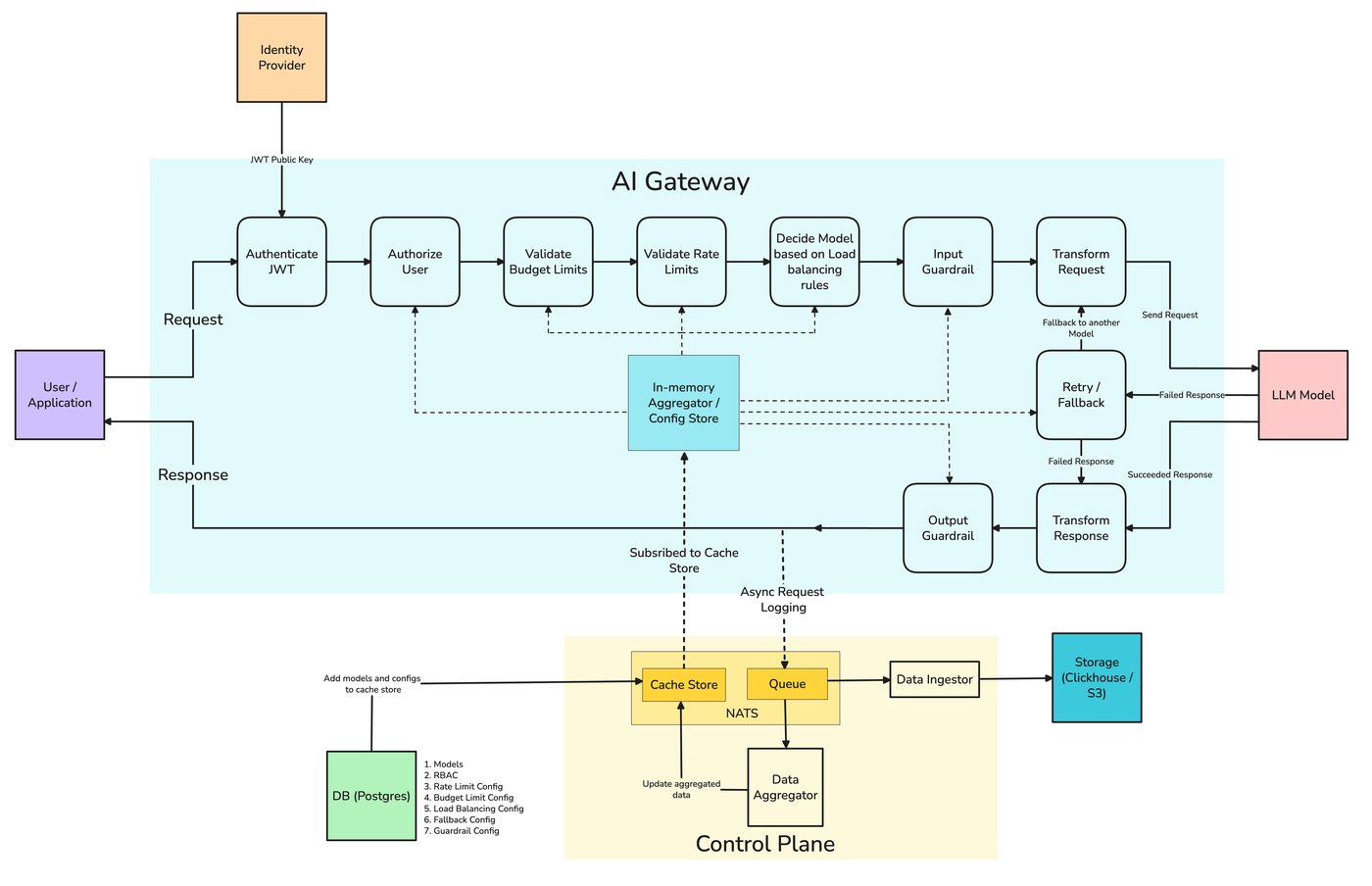
アプリケーションコードは、OpenAIスタイルの呼び出しと変わらず、ガバナンスはクライアントロジックではなく、ベアラートークンとメタデータヘッダーにあります。パーソナルアクセストークンはユーザーに解決され、仮想アカウントトークンは本番サービス用の非人間的なIDに解決されます。 X-TFY-METADATA ヘッダーには、ポリシー、予算、監査ログが照合する対象となる構造化されたフィールド(チーム、プロジェクト、コストセンター、環境)が含まれています。
認証情報と監査メタデータを使用してゲートウェイを呼び出す(Python、OpenAI互換)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-virtual-account-token>", # VAT for production; PAT in dev
)
resp = client.chat.completions.create(
model="openai-main/gpt-5.5",
messages=[{"role": "user", "content": "Summarize this document."}],
extra_headers={
# Structured identity for audit, attribution, and policy matching.
"X-TFY-METADATA": '{"team":"support-ai","project":"helpdesk","cost_center":"cc-203","environment":"production"}',
},
)
print(resp.choices[0].message.content)1つのキーで1つのモデルを呼び出す単一のプロトタイプには、ガバナンスは不要です。しかし、複数のチームにまたがる多数のサービスが、複数のプロバイダーを呼び出し、機密性の異なるデータを扱う場合、制御プレーンが必要です。なぜなら、障害モードはもはや仮説ではないからです。共有キーは使用状況の帰属を意味しないため、どのチームが支出を増やしているのかを財務部門に伝えたり、どのチームが顧客データに触れたのかをセキュリティ部門に伝えたりすることはできません。支出制限がないと、暴走したエージェント(ルーティングに関する以前の投稿のサイレントエスカレーションを思い出してください)が、誰も気づく前に予算を使い果たしてしまう可能性があります。監査証跡がないと、インシデントや監査のために何が起こったかを再構築できません。そして、アクセス制御がないとシャドウAIが発生します。つまり、誰も追跡することなくチームがモデルを接続してしまうのです。
運用上のプレッシャーに加えて、規制上のプレッシャーもあります。EU AI法は、記録保持、透明性、人間の監視(セクション7)に関する義務を段階的に導入しており、SOC 2、HIPAA、金融規制などの業界規制は、以前からアクセス制御と監査を求めてきました。共通しているのは、これらすべてがメイの質問に答えられることを前提としている点です。 AIガバナンス は、それを可能にするための取り組みです。

Meiの問題の根本原因は、共有されているプロバイダーキーにあります。仮想キーがこれを解決します。チームに実際のプロバイダー認証情報を渡す代わりに、各チームまたはアプリケーションに、ゲートウェイで基盤となるプロバイダーキーにマッピングされる、ゲートウェイ管理の独自のキーを発行します。アプリケーションは仮想キーで認証し、ゲートウェイが実際のキーを保持します。
この単一の間接化が、ガバナンスの大部分を可能にします。使用状況は仮想キーに紐付けられるため、支出とデータアクセスをチームごとに報告できます( コストアトリビューションに関する投稿 はまさにこれに基づいています)。失効はローカルです。他のすべてのユーザーのためにプロバイダーキーをローテーションすることなく、あるチームの仮想キーを無効にできます。アクセスはスコープ可能です。仮想キーは特定のモデル、ルート、またはデータクラスに制限できます。プロバイダー認証情報は、追跡やクリーンなローテーションができない多数のサービス設定に散らばるのではなく、ゲートウェイという一箇所に存在します。 TrueFoundryのAI Gatewayでは、仮想キーは、不透明な共有認証情報ではなく、使用状況、予算、アクセスポリシーをチームまたはアプリケーションに結びつける単位となります。
仮想キーはIDを確立し、RBACとポリシーはそのIDが何を実行できるかを決定します。質問は具体的です。どのチームが高価なフロンティアモデルを使用できるか、どのプロバイダーにアクセスできるか、どのツールを呼び出せるか(MCP設定の場合)、どのデータクラスをどこに送信できるか、などです。これらをCedarやOPAのようなエンジンを使ってポリシー・アズ・コードとしてエンコードすることで、ルールは部族の知識や散在する条件文として存在するのではなく、明示的でレビュー可能、かつバージョン管理されたものになります。
アクセスポリシーの例(概念的なものであり、正確なスキーマはゲートウェイ固有です)# 研究チームのみがフロンティアモデルを呼び出すことができます。allow if principal.team == "research" and resource.model == "gpt-5.5"# 顧客データのリクエストはEU居住モデルに留まる必要があります。deny if request.data_class == "customer_pii" and resource.region != "eu"# 財務チームは外部プロバイダーを一切呼び出すことはできません — セルフホスト型のみです。allow if principal.team == "finance" and resource.kind == "self_hosted"
ポリシー・アズ・コードの価値は、「誰が何を呼び出せるか」をプルリクエストでレビューし、テストし、監査人に証明できるものに変える点にあります。これは、TrueFoundryの MCPセキュリティ の取り組みであり、CedarとOPAがエージェントがどのツールを呼び出すことができるかを制御します。ゲートウェイは、すべてのリクエストがプロバイダーまたはツールに到達する前に通過する唯一の場所であるため、強制ポイントとなります。
予算とレート制限は通常、不正利用やコストの暴走に対する保護として捉えられます。ガバナンスの文脈では、これらは公平性と説明責任のコントロールでもあります。各チームには定められた割り当てがあり、超過は可視化され、単一のチームが組織全体のモデル予算を密かに使い果たすことはできません。その仕組みは、チームまたは仮想キーごとのハードリミットとソフトリミット、制限が近づいた際の警告、そして超過した場合の強制措置(通常は429エラー)であり、これは コストアトリビューションに関する投稿で説明されている強制パスと同じです。
ガバナンスの観点から見ると、これらの設定方法が変わります。アラート付きのソフトリミットは説明責任ツールであり、本番環境を停止させることなく、予算責任者にチームが予算を超過しつつあることを伝えます。ハードリミットは、ルーティングに関する投稿で述べられているような、静かにエスカレートするカスケードのような暴走ケースに対するガードレールです。キーごとのレート制限は、共有容量設定における公平性メカニズムとしても機能し、あるチームのバッチジョブが別のチームのインタラクティブトラフィックを枯渇させるのを防ぎます。これらを TrueFoundryのAIゲートウェイ サービスごとに再実装されるのではなく、仮想キーごとに一貫して適用されることを意味します。
スキーマは意図的にルールベースで設計されており、ポリシーは監査人に説明するのと同じように読み取ることができます。 誰が (主体:ユーザー、チーム、仮想アカウント、または任意のカスタムメタデータキー)、 何を (モデル)、 どれくらい (制限と単位 — 1分、1時間、または1日あたりのリクエスト数またはトークン数)、そして どのようにスコープされるか (1つの共有制限、またはユーザーごと/モデルごと/メタデータ値ごとの個別の制限( rate_limit_applies_per))。ルールは順番に評価され、最初に一致したものが適用されるため、より具体的なルールが広範なフォールバックよりも優先されます。
gateway-rate-limiting-config(TrueFoundryドキュメントからの実際のスキーマ)
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
# 1. Specific override: bob's runaway script gets a hard 1k requests/day on gpt4
- id: "bob-gpt4-day-cap"
when:
subjects: ["user:bob@example.com"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_day
# 2. Team-level token cap on a costly model
- id: "backend-team-gpt4-tpm"
when:
subjects: ["team:backend"]
models: ["openai-main/gpt4"]
limit_to: 20000
unit: tokens_per_minute
# 3. Fairness floor: every user gets their own 1M-token/day budget on any model
- id: "user-daily-token-cap"
when: {}
limit_to: 1000000
unit: tokens_per_day
rate_limit_applies_per: ["user"]
# 4. Project-level cap based on metadata in the request header
- id: "project-hourly-cap"
when: {}
limit_to: 50000
unit: tokens_per_hour
rate_limit_applies_per: ["metadata.project_id"]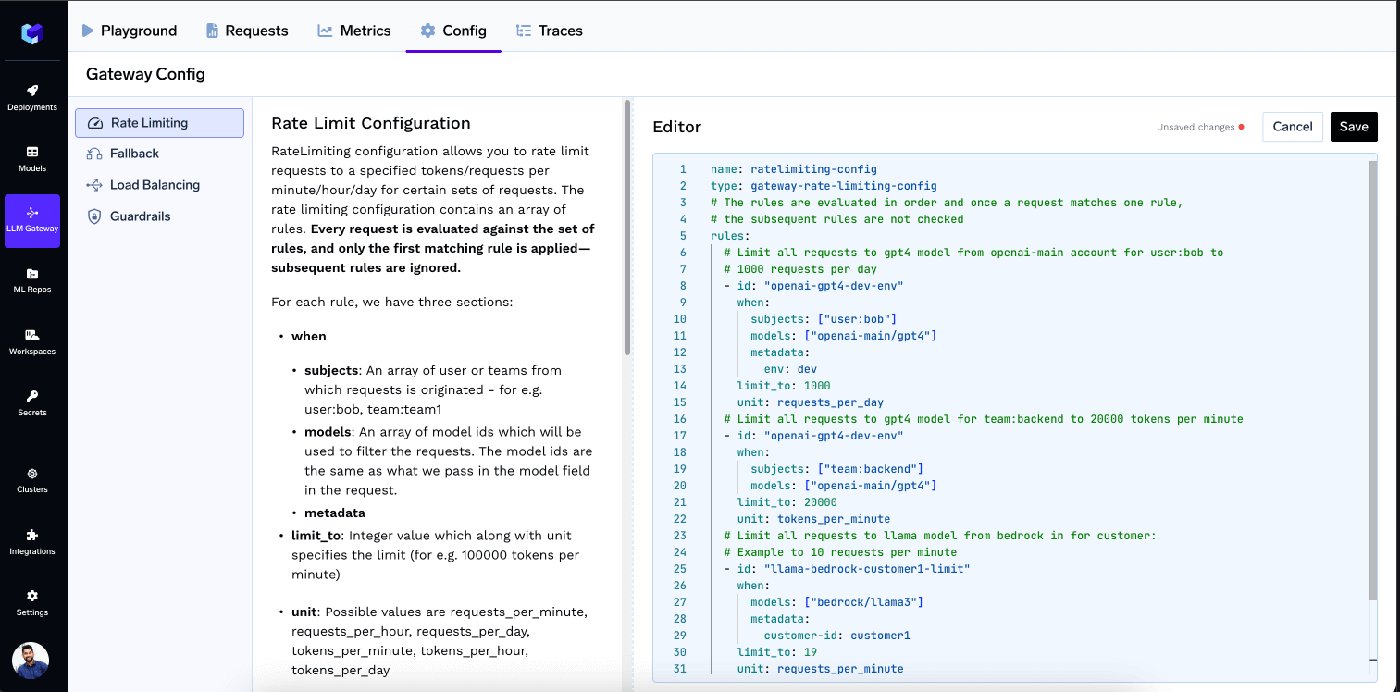
内部では、適用には スライディングウィンドウ・トークンバケット 60秒のウィンドウで合計される12個の5秒バケットを持つアルゴリズムです。短時間の急増ではチームが締め出されない程度にバーストを許容し、暴走スクリプトが数秒以内に検知される程度に厳格です。ゲートウェイがID(PATまたはVAT → ユーザー、チーム、仮想アカウント)を解決し、 X-TFY-METADATA をすべての呼び出しで読み取るため、単一のポリシーが通常対応すべき4つのガバナンス対象(キーごとにレート制限される開発者、集合的にレート制限されるチーム、グローバルにレート制限されるモデル、メタデータタグによってレート制限されるプロジェクト)を、同じルール式でカバーできます。
監査の側面がもう一方の重要な要素です。すべてのレート制限の決定、ガードレールの結果、フォールバックの遷移、およびすべてのモデル呼び出しは、同じリクエストトレースに記録されます(x-tfy-trace-id がレスポンス内の)、そして、この同じトレースは、 UIの「リクエストトレース」 を介して公開され、 OpenTelemetryを介してエクスポートされます。これにより、「ログがあります」という状態が「規制当局に提出できる監査証跡があります」という状態に変わります。
「ログがあります」と「コンプライアンス対応の監査証跡があります」は異なる主張です。監査に耐えうるログには4つの特性があります。それは 不変であること — 事後にエントリを編集または削除できないこと。それは 完全であること — すべての呼び出しが、誰が(どのチーム/仮想キー)、何を(モデル、ルート、アクション)、いつ、どのデータカテゴリが関与したかを記録すること。それは 改ざん検知可能であること — エントリが暗号化されたトレースIDやハッシュチェーンのようなものを含み、改ざんが検出可能であること。そしてそれは エクスポート可能であること — クエリできないベンダーダッシュボード内だけに留まるのではなく、SIEMにストリーミングされます。
これが、メイが疑問に答えることを可能にしたレイヤーです。不変で、チームごと、データカテゴリでタグ付けされたすべての呼び出しの記録がSIEMにエクスポートされ、後からクエリ可能です。これは、 OpenTelemetryに関する投稿 — 可観測性を支える同じスパンであり、監査が要求する完全性と不変性の特性を備えています。
規制対象データの場合、リクエストがどこで処理されるか自体がガバナンス上の決定であり、ルーティングとして強制されます。地域を意識したルーティングにより、EUの個人データを含むリクエストはEU居住のエンドポイントに留まります。プロバイダー制限により、特定のデータクラスが特定のプロバイダーに到達するのを完全にブロックします。そして、最も機密性の高いデータについては、自己ホスト型のオープンウェイトモデルが処理を自社のインフラストラクチャ内に保持するため、規制対象コンテンツが境界を離れることは一切ありません。
これらの決定は、セクション3のポリシーエンジンと連携します。「顧客のPIIはEU居住モデルでのみ処理される」というポリシーは、アクセスポリシーとして表現されたレジデンシー規則であり、ゲートウェイはそれに応じてルーティングを行うか、ルーティングを拒否することでこれを強制します。なぜなら TrueFoundryのAIゲートウェイ ホスト型モデルと自己ホスト型モデルを単一のインターフェースで提供するため、レジデンシーは個別の統合ではなくルーティングルールとなり、データクラスがどこで処理されるかの選択は、他のすべての決定と同様にログに記録されます。
EU AI法は段階的に導入されています。禁止されている行為とAIリテラシーの義務は2025年2月から、汎用AIモデルに関する義務は2025年8月から適用されており、高リスクシステムに関する義務(リスク管理、データガバナンス、記録保持/ロギング、透明性、人間の監視)は2026年8月頃に適用される予定です。ただし、用途ベース(附属書III)の高リスクシステムのタイミングは、執筆時点で三者協議中であり、一部を2027年12月まで延期する可能性のある欧州委員会のデジタルオムニバス簡素化提案の対象となります。日程は変更される可能性があります。これらは流動的な領域として扱い、最新の条文で確認してください。
ゲートウェイが役立つのは、これらの義務のいくつかが前提とする運用基盤です。記録保持と自動ロギングは、コンプライアンスグレードの監査ログ(セクション5)に対応します。人間の監視は、 プロンプトインジェクションに関する投稿 高リスクなアクションに対して議論されたヒューマン・イン・ザ・ループのチェックポイントに対応します。データガバナンスは、レジデンシールーティングとPIIガードレールに対応します。透明性の義務は、システムが何を行い、どのデータに対して行ったかを示すことができることでサポートされます。
ガバナンスはアクセスや予算だけでなく、どのようなコンテンツのフローが許可されるかにも関わります。このシリーズの残りの部分で説明されているガードレール(PII/PHI検出、プロンプトインジェクション防御、コンテンツモデレーション、シークレット検出)は、各アプリケーションの裁量に任せるのではなく、ポリシーとして強制される場合にガバナンス制御となります。「顧客のPIIはすべてのルートで編集される」および「出力はロギングシンクに到達する前にスクリーニングされる」はポリシー記述であり、これらを一律に強制する場所はゲートウェイです。
これにより、以前の投稿とのつながりができます。 PIIに関する投稿の4つの挿入ポイント、 プロンプトインジェクションに関する投稿の入出力ガードレール、そして本稿で述べるRBACと監査は、一つのコントロールプレーンの側面です。IDが「誰が」を、ポリシーが「何を呼び出すことができるか」を、ガードレールが「どのようなコンテンツが通過できるか」を、予算が「どれくらい」を、レジデンシーが「どこに」を決定し、監査ログがそのすべてを記録します。 TrueFoundryのガードレール は、LLMおよびMCPフックで、適用可能で設定可能なポリシーとして実行されます。これにより、善意の意図が、監査人が検証できるガバナンスへと変わるのです。
仮想キーと、チームごとに個別のプロバイダーキーを持つことの違いは何ですか?
個別のプロバイダーキーは、ある程度の帰属情報を提供しますが、実際の認証情報はサービス設定に散らばり、ローテーションが難しく、漏洩しやすく、ポリシーを保持しません。仮想キーはゲートウェイによって管理されます。これは実際のプロバイダーキーに一元的にマッピングされ、チームのRBAC、予算、レジデンシーポリシーを保持し、プロバイダーの認証情報や他のチームに影響を与えることなく、取り消したり再スコープしたりできます。この間接化こそが重要な点なのです。
監査ログとは、プロンプトをログに記録することですか?
いいえ、通常はそうすべきではありません。何が起こったかを再構築するために必要なメタデータ、つまりチーム、モデル、ルート、アクション、データカテゴリ、ガードレールイベント、タイムスタンプ、トレースIDをログに記録します。生のプロンプトコンテンツをログに記録すると、PIIガードレールが存在する目的である機密データの問題を再発させてしまいます。コンプライアンスグレードとは、メタデータが完全で不変であることであり、ユーザーデータの逐語的な転写ではありません。
ゲートウェイを導入すれば、EU AI法に準拠できますか?
いいえ。ゲートウェイは、記録保持、ロギング、人間の監視のサポート、データガバナンスといった特定の運用上の義務を満たすのに役立ちますが、コンプライアンスは、リスク分類、プロバイダーまたはデプロイヤーとしての役割、文書化、そしてどのゲートウェイも実行しない適合性評価に依存します。ゲートウェイは必要なインフラとして捉え、ご自身のユースケースに必要なものについては、実際の規制と弁護士に相談してください。デジタルオムニバス提案の下で、タイムラインもまだ変動しています。
これはまた、コスト帰属に関する投稿ではないですか?
仮想キーとチームごとの帰属という基盤は共通していますが、視点が異なります。コストに関する投稿は、支出(誰がそれを推進しているか、予算、チャージバック)についてです。本稿は、制御と説明責任(誰が何を呼び出すことができるか、どのようなコンテンツが流れるか、監査のために何が記録されるか、規制対象データがどこで処理されるか)についてです。同じコントロールプレーンですが、その上に課せられる義務が異なります。
ガバナンスはどこに存在すべきですか — アプリケーションですか、それともゲートウェイですか?
ゲートウェイです。なぜなら、ガバナンスは定義上、横断的なものだからです。すべてのサービスにわたるアクセス、予算、レジデンシー、監査ルールの一貫したセットが、すべてのリクエストが通過する唯一のポイントで適用されます。アプリケーションごとのガバナンスは漂流し、ギャップを生み出します。これが共有キーが何年も存続する理由です。アプリケーションは、人間による承認が必要なほど高リスクなアクションはどれか、といったドメイン固有の判断を依然として所有します。
メイの監査結果は違反ではなく、回答不能でした。ガバナンスとは、質問(誰が、何を、どれくらい、どこで、誰のデータに対して)に事前に答えられるようにする、地味な作業です。そしてゲートウェイは、それらの回答が1つのリクエストごとに適用され、記録される場所なのです。
TrueFoundryのAIゲートウェイ は、アプリケーションと1,600以上のモデル(OpenAI、Anthropic、Google、AWS Bedrock、Azure OpenAI、および自社ホスト型モデルを含む)の間に位置し、単一のOpenAI互換APIの背後で機能するエンタープライズグレードのコントロールプレーンです。本稿で述べたガバナンス制御を、サービスごとのコードではなく設定へと変換します。具体的には、非人間的な本番環境IDのための仮想アカウント、開発用のパーソナルアクセストークン、プロバイダーアカウントごとにスコープ設定されたRBAC、ユーザーごと/チームごと/モデルごと/メタデータごとのスコープを持つYAMLで表現されたレート制限および予算ルール、そしてMCPツール境界でのポリシーアズコードガードレール(CedarおよびOPA)を提供します。
ゲートウェイはすでにすべてのリクエスト上に存在し、すべての呼び出しに対して完全なトレースを出力するため、コンプライアンスグレードの監査が実用的になる場所でもあります。ID、ポリシー決定、ガードレールの結果、モデル選択、トークン数、コストはすべて同じトレースIDに紐付けられ、UIの「リクエストトレース」で確認でき、OpenTelemetryを通じてエクスポート可能で、SIEM統合のためにAPI経由でアクセスできます。同じゲートウェイは、厳密なキャッシュとセマンティックキャッシュ、フォールバックとリトライ、および可観測性ダッシュボードを追加し、SaaSとして、またはVPC内、オンプレミス、エアギャップ環境でデプロイ可能で、SOC 2、HIPAA、ITARに準拠しており、GartnerのAIゲートウェイ市場ガイドで評価されています。 アクセス制御、 レート制限、および ガードレール ドキュメント、または AI Gateway の概要 をさらに詳しく知るには。
NorthwindとMeiは例示です。仮想キー、RBAC、ポリシーアズコード、監査ログ、レジデンシールーティングといったガバナンスパターンは、LLMトラフィックに適用される標準的なコントロールプレーンのプラクティスです。EU AI法の日付と義務は、2026年5月時点の欧州委員会が公表したタイムラインと報告書から要約されており、継続的な修正(特に三者協議中のデジタルオムニバス提案)の対象となります。本稿はエンジニアリングに関するガイダンスであり、法的助言ではありません。ここで説明するゲートウェイ制御は、コンプライアンスを構成するものではなく、特定の義務を満たすのに役立つものです。ご自身のユースケースについては、規制に対する現在の要件と、資格のある弁護士にご確認ください。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


