














July 15, 2026
|
5 min read

Published: June 1, 2026

Blazingly fast way to build, track and deploy your models!
PII can enter an LLM pipeline at four points — user input, retrieved context, tool results, and the model's own output — and many teams start by guarding only the first one. This post works through where PII enters, the detection methods that catch each kind (regex, entropy analysis, NER, external APIs) and their accuracy and latency tradeoffs, the difference between rewriting PII and blocking on it, the way redaction can quietly destroy the meaning the model needs, and the framework for deciding whether redaction belongs at the gateway or in the application.
Thursday at Northwind. The support team's escalation agent answered a customer's question about their shipping account by summarizing the customer's file — and in the second sentence, returned the customer's full Social Security number. The number was real. It had not come from anything the customer typed. It came from a support ticket the RAG system had retrieved, where an agent three years earlier had pasted the SSN into a free-text note.
Reza, a security engineer on the platform team, traces it in an afternoon. The input-redaction guardrail the team had shipped six months earlier scanned every user message for PII and worked exactly as designed. It had simply never looked at the retrieved context. The SSN entered the pipeline at a point the guardrail didn't watch, rode into the prompt as part of a retrieved document, and the model — doing its job — quoted it back.
This post is the threat model that incident teaches, and the engineering tradeoffs in covering all of it: where PII enters, how you detect each kind, what detection costs in latency, and where the redaction logic should live.
An LLM request is not a single channel. PII can enter the context at four distinct points, and each needs its own detection step:
1. User input. What the user types. This is the point everyone guards first, and the only point many pipelines guard at all. Real, but rarely the most dangerous, because the user generally knows what they typed.
2. RAG-retrieved context. Documents pulled into the prompt by a retrieval step. The indexer almost never scrubbed them — they're internal tickets, wiki pages, CRM notes — and any PII inside rides straight into the prompt. This is the cold-open case, and it is often the most overlooked: nobody at request time chose to include it, so an input guardrail watching the user's message never sees it.
3. Tool results. Data returned by a tool the agent called — a customer-lookup API, a database query, an MCP server (the post-tool hook from the MCP gateway discussed earlier in this series). A tool that queries a customer record returns PII directly into the context, by design.
4. Model output. The model's own response. Even with clean inputs, a model can emit PII — recombined from context, or in rare cases memorized from training. For compliance, any PII in an output that gets logged or shown to an unauthorized viewer is a policy violation regardless of where it came from.
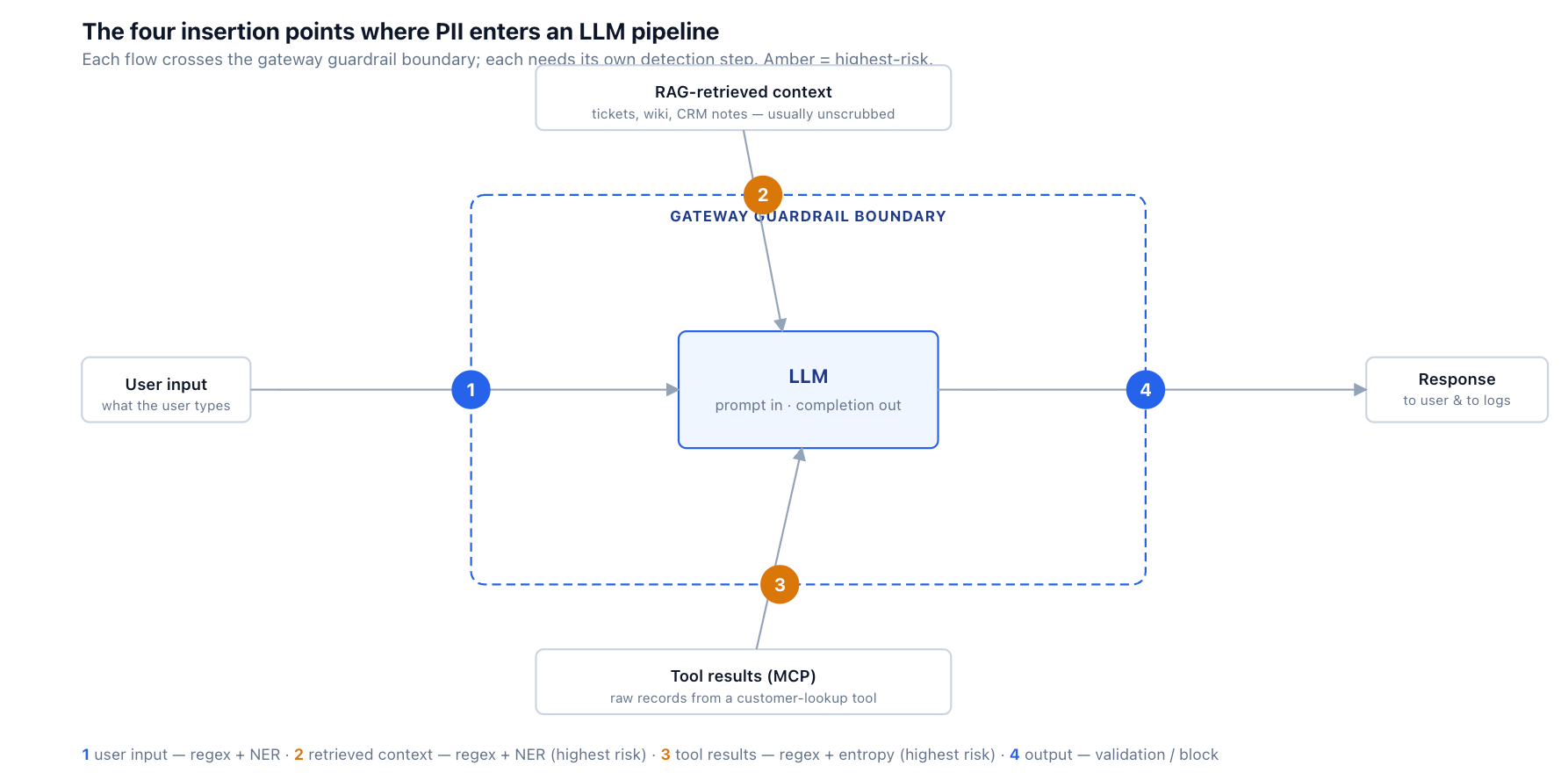
One clarification worth making early, because the numbers line up confusingly: these four insertion points are a threat model — they describe where sensitive data enters the pipeline. They are not the same as the four guardrail hooks a gateway exposes to run a check (in TrueFoundry's case: LLM input, LLM output, MCP pre-tool, and MCP post-tool). The two framings overlap but don't map one-to-one. User input and retrieved context both arrive in the prompt, so both are caught at the LLM-input hook; tool results are caught at the MCP post-tool hook; model output at the LLM-output hook. The MCP pre-tool hook guards what the agent sends to a tool — a different concern (SQL injection, argument validation) that isn't a PII insertion point at all. Insertion points are about where to look; hooks are about where you can stand to look.
Detection difficulty tracks the structure of the data. Three classes:
Structured PII has a deterministic format a regular expression can match. Social Security numbers (three digits, two digits, four digits), credit card numbers, US phone numbers, email addresses. Credit cards are worth a caveat: "sixteen digits" is a simplification, not the detector — card numbers vary by network (American Express is fifteen digits, others differ in length and prefix), so production detection combines network-specific prefix and length rules with a checksum such as Luhn. The checksum matters: it turns "a numeric string" into "a plausibly valid card number," cutting false positives on order IDs and tracking numbers.
Semi-structured PII has a recognizable shape but is not a fixed pattern. API keys, OAuth tokens, AWS access keys (the AKIA prefix followed by sixteen characters), PEM-encoded private key blocks. Two signals catch these: a prefix or delimiter pattern (AKIA…, -----BEGIN PRIVATE KEY-----) and high entropy — a run of characters that looks random rather than linguistic.
Unstructured PII has no pattern at all: person names, physical addresses, dates of birth in prose. There is no regular expression for "is this token a person's name," because a name is just words, and the same word is a name in one sentence and not in another. "April" is a name and a month. "Penny" is a name and a coin. Only context disambiguates, which is why this class requires a model — named-entity recognition (NER) or an LLM — not a pattern.
One taxonomy note that matters for compliance language: PII, strictly, is information that identifies a natural person. Organization names, vendor names, and internal project names are often sensitive business identifiers worth redacting for confidentiality, but they are not inherently PII — an org name becomes personal data only in specific contexts (a sole proprietorship, a one-person practice, employer information tied to a named individual). They live in the same unstructured-detection bucket as person names from a tooling standpoint, but conflating the two invites a legitimate privacy-law objection. This post keeps the engineering point (both need NER-class detection) while keeping the categories distinct.
Examples by category — why regex covers the first two and not the third
# Structured — deterministic, regex with validationSSN \d{3}-\d{2}-\d{4}
credit card 16 digits, Luhn-valid
email local@domain.tld
# Semi-structured — prefix/format + entropyAWS key AKIA[0-9A-Z]{16}
PEM block -----BEGIN (RSA )?PRIVATE KEY-----
api token high Shannon entropy over a 32+ char window
# Unstructured — no pattern; requires NER / LLM with contextperson "the patient's name is Jane Park" -> Jane Park
address "ship to 42 Wallaby Way, Sydney" -> 42 Wallaby Way, Sydney
org* "she works at Meridian Logistics" -> Meridian Logistics
# *sensitive business identifier, not strictly PII — same detector, different categoryA production detector is a chain of tiers, ordered cheapest-first. Each tier handles what the cheaper tiers can't.
The chaining logic: run Tier 1 and 2 always — they are cheap and catch the highest-stakes structured PII and secrets with high reliability on well-formatted inputs (with the format-variant caveats from the next section). Run Tier 3 (NER) when names and addresses matter, which for most customer-facing workloads is always. Reserve Tier 4 for workloads where the compliance bar genuinely justifies the latency and per-call cost — regulated healthcare and finance documents, where missing a domain-specific identifier is a reportable breach. Running Tier 4 on every request is a common and expensive mistake; most requests are fully handled by the first three tiers.
One implementation detail about Tier 4: some external APIs (AWS Comprehend's real-time path, for instance) return entity offsets and confidence scores rather than a ready-redacted string, and their built-in redaction may be an asynchronous batch operation. For inline gateway use you typically call detection, receive the spans, and perform the replacement yourself — so the gateway still owns offset handling, replacement, and policy behavior even when a third party does the detection.
Microsoft's open-source Presidio is a widely used example of this layered approach — predefined and custom recognizers, regex, rule-based logic, checksums, an NER model, and hooks for external PII detection models — and most gateway guardrail implementations, including TrueFoundry's, build on the same layered idea.
Two fundamentally different things to do when PII is detected:
Mutation mode rewrites the data and lets the request continue. "John Smith at Goldman Sachs" becomes "[PERSON] at [ORG]," and the redacted prompt proceeds to the model. This is the right mode for input hygiene — clean the prompt so the model never sees the PII in the first place.
Validation mode detects PII and blocks the request entirely, returning an error. Nothing is rewritten; the request fails. This is the right mode for output compliance, where the policy is that any PII in a response is a violation — for instance, a response destined for a logging pipeline that must remain PII-free.
Example policy response — validation-mode block (exact status code and shape are gateway-specific)
HTTP/1.1 422 Unprocessable Entity
Content-Type: application/json
{
"error": {
"type": "guardrail_violation",
"guardrail": "pii_output_validation",
"message": "Response blocked: contains PII categories [US_SSN, PERSON].",
"detected": [
{ "category": "US_SSN", "tier": "regex" },
{ "category": "PERSON", "tier": "ner", "confidence": 0.91 }
]
}
}The two compose naturally in one pipeline: mutation on the way in (scrub the prompt), validation on the way out (block any response that still contains PII). They are not alternatives; they answer different questions.
The useful production framing is not that one detector is "best" — it is that each detector has a region where it is reliable and a characteristic way it fails. Reported precision and recall numbers in the PII literature swing sharply with dataset, language, domain, annotation policy, and the span-vs-token matching criterion, so a single number is rarely a property of the method. What is stable across studies is the shape of the strengths and failure modes:
Two patterns hold across essentially every published comparison. First, regex on structured identifiers with stable syntax is the strongest and cheapest first line — for SSNs, emails, phone numbers, and known credential formats — and weakest when the identifier is reformatted, obfuscated, partial, or context-dependent. Second, NER and PII APIs are stronger for names, addresses, and prose-like identifiers but introduce false positives and domain drift: a name detector trained on general English misses names in other languages, over-flags product and organization mentions as people, and behaves differently in support tickets, medical notes, and log files. The SPY-dataset study found dedicated NER models over-tagging in PII contexts — high recall, lower precision — which is the false-positive end of exactly this pattern.
The safe production stance follows from that: benchmark on a representative sample of your own traffic before setting blocking thresholds, tune thresholds per entity type, and use different actions for different confidence levels — redact obvious structured identifiers, block high-confidence output leaks, and audit ambiguous detections before enforcing.
Redaction is lossy by definition, and the loss sometimes destroys the information the task depended on. Consider:
How naive redaction collapses meaning
original: "Wire $50,000 from John Smith's Goldman Sachs account to Jane Doe."
redacted: "Wire $50,000 from [PERSON]'s [ORG] account to [PERSON]."The redacted prompt is now ambiguous in a way the original was not. The model cannot tell which [PERSON] is the source and which is the destination — the two distinct people have collapsed into the same token. A model asked to act on this will guess, and a wire transfer is a bad place to guess.
Three mitigations, in increasing order of capability and cost:
Unique placeholders. Replace with [PERSON_1], [PERSON_2], [ORG_1] rather than a generic tag. This preserves distinctness — the model knows the two people are different even if it doesn't know who they are. Cheap and usually sufficient.
A session redaction map. Maintain a mapping from placeholder to original value, scoped to the session, so the output can be de-redacted before it returns to an authorized user — "[PERSON_1]" in the model's answer becomes "John Smith" again on the way out.
The hard limit on de-redaction. You can only de-redact to a destination as trusted as the original source. If the output is logged, de-redacting puts the PII back into the logs — defeating the redaction. If the output goes to a user not authorized to see the PII, de-redaction is a disclosure. De-redaction works only when the endpoint's trust level matches the input's; otherwise the placeholder has to stay.
And the redaction map itself is sensitive infrastructure. A session map storing [PERSON_1] → John Smith is, by definition, a PII store — it needs the same controls as the data it protects: encryption at rest, a short TTL, strict session scoping, audit logging on every de-redaction, and authorization checks before any reverse lookup. A redaction layer that persists its maps carelessly has just created a second PII database, often a less-governed one than the system it was protecting.
On a representative payload — a 500-token prompt with a few PII entities — the tiers fall roughly an order of magnitude apart (these are illustrative figures on typical hardware; real numbers depend on model size, batching, and network):
The key architectural fact: a mutation guardrail runs synchronously before the model request, because the prompt has to be rewritten before it is sent. That latency adds directly to time-to-first-token. A 180 ms external-API check on the input adds 180 ms to every request's TTFT — on top of the model's own first-token latency.
This is why tier ordering is a performance decision, not just an accuracy one. Keep regex and entropy inline everywhere; they are free relative to model latency. Put NER inline only where names matter. For the external API, either reserve it for the workloads whose compliance bar justifies a fifth of a second of added TTFT, or apply it on the output path where the latency is not blocking the user's first token.
The parallelism that helps here is specific, and it runs on the input side, not the output side. Input validation (detect-and-maybe-block, no rewrite) can run concurrently with the model request — the gateway fires both, and cancels the model call if validation fails, so in the happy path the check adds no first-token latency. Input mutation cannot be parallelized away, because the model must receive the already-cleaned prompt, so its cost is added directly. Output guardrails are the harder case: they need the complete response to evaluate, which is why TrueFoundry's gateway, for example, skips output guardrails entirely on streaming responses (stream: true) and requires stream: false if you need them to run. The general lesson is that "cancel the response after detecting PII" is not a safe design for streaming — once a chunk has streamed to the client or to a log, cancellation is too late. Streaming output redaction is its own design problem: either buffer the response and scan before release (giving up the streaming latency benefit), or scan chunks with a deliberate delay, or accept that enforcement happens after partial disclosure.
Neither layer is universally correct. The decision turns on who has the context and who needs the result.
In practice most mature setups use both, split by PII class rather than choosing one layer. The gateway handles the structured PII and secrets — universal, cheap, high-stakes, the same everywhere — at all four insertion points. The application handles the context-dependent semantic cases where only it knows what counts as sensitive. The split is not gateway-versus-application; it is structured-and-universal at the gateway, context-dependent in the application.
The cold open is squarely a gateway case: a retrieved SSN is structured PII, dangerous in every context, entering at a point no individual application owns. That is exactly the class the gateway should catch at all four points.
But it is worth being clear that request-time redaction is the last line of defense for RAG, not the first. The cleaner architectural answer to the cold open is upstream: the ingestion pipeline should classify documents and chunks for PII at index time, record sensitivity metadata, and restrict retrieval by the requesting user's authorization — so a customer's SSN-bearing ticket is either scrubbed before indexing or never retrievable into a context that shouldn't see it. Gateway redaction catches the sensitive text that still reaches the prompt despite all that; it should not be the only control standing between a dirty index and the model. A pipeline that relies solely on the gateway to clean a poorly-governed index is one detector failure away from the incident it was meant to prevent.
Doesn't redaction hurt model output quality?
Somewhat, yes — the semantic-distortion problem in section 6 is the mechanism. Generic placeholders that collapse distinct entities degrade the model's ability to reason about the prompt. Unique placeholders ([PERSON_1], [PERSON_2]) mitigate most of it. For high-PII workloads, some quality cost is the price of compliance; the engineering goal is to minimize it, not pretend it's zero.
Can't we just use an LLM to detect PII?
You can, and an LLM detector has the best accuracy on context-dependent PII (it understands "the patient's name is" in a way regex and even NER don't). The costs: a full model call of added latency and spend, and — importantly — the detector model now sees the PII, which may itself be a compliance question depending on where that model runs. It's effectively a more expensive, more accurate Tier 4, appropriate where the document complexity justifies it.
What about false positives blocking legitimate requests?
This is validation mode's main risk, and NER's over-flagging (section 5) makes it real — an organization or product name misread as a person can block a valid request. Tune the confidence threshold per category, log and review blocks, and provide an override path for authorized users. A blocker that's too aggressive trains users to route around it, which is worse than a calibrated one.
How does redaction interact with the tracing and cost work from earlier posts?
Each redaction event emits a span attribute recording which categories were detected, by which tier, and whether the action was mutation or block — without recording the PII itself. That gives a centralized audit trail (what was redacted, when, on which route) that attributes to the team and app metadata from the cost-attribution post. See our OpenTelemetry for LLMs and Cost Attribution posts.
Does this work for non-English PII?
Partially, and it's a real gap. NER models are language-specific; a model trained on English under-detects names and addresses in other languages and scripts. Multi-language compliance requires either per-language NER models or the external APIs that support multiple languages — and the accuracy is generally lower for lower-resource languages. Worth testing explicitly rather than assuming the English numbers transfer.
Where does TrueFoundry fit?
TrueFoundry's AI Gateway runs guardrails at the four hooks — LLM input, LLM output, MCP pre-tool, MCP post-tool — in either validate (block) or mutate (rewrite) mode. For PII specifically it offers several options rather than one: a built-in PII/PHI detection guardrail powered by Azure AI Language (SaaS), a built-in Regex Pattern Matching guardrail that runs in-gateway with no external call (presets for cards, SSNs, and credentials plus custom patterns), a built-in Secrets Detection guardrail for keys and tokens, and integrations with external providers (Azure PII bring-your-own-key, CrowdStrike, and others) or custom guardrails built with Guardrails.AI or a Python function. The right configuration depends on whether a route needs mutation or blocking, local execution or provider-backed detection, and SaaS or self-hosted deployment. The gateway-versus-application decision in section 8 stays with the operator; the gateway supplies the centralized, structured-PII-and-secrets tier, and the application keeps the context-dependent cases that only it has the information to judge.
The cheapest, highest-leverage first move is the one the cold open needed: regex on structured PII at all four insertion points, not just user input. It is fast and cheap, highly effective on well-formatted identifiers like the straightforward retrieved SSN in the cold open, and the right first layer before more expensive context-aware detectors — though even regex needs representative test coverage for format variants and false positives. The expensive tiers come second, on the workloads whose compliance bar justifies the latency.
Northwind, Reza, and the support-agent incident are illustrative; the four-insertion-point threat model, the detection-tier characteristics, and the accuracy and latency patterns reflect the published behavior of regex, NER (Presidio-class), and external PII APIs as of May 2026. Detector strengths and failure modes are drawn from the qualitative patterns reported across the cited studies, not a single benchmark run; exact precision and recall vary sharply with dataset, domain, language, annotation policy, and matching criterion, which is why the post recommends benchmarking on representative traffic before setting thresholds. Latency figures are order-of-magnitude on typical hardware and depend on model size, batching, region, and network path.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.webp)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)








