
.webp)
June 25, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 24, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Partie 1 a posé le diagnostic : le tokenmaxxing n'est pas un problème d'utilisation de l'IA ; c'est un problème de plan de contrôle. Si les jetons bruts deviennent un objectif, les gens optimiseront pour les jetons bruts. Si l'exploitation de l'IA encadrée devient le modèle opérationnel, la plateforme peut encourager l'adoption tout en limitant les coûts, les risques et le bruit opérationnel. Cette partie concrétise cette architecture.
La thèse est simple. Chaque requête IA quittant une application d'entreprise est, que vous la traitiez ainsi ou non, un événement d'exécution avec des conséquences en termes de coût, de sécurité et d'audit. L'endroit le plus efficace pour associer des contrôles à ces événements est la passerelle — la couche qui se situe entre chaque application et chaque modèle et backend d'outil. Un tableau de bord construit en aval peut décrire ce qui s'est passé. Seule la passerelle peut décider de ce qui se passe ensuite.
Un tableau de bord signale un problème. Une passerelle empêche le suivant. L'architecture ci-dessous rend cette distinction opérationnelle.
Une requête IA encadrée nécessite quatre enveloppes autour d'elle avant de quitter l'application. Considérez cela comme le modèle OSI pour l'IA d'entreprise — chaque couche a une responsabilité spécifique et un mode de défaillance spécifique lorsqu'elle est absente.
Ces enveloppes doivent se trouver sur le chemin de la requête, et non dans un rapport que quelqu'un lit le vendredi. Un tableau de bord construit après coup peut décrire un problème ; seule une enveloppe sur la requête en direct peut façonner le prochain appel. C'est le principe architectural qui sépare une plateforme d'IA encadrée d'un module complémentaire d'analyse.
La première norme d'implémentation est un contrat de métadonnées strict. Utilisez des clés de type chaîne de caractères, envoyez-les à chaque requête et rendez-les obligatoires dans vos wrappers SDK, bibliothèques clientes internes, frameworks de bots et modèles d'agents. Le coût d'un champ manquant apparaît plus tard sous la forme d'une ligne de facture manquante, d'un pic inattribuables ou d'un événement de garde-fou que personne ne peut attribuer à un propriétaire.
// JSON — minimum metadata contract
// Treat as a strict schema, not a suggestion.
{
"team": "payments-platform", // maps to FinOps cost center
"project_id": "proj-agentic-refactor", // rate/budget scoping key
"workflow": "repo-understanding", // routing and policy selector
"surface": "ide-agent", // hourly rate-limit selector
"environment": "production", // budget tier selector
"cost_center": "eng-core", // accounting integration
"ticket_id": "ENG-18472", // outcome join key — THE most important field
"policy_version": "ai-leverage-v1" // audit trail
}
// Python SDK — never skip the metadata header:
// extra_headers={"X-TFY-METADATA": json.dumps(metadata)}Le balisage est le travail d'ingénierie le moins coûteux dans toute cette architecture et la première chose qui pose problème lorsque les équipes l'ignorent.
Dans la passerelle TrueFoundry, cela transite via l'en-tête X-TFY-METADATA. Le même espace de noms de clés alimente ensuite tout en aval : les budgets s'appliquent par projet, les limites de débit par flux de travail, les tableaux de bord sont regroupés par équipe, les traces sont jointes aux tickets, et la finance alloue les dépenses par centre de coûts. Il n'y a pas de deuxième source de vérité.

L'objectif architectural n'est pas de complexifier. Il est de maintenir une correspondance étroite entre chaque mode de défaillance réaliste et le contrôle spécifique qui l'empêche. Voici la taxonomie complète :
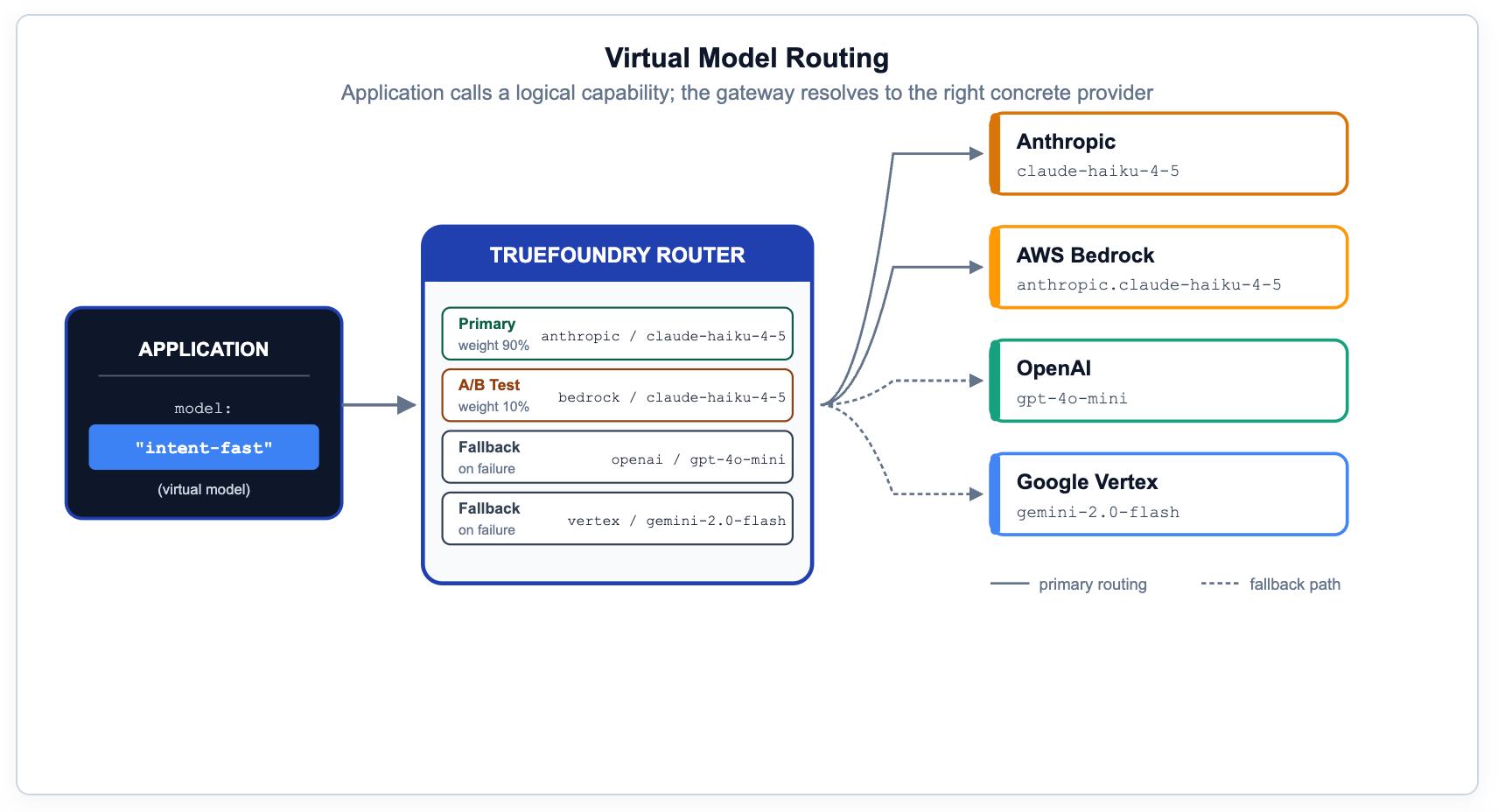
Si le code de l'application nomme un modèle de fournisseur spécifique, vous avez perdu la capacité de migrer, tester, faire de l'A/B testing ou basculer sans modifications de code. Le bon modèle est d'exposer des capacités logiques — des noms comme prod/engineering-assistant ou prod/frontier-reasoning — et de laisser la passerelle les résoudre en cibles physiques basées sur les métadonnées, la priorité, le poids ou la latence mesurée.
Chez TrueFoundry, c'est à cela que servent les modèles virtuels et la configuration de routage. Les mêmes règles couvrent les déploiements canaris, la préférence régionale, le déploiement sur site avec bascule vers le cloud et les surdéfinitions d'invites spécifiques au fournisseur. C'est la capacité la plus sous-estimée de la pile de gouvernance — elle rend la conformité, l'optimisation des coûts et la migration des modèles invisibles pour les développeurs d'applications.
# YAML — gateway-load-balancing-config
# Evaluated top-to-bottom; first match wins.
name: engineering-agent-routing
type: gateway-load-balancing-config
rules:
# Simple repo questions: cheap-first with frontier fallback.
- id: 'simple-repo-questions'
type: priority-based-routing
when:
models: ['prod/engineering-assistant']
metadata:
workflow: 'repo-understanding'
load_balance_targets:
- target: openai-main/gpt-4o-mini
priority: 0
retry_config: {attempts: 2, delay: 100, on_status_codes: ['429','500']}
fallback_status_codes: ['429', '500', '502', '503']
- target: anthropic-main/claude-sonnet
priority: 1
# Security-critical: strongest reasoner first.
- id: 'security-critical-review'
type: priority-based-routing
when:
metadata:
workflow: 'security-review'
load_balance_targets:
- target: anthropic-main/claude-opus
priority: 0
- target: openai-main/gpt-4.1
priority: 1
# Cost-sensitive batch: on-prem first, cloud as overflow.
- id: 'batch-processing-jobs'
type: priority-based-routing
when:
metadata:
surface: 'batch-pipeline'
load_balance_targets:
- target: on-prem/llama-3.1-70b
priority: 0
- target: openai-main/gpt-4o-mini
priority: 1
Documentation sur le routage : truefoundry.com/docs/ai-gateway/load-balancing-overview
Une fois que les applications d'IA sont en production, elles traitent des données utilisateur réelles et, dans les configurations d'agents, prennent des actions réelles via des outils. Le périmètre de sécurité n'est pas une seule chose. Ce sont quatre points d'ancrage, situés aux quatre moments où la passerelle peut intervenir avant qu'une requête ne cause des dommages.
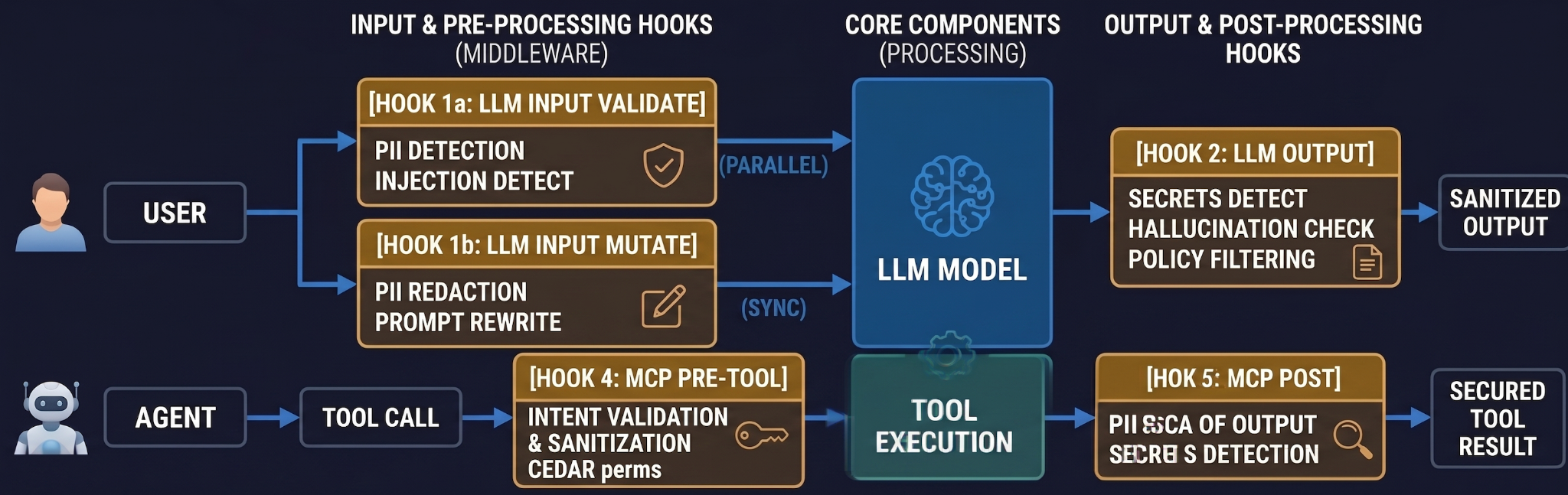
# Per-request guardrails — passed via X-TFY-GUARDRAILS header.
# For org-wide enforcement: AI Gateway → Controls → Guardrails.
X-TFY-GUARDRAILS: {
"llm_input_guardrails": [
"global/pii-redaction",
"global/prompt-injection-detection"
],
"llm_output_guardrails": [
"global/secrets-detection",
"global/hallucination-check"
],
"mcp_tool_pre_invoke_guardrails": [
"global/sql-sanitizer",
"global/cedar-permissions"
],
"mcp_tool_post_invoke_guardrails": [
"global/secrets-detection",
"global/pii-redaction"
]
}
# Rollout strategy — never go straight to blocking in production:
# Phase 1: mode=audit (log violations, let requests through)
# Phase 2: mode=enforce (block on fail, fail-open on provider errors)
# Phase 3: mode=strict (block on fail AND on provider errors)
Déployez les garde-fous en trois étapes : Audit → Appliquer-mais-ignorer-en-cas-d'erreur → Strict. Le réglage intermédiaire est celui qui vous sauvera le jour où un fournisseur de sécurité tiers subira une panne.
Aperçu des garde-fous : truefoundry.com/docs/ai-gateway/guardrails-overview
Détection des IPI/IPS : truefoundry.com/docs/ai-gateway/tfy-pii
Détection des secrets : truefoundry.com/docs/ai-gateway/secrets-detection
Deux questions dominent les opérations une fois que l'utilisation de l'IA gouvernée est en production : « pourquoi cette requête s'est-elle comportée de cette manière ? » et « le coût que nous payons est-il justifié par le travail que nous obtenons ? » On ne peut répondre à aucune des deux questions à partir d'un graphique de nombre de jetons.
L'ensemble minimal d'informations nécessaire pour y répondre — et l'ensemble que la passerelle de TrueFoundry fournit prête à l'emploi :
Documentation sur l'analyse : truefoundry.com/docs/ai-gateway/analytics
Export OpenTelemetry : truefoundry.com/docs/ai-gateway/export-opentelemetry-data
Les quatre enveloppes ci-dessus ont été conçues en supposant des requêtes de type chat : une application envoie une invite, le modèle renvoie du texte. Les charges de travail d'IA modernes ont dépassé cette hypothèse. Les agents appellent des outils. Les outils appellent d'autres outils. Une seule requête utilisateur peut générer une trajectoire d'agent en 50 étapes qui touche une demi-douzaine de serveurs MCP. La surface de coût, la surface de sécurité et la surface d'audit sont toutes passées de l'invite à l'appel d'outil.
C'est pourquoi la passerelle TrueFoundry prend en charge nativement l'API LLM et le protocole de contexte de modèle (MCP). La même enveloppe d'identité, les mêmes disjoncteurs, les mêmes mécanismes d'observabilité s'appliquent à un appel d'outil comme à une complétion de chat. L'identité OAuth 2.0 est injectée dans les appels d'outils MCP afin qu'un agent agisse en tant qu'utilisateur spécifique, et non en tant que compte de service, lorsqu'il interroge une base de données ou dépose un ticket Jira. Les serveurs MCP virtuels vous permettent de composer un « serveur d'agent financier » logique à partir d'outils répartis sur trois serveurs MCP réels, avec un contrôle d'accès et des limites de débit appliqués à la composition.
Le protocole de contexte de modèle est important pour le coût, pas seulement pour l'architecture. TrueFoundry rapporte jusqu'à 99 % d'économies de jetons d'inférence lorsque les agents utilisent la récupération active d'outils au lieu d'intégrer le contexte dans les invites — et une surcharge d'appel d'outil mesurée à environ 10 ms.
→ Présentation de la passerelle MCP
Il est tentant d'intégrer ces contrôles dans le code de l'application : un wrapper ici, un décorateur Python là, une classe utilitaire dans le framework d'agent. Cela fonctionne jusqu'à ce que vous ayez trois équipes d'application, deux fournisseurs de modèles, une acquisition, un audit PCI et un incident de limite de débit un mardi.
À ce stade, vous découvrez que vous avez construit quatre plans de contrôle légèrement différents qui sont en désaccord, et qu'aucun d'entre eux ne peut arrêter une requête provenant d'une équipe qui n'a pas importé le wrapper. La passerelle existe pour la même raison que les passerelles API il y a dix ans : c'est le seul endroit où chaque requête, de chaque application, dans chaque environnement, peut être observée et façonnée uniformément.
L'objection à une passerelle est toujours « un saut supplémentaire dans le chemin de la requête ». La passerelle IA TrueFoundry ajoute environ 5 ms de surcharge p50 et gère plus de 350 requêtes par seconde sur un seul vCPU. L'objection ne résiste pas à l'épreuve des chiffres.
La passerelle est également le seul endroit capable de gérer l'intégralité de la surface d'infrastructure de l'IA moderne : plus de 1000 LLM chez plus de 19 fournisseurs, ainsi que les serveurs MCP que vos agents appellent, et les modèles auto-hébergés derrière votre VPC. TrueFoundry a été citée dans le rapport Gartner « 10 meilleures pratiques pour optimiser les coûts de l'IA générative et agentique 2026 » — car la seule façon pour les entreprises d'optimiser réellement cette surface est de faire passer chaque requête par une couche gouvernée unique.
→ Architecture de la plateforme
→ Architecture du plan de passerelle
Le « tokenmaxxing » est un symptôme d'une adoption non gérée de l'IA. L'architecture ci-dessus est le remède. L'identité définit qui demande. La politique définit ce qui est autorisé. La sécurité définit ce qui est acceptable. L'observabilité définit ce qui s'est réellement passé. Ensemble, ils convertissent l'activité brute des jetons en un cycle de vie de requête gouverné — responsable, utile, sûr, ajustable.
L'objectif n'est pas de réduire l'utilisation de l'IA. L'objectif est de rendre chaque ligne explicable.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception
© 2026 Tous droits réservés.










.webp)





.webp)
.webp)