Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
9,9
Serie TrueFoundry Accelerator: acelerador inteligente de procesamiento de documentos
¿El OCR y el procesamiento de documentos no son un problema resuelto?
Si bien muchos creen que el OCR y el procesamiento de documentos son tecnologías resueltas, la entrada manual de datos cuesta a las empresas estadounidenses entre 15 000 y 30 000 dólares por empleado y año. Fuente: La pérdida operacional y de tiempo debida al procesamiento manual de documentos sigue siendo importante porque:
OCR tradicional: frágil y de bajo rendimiento
Los métodos tradicionales de OCR (visión artificial, reglas y PNL) muestran una baja adaptabilidad a varios formatos y diseños de escritura y, a menudo, no tienen en cuenta los requisitos de formato de datos y contexto.
Baja adaptabilidad: incluso los mejores sistemas de OCR tradicionales de su clase se mantienen con una precisión del 85 al 90% para documentos complejos, y el contenido escrito a mano se reduce a una tasa de precisión de tan solo el 64%. SFuente
Calidad de imagen o iluminación deficientes: 300 DPI es el mínimo estándar para obtener resultados de OCR óptimos
Ruido
Inclinación y orientación
Dependencia de la plantilla y el diseño: se ha optimizado para funcionar en una plantilla específica, por lo que necesita canalizaciones de procesamiento posteriores personalizadas o un cambio de plantilla para cada nueva actualización de tipo de documento o plantilla. Por ejemplo, Nuevo formato de factura de un proveedor, una columna ligeramente desplazada en un informe
Ceguera al contexto: el OCR a nivel de caracteres no logra diferenciar entre caracteres similares, lo que hace que se pierda la comprensión del contexto de todo el documento. Por ejemplo, «50 mg de metformina» podría leerse como «5 mg de metformina», lo cual es incorrecto para cualquier tarea médica posterior.
OCR/LLM Accuracy by Document Type
Document Type
Traditional OCR
SmolDocling (2B)
Qwen-VL-Max (18B)
GPT-4o
Gemini 2.5 Pro
Claude 3.7 Sonnet
Human Baseline
Clean Printed Text
97–98%
92–95%
97–98%
99–99.5%
99–99.5%
99–99.5%
99.8%
Tables & Forms
80–85%
83–87%
91–94%
96–98%
95–97%
95–97%
98–99%
Handwriting (Print)
70–80%
65–75%
80–85%
86–90%
88–92%
89–93%
96–98%
Handwriting (Cursive)
50–70%
60–70%
75–80%
82–90%
80–89%
81–90%
95–97%
Low-Quality Scans
60–75%
80–85%
90–93%
93–96%
92–95%
93–95%
95–97%
Mathematical Notation
70–80%
75–80%
88–93%
92–96%
94–97%
94–96%
97–99%
OCR basado en LLM: impredecible y costoso
Los OCR basados en LLM resuelven algunos desafíos de los métodos tradicionales, pero introducen nuevas complejidades:
No se resuelve para texto manuscrito: a pesar de que GPT-4V y Claude 3.5 Sonnet lo lograron 82-90% de precisión en cuanto al texto manuscrito, una mejora significativa, aún no alcanza los umbrales críticos para la empresa. Por ejemplo, en el cuidado de la salud, una tasa de error del 10 al 18% en las recetas manuscritas podría, literalmente, poner en peligro la vida.
Difícil de escalar:
Costoso prohibitivo: para las organizaciones que procesan millones de documentos cada año.
Respuestas más lentas:
Es difícil mantener los SLA en servidores autónomos
Tiempos de inactividad y picos de latencia con proveedores externos
Salidas inconsistentes:
Alucinaciones - p. ej., un valor completamente inventado para una cláusula de un documento legal
Difícil de cumplir con una producción estructurada
Mismo mensaje, respuestas diferentes
En industrias como los servicios financieros y la atención médica, que procesan millones de documentos críticos al año, es esencial contar con un sistema que pueda escalar de manera confiable y generar resultados de alta calidad a bajo costo
¿Qué tan bueno es su proceso de procesamiento de documentos? (Métricas prácticas)
Operational Metrics & World-Class Benchmarks
Metric
Definition (Short)
World-Class Benchmark
Straight-Through Processing (STP)
% of documents processed end-to-end without human touch
85–95% for structured documents
Field Extraction Accuracy
Correctness of extracted key fields (names, amounts, dates)
99%+ for critical fields
Time to Value
Time from document receipt to structured data availability
<2 min (simple docs), <10 min (complex forms)
Human Edit Rate
% of data requiring manual correction
<5% while maintaining 99%+ accuracy
Processing Cost per Document
Total cost (compute, labor, infra) per processed page
$0.02–$0.15 per page (depending on complexity)
Presentamos el acelerador inteligente de procesamiento de documentos de TrueFoundry
El procesamiento inteligente de documentos (IDP) de TrueFoundry es un acelerador generativo basado en inteligencia artificial que combina prácticas listas para la producción con una canalización de OCR altamente personalizable y precisa para crear y enviar flujos de trabajo de procesamiento de documentos de extremo a extremo.
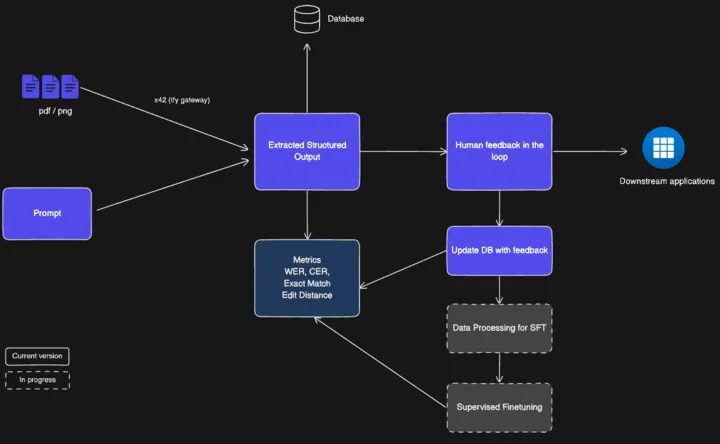
Cómo funciona: ¡Implementa tus aplicaciones con datos estructurados en cuestión de minutos!
El acelerador ingiere sus archivos PDF, imágenes o faxes y los limpia: elimina el ruido, reduce la inclinación y aumenta el tamaño. Por lo tanto, los modelos parten de una imagen nítida. Luego clasifica cada documento (factura, receta, nota manuscrita) y adjunta el esquema, las instrucciones y las reglas de dominio correctos. El modelo de extracción extrae campos estructurados y puntuaciones de confianza; un motor de reglas los valida y enriquece con comprobaciones y búsquedas. Los elementos se envían al revisor a través de una interfaz de usuario sencilla y cada corrección se retroalimenta para mejorar el sistema de forma continua.
Componentes modulares y personalizables
El acelerador está compuesto por componentes modulares conectables que, en conjunto, pueden crear un prototipo desde el primer día o una aplicación lista para la producción a gran escala.
Componentes básicos
Soporte multimodelo (OSS y código cerrado)
Human-in-the-Loop (HITL) y comentarios
Infraestructura de ajuste fino integrada
Monitorización y observabilidad
Integración de la base de conocimientos (RAG + Knowledge Graph)
Componentes avanzados
Clasificación y enrutamiento automatizados
OCR y cajas delimitadoras con reconocimiento regional
Descubrimiento automático de esquemas (tiro cero)
Validación y posprocesamiento
Cumplimiento y auditabilidad
Nuestro diseño ha sido validado en múltiples implementaciones empresariales
Diseñe para la elección y el control
El acelerador no depende del modelo, es de código cerrado o de OSS, y puede enrutarse entre proveedores en función de la relación precio/rendimiento y la conmutación por error. Los expertos se mantienen informados gracias a una interfaz de usuario de revisión adaptada a cada dominio, cuyas modificaciones se convierten en datos de entrenamiento.
Operativo desde el primer día.
Obtiene observabilidad en tiempo real (latencia, rendimiento, coste por documento) además de los KPI empresariales: STP, precisión de campo y velocidad de edición. La validación y el enriquecimiento imponen reglas interdisciplinarias y normalizan los formatos antes de que los datos lleguen a las aplicaciones posteriores.
Adaptable, especialmente para los casos de uso empresarial complejos
El descubrimiento de esquemas, el OCR con reconocimiento regional y la base de conocimientos gestionan diseños complejos; los registros de auditoría conservan cada acción, puntuación y anulación para los entornos regulados.
¿Cómo nos aseguramos de que este sistema escale?
Nuestra arquitectura es un modelo independiente de la nube y basado en microservicios, diseñado para brindar confiabilidad, escalabilidad y rentabilidad de nivel empresarial. Al desvincular los componentes principales de las colas de mensajes asincrónicas, el sistema gestiona las cargas de trabajo fluctuantes y las fallas de los componentes sin perder datos, lo que evita la dependencia de un proveedor.
Capa de ingestión
Puerta de enlace de LLM sin estado: punto de entrada único (autenticación o límite de velocidad) que pone en cola todos los documentos en un tema de mensaje.
Almacenamiento en búfer duradero: las cargas sin procesar se escriben en el almacenamiento de objetos para su reproducción, auditoría y recuperación.
Tubería de procesamiento
Aislamiento del servicio: separe a los trabajadores para su clasificación, extracción y validación; cada uno se puede actualizar y escalar por sí solo.
Escalado automático independiente: los extractores que utilizan mucha CPU y GPU se escalan durante los picos sin afectar a las etapas más ligeras.
Trabajos idempotentes: las tareas reproducibles con deduplicación garantizan reintentos seguros y salidas exactamente una vez.
Administración de datos y estado
Almacenamiento portátil: los cubos compatibles con S3 contienen documentos y artefactos con control de versiones.
Estructura troncal relacional: la base de datos compatible con PostgreSQL rastrea los metadatos, el estado del flujo de trabajo y las colas HITL.
Contratos de esquema: las interfaces claras entre los servicios permiten realizar cambios seguros y compatibles con versiones anteriores.
Capa de retroalimentación y MLOps
Bucle humano: las correcciones verificadas se capturan con su procedencia para los datos de entrenamiento.
Ciclo cerrado: los procesos automatizados de readiestramiento, evaluación e implementación hacen que los mejores modelos vuelvan a la producción.
Versiones reguladas: el registro de modelos, las comprobaciones A/B y las reversiones mantienen las mejoras seguras y auditables.
Conclusión
El OCR moderno no está «resuelto», especialmente cuando la precisión, la escala y el costo son importantes. El IDP Accelerator de TrueFoundry ofrece un enfoque pragmático y listo para la producción, que incluye la extracción multimodelo, la validación automatizada y una intervención humana que mejora el sistema de forma continua. El resultado es un procesamiento más rápido y directo, una mayor precisión sobre el terreno en los documentos que realmente hacen funcionar su empresa y una plataforma que sus equipos pueden utilizar, y no solo una demostración que admirar.
Este acelerador le ayuda a procesar más documentos de manera eficiente y rentable, a la vez que mantiene la integridad de los datos para los auditores, expertos y operadores, lo que permite una implementación inmediata sin la necesidad de una amplia ingeniería personalizada.
Piloto en producción: Conéctese con nosotros a través de este enlace. ¡Podemos crear un prototipo funcional para su propio caso práctico y ayudarle a entregar una aplicación lista para producción en una décima parte del tiempo normal de desarrollo!
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga
































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


