

July 20, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 8, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
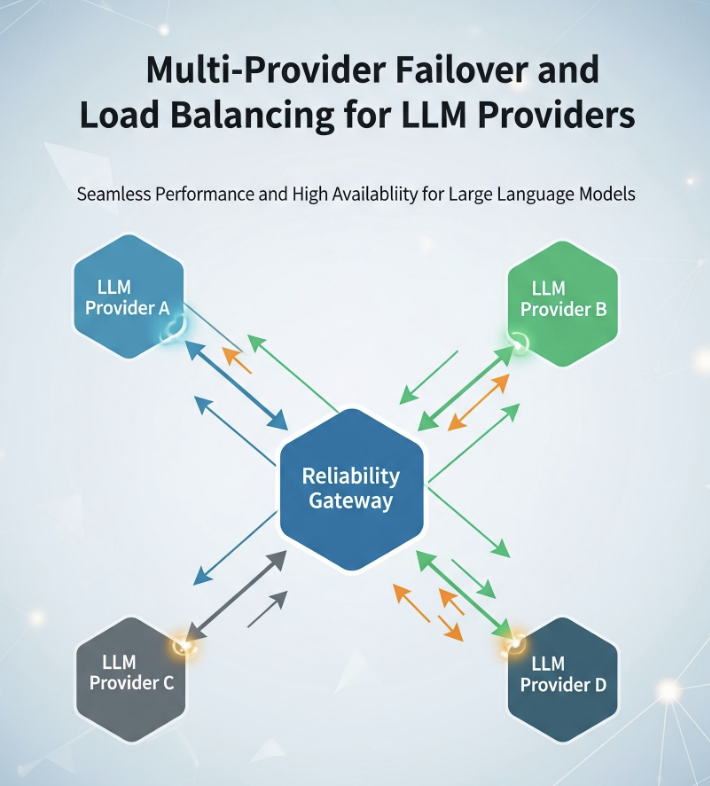
Every model provider has bad days — regional outages, rate-limit storms under load, latency that degrades without quite failing. If your application calls one provider directly, that provider's worst day is your worst day. This post is the reliability layer that prevents it: a taxonomy of how LLM calls fail, retries that don't make things worse, fallback chains across providers, health-aware load balancing, circuit breakers that fail fast, and the genuinely hard case of failing over mid-stream.
2:14 a.m. at Northwind. Nadia, an SRE, woke to a page: the customer-facing support agent was returning errors to every user. Not some users — every user. Northwind's own services were healthy; CPU, memory, and queues were all nominal. The errors were identical: 503 from the model provider. A regional incident on the provider's side had taken its inference endpoint down, and Northwind's agent called that endpoint directly. Every request hit the dead endpoint, failed, and returned an error to the customer. For forty minutes, until the provider recovered, there was nothing to do but wait — the agent had exactly one way to get a completion, and it was down.
The postmortem's action item wasn't "pick a more reliable provider." Every provider has incidents. It was "never depend on a single provider for a request that has to succeed." That is a gateway problem, and this post is how to solve it: retries that don't make things worse, fallback chains across providers, health-aware load balancing, and circuit breakers that fail fast instead of dragging your whole system down with the provider.
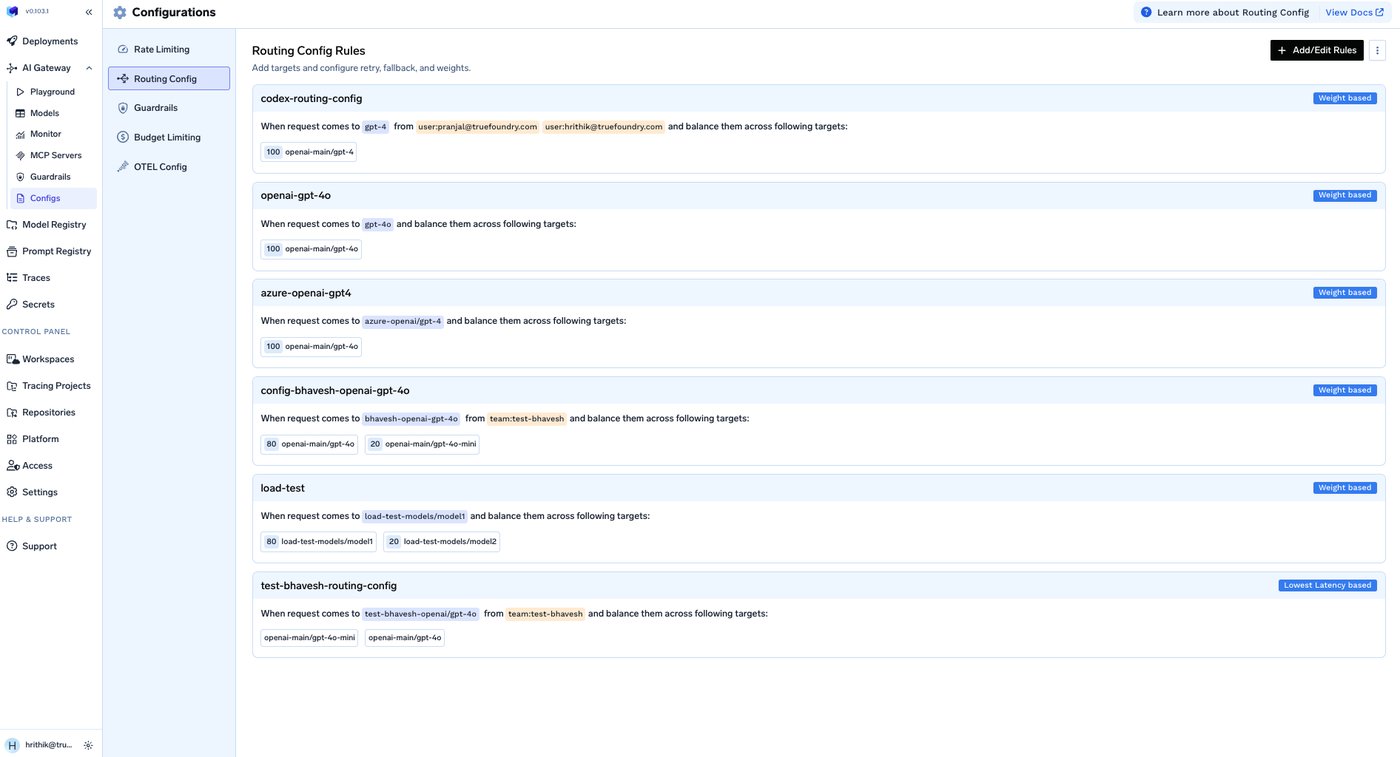
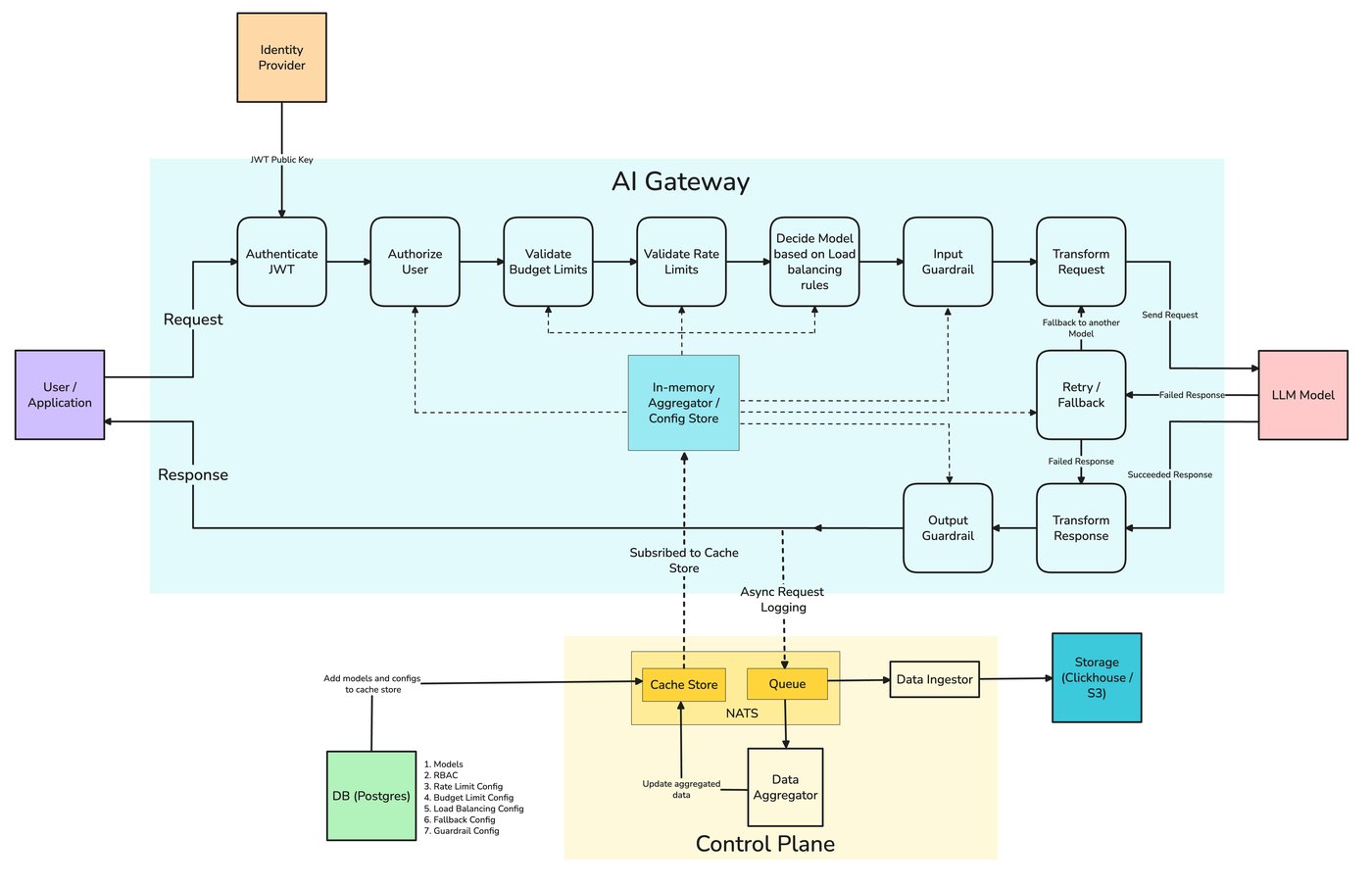
Everything in this post — retries, fallback chains, health-aware load balancing — is something TrueFoundry's AI Gateway expresses as configuration rather than per-service code. Its routing configuration defines load-balancing, fallback, and retry rules in YAML, evaluates them in order so the first matching rule wins, and applies them centrally to every request instead of being reimplemented in each app.
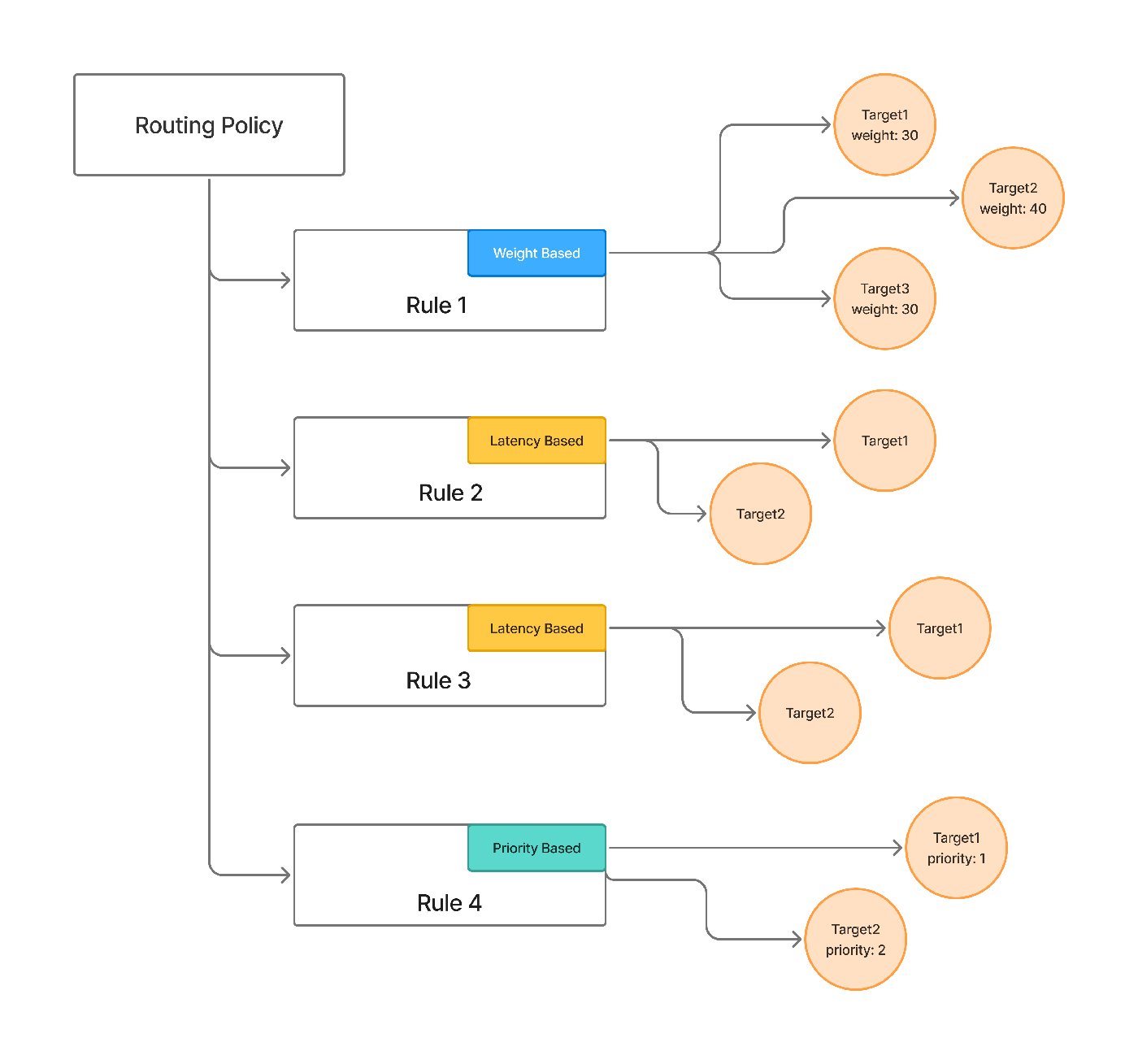
The pieces map onto the failure taxonomy below. Each target carries its own retry_config — attempts, delay, and the status codes worth retrying (429/500/502/503 by default) — and a separate fallback_status_codes list moves the request to the next target when retries won't help. Priority-based routing gives an ordered failover chain; latency-based routing favors the lowest-latency healthy target; and an unhealthy target is detected from its requests-, tokens-, and failures-per-minute and sidelined for a cooldown. The docs even cover the hard streaming case from section 8 — provider-specific stream-overload handling so a fall-through can happen before any user-visible tokens are emitted.
Calling the gateway from an application is a one-line change for anything already using the OpenAI SDK — same client, different base URL and key — so the reliability policy lives in config, not code:
# Calling the gateway from Python (OpenAI-compatible API)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-personal-access-token>", # Bearer-auth'd JWT
)
resp = client.chat.completions.create(
model="gpt-5.5", # the gateway resolves retries + fallback per the config
messages=[{"role": "user", "content": "Summarize the document."}],
)
print(resp.choices[0].message.content)Production LLM applications depend on infrastructure they don't control. Providers have regional and global outages, they return 429s when you exceed a rate limit (and sometimes when they're simply overloaded), and their latency degrades under load without returning an error at all. A direct integration makes the provider a single point of failure: there is no path to a completion except the one that's down.
The work that fixes this — retries, fallback, load balancing, circuit breaking — is cross-cutting. Every service that calls a model needs it, and implementing it per service means each one reimplements the same logic and drifts from the others, so the agent team's retry policy and the search team's are subtly different and both are subtly wrong. The gateway is the one component that sees every provider, holds every key, and normalizes the API to a single shape — which is exactly what failing over from one provider to another requires. Centralizing reliability at TrueFoundry's AI Gateway means one policy, applied uniformly, with the failover events landing on the same request traces as the rest of your telemetry.
The most common reliability mistake is treating every failure as "error, retry." Different failures want different responses, and the table below is the map. Getting this wrong is how a rate limit becomes an outage.
The last row is the one teams get wrong most often: a content-filter rejection is a property of the request, not a transient fault. Retrying it wastes time and money, and failing over to another provider often just produces the same rejection — so it should be classified as non-retryable and surfaced, not silently looped. A separate remediation path may rewrite the prompt, ask the user to clarify, or route to a safer workflow, but that is a policy flow, not failover. Encoding this table once at the gateway — which signal maps to retry, fall back, or surface — means every service inherits the same classification rather than reinventing it; applying that mapping uniformly is part of what TrueFoundry's AI Gateway centralizes.
Retries are the first line of defense and the easiest to weaponize against yourself. Three rules make them safe: exponential backoff (wait longer after each failure), jitter (randomize the wait so clients don't retry in lockstep), and honoring the provider's rate-limit headers — Retry-After where it's sent, or remaining/reset headers like x-ratelimit-* where that's the provider's contract (when the server tells you when to come back, listen).
The failure they prevent is the thundering herd. When a provider starts returning 429s under load and every client retries immediately and in sync, the retries themselves sustain the overload — a self-inflicted denial of service that keeps the provider pinned exactly when you need it to recover. Jitter de-synchronizes the retries, backoff reduces the pressure over time, and Retry-After respects the provider's own signal about when capacity will return. Equally important is not retrying what won't succeed: a malformed request or a content-filter rejection is a 4xx that will fail identically on the next attempt, so retrying it just adds latency and cost.
# Exponential backoff with jitter; honor Retry-After; cap attempts
for attempt in range(MAX_ATTEMPTS): # keep MAX small — 2–3 — then fall back
resp = call(provider, req)
if resp.ok:
return resp
if resp.status == 429 and resp.retry_after:
sleep(resp.retry_after) # respect the server's hint
elif resp.retryable: # 5xx, timeout
sleep(min(CAP, BASE * 2 ** attempt) * random.uniform(0.5, 1.0))
else:
break # non-retryable (4xx, content filter) — stop
raise Exhausted(provider) # hand off to the fallback chain
A consistent retry policy is exactly the kind of thing that drifts when each service owns its own. Applied at TrueFoundry's AI Gateway, the backoff, jitter, and Retry-After handling are uniform across every service that routes through it, and the retry-then-fall-back boundary is one configured behavior rather than five slightly different ones.
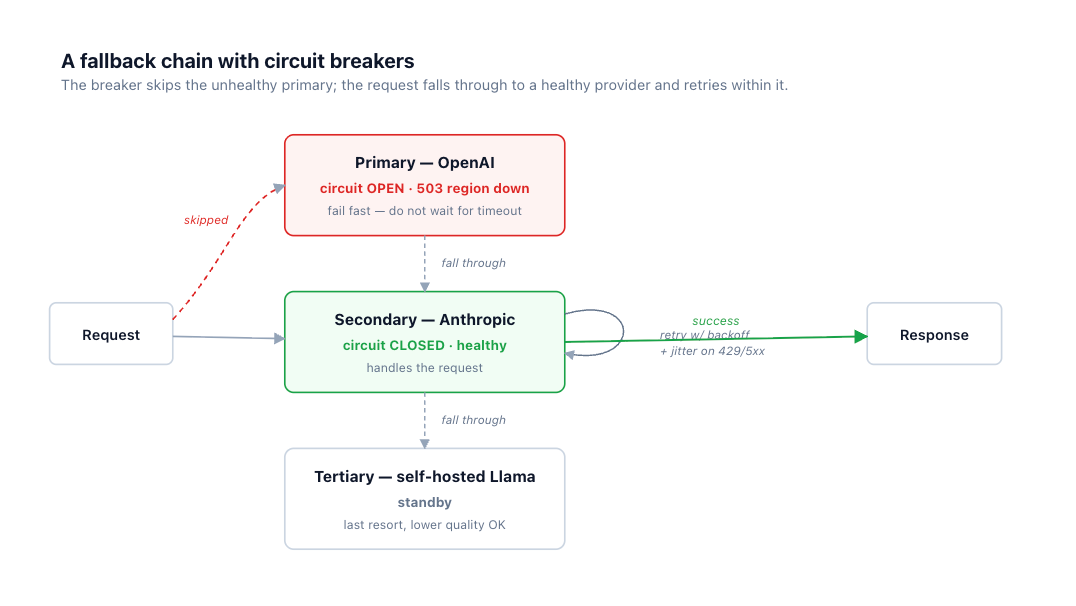
When retries against the primary are exhausted, a fallback chain keeps the request alive: primary, then secondary, then tertiary. There are two axes. Across providers (Claude, then GPT, then Gemini) gives independent failure domains — different infrastructure, different incidents, so the secondary is unlikely to be down for the same reason as the primary. Within a provider (an alternate region or deployment) is cheaper to set up but shares a failure domain, so it protects against a localized issue rather than a provider-wide one.
Illustrative fallback chain (conceptual — exact schema is gateway-specific)
fallbacks:
- provider: openai/gpt-5.5
- provider: anthropic/claude-sonnet-4-6 # different vendor = independent failure domain
- provider: self-hosted/llama-3.x # last resort; lower quality acceptable to stay up
trigger_on: [5xx, timeout, circuit_open] # NOT content-filter rejections
This isn't only a pattern — it's how TrueFoundry's AI Gateway is configured. A fallback chain is a priority-based routing rule: each target gets a priority, its own retry policy, and the status codes that should trigger a fall-through to the next target — spanning hosted and self-hosted models behind one OpenAI-compatible API, so the fallback can be a different vendor or your own model without the application knowing:
How TrueFoundry expresses the same chain (gateway-load-balancing-config)
name: reliability-config
type: gateway-load-balancing-config
rules:
- id: chat-failover
type: priority-based-routing # ordered chain: priority 0, then 1, then 2
when:
models: [gpt-5.5]
load_balance_targets:
- target: openai/gpt-5.5
priority: 0
retry_config: { attempts: 2, on_status_codes: ["429","500","502","503"] }
fallback_status_codes: ["429","500","502","503"]
- target: anthropic/claude-sonnet-4-6 # different vendor = independent failure domain
priority: 1
- target: self-hosted/llama-3.x # last resort; lower quality OK
priority: 2Retries happen within a target via retry_config; fallback_status_codes decide when to give up and move to the next. The gateway's request-level view records which targets were tried and why a fall-through happened, so failover is debuggable rather than inferred — and the full schema, including weight- and latency-based strategies, is in the routing config docs.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada









.png)

.webp)
.webp)
.webp)



.webp)
.webp)


