Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
9,9
Wie man über die AI-Gateway-Architektur im generativen KI-Stack nachdenkt
In modernen generativen KI-Systemen ist KI-Gateway funktioniert als kritische Proxyschicht zwischen Anwendungen und Anbietern von Sprachmodellen (LLM). Es spielt eine zentrale Rolle bei der Verwaltung von Zuverlässigkeit, Beobachtbarkeit, Zugriffskontrolle und Kosteneffizienz für jede Anforderung, die in die Produktion eingeht.
Weil das Tor liegt im kritischen Pfad des Produktionsverkehrs, es muss unter Berücksichtigung der folgenden Kernprinzipien konzipiert werden:
Wichtige architektonische Prioritäten:
Hohe Verfügbarkeit: Das Gateway darf nicht zu einer einzigen Ausfallstelle werden. Selbst angesichts von Abhängigkeitsproblemen (wie Datenbank- oder Warteschlangenausfällen) sollte es den Datenverkehr weiterhin problemlos abwickeln.
Niedrige Latenz: Da es bei jeder Inferenzanforderung enthalten ist, muss das Gateway Folgendes hinzufügen minimaler Aufwand um eine schnelle Benutzererfahrung zu gewährleisten.
Hoher Durchsatz und Skalierbarkeit: Das System sollte linear mit der Auslastung skalieren und in der Lage sein, Tausende von gleichzeitigen Anfragen mit effizienter Ressourcennutzung zu verarbeiten.
Keine externen Abhängigkeiten im Hot Path: Alle netzwerkgebundenen oder festplattengebundenen Operationen sollten auf asynchrone Systeme ausgelagert werden, um Leistungsengpässe zu vermeiden.
In-Memory-Entscheidungsfindung: Wichtige Prüfungen wie Ratenbegrenzung, Lastausgleich, Authentifizierung und Autorisierung sollten alle im Speicher durchgeführt werden, um maximale Geschwindigkeit und Zuverlässigkeit zu gewährleisten.
Trennung von Steuerungsebene und Proxyebene: Konfigurationsänderungen und Systemmanagement sollten vom Live-Verkehrsrouting entkoppelt werden, um globale Bereitstellungen mit regionaler Fehlerisolierung zu ermöglichen.
Die KI-Gateway-Architektur von TrueFoundry
True Foundry's KI-Gateway verkörpert alle oben genannten Designprinzipien und wurde speziell für niedrige Latenz, hohe Zuverlässigkeit und nahtlose Skalierbarkeit entwickelt
Die Gateway-Architektur von TrueFoundry
Hauptmerkmale der AI-Gateway-Architektur
Basiert auf Hono Framework: Das Gateway nutzt Hono, ein minimalistisches, ultraschnelles Framework, das für Edge-Umgebungen optimiert ist. Dies gewährleistet einen minimalen Laufzeitaufwand und eine extrem schnelle Anforderungsbearbeitung.
Keine externen Aufrufe auf dem Anforderungspfad: Sobald eine Anfrage das Gateway erreicht, löst sie keine externen Aufrufe aus (es sei denn, das semantische Caching ist aktiviert). Die gesamte Betriebslogik wird intern verarbeitet, wodurch das Risiko reduziert und die Zuverlässigkeit erhöht wird.
In-Memory-Durchsetzung: Alle Entscheidungen über Authentifizierung, Autorisierung, Ratenbegrenzung und Lastenausgleich werden mithilfe von In-Memory-Konfigurationen, wodurch Reaktionszeiten im Bereich von unter einer Millisekunde gewährleistet werden.
Asynchrone Protokollierung: Protokolle und Anforderungsmetriken werden asynchron in eine Nachrichtenwarteschlange übertragen, um sicherzustellen, dass die Datenbeobachtbarkeit den Anforderungspfad nicht blockiert oder verlangsamt.
Ausfallsicheres Verhalten: Selbst wenn die externe Protokollierungswarteschlange ausgefallen ist, wird das Gateway nicht scheitern irgendwelche Anfragen. Dies garantiert Verfügbarkeit und Widerstandsfähigkeit bei teilweisen Systemausfällen.
Horizontal skalierbar: Das Gateway ist CPU-gebunden und zustandslos, was eine einfache Skalierung ermöglicht. Es arbeitet effizient bei hoher Parallelität und geringem Speicherverbrauch.
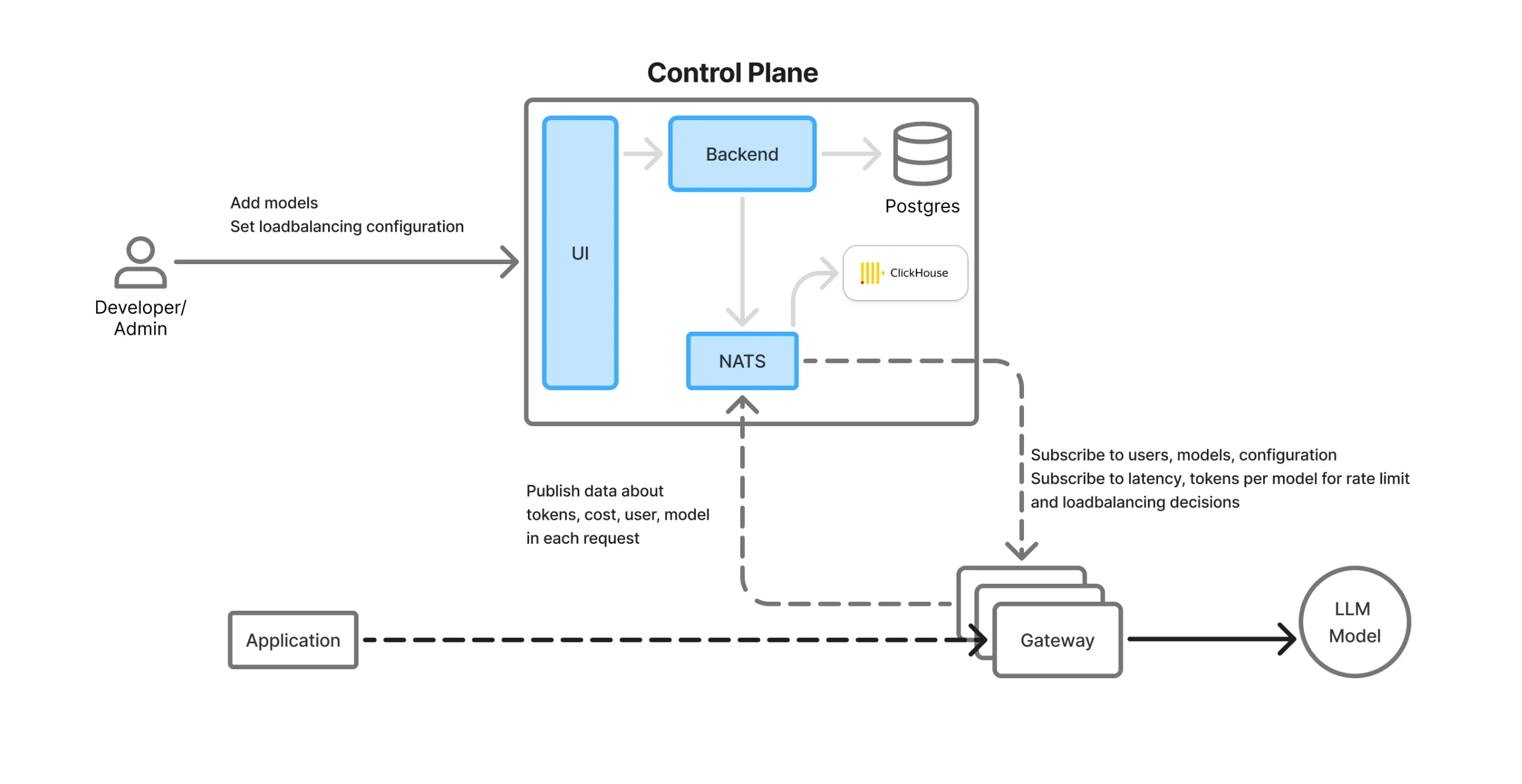
Steuerungsebene und Datenfluss
TrueFoundry trennt die Steuerungsebene (Management) von der Datenebene (Verkehrsrouting in Echtzeit) für Skalierbarkeit und Flexibilität.
Überblick über die Komponenten des AI-Gateways:
UI: Weboberfläche mit LLM-Spielplatz, Monitoring-Dashboards und Konfigurationspanels für Modelle, Teams, Ratenlimits usw.
Klicken Sie auf Haus: Leistungsstarke Spaltendatenbank zum Speichern von Protokollen, Metriken und Nutzungsanalysen.
NATS-Warteschlange: Fungiert als Echtzeit-Synchronisationsbus zwischen der Steuerungsebene und den verteilten Gateway-Pods. Alle Konfigurations-/Statusaktualisierungen werden über NATS übertragen und sind sofort in allen Regionen verfügbar.
Backend-Dienst: Orchestriert die Konfigurationssynchronisierung, Datenbankaktualisierungen und die Erfassung von Analysen.
Gateway-Pods: Statuslose, regionsinterne, kompakte Proxys, die den tatsächlichen LLM-Verkehr abwickeln. Sie verarbeiten NATS-Nachrichten und führen die gesamte Logik im Speicher aus, ohne externe Abhängigkeiten.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Leistungsbenchmarks für das AI Gateway von TrueFoundry
Das Gateway von TrueFoundry wurde gründlich auf seine Leistung unter produktionsähnlichen Belastungen getestet:
250 RPS auf 1 CPU/1 GB RAM mit nur 3 ms Latenz hinzugefügt.
Skaliert effizient auf bis zu 350 RPS pro Pod, bevor die CPU-Auslastung erreicht ist. Darüber hinaus können Sie Replikate hinzufügen.
unterstützt Zehntausende von RPS mit horizontaler Skalierung über Regionen hinweg.
Keine zusätzliche Latenz selbst wenn mehrere Regeln für Ratenlimit, Authentifizierung und Lastenausgleich gelten.
Warum das wichtig ist
Wenn Sie GenAI-Workloads in großem Umfang ausführen oder planen, mehrere LLMs (OpenAI, Claude, Open Source usw.) zu integrieren, wird das Gateway zur Grundlage Ihres Stacks.
Das Design von TrueFoundry gewährleistet:
Du kannst sicher routen und skalieren anbieterübergreifend.
Bewerben feinkörnige Steuerungen auf Benutzer-/Teamebene.
Sorgen Sie für Beobachtbarkeit und Steuerung im gesamten System und kontrollieren Sie gleichzeitig die Kosten generativer KI.
Mach das alles ohne die Latenz oder Zuverlässigkeit zu beeinträchtigen.
Eine Demo buchen jetzt, wenn Sie mit AI Gateway beginnen möchten.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last

































.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




