




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 12, 2026

Blazingly fast way to build, track and deploy your models!
À medida que a adoção de machine learning continua a acelerar em todas as indústrias, a necessidade de pipelines de ML robustos, escaláveis e automatizados nunca foi tão grande. Em 2026, as plataformas MLOps tornaram-se fundamentais para operacionalizar a IA, desde o treinamento e implantação de modelos até o monitoramento e a governança.
Essas plataformas otimizam o ciclo de vida de ponta a ponta, ajudando as equipes a gerenciar a complexidade, garantir a reprodutibilidade e acelerar o tempo de valorização. Seja você uma startup escalando seu primeiro modelo ou uma empresa implantando centenas, escolher a plataforma MLOps certa é fundamental.
Neste guia, exploramos o que é MLOps, por que é importante e as melhores ferramentas MLOps que moldam o cenário em 2026.

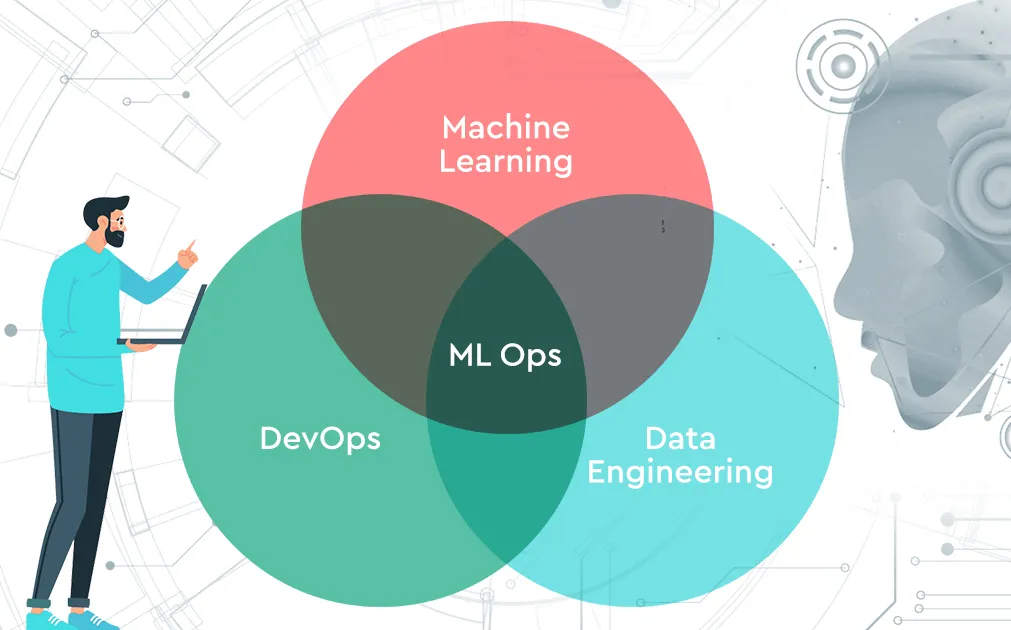
MLOps (Machine Learning Operations) é uma disciplina que mescla os princípios de machine learning, DevOps e engenharia de dados para permitir o desenvolvimento, implantação, monitoramento e manutenção de sistemas de ML confiáveis em escala. Garante que os modelos construídos em ambientes experimentais possam ser transicionados de forma segura e eficiente para a produção, onde devem ter um desempenho consistente, adaptar-se às mudanças e permanecer responsáveis.
Os fluxos de trabalho tradicionais de DevOps focam no controle de versão, pipelines de CI/CD, testes automatizados e confiabilidade do sistema. O MLOps herda estes, mas os estende para abordar os desafios únicos de machine learning: gerenciar dados em constante evolução, retreinar modelos para considerar o desvio, avaliar resultados não determinísticos e manter a reprodutibilidade entre as iterações do modelo.
À medida que o machine learning avança da experimentação para a implantação em escala empresarial, as ferramentas MLOps tornaram-se essenciais para garantir consistência, confiabilidade e velocidade em todo o ciclo de vida do modelo. Sem uma solução MLOps centralizada, as equipes frequentemente acabam com ferramentas fragmentadas, processos manuais e fluxos de trabalho inconsistentes que atrasam a inovação e introduzem riscos operacionais.
Plataformas MLOps resolvem esses desafios ao fornecer uma interface unificada para gerenciar pipelines de dados, fluxos de trabalho de treinamento, rastreamento de modelos, implantação e monitoramento, tudo em um só lugar. Essa consolidação permite uma colaboração mais estreita entre cientistas de dados, engenheiros de ML e equipes de DevOps, reduzindo o atrito na transição e melhorando a reprodutibilidade entre os ambientes.
Ao selecionar as ferramentas MLOps em 2026, é importante avaliar não apenas as funcionalidades, mas quão bem a plataforma suporta seu fluxo de trabalho de ML, escala com sua infraestrutura e se alinha com os objetivos operacionais de sua equipe. Abaixo estão alguns critérios essenciais a serem considerados::
Uma plataforma MLOps ideal deve cobrir todo o ciclo de vida de machine learning, desde o versionamento de dados e treinamento até a implantação e monitoramento. Cadeias de ferramentas fragmentadas podem criar ineficiências e inconsistências entre as equipes. Plataformas que unificam essas etapas em um único fluxo de trabalho ajudam a melhorar a reprodutibilidade, reduzir as transições e acelerar a iteração.
À medida que as cargas de trabalho de ML escalam, a plataforma também deve escalar. Uma boa solução MLOps deve suportar desde a experimentação local até o treinamento distribuído em múltiplas GPUs ou nós. Também deve oferecer flexibilidade na implantação, suportando ambientes nativos da nuvem, on-premise e híbridos, sem prender você a uma pilha específica.
A usabilidade é muitas vezes negligenciada, mas crítica. Uma plataforma robusta oferece interfaces limpas, tanto de UI quanto de CLI, juntamente com SDKs abrangentes que se integram com frameworks populares como PyTorch, TensorFlow e Hugging Face. Uma plataforma intuitiva tanto para cientistas de dados quanto para engenheiros de ML promove melhor colaboração e um onboarding mais rápido.
MLOps não existe isoladamente. Sua plataforma deve se integrar perfeitamente com sistemas existentes para armazenamento (como S3 ou GCS), ferramentas de CI/CD (como GitHub Actions ou Jenkins), plataformas de observabilidade (como Prometheus ou Grafana) e registros de modelos. Uma integração robusta garante um fluxo contínuo de dados e modelos em todo o seu pipeline.
Para organizações que operam em ambientes regulamentados, os recursos de governança são essenciais. A plataforma deve suportar controle de acesso baseado em função (RBAC), logs de auditoria e rastreamento de linhagem. A conformidade com padrões como SOC 2, HIPAA ou GDPR ajuda a garantir a privacidade dos dados, a confiança e a viabilidade a longo prazo em ambientes corporativos.
O cenário de MLOps em 2026 é rico em plataformas que atendem a diferentes necessidades, desde o rastreamento leve de experimentos até a implantação e monitoramento de modelos de nível empresarial. Abaixo estão as 25 melhores ferramentas MLOps, ajudando as equipes a otimizar seus fluxos de trabalho de ML, infraestrutura e operacionalizar modelos em escala. Cada plataforma tem seus pontos fortes, dependendo da sua pilha de tecnologia, maturidade da equipe e objetivos de negócios.
TrueFoundry é uma plataforma moderna de MLOps e LLMOps construída para equipes que desejam implantar, escalar e monitorar modelos de machine learning e IA generativa em produção. Ela abstrai a complexidade da infraestrutura, ao mesmo tempo em que oferece controle total, permitindo que as equipes passem da experimentação para a implantação em minutos.
Ao contrário dos sistemas legados, o TrueFoundry é otimizado para desempenho, produtividade do desenvolvedor e fluxos de trabalho GenAI-first, incluindo suporte para agentes, pipelines RAG e rastreamento avançado. Sua segurança de nível empresarial e design modular a tornam uma das melhores ferramentas MLOps, adequada para organizações de todos os tamanhos.
Principais Recursos:
Ideal Para:
Equipes orientadas por IA que constroem produtos baseados em LLM, especialmente onde desempenho, segurança e observabilidade são críticos. Excelente para equipes ágeis ou empresas que precisam de implantação GenAI escalável. Aqui estão algumas das melhores ferramentas de gateway LLM.
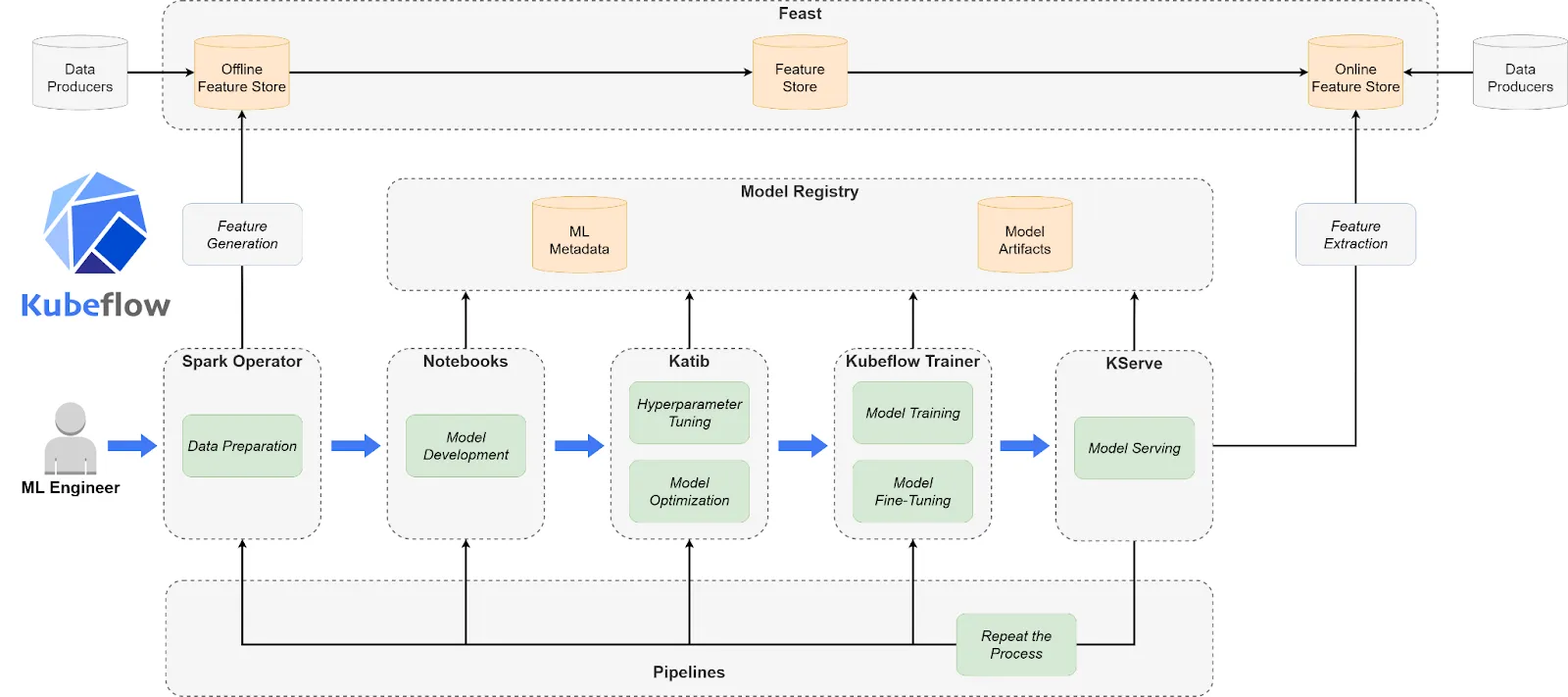
Kubeflow é uma das melhores ferramentas MLOps de código aberto e nativa do Kubernetes para construir e gerenciar fluxos de trabalho de ML portáteis e composíveis. Oferece a flexibilidade para orquestrar treinamento, ajuste e serviço usando abstrações familiares do Kubernetes. Embora poderoso, o Kubeflow exige conhecimento aprofundado de infraestrutura e não é ideal para equipes sem suporte DevOps dedicado. Ele se destaca quando pipelines de ML personalizados, escaláveis e seguros são uma necessidade.
Principais Recursos:
Melhor Para:
Equipes com forte expertise em Kubernetes que buscam personalizar e controlar totalmente seus fluxos de trabalho de MLOps, especialmente em ambientes regulamentados ou de nuvem híbrida.
MLflow é uma plataforma MLOps leve e de código aberto criada pela Databricks, focada no gerenciamento de experimentação de ML e versionamento de modelos. Seus componentes modulares permitem que as equipes integrem rastreamento, registro e implantação em seus fluxos de trabalho existentes.
Esta ferramenta MLOps é ideal para equipes menores ou organizações que desejam flexibilidade sem a sobrecarga de uma infraestrutura em grande escala ou do Kubernetes.
Principais Recursos:
Melhor Para:
Equipes de ML que buscam ferramentas leves e personalizáveis para rastrear experimentos, compartilhar modelos e gerenciar versões sem depender de uma plataforma em larga escala.
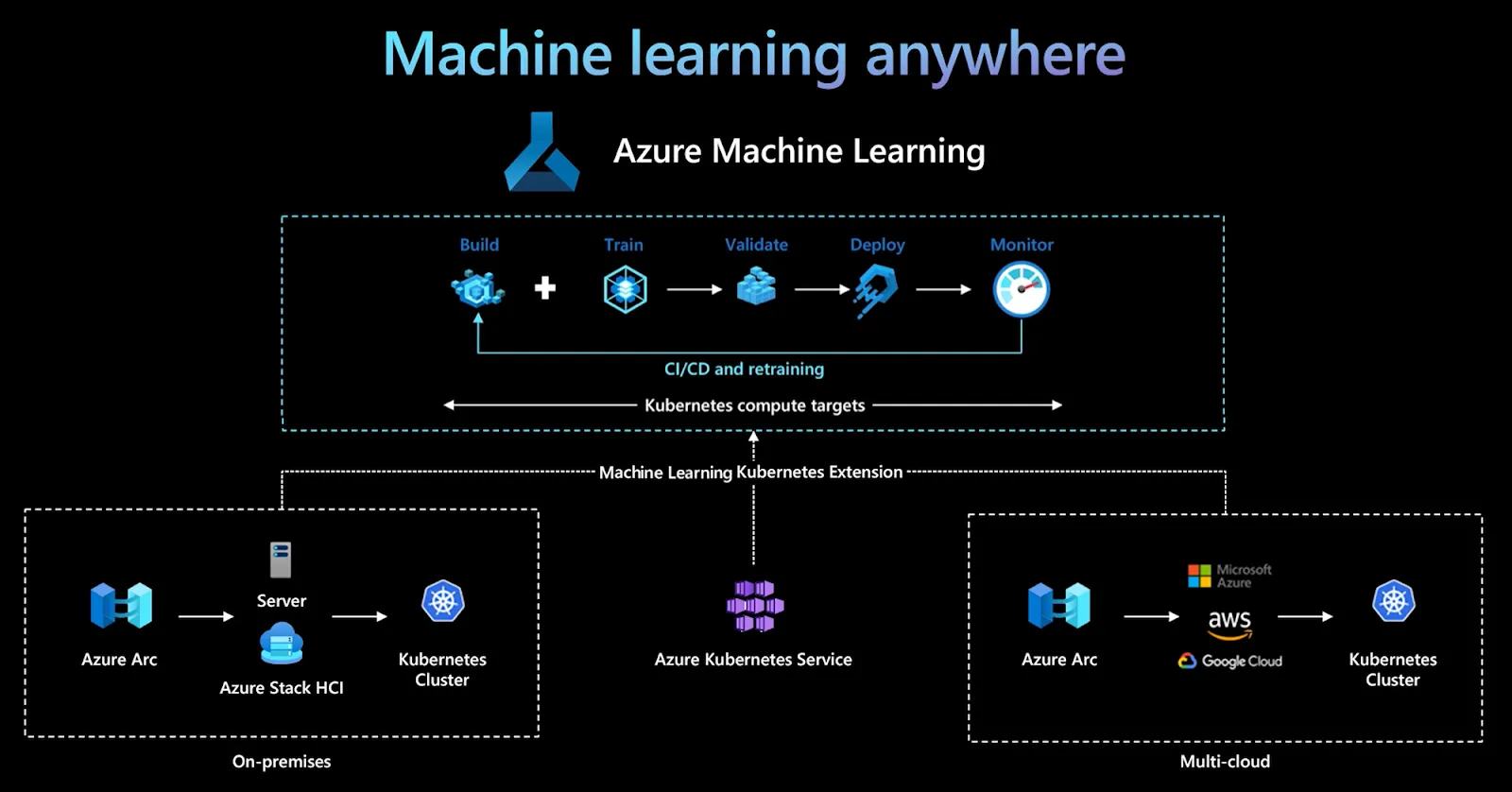
Azure Machine Learning é a plataforma MLOps totalmente gerenciada da Microsoft, projetada para construir, treinar, implantar e monitorar modelos de machine learning em escala empresarial. Ela se integra perfeitamente com o ecossistema Azure, oferecendo um poderoso conjunto de ferramentas para gerenciamento de modelos, AutoML e IA responsável. O Azure ML é ideal para organizações que já investem na nuvem da Microsoft e buscam segurança, escalabilidade e conformidade.
Principais Recursos:
Ideal Para:
Empresas que operam no Microsoft Azure e precisam de uma plataforma MLOps altamente segura, escalável e totalmente integrada, com conformidade empresarial incorporada.
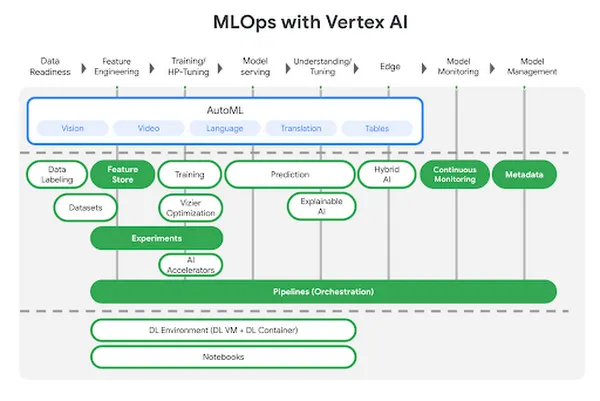
Vertex AI é a plataforma unificada do Google Cloud para desenvolvimento de ML, combinando AutoML e treinamento de modelos personalizados em uma única interface. Ela abstrai a infraestrutura enquanto oferece serviços avançados como feature stores, pipelines e rastreamento de experimentos.
Construída para escalabilidade e integração com o ecossistema do Google, esta ferramenta MLOps é otimizada para implantação de ML em nível de produção e fluxos de trabalho orientados a dados.
Principais Recursos:
Ideal Para:
Equipes que constroem e escalam machine learning no Google Cloud e desejam uma plataforma MLOps gerenciada e escalável com integração completa de dados e implantação.
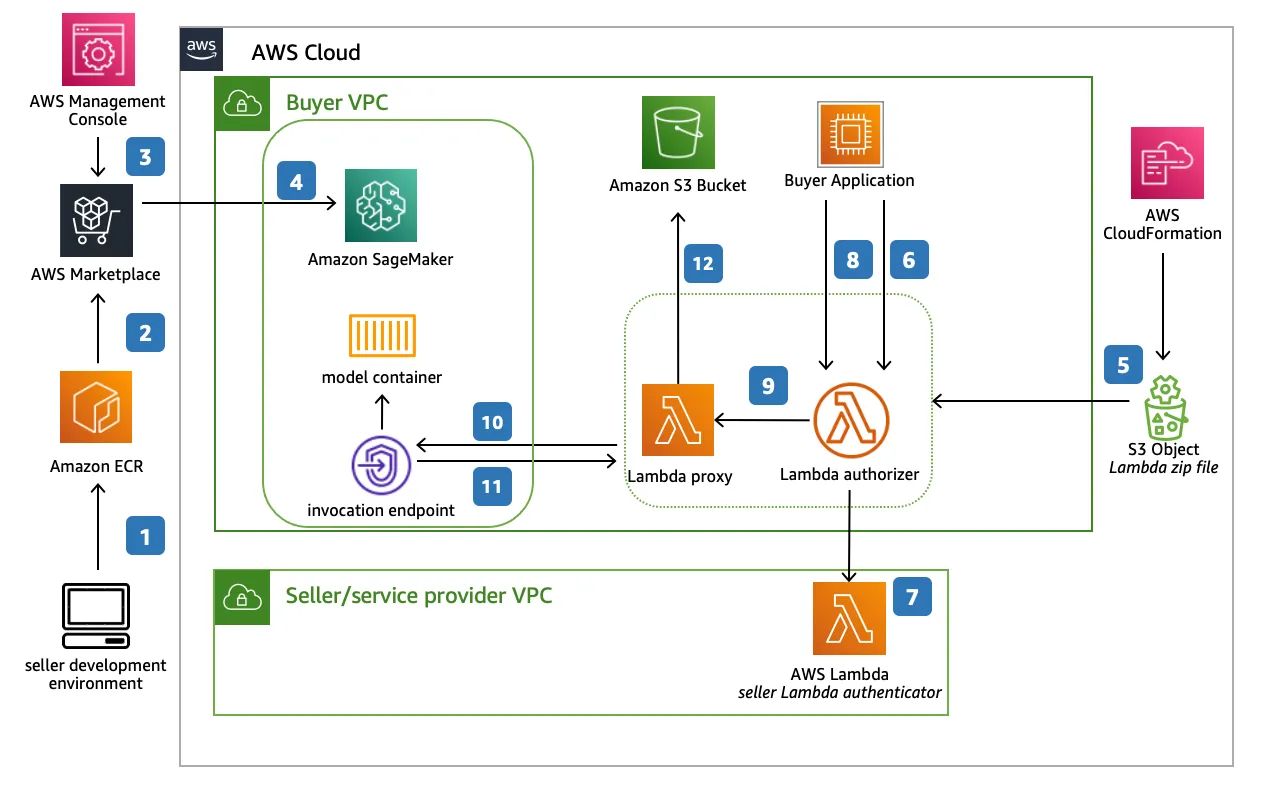
Amazon SageMaker é a principal plataforma MLOps da AWS, oferecendo desde o pré-processamento de dados até a implantação de modelos em tempo real. Conhecido por sua ampla funcionalidade, o SageMaker suporta desenvolvimento de modelos personalizados, AutoML, hospedagem de modelos e ferramentas avançadas de monitoramento. É fortemente integrado ao ecossistema AWS, tornando-o uma escolha ideal para empresas nativas da nuvem.
Principais Recursos:
Ideal Para:
Organizações que já utilizam a AWS para infraestrutura e que precisam de uma plataforma MLOps robusta e escalável, com integração profunda e suporte completo ao ciclo de vida.
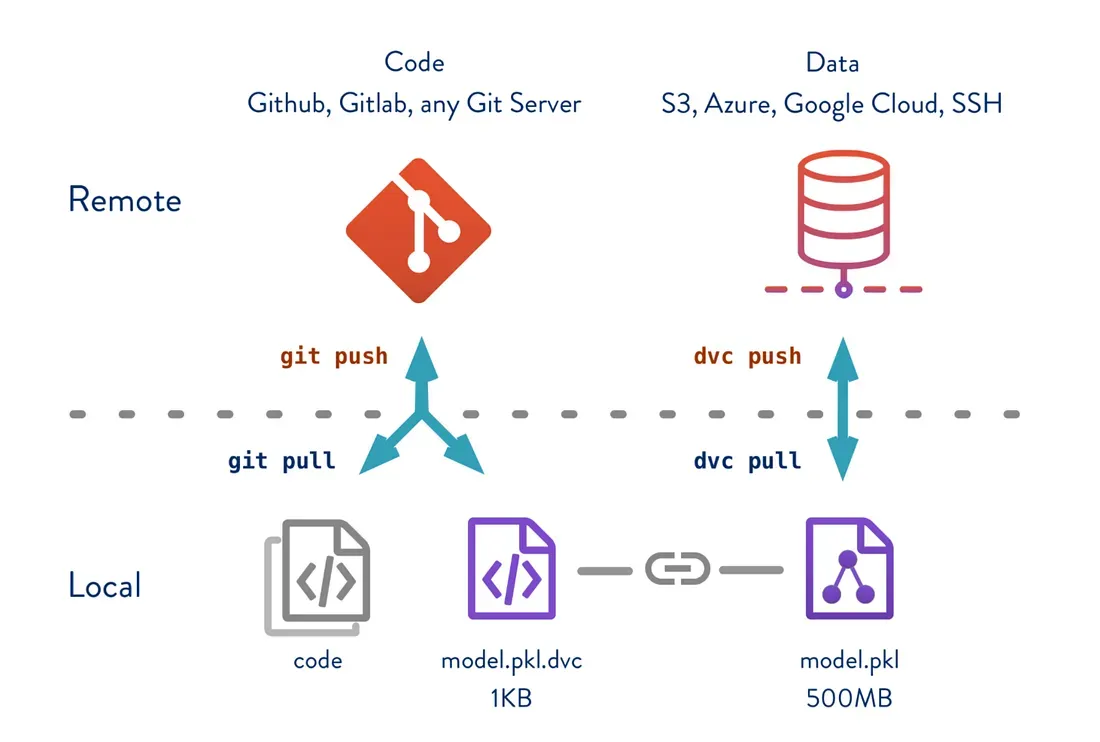
DVC é uma ferramenta de código aberto que traz controle de versão para projetos de machine learning, rastreando conjuntos de dados, modelos e experimentos — de forma semelhante a como o Git gerencia código. Não pretende ser uma plataforma MLOps full-stack, mas foca na reprodutibilidade, colaboração e rastreamento de modelos através de fluxos de trabalho compatíveis com Git. O DVC integra-se perfeitamente em pipelines existentes e dá aos profissionais de ML mais controle sobre o gerenciamento de experimentos.
Principais Recursos:
Ideal Para:
Equipes que buscam recursos MLOps leves e com foco em código, centrados na reprodutibilidade, fluxos de trabalho baseados em Git e gerenciamento de experimentos — especialmente em projetos de pesquisa e ML iterativos.
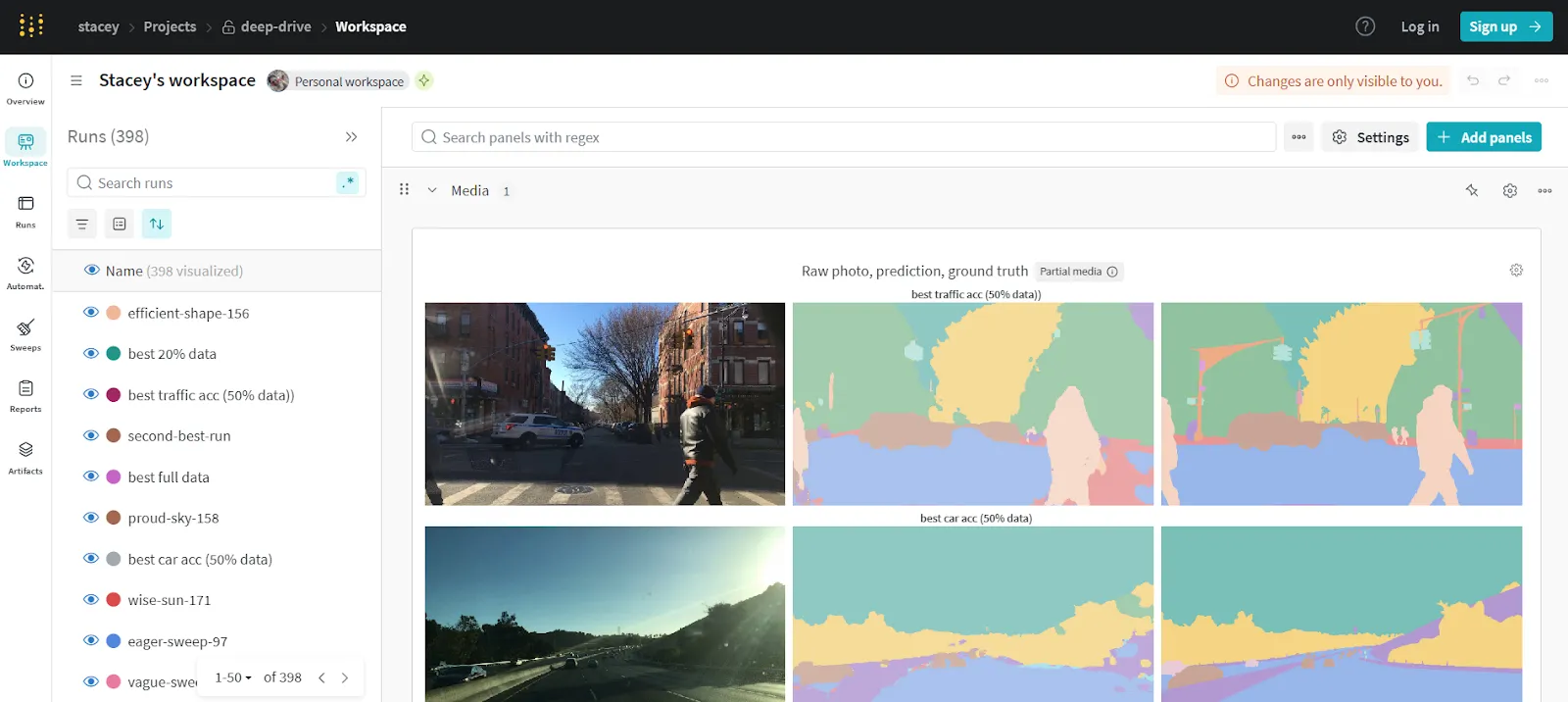
Weights & Biases (W&B) é uma das melhores ferramentas MLOps para rastreamento de experimentos, colaboração e visualização de modelos. É amplamente adotado em ambientes de pesquisa e produção, oferecendo integração simples com a maioria dos frameworks de ML. O W&B foca na observabilidade, possibilitando insights em tempo real sobre o desempenho de treinamento, hiperparâmetros e métricas do sistema.
Principais Recursos:
Ideal para:
Equipes de ML focadas em iteração rápida, visualização e colaboração. Ideal para ambientes orientados à pesquisa e equipes que desejam uma melhor compreensão do desempenho do treinamento.
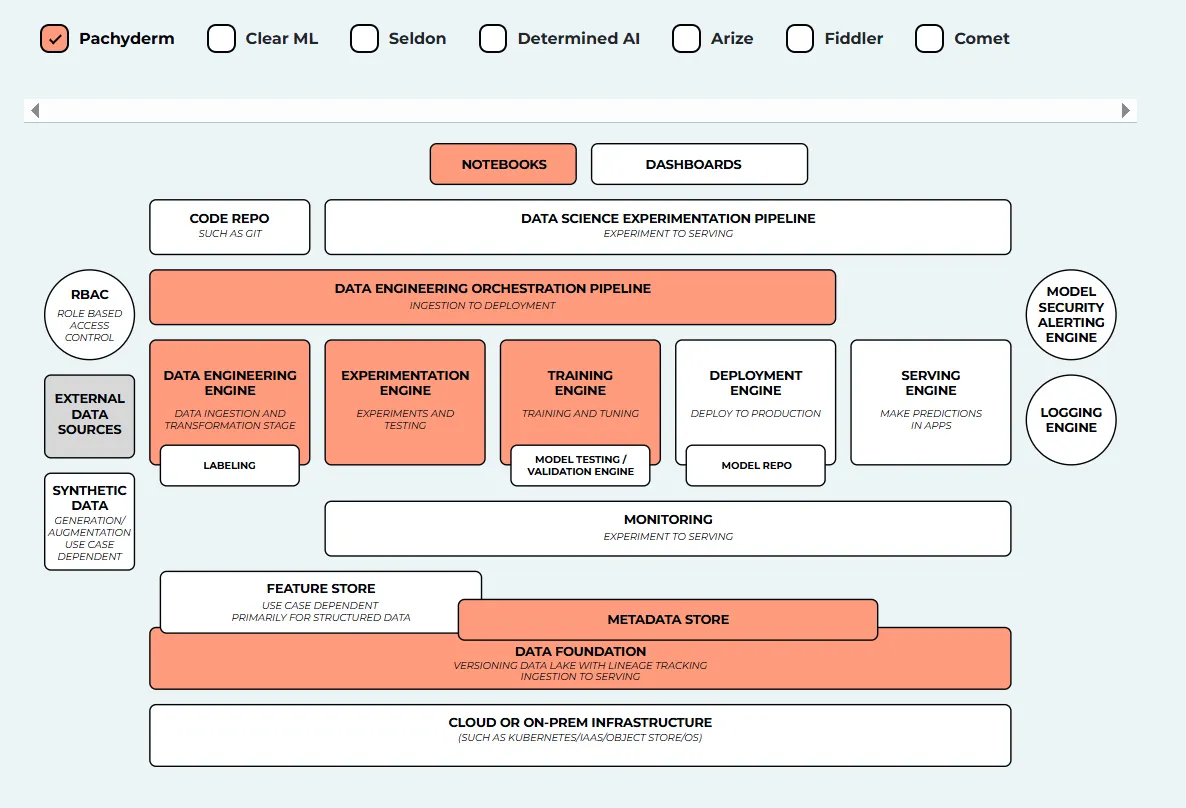
Pachyderm é uma plataforma de ciência de dados de código aberto construída para linhagem de dados, controle de versão e pipelines reproduzíveis. Ao contrário das ferramentas MLOps tradicionais, o Pachyderm usa uma abordagem semelhante ao Git para dados, tornando-o altamente adequado para equipes que lidam com dependências de dados complexas ou ambientes regulamentados. Ele combina conteinerização com orquestração de pipeline de dados para garantir fluxos de trabalho versionados e rastreáveis.
Principais recursos:
Ideal para:
Equipes em setores regulamentados ou fluxos de trabalho intensivos em dados que precisam de forte controle de versão e rastreamento de linhagem para conformidade, reprodutibilidade e escala.
Allegro AI é uma plataforma MLOps projetada especificamente para gerenciar fluxos de trabalho de aprendizado profundo em escala — especialmente em ambientes de visão computacional e IA de borda. Ela se concentra em melhorar a reprodutibilidade, colaboração e rastreabilidade em todo o ciclo de vida da IA.
Com fortes capacidades em gerenciamento de conjuntos de dados, versionamento de modelos e rastreamento de experimentos, esta ferramenta MLOps oferece uma infraestrutura segura e completa para equipes que constroem e implantam modelos de alto desempenho em produção ou em ambientes regulamentados.
Principais recursos:
Ideal para:
Equipes que trabalham com visão computacional, aprendizado profundo ou casos de uso de implantação de borda — especialmente em setores como automotivo, manufatura, saúde ou defesa, onde a rastreabilidade e o controle sobre dados e modelos são essenciais.
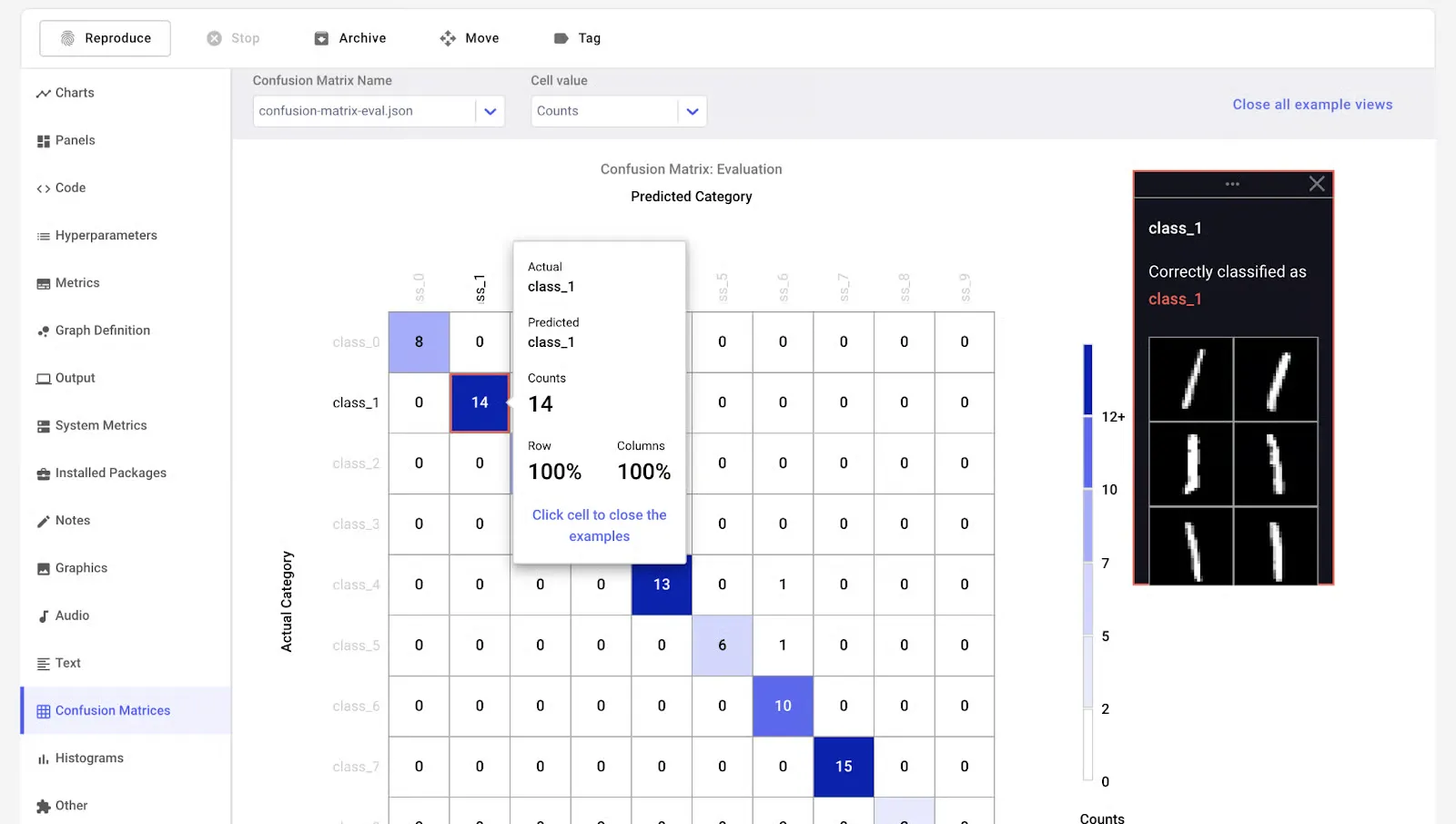
Comet ML é uma plataforma de machine learning projetada para ajudar a monitorar, analisar e refinar modelos e experimentos. Ela funciona perfeitamente com bibliotecas populares como Scikit-learn, PyTorch, TensorFlow e Hugging Face.
A ferramenta Comet MLOps facilita a exploração e comparação dos resultados de experimentos, ao mesmo tempo em que oferece visualizações ricas para amostras de dados, incluindo imagens, áudio, texto e tabelas estruturadas.
Principais Recursos:
Ideal Para:
Ideal para cientistas de dados, engenheiros de machine learning e equipes que desejam uma maneira fácil de rastrear experimentos, comparar resultados e melhorar o desempenho do modelo.

Prefect é uma ferramenta moderna de orquestração de fluxo de trabalho projetada para monitorar, coordenar e gerenciar pipelines de dados entre aplicações. É uma solução de código aberto e leve, construída para suportar fluxos de trabalho de machine learning e dados de ponta a ponta.
Você pode usar o Prefect Orion UI ou o Prefect Cloud para gerenciar e visualizar fluxos de trabalho. O Prefect Orion UI é um motor de orquestração e servidor de API de código aberto, hospedado localmente, que fornece insights sobre as execuções de fluxo de trabalho locais e a atividade do sistema.
O Prefect Cloud, por outro lado, é um serviço hospedado que permite visualizar fluxos, execuções e implantações, ao mesmo tempo em que gerencia contas, espaços de trabalho e colaboração em equipe.
Principais Recursos:
Ideal para:
Engenheiros de dados, engenheiros de ML e equipes que precisam de orquestração de fluxo de trabalho confiável, visibilidade dos pipelines e colaboração escalável para dados e projetos de aprendizado de máquina.
Metaflow é uma ferramenta de gerenciamento de fluxo de trabalho para ciência de dados e aprendizado de máquina que simplifica a construção, execução e implantação de modelos. Esta ferramenta de MLOps ajuda as equipes a gerenciar pipelines em escala, lidando automaticamente com o rastreamento de experimentos, versionamento de dados e implantação em produção.
Principais Recursos:
Ideal para:
Cientistas de dados e equipes de ML que buscam uma ferramenta de fluxo de trabalho simples e escalável que gerencia orquestração, rastreamento e implantação, minimizando a sobrecarga de MLOps.
Dagster é uma plataforma de orquestração nativa da nuvem que ajuda equipes de dados a definir, executar e monitorar pipelines de dados complexos de forma eficiente. Ela foca em confiabilidade, observabilidade e uma experiência de desenvolvimento moderna para gerenciar fluxos de trabalho de dados.
Principais Recursos:
Ideal Para:
Engenheiros de dados e equipes de dados que precisam de orquestração de pipeline de dados confiável, testável e observável com forte integração e um fluxo de trabalho de desenvolvimento moderno.

Kedro é uma ferramenta de orquestração de fluxo de trabalho baseada em Python que ajuda a construir projetos de ciência de dados reproduzíveis, manteníveis e modulares. Ela incorpora as melhores práticas de engenharia de software, como modularidade, separação de preocupações e versionamento, em fluxos de trabalho de aprendizado de máquina.
Principais Recursos:
Ideal para:
Cientistas de dados e equipes que desejam fluxos de trabalho de ciência de dados estruturados, de fácil manutenção e reproduzíveis, utilizando as melhores práticas de engenharia de software.
TruEra é uma plataforma focada em melhorar a qualidade de modelos de machine learning através de testes, explicabilidade e análise de causa raiz. Esta ferramenta MLOps ajuda as equipes a depurar modelos, entender problemas de desempenho e garantir a equidade em todo o ciclo de vida do ML.
Principais Recursos:
Ideal para:
Engenheiros de ML, cientistas de dados e organizações que precisam de insights mais aprofundados sobre modelos, verificações de equidade e monitoramento de desempenho confiável em todo o ciclo de vida do modelo.
BentoML é uma plataforma Python-first que simplifica a implantação, o serviço e o monitoramento de modelos de machine learning em produção. Ela ajuda as equipes a lançar aplicativos de ML mais rapidamente com um serviço de modelo escalável e de alto desempenho.
Recursos Principais:
Ideal para:
Engenheiros e equipes de ML que precisam de uma forma rápida, escalável e confiável para implantar e gerenciar modelos de machine learning em ambientes de produção.
Evidently AI é uma biblioteca Python de código aberto para monitorar modelos de machine learning em desenvolvimento, validação e produção. Ajuda a garantir a qualidade dos dados e do modelo, detectando desvios, problemas de desempenho e outros potenciais problemas.
Recursos Principais:
Ideal para:
Cientistas de dados e engenheiros de ML que precisam de monitoramento de modelo confiável, detecção de desvio e rastreamento de desempenho ao longo de todo o ciclo de vida de ML.
DagsHub é uma plataforma de colaboração para projetos de machine learning que ajuda as equipes a rastrear, versionar e gerenciar dados, modelos, experimentos, pipelines e código em um só lugar. Frequentemente descrito como "GitHub para machine learning", ele oferece ferramentas para otimizar o fluxo de trabalho de ML de ponta a ponta.
Principais Recursos:
Ideal Para:
Equipes e organizações de ML que precisam de um ambiente colaborativo e com controle de versão para gerenciar todo o ciclo de vida do machine learning, com forte suporte à integração e reprodutibilidade.

A Plataforma MLOps Iguazio é uma solução completa que automatiza todo o ciclo de vida do machine learning, desde a ingestão e preparação de dados até o treinamento, implantação e monitoramento em produção. Esta ferramenta MLOps oferece tanto um framework de código aberto (MLRun) quanto uma plataforma totalmente gerenciada, com implantação flexível em ambientes de nuvem, híbridos ou on-premises.
Principais Recursos:
Ideal para:
Empresas e setores regulamentados (por exemplo, saúde, finanças) que precisam de uma plataforma MLOps flexível, escalável e governada, com forte automação e controle de implantação.

Qdrant é um banco de dados vetorial de código aberto e pesquisa de similaridade mecanismo que permite armazenar, gerenciar e consultar embeddings vetoriais através de um serviço pronto para produção e uma API simples. Ele é projetado para pesquisa semântica de alto desempenho e aplicações baseadas em IA.
Principais recursos:
Ideal para:
Desenvolvedores e equipes de ML que constroem pesquisa semântica, sistemas de recomendação e aplicações de IA que exigem pesquisa e filtragem de vetores rápidas e escaláveis.

LakeFS é um sistema de controle de versão de dados de código aberto que traz operações semelhantes ao Git para o armazenamento de objetos, permitindo que as equipes gerenciem data lakes com os mesmos fluxos de trabalho usados para código. Ele possibilita o versionamento de dados escalável e confiável para ambientes de dados em larga escala.
Principais Recursos:
Ideal Para:
Engenheiros de dados e organizações que gerenciam grandes data lakes e que precisam de controle de versão confiável, experimentação segura e fluxos de trabalho de dados reproduzíveis em escala.

Fiddler AI é uma plataforma de monitoramento e explicabilidade de modelos que ajuda as equipes a entender, depurar e rastrear modelos de machine learning em produção. Ela fornece insights claros sobre o comportamento do modelo, desempenho e qualidade dos dados por meio de uma interface intuitiva.
Principais Recursos:
Ideal para:
Engenheiros de ML, cientistas de dados e organizações que precisam de monitoramento de modelos transparente, explicabilidade e alertas proativos para manter sistemas de ML de produção confiáveis.
Ray é um framework de computação distribuída que ajuda desenvolvedores a escalar aplicações de IA e Python com facilidade. Ele oferece um ambiente de execução flexível e um conjunto de bibliotecas de IA para construir, treinar e implantar sistemas de aprendizado de máquina em escala.
Principais Recursos:
Ideal para:
Desenvolvedores, engenheiros de ML e equipes de IA que precisam de um framework flexível e de alto desempenho para escalar treinamento, processamento de dados e servir modelos em ambientes distribuídos.
Nuclio é um framework serverless de alto desempenho, projetado para cargas de trabalho intensivas em dados, E/S e computação. Ele permite o processamento em tempo real sem gerenciamento de servidor e se integra bem com ferramentas de ciência de dados e plataformas de ML.
Principais Recursos:
Ideal Para:
Organizações e equipes de ML que precisam de uma plataforma serverless de alto desempenho para processamento de dados em tempo real, streaming e cargas de trabalho de IA escaláveis em ambientes de nuvem e borda.
As melhores ferramentas MLOps ajudam as organizações a gerenciar o ciclo de vida completo do aprendizado de máquina de forma mais eficiente. Elas trazem automação, colaboração e confiabilidade para a construção, implantação e manutenção de sistemas de ML.
As ferramentas MLOps automatizam tarefas repetitivas como preparação de dados, rastreamento de experimentos e orquestração de pipelines. Isso permite que as equipes iterem mais rapidamente, reduzam erros manuais e movam modelos da ideia para a produção com mais agilidade.
Essas ferramentas fornecem espaços de trabalho compartilhados, ativos versionados e documentação clara, facilitando a colaboração de cientistas de dados, engenheiros e partes interessadas, a revisão de mudanças e o compartilhamento de insights entre as equipes.
Com monitoramento, testes e validação integrados, as ferramentas MLOps ajudam a detectar problemas como desvio de dados (data drift), viés e degradação de desempenho. Isso garante que os modelos permaneçam precisos, confiáveis e alinhados com os objetivos de negócios.
As plataformas MLOps rastreiam versões de dados, código, modelos e experimentos, permitindo que as equipes reproduzam resultados, auditem alterações e mantenham a consistência entre os ambientes.
Elas simplificam a implantação de modelos em produção através de automação, pipelines de CI/CD e infraestrutura escalável, permitindo que as organizações lidem com cargas de trabalho crescentes e se adaptem às demandas em constante mudança de forma eficiente.
MLOps evoluiu de uma prática de nicho para um componente fundamental dos fluxos de trabalho modernos de aprendizado de máquina. Em 2026, as organizações já não perguntam se precisam de MLOps, elas perguntam qual plataforma melhor se alinha com seus objetivos, infraestrutura e escala.
Como vimos, o cenário oferece desde ferramentas leves e modulares como MLflow e DVC até soluções empresariais totalmente gerenciadas como Azure ML, Vertex AI e SageMaker.
Para equipes focadas em GenAI, ajuste fino e inferência em tempo real, plataformas mais recentes como TrueFoundry oferecem recursos de ponta construídos para os desafios modernos da IA.
Operacionalize suas cargas de trabalho de ML e GenAI mais rapidamente. Agende uma demonstração com a TrueFoundry para começar.
MLOps não é melhor que DevOps; é uma extensão do DevOps adaptada para aprendizado de máquina. Enquanto o DevOps se concentra na entrega de software e automação de infraestrutura, o MLOps adiciona recursos para gerenciamento de dados, rastreamento de experimentos, monitoramento de modelos e reprodutibilidade, abordando os desafios únicos de construir, implantar e manter sistemas de ML em produção.
As melhores ferramentas MLOps para empresas são aquelas que equilibram a velocidade do desenvolvedor com uma governança de infraestrutura rigorosa. Embora grandes provedores de nuvem ofereçam serviços amplos, a TrueFoundry é frequentemente a escolha ideal para equipes que exigem soberania de dados e flexibilidade multi-nuvem. Ela fornece um plano de controle unificado que é executado nativamente dentro da sua VPC privada, permitindo automatizar todo o ciclo de vida, do treinamento à implantação, sem comprometer a segurança ou o controle da infraestrutura.
Docker é uma tecnologia fundamental para a conteinerização, tornando-o uma peça crítica da pilha de ferramentas MLOps. Ele garante que os modelos sejam executados de forma consistente em ambientes de desenvolvimento e produção, embora não gerencie tarefas de nível superior como monitoramento de modelos ou versionamento. A TrueFoundry simplifica o processo de conteinerização ao construir automaticamente imagens Docker e orquestrá-las no Kubernetes, permitindo que cientistas de dados implantem código sem precisar se tornar especialistas em DevOps.
A TrueFoundry funciona como uma camada de abstração centrada no desenvolvedor que se sobrepõe à sua infraestrutura de nuvem existente. Ela se conecta diretamente aos seus clusters Kubernetes e automatiza tarefas complexas como provisionamento de recursos, CI/CD e serviço de modelos. Ao fornecer uma única interface para gerenciar experimentos e cargas de trabalho de produção, ela reduz os tempos de implantação de semanas para minutos ao mesmo tempo em que reduz os custos através da otimização automatizada de GPU e suporte a instâncias spot.
Não há uma única nuvem que seja a melhor para MLOps; a escolha certa depende das suas necessidades, ferramentas e orçamento. AWS, Azure e Google Cloud oferecem serviços MLOps robustos, incluindo pipelines automatizados, treinamento escalável e monitoramento de modelos. As equipes geralmente escolhem com base na infraestrutura existente, requisitos de conformidade e integração com seu ecossistema de dados.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




