




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Ajuste fino é uma técnica utilizada em aprendizado de máquina, especialmente em aprendizado profundo, onde um modelo pré-treinado é treinado ou "ajustado" adicionalmente em um conjunto de dados menor e específico, adaptado a uma tarefa particular.
Suponha que você esteja desenvolvendo um modelo que gera manuais técnicos para eletrônicos usando GPT-3 (um modelo de linguagem grande com 175 bilhões de parâmetros), mas a saída genérica do GPT-3 não está atendendo à precisão técnica e ao tom exigidos.
Neste caso, você pode pensar em retreinar o modelo para o seu caso de uso específico, mas treinar diretamente um modelo como o GPT-3 do zero para abordar esta tarefa de nicho é impraticável devido à exigência de recursos computacionais e dados especializados.
É aqui que o ajuste fino entra em jogo.
O ajuste fino é como ensinar um truque novo ao GPT-3. Ele já sabe muito sobre linguagens graças ao seu treinamento em inúmeros textos, de livros a websites. Seu trabalho é treiná-lo adicionalmente em um conjunto de dados direcionado — neste caso, um corpus de manuais técnicos e documentação existentes específicos para eletrônicos.
Alguns métodos básicos de ajuste fino:
Ajuste Fino Eficiente em Parâmetros (PEFT) é uma técnica que visa minimizar o número de parâmetros adicionais necessários durante o ajuste fino de modelos de redes neurais pré-treinados,
Isso ajuda a reduzir os custos computacionais e o uso de memória, enquanto ainda mantém ou até melhora o desempenho. O PEFT consegue isso adicionando embeddings de prompt como parâmetros extras do modelo e ajustando apenas um pequeno número de parâmetros extras.
O PEFT também requer um conjunto de dados muito menor em comparação com o ajuste fino tradicional.
Carregue o modelo escolhido usando um framework de aprendizado de máquina como TensorFlow, PyTorch ou a biblioteca Transformers da Hugging Face. Esses frameworks fornecem APIs para baixar e carregar modelos pré-treinados facilmente.
Aqui está um exemplo de código:
Antes do ajuste fino, você deve experimentar diferentes prompts para guiar as respostas do modelo. Teste vários prompts com o modelo pré-treinado para ver como eles afetam a saída e escolha o mais apropriado. Você também pode alterar diferentes parâmetros como max_length, temperature, etc.
É como descobrir a melhor forma de fazer sua pergunta para que o modelo entenda o que você quer.
Em um conjunto de dados para ajuste fino, existem tipicamente duas partes: Prompt (Entrada) e Resposta (Saída). O Prompt é como uma pergunta ou um ponto de partida, e a Resposta é o que você deseja que o modelo gere em resposta a essa pergunta. Pode ser na forma de colunas ou uma sequência de entradas de texto (mais comum).
O melhor prompt identificado na etapa anterior será usado aqui e a Resposta será exatamente o que queremos que o modelo produza quando receber esse Prompt.
É aqui que você ensina o modelo a melhorar em sua tarefa. Você usará o conjunto de dados para ajustar ligeiramente o “conhecimento” do modelo.
Aqui está uma visão geral simplificada de como configurar e executar o processo de ajuste fino com PyTorch:
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5) # lr é a taxa de aprendizado
Ao explorar ferramentas para engenharia de prompts, é útil categorizá-las em dois domínios principais: Plataformas de Código e Plataformas No-Code. Essa distinção simplifica o processo de seleção
Plataformas de Código referem-se a plataformas que fornecem máquinas virtuais que podem ser usadas para executar seu script Python personalizado para ajuste fino, como o mencionado anteriormente. Enquanto isso, Plataformas No-Code referem-se a ferramentas que exigem um script Python simples ou nenhum script para funcionar. Elas possuem uma interface de usuário dedicada onde você pode iniciar o treinamento com apenas alguns cliques.
Plataformas no-code, por outro lado, são projetadas para simplicidade e facilidade de uso. Elas eliminam a necessidade de escrever scripts Python, oferecendo uma interface de usuário intuitiva onde o treinamento pode ser iniciado com apenas alguns cliques. Este domínio é adequado para usuários sem conhecimento de programação ou para aqueles que preferem uma abordagem direta à engenharia de prompts.
TrueFoundry é uma ferramenta que ajuda as equipes de ML a colocar seus modelos em funcionamento sem problemas. É construída sobre Kubernetes, o que significa que pode ser executada em diferentes nuvens ou até mesmo em seus próprios servidores. Isso é importante para empresas preocupadas em manter seus dados seguros e controlar custos
Para o ajuste fino (fine-tuning), é uma das melhores ferramentas disponíveis, atendendo tanto a iniciantes quanto a especialistas. Aqui você tem duas opções: implantar um notebook de ajuste fino para experimentação ou iniciar um trabalho de ajuste fino dedicado.
Notebooks oferecem uma configuração ideal para ajuste fino exploratório e iterativo. Você pode experimentar em um pequeno subconjunto de dados, testando diferentes hiperparâmetros para descobrir a configuração ideal para o melhor desempenho.
Depois de identificar os hiperparâmetros e a configuração ideais por meio da experimentação, a transição para um trabalho de implantação ajuda a realizar o ajuste fino em todo o conjunto de dados e facilita um treinamento rápido e confiável.
Portanto, notebooks são fortemente recomendados para exploração inicial e ajuste de hiperparâmetros, e os trabalhos de implantação são a escolha preferida para o ajuste fino de LLMs em larga escala, especialmente quando a configuração ideal foi estabelecida por meio de experimentação prévia.
Aqui está um guia passo a passo para realizar o ajuste fino usando Notebook e Trabalhos:
Truefoundry suporta dois formatos de dados diferentes:
Cada linha contém uma chave chamada messages. Cada chave de mensagem contém uma lista de mensagens, onde cada mensagem é um dicionário com as chaves role e content. A chave role pode ser user, assistant ou system, e a chave content contém o conteúdo da mensagem.
2. Ajuste Fino
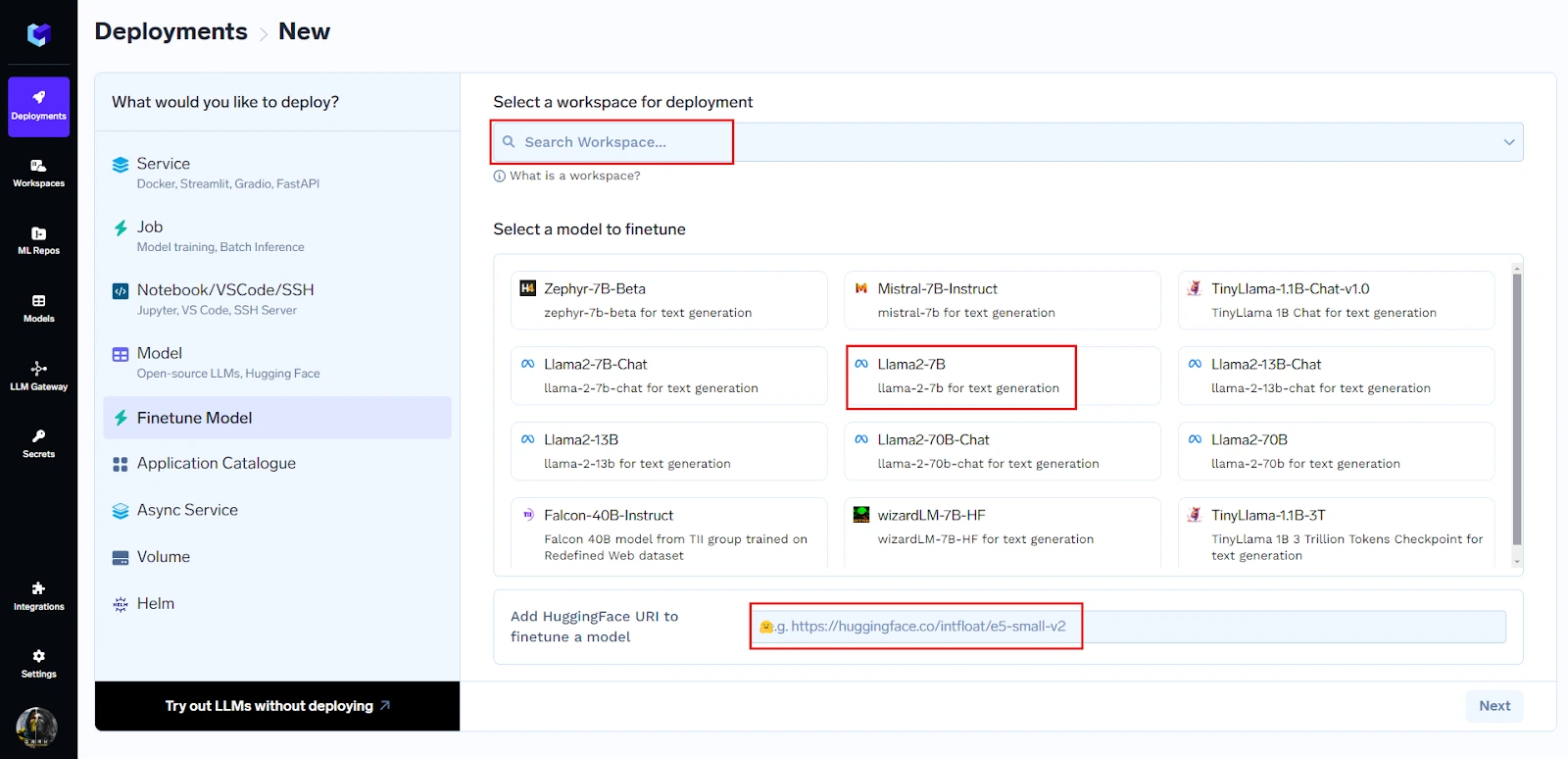
Você pode iniciar o ajuste fino com apenas três cliques:
Você pode escolher um modelo da lista abrangente disponível ou simplesmente colar o URL do Hugging Face para iniciar o ajuste fino.
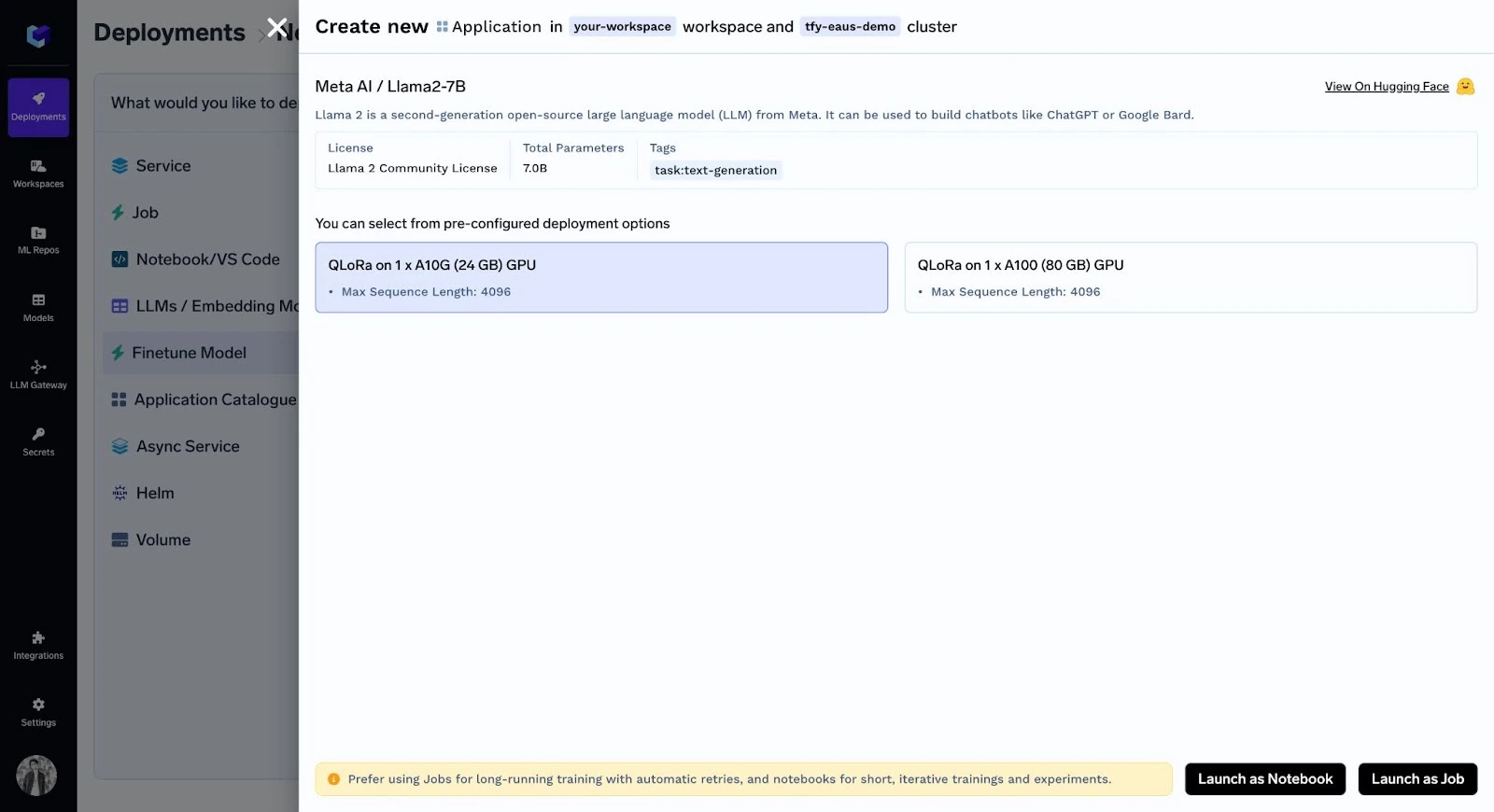
Agora, após selecionar a GPU desejada, você tem duas opções: Executar como notebook ou como Job.
3. Ajuste Fino usando um Notebook
Após escolher ‘Launch as Notebook’ e selecionar os valores padrão para os hiperparâmetros, você pode ver seu notebook:

4. Ajuste Fino como Job:
Antes de começar, você precisará primeiro criar um ML Repo (este será usado para armazenar suas métricas de treinamento e artefatos, como seus checkpoints e modelos) e conceder acesso ao seu workspace ao ML Repo. Você pode ler mais sobre Repositórios ML na documentação da Truefoundry.
Agora você deve escolher ‘Launch as Job’ e selecionar os valores padrão dos hiperparâmetros para iniciar o ajuste fino.
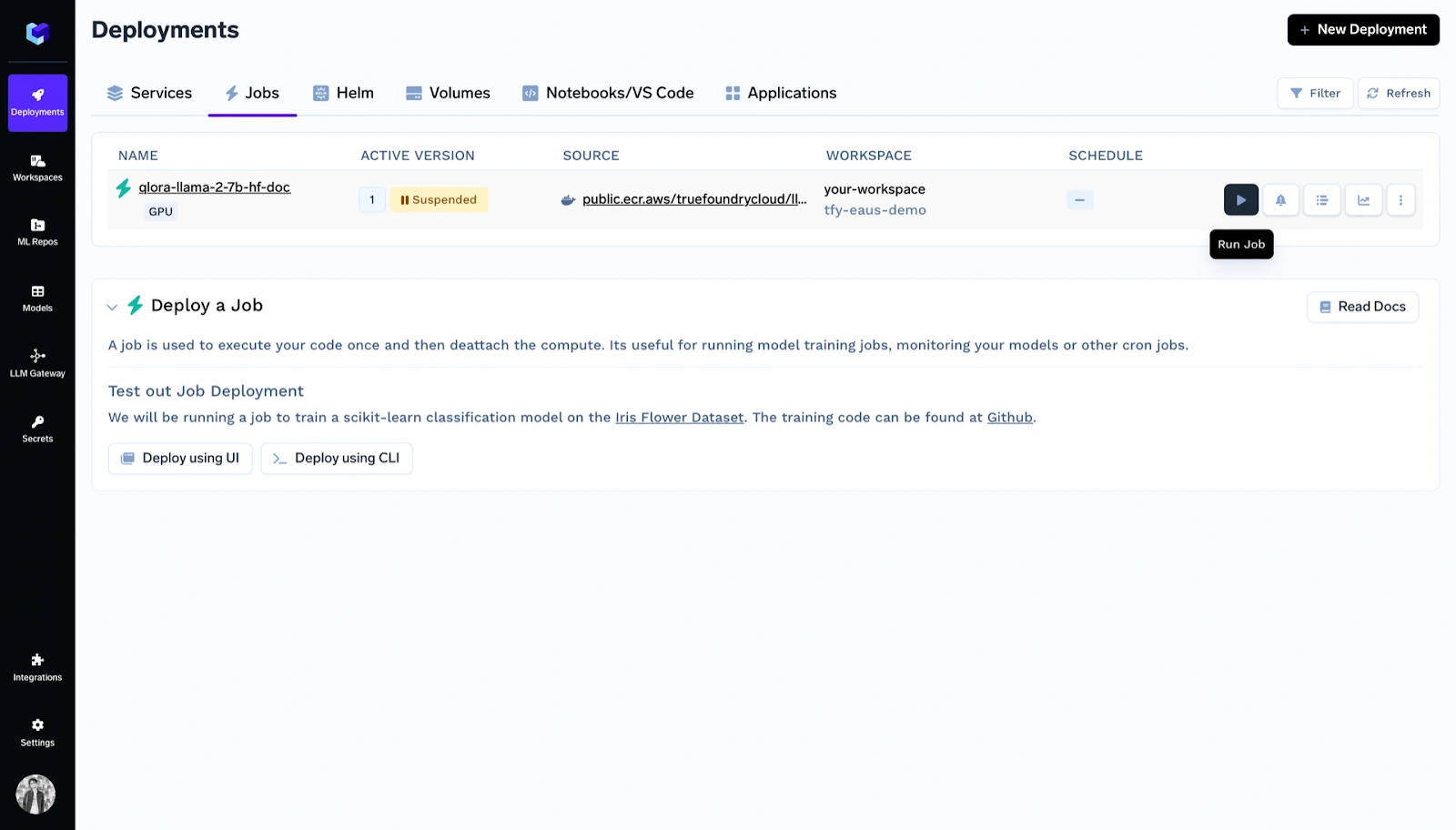
Dentro dos deployments você pode ver o job listado e clicar em 'run job'.
Principais Recursos:
A API da OpenAI fornece acesso a modelos avançados de inteligência artificial desenvolvidos pela OpenAI, incluindo as versões mais recentes do GPT (Generative Pre-trained Transformer). Uma das características marcantes da API da OpenAI é sua capacidade de ajustar modelos em conjuntos de dados personalizados.
Assim, você pode adaptar o comportamento de modelos como o GPT-3 ou versões mais recentes para aplicações específicas ou para aderir a estilos e preferências de conteúdo particulares.
Como estou me referindo à API, não é exatamente "No-Code", mas ainda assim é fácil configurá-la para treinamento em comparação com outras ferramentas da seção anterior.
Exemplo de Código para Fine-Tuning:
Para fazer o fine-tuning de um modelo, você primeiro precisa preparar seu conjunto de dados em um formato que a API da OpenAI possa entender. Tipicamente, você teria que criar um arquivo JSON que se parece com isto:
Você pode facilmente carregar o conjunto de dados usando a CLI (Interface de Linha de Comando) da OpenAI.
openai tools fine_tunes.prepare_data -f your_dataset.jsonl
Uma vez que seu conjunto de dados esteja preparado e carregado, você pode iniciar um processo de fine-tuning. O seguinte é um exemplo usando a biblioteca Python da OpenAI:
Após a conclusão do processo de fine-tuning, você pode usar seu modelo com fine-tuning para gerar texto ou outras tarefas, especificando o ID do modelo com fine-tuning:
Você também pode implantar seu modelo com fine-tuning.
Principais Recursos:
Microsoft Azure é uma plataforma de computação em nuvem que oferece uma ampla gama de serviços, incluindo computação, armazenamento, análise e muito mais. Ela fornece aos usuários as ferramentas para construir, implantar e gerenciar aplicativos de forma eficiente.
Uma característica notável é sua interface intuitiva, facilitando a navegação para iniciantes sem a necessidade de conhecimento aprofundado em codificação. Com simples cliques, em vez de codificação complexa, os usuários podem ajustar suas aplicações, tornando o Azure uma ferramenta acessível para um desenvolvimento sem estresse.
Aqui está um guia simples sobre como configurar uma tarefa de ajuste fino no Azure:
Obviamente, este é o requisito básico para todas as ferramentas. Os dados de treinamento podem estar no formato JSON Lines (JSONL), CSV ou TSV. Os requisitos dos seus dados variam com base na tarefa específica para a qual você pretende ajustar seu modelo.
Para classificação de texto:
Duas colunas: Frase (string) e Rótulo (inteiro/string)
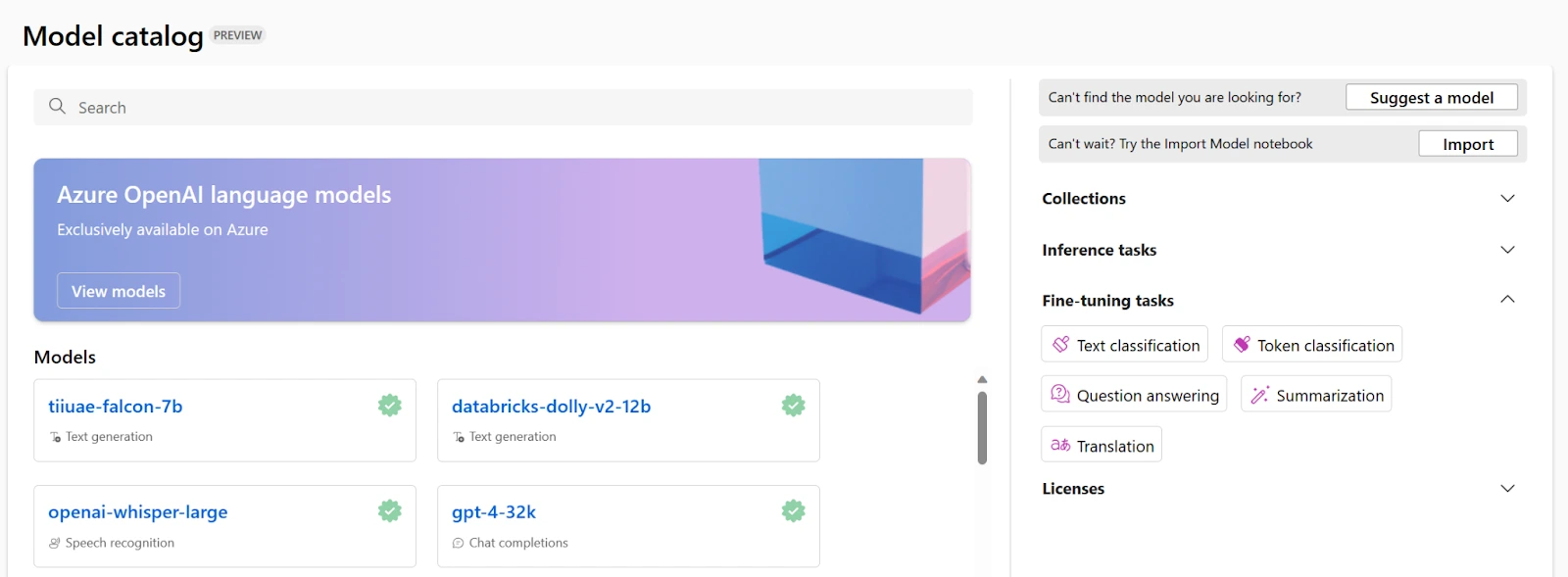
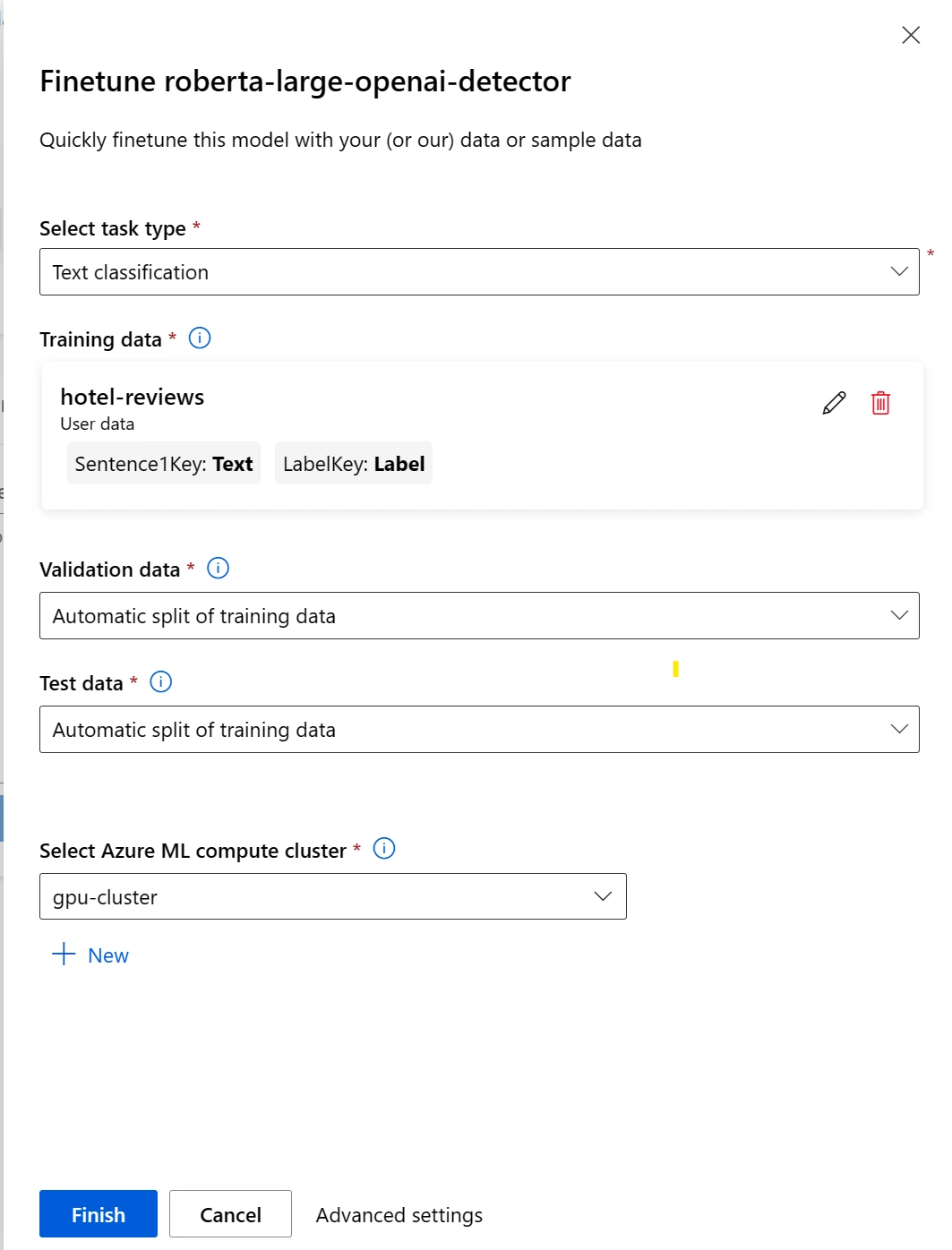
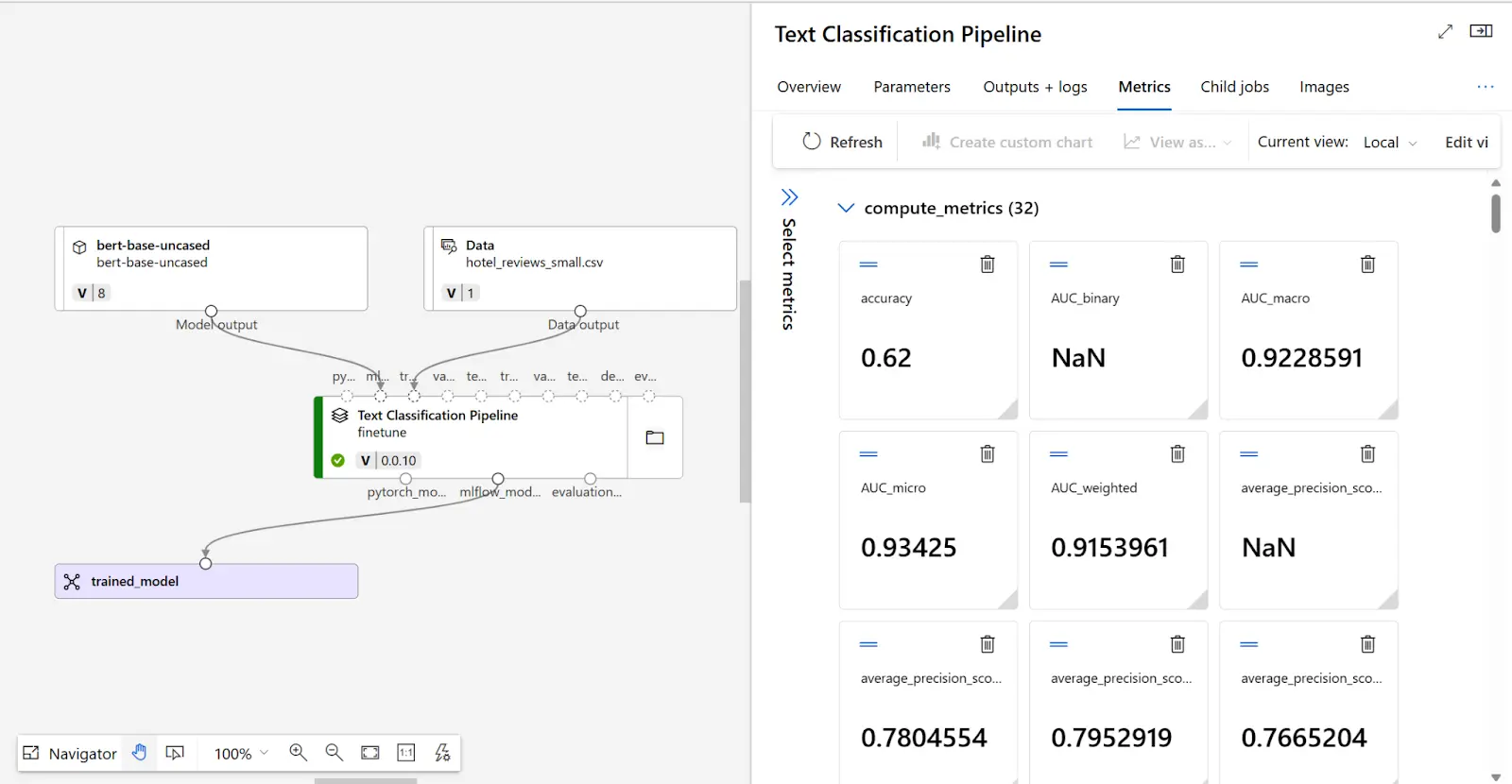
Após enviar a tarefa de ajuste fino, um trabalho de pipeline será criado para treinar seu modelo. Você pode revisar todas as entradas e coletar o modelo a partir das saídas do trabalho.
Para decidir se o seu modelo ajustado tem o desempenho esperado, você pode revisar as métricas de treinamento e avaliação.
Principais Recursos:
Replicate é uma ferramenta versátil projetada para o ajuste fino de vários aspectos de aplicações de software. As aplicações do Replicate como ferramenta de ajuste fino incluem otimização de desempenho, ajuste de configurações e aprimoramento de funcionalidades com esforço mínimo. Ele simplifica o processo ao lidar com a configuração da GPU. Semelhante à API da OpenAI, não é exatamente "Sem Código" como outras ferramentas da lista, mas ainda assim é fácil configurá-lo para treinamento em comparação com outras ferramentas da seção anterior.
Os seus dados de treino precisam estar no formato JSONL. Abaixo, encontra-se um exemplo de como poderá estruturar este ficheiro:
Precisa de definir o seu token de API do Replicate como uma variável de ambiente no seu terminal:
export REPLICATE_API_TOKEN=<your-token-here>
Pode carregar os seus dados para um bucket s3 ou diretamente no Replicate usando comandos curl:
Precisa de criar um modelo vazio no Replicate para o seu modelo treinado. Quando o seu treino terminar, este será enviado como uma nova versão para este modelo.
Precisa de criar um Trabalho de treino na sua IDE, como mostrado abaixo:
Para monitorizar o progresso programaticamente, pode usar:
Após a conclusão do treino, pode executar o seu modelo com a API:
Principais Funcionalidades:
No Gen AI Studio, você tem ambas as opções para configurar trabalhos de ajuste fino, via API ou pelo site; aqui, falarei apenas sobre o método da API. Ele possui o processo mais simplificado em comparação com as ferramentas discutidas anteriormente.
Seu conjunto de dados deve estar no formato JSONL, com cada linha sendo um objeto JSON com as chaves "input_text" e "output_text". Ele pode começar o treinamento com apenas 10 exemplos, mas pelo menos 100 exemplos são recomendados.
Você deve fazer o upload do seu conjunto de dados para um bucket do Google Cloud Storage (GCS); se não tiver um, pode criar um no Google Drive.
Agora você precisa fornecer suas credenciais para estabelecer a conexão:
Você precisa definir uma função para o ajuste com os parâmetros necessários.
Chame a função de ajuste especificada anteriormente, com seus parâmetros específicos. O parâmetro training_data pode ser um URI do GCS ou um pandas DataFrame.
Principais Recursos:
Predibase é uma plataforma especializada projetada para facilitar o ajuste fino de grandes modelos de linguagem (LLMs), como o GPT-4, para tarefas ou aplicações específicas. Ela oferece acesso às capacidades avançadas dos LLMs, fornecendo um ambiente simplificado e fácil de usar para personalizar esses modelos de acordo com as necessidades individuais.
O Predibase oferece a opção de usar tanto o SDK Python quanto a interface de usuário (UI) para realizar trabalhos de ajuste fino.
Aqui está um guia passo a passo para ajustar o mistral-7b-instruct:
Primeiro, crie uma conta no Predibase e faça um depósito para adicionar créditos. Em seguida, gere sua Chave de API.
Vá para Modelos e clique em “Novo Repositório de Modelos”, conforme mostrado abaixo:
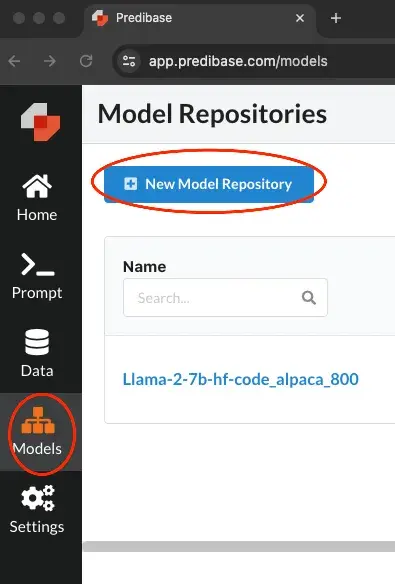
Agora, nomeie seu repositório e adicione uma descrição.
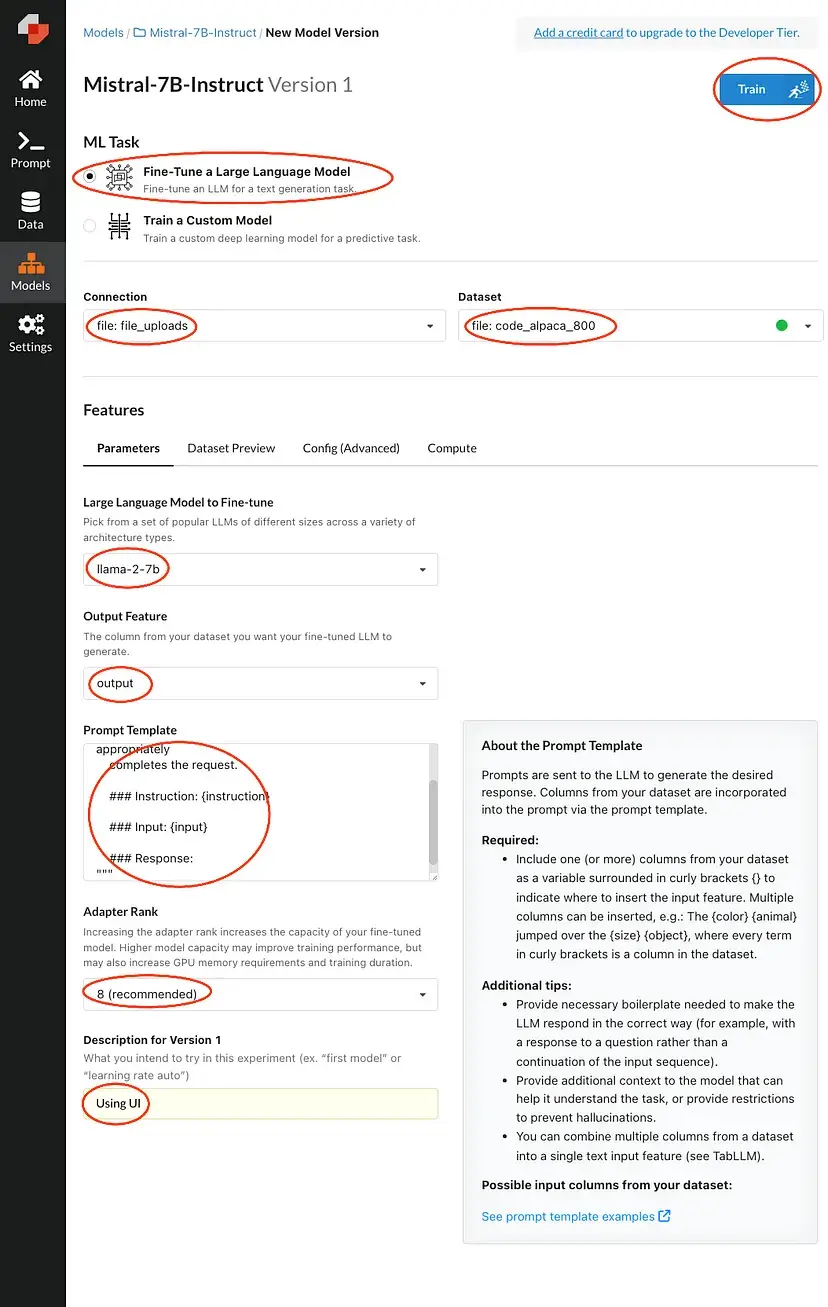
Preencha as áreas destacadas e depois clique em treinar. Isso colocará sua solicitação na fila até que haja um recurso de computação disponível.
As Plataformas de Código são projetadas para usuários com uma sólida formação em programação. Essas plataformas fornecem máquinas virtuais que permitem a execução de scripts Python personalizados para tarefas como ajuste fino. Essas plataformas são perfeitas para projetos que exigem alta personalização e controle intrincado sobre as fases de treinamento e implantação.
Amazon SageMaker é um serviço totalmente gerenciado que oferece a desenvolvedores e cientistas de dados a capacidade de construir, treinar e implantar modelos de aprendizado de máquina rapidamente.
O Amazon SageMaker não possui um recurso de "ajuste fino" dedicado e integrado, especificamente rotulado como tal para grandes modelos de linguagem. Em vez disso, ele oferece uma plataforma poderosa e flexível que permite executar scripts Python personalizados para realizar tarefas de ajuste fino.
Aqui está um exemplo simples de como você pode iniciar um trabalho de ajuste fino para um modelo de linguagem com Hugging Face no SageMaker. Isso pressupõe que você já configurou uma conta AWS e o AWS CLI. (você pode usar TensorFlow ou PyTorch diretamente no Amazon SageMaker para tarefas de ajuste fino)
Normalmente, você escreveria um script de ajuste fino (train.py) que você passa para o estimador. Este script deve incluir sua lógica de carregamento, ajuste fino e salvamento do modelo.
Principais Recursos:
O Google Colab é um serviço popular de notebook Jupyter baseado em nuvem que oferece acesso gratuito a recursos de computação, incluindo GPUs e TPUs, tornando-o uma excelente plataforma para o ajuste fino de grandes modelos de linguagem (LLMs)
É particularmente amigável para iniciantes. Os notebooks do Colab são executados na nuvem, diretamente do seu navegador, sem exigir nenhuma configuração local.
Aqui está o trecho de código simples para ajustar um Modelo Transformer com Hugging Face Transformers e PyTorch no Google Colab
!pip install torch torchvision transformers
model.save_pretrained("/content/drive/My Drive/Colab Models/my_finetuned_model")
Principais Recursos:
Paperspace Gradient é um conjunto de ferramentas projetado para simplificar o processo de desenvolvimento, treinamento e implantação de modelos de aprendizado de máquina na nuvem.
O Gradient é particularmente eficaz para tarefas como o ajuste fino de grandes modelos de linguagem (LLMs) devido à sua infraestrutura escalável e suporte a contêineres, tornando-o uma excelente escolha para cientistas de dados e profissionais de ML.
Aqui está um exemplo de ajuste fino de um Modelo Transformer com PyTorch no Paperspace Gradient.
model.save_pretrained("./my_finetuned_model")
Principais Recursos:
Run.AI é uma plataforma projetada para otimizar os recursos de GPU para cargas de trabalho de aprendizado de máquina, facilitando para cientistas de dados e pesquisadores de IA executar e gerenciar modelos de IA complexos, incluindo o ajuste fino de grandes modelos de linguagem (LLMs).
É baseado em Kubernetes, uma ferramenta que organiza os recursos computacionais de forma eficiente. Assim, facilita a execução de projetos complexos de IA e permite que as equipes desenvolvam seus projetos sem problemas.
Você pode consultar a documentação do Run.AI para obter informações detalhadas, aqui está um exemplo simplificado baseado no fluxo de trabalho geral para o ajuste fino de um modelo como o LLaMA-2 na plataforma Run.AI.
runai submit my-fine-tuning-job -p my-project --gpu 2 --image my-llama2-fine-tuning-image train.py
Seu script train.py deve incluir a lógica para carregar o LLaMA-2 (ou o modelo escolhido), seu conjunto de dados e executar o processo de ajuste fino. Isso pode envolver o uso de bibliotecas como Hugging Face Transformers para carregamento de modelos e TensorFlow ou PyTorch para o loop de treinamento.
from transformers import LlamaForConditionalGeneration, LlamaTokenizer
O Run.AI oferece ferramentas para monitorar o uso da GPU, o progresso dos seus trabalhos de treinamento e gerenciar os recursos computacionais de forma eficaz. Use o painel ou a CLI do Run.AI para acompanhar o status e o desempenho do seu trabalho.
runai list jobs
Este comando lista todos os trabalhos atuais, permitindo que você monitore o progresso e o uso de recursos da sua tarefa de ajuste fino.
Principais Recursos:
Escolhendo a Ferramenta Certa para Você:
Facilidade de Uso: Escolha ferramentas que sejam diretas, especialmente se você não é muito fã de codificação. Algumas ferramentas nem sequer exigem que você escreva código!
Escalabilidade: Garantir que a ferramenta possa crescer com o seu projeto, lidando com conjuntos de dados maiores e modelos mais complexos de forma fluida.
Suporte a Modelos e Conjuntos de Dados: Escolha ferramentas que funcionem bem com os tipos específicos de dados e modelos que você está usando.
Recursos Computacionais: Procure acesso a GPUs ou TPUs se o seu projeto precisar de grande poder computacional.
Custo: Considere quanto você está disposto a gastar. Algumas ferramentas são gratuitas; outras cobram com base nos recursos que você utiliza.
Personalização e Controle: Se você domina a programação, pode preferir ferramentas que permitem ajustar tudo.
Integração: É mais fácil se a ferramenta se integrar perfeitamente ao seu fluxo de trabalho e ferramentas existentes.
Comunidade e Suporte: Uma comunidade de apoio e uma boa documentação podem poupar-lhe muitas dores de cabeça.
As principais ferramentas de fine-tuning incluem Hugging Face para acesso a modelos, SiliconFlow para treinamento baseado em nuvem e TrueFoundry para orquestração de nível empresarial. Bibliotecas de código aberto como Axolotl e LLaMA-Factory também suportam técnicas avançadas como LoRA. A TrueFoundry unifica de forma única o acesso a modelos, o rastreamento de experimentos e a governança de implantação em uma única plataforma segura.
Os custos de fine-tuning na nuvem dependem das horas de computação da GPU, do tamanho do modelo e dos requisitos de armazenamento. Treinar um modelo de 7B parâmetros geralmente custa entre US$ 100 e US$ 400, enquanto modelos de 70B podem exceder US$ 10.000. O uso de métodos eficientes em parâmetros como QLoRA reduz significativamente essas despesas para aproximadamente US$ 50 a US$ 300 por execução de treinamento.
As ferramentas de fine-tuning PEFT utilizam técnicas como LoRA para ajustar apenas uma pequena fração dos parâmetros de um modelo. Isso reduz os requisitos de memória da GPU, permitindo que as equipes treinem modelos massivos em hardware de consumo ou em uma única GPU. Essas ferramentas aceleram as velocidades de treinamento, ao mesmo tempo em que oferecem uma precisão comparável ao retreinamento completo do modelo.
As ferramentas de fine-tuning retreinam modelos em conjuntos de dados especializados, ajustando parâmetros para melhorar o desempenho em tarefas específicas de domínio. A engenharia de prompt modifica o texto de entrada para guiar as saídas sem alterar os pesos internos do modelo. Embora a engenharia de prompt seja mais rápida, o fine-tuning oferece um controle mais profundo e precisão superior para casos de uso empresariais complexos.
O TrueFoundry simplifica o fine-tuning ao fornecer uma interface unificada para integração de dados, rastreamento de experimentos e implantação de modelos. Os usuários carregam dados proprietários e lançam trabalhos de fine-tuning em infraestrutura otimizada, utilizando backends de alto desempenho. Assim que o treinamento é concluído, as equipes podem implantar checkpoints atualizados diretamente para produção com um único clique.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)




%20(11).webp)

.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




