














November 5, 2025
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
TrueFoundryが、大規模言語モデル(LLM)のデプロイとファインチューニングのための、強力かつ使いやすいソリューションを開発したことをご紹介できることを大変嬉しく思います。 モデルカタログ。私たちは、企業がKubernetes上でオープンソースLLMをセルフホストできるよう支援し、ワンクリックで推論コストを10分の1にすることを目指しています。このブログでは、 Dolly-v2-3b モデルをデプロイし、 Pythia-70M モデルをTrueFoundryでファインチューニングする方法をご紹介します。TrueFoundryプラットフォーム は、ロジスティック回帰のような最もシンプルなものから、Stable Diffusionのような最先端のモデルまで、あらゆる種類の機械学習および深層学習モデルをサポートするように設計されています。大規模言語モデルに関しては、なぜ新しいものを構築する必要があるのか、と疑問に思うかもしれません。
これらのモデルの途方もないサイズと複雑さは、実世界のアプリケーションにデプロイする際に大きな課題となります。TrueFoundryプラットフォームはすでにあらゆるサイズのモデルを大規模にデプロイすることをサポートしていましたが、これらのモデルに対してさらに最適化(コストと時間)とユーザーエクスペリエンスの改善ができることに気づきました。
ChatGPTのような大規模言語モデル(LLM)は、人工知能の分野で間違いなく大きな話題を呼んでいます。
しかし、すでに本番環境での導入を開始している50社以上の企業と話した結果、LLMがすでに生み出している価値は計り知れません。私たちは、人々が日々新しいユースケースを発見するにつれて、LLMの利用は拡大する一方だと考えています。
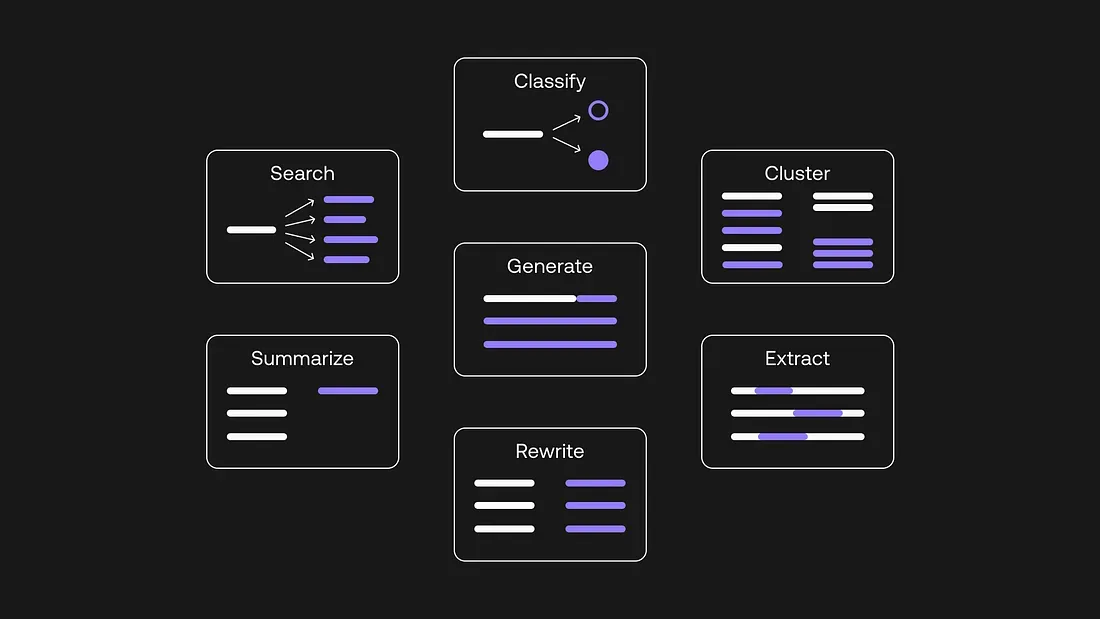
大規模言語モデルとOpenAI APIを使って概念実証(PoC)のユースケースを作成するのは簡単ですが、本番環境への導入🚀を考え始めると、さらに多くの考慮事項が必要になります。
ほとんどの企業にとって、LLMを確実に提供するための複雑なGPUインフラを扱うエンジニアリング能力を構築することは、困難で時間のかかる作業です。さらに、ほとんどの企業は、それぞれのユースケースに最適な特定のモデルを求めており、そのためにはこれらのモデルをファインチューニングする必要があります。これは技術的に困難であると同時に、費用のかかることでもあります。
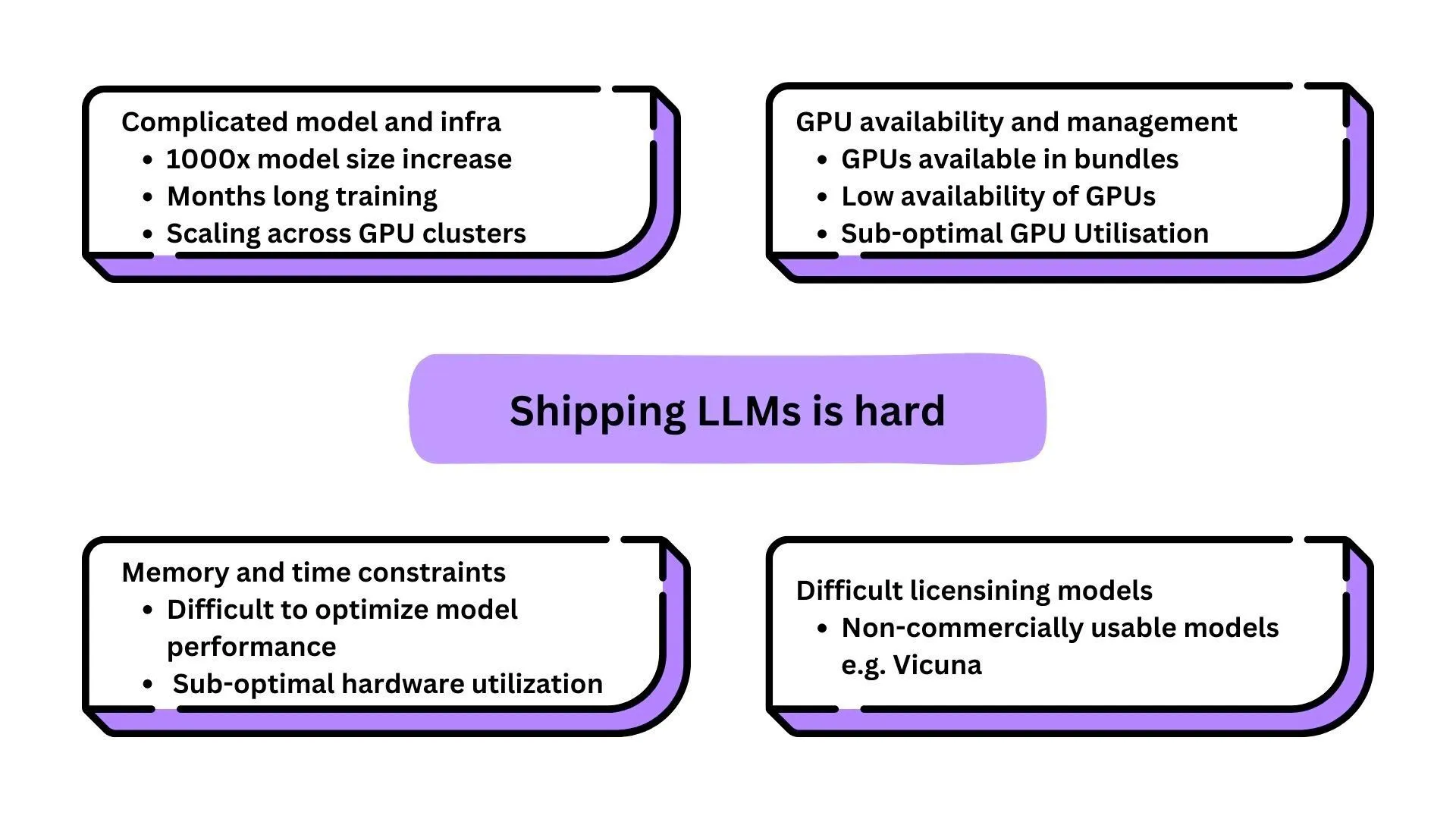
LLMの未来について、私たちはオープンソースモデルが今後の主流になると考えています。このトピックに関する私たちの見解については、さらに詳しく こちら。私たちは、急速に進化するイノベーターコミュニティの力を活用し、企業が組織内でこれらのオープンソースLLMの価値を最大限に活用できるよう支援することにしました。
TrueFoundryは、特定のユースケースに合わせてファインチューニングされたオープンソースLLMが、パートナー企業の組織にもたらすことができる最大限のメリットを享受できるよう願っています。
しかし、自社のインフラでオープンソースモデルを管理・展開するのは容易ではありません。一方、 オンプレミスLLMの展開 は、比類のないデータ制御、コンプライアンス対応、長期的なコスト効率を提供しますが、GPUオーケストレーション、Kubernetes管理、モデル最適化に関する深い専門知識が必要です。
しかし、データを取り込んで数回クリックするだけで、それが実現できるとしたらどうでしょう?
私たちは、企業がLLMの概念実証(PoC)から本番環境への移行で直面する課題を理解しています。私たちは、このプロセスをパートナー企業にとって非常に簡単にするレイヤーを構築することを目指しています。その方法をご紹介します。
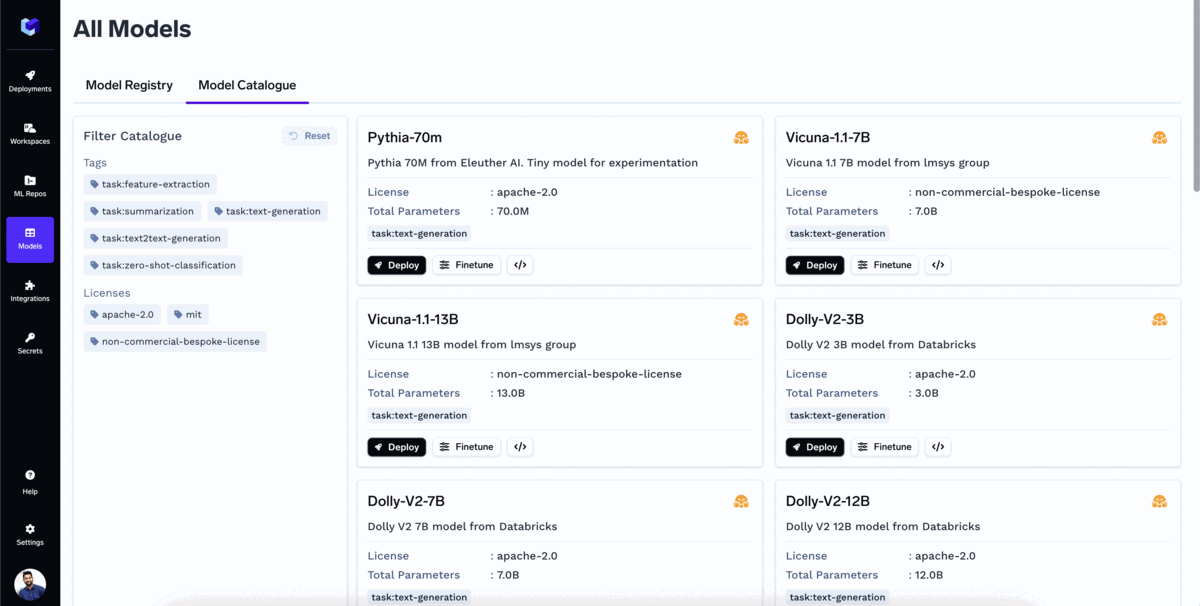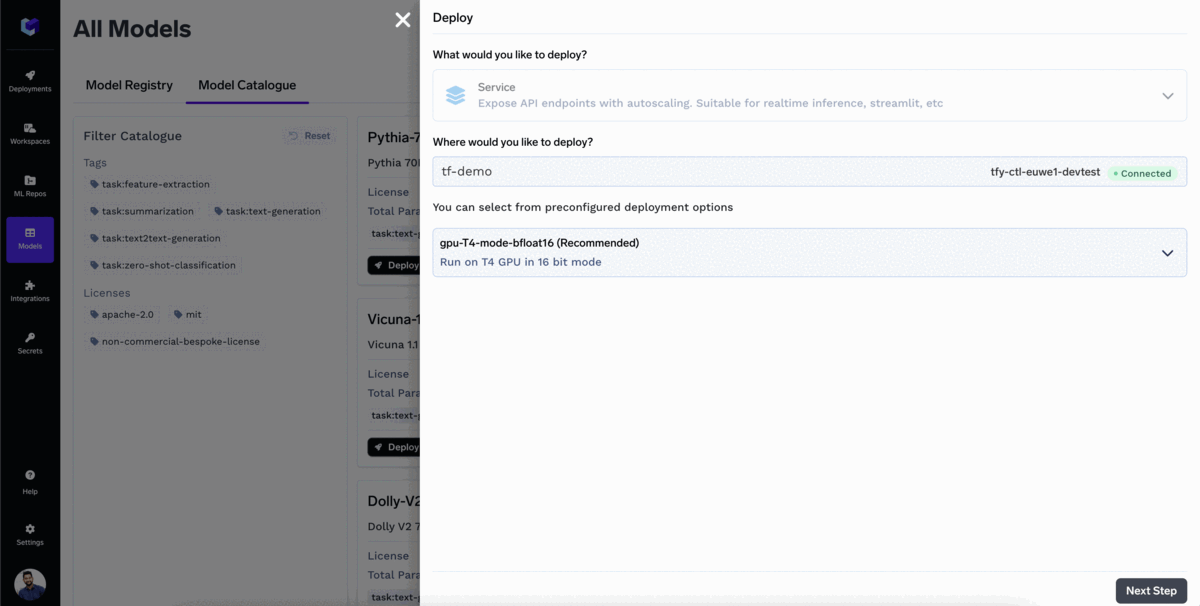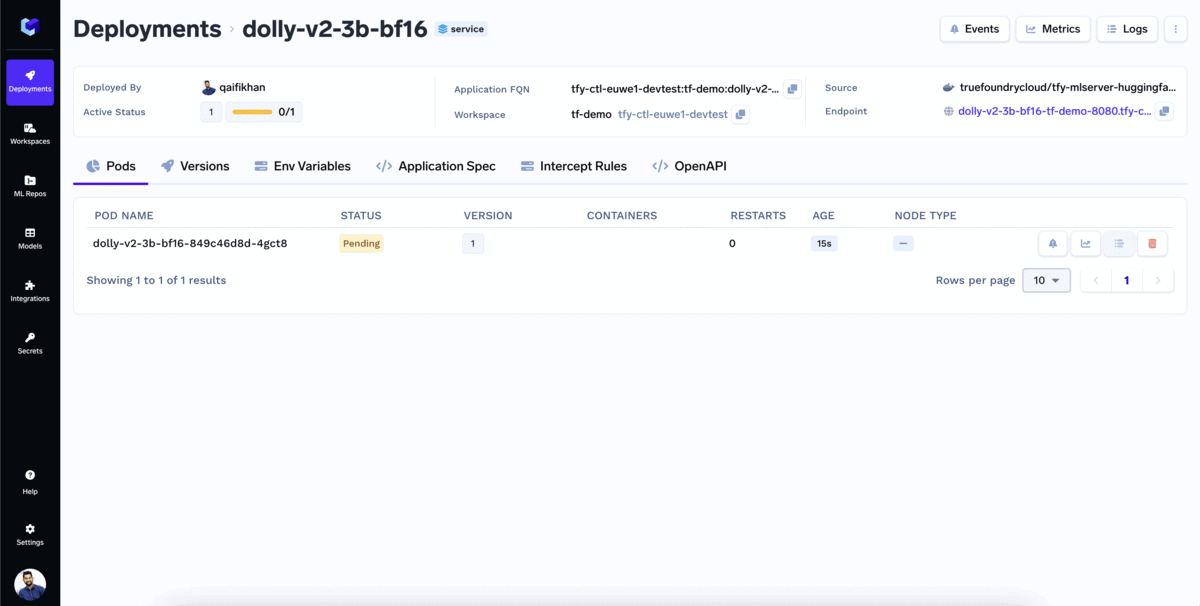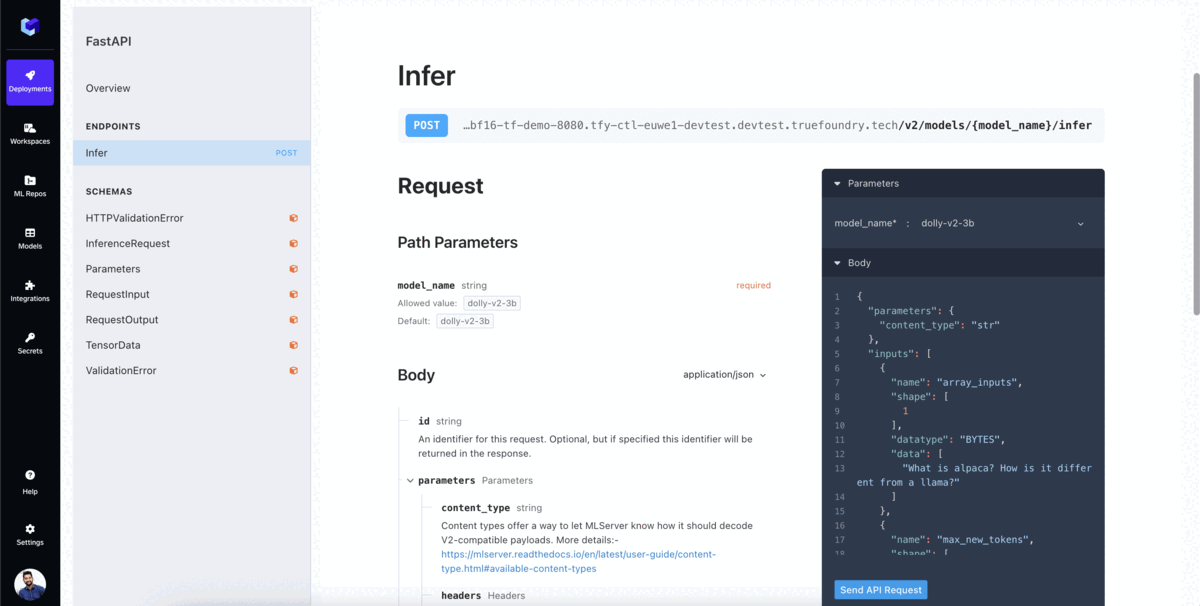
TrueFoundryの モデルカタログ は、ワンクリックでデプロイできる人気のオープンソース大規模言語モデル(LLM)の集積所です。ユーザーはモデルカタログから直接モデルをファインチューニングすることもできます。
この カタログ は、ほとんどの人気モデルをすでにサポートしており、毎日さらに多くのモデルのサポートを追加しています。お客様自身のクラウドにすでにデプロイできる人気モデルの一部をご紹介します:
その他多数.....
企業が初日から製品を出荷できることにこだわっています。これを可能にするために、私たちがLLM機能構築の基盤としている原則をご紹介します:
ℹ️
UIでのトレーニングおよびファインチューニングのフローに関する詳細な手順については、以下を参照してください。 このYouTube動画
LLMのデプロイは、たった3回のクリックで完了します!
🚀
モデルがデプロイされました!
推論を開始 モデルAPIエンドポイントを使用して。TrueFoundryは、 OpenAPIインターフェース でモデルをテストし、アプリケーション内でモデルを呼び出すためのサンプルコードを提供します。
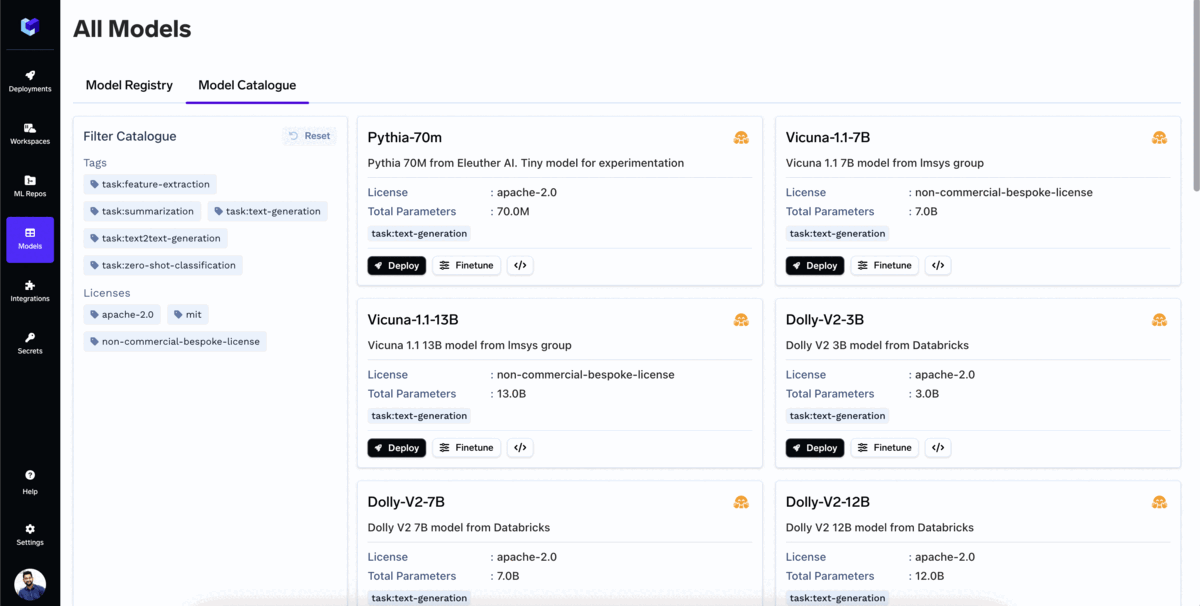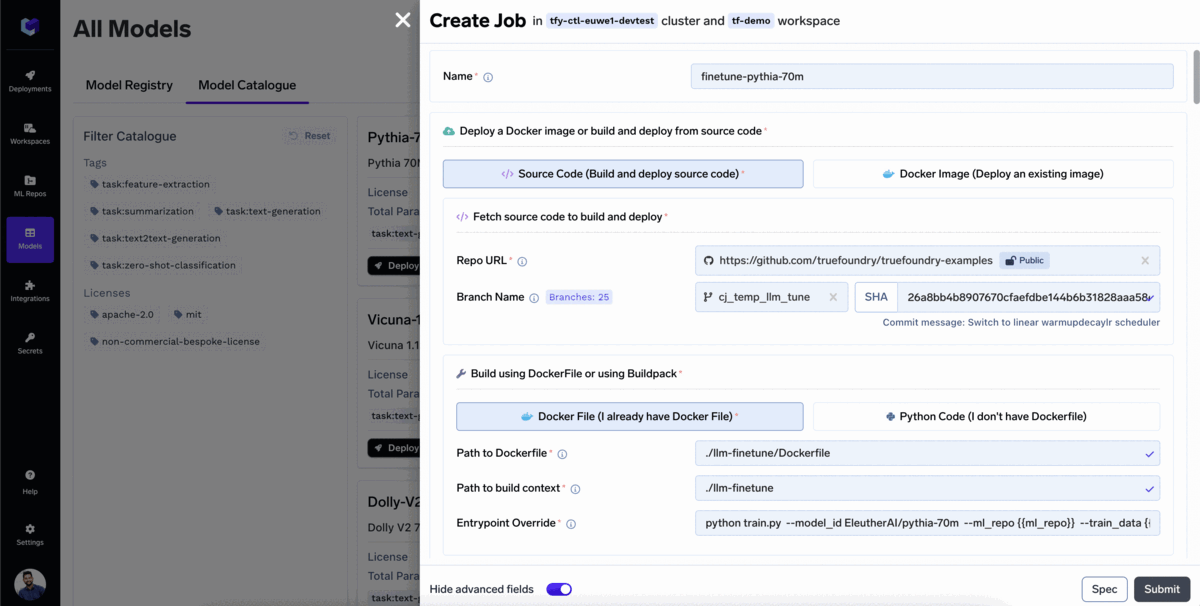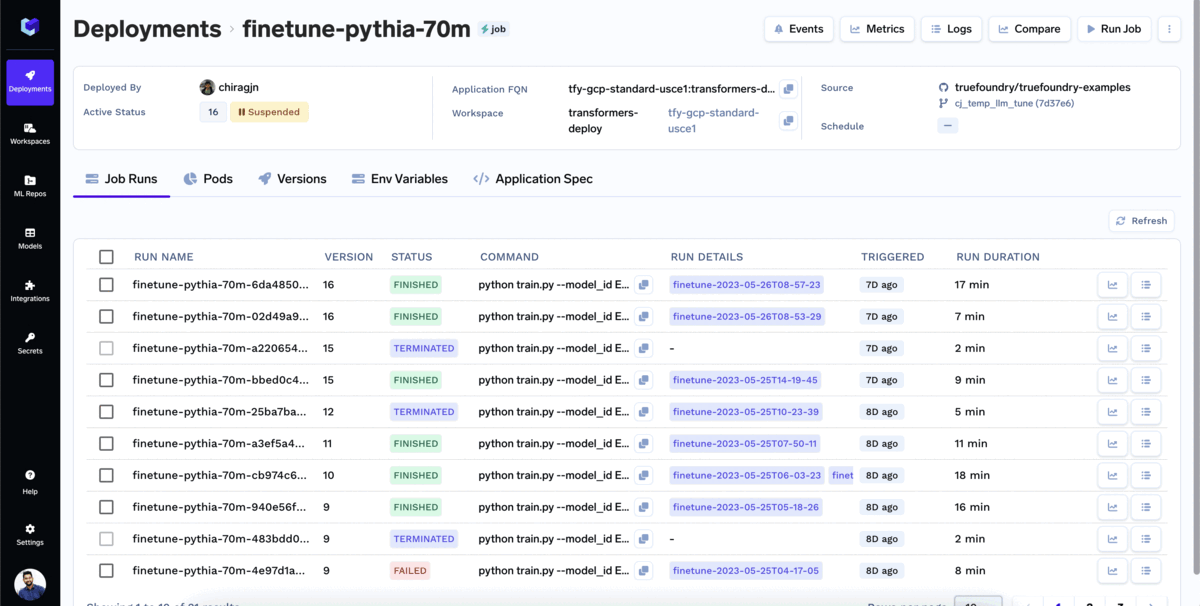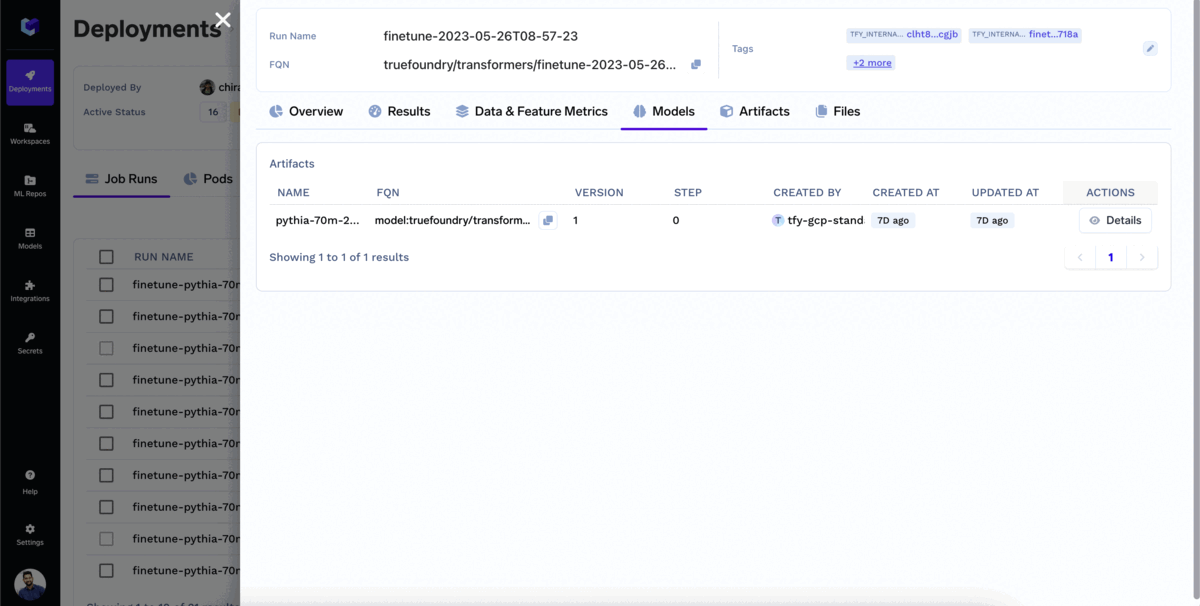
ほとんどの企業は、特定のユースケースに合わせてファインチューニングされたモデルを使用したいと考えるでしょう。TrueFoundryでモデルをファインチューニングするには:
🚀
モデルのファインチューニングが開始されました!
ファインチューニングの 監視が可能です。 進捗状況は、ジョブ実行タブで確認できます。そこでは、損失メトリクス、トレーニング曲線、評価結果など、トレーニングジョブに関連するすべての情報を表示できます。これにより、ファインチューニングプロセスを追跡し、ジョブのパフォーマンスに基づいて情報に基づいた意思決定を行うことができます。
大規模言語モデル(LLM)と生成AIに関する私たちの取り組みは、まだ始まったばかりです。今後、さらに多くのものを構築していく予定ですので、最新情報をお届けしていきます!
私たちも、他の皆さんと同様に、この分野についてはまだ学習段階にあります。もし貴社で大規模言語モデルの活用をご検討されているのであれば、ぜひお話しし、情報交換させていただければ幸いです。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)




.png)








.webp)
.webp)


