













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
2026年のアプリケーションは、単一のモデルと対話するのではなく、フロンティア、ミドルティア、安価なモデル、自己ホスト型など、さまざまなモデルのメニューと対話します。ルーティングとは、コスト、レイテンシ、品質という互いに相反する3つの目標を考慮しながら、リクエストごとに1つのモデルを選択するポリシーです。この記事では、静的ルールからセマンティックルーティング、モデルカスケードに至るまでのルーティング戦略、ルーティングの基準としたい品質を測定するという難しい問題、ルーティングがフェイルオーバーではない理由、そしてルーターが密かに期待を裏切らないようにするための計測について解説します。
ノースウィンドでの火曜日。 プラットフォームエンジニアのオマールは、今四半期、ある数字を誇りに思っていました。それは、会社のLLM利用料が41%削減されたことです。彼はルーターを構築しました。単純な分類や意図検出の呼び出しは安価なモデルに送られ、多段階推論やコード生成といった本当に難しいリクエストだけがフロンティアモデルに到達するようにしました。それはうまくいき、財務部門もそれに気づきました。
しかし、2週目の請求額は、トラフィックの増加がないにもかかわらず、1週目の3倍になりました。オマールは原因を突き止めました。彼が構築したカスケードには検証機能があり、安価なモデルの出力はスキーマチェックされ、チェックに失敗するとリクエストはフロンティアモデルにエスカレートされる仕組みでした。プロバイダー側のアップデートにより、安価なモデルの出力フォーマットが微妙に変更され、スキーマチェックがほとんどの応答で失敗するようになり、ルーターは密かにトラフィックの約90%を最も高価なモデルにエスカレートさせていたのです。エラーもアラートも発生しませんでした。ルーターは指示された通りに動作していましたが、オマールが意図した通りには機能しなくなっていたのです。エスカレーション率は9日間上昇し続けていましたが、誰もそれに気づいていませんでした。
ルーティングは、LLMスタックにおいて最も効果的なコスト削減手段の一つであり、同時に密かに誤った設定になりやすいものでもあります。この記事では、その戦略、トレードオフ、そしてルーターが正しく機能し続けるための計測について解説します。
この記事で紹介するルーティング戦略は抽象的なものではなく、 TrueFoundryのAIゲートウェイ がどのように設定されているかを示しています。その ルーティング設定 は、モデル、サブジェクト(ユーザー、チーム、仮想アカウント)、または X-TFY-METADATA ヘッダーによって各リクエストを照合し、ルールを上から順に評価して最初の一致を優先し、ターゲットモデルにリクエストを送信します。これらはすべて、アプリケーション内の分岐ロジックではなく、ゲートウェイで適用されるYAMLとして行われます。
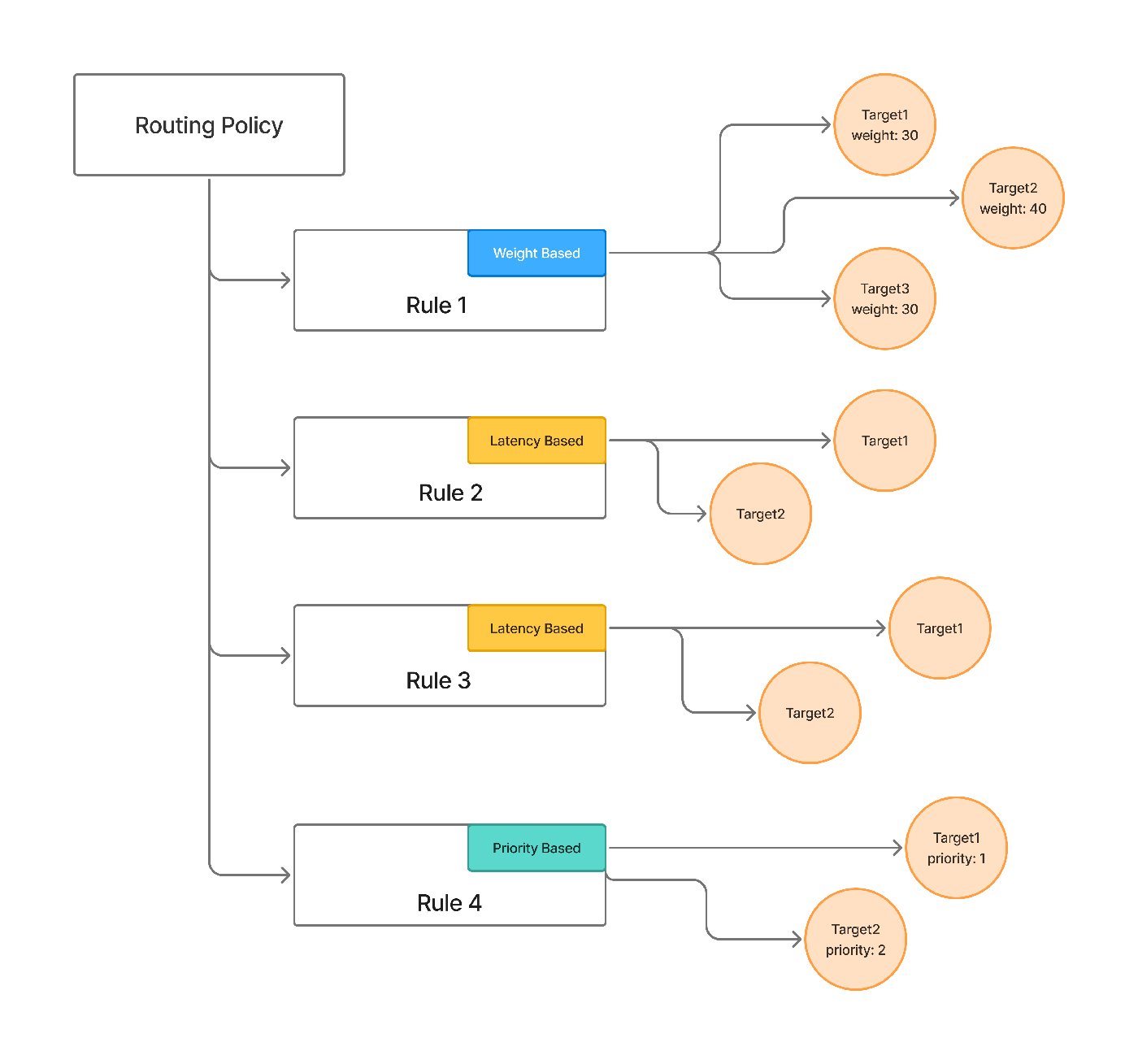
3つの戦略は、セクション2の段階にマッピングされます。 重みベース 分割とカナリアリリース用、 レイテンシベース 最もレイテンシの低い健全なターゲットを優先するため、そして 優先度ベース フォールバックを伴う順序付けられた優先順位のために。ターゲットごとの上書きは、この投稿で提起されているモデル固有のプロンプトの問題も解決します。つまり、異なる prompt_version_fqn をターゲットごとに設定できるため、各モデルはそのモデルに合わせたプロンプトを受け取ります。これはターゲットごとのリトライとフォールバックと合わせて利用できます。(新しいセットアップの場合、ドキュメントでは仮想モデルを推奨しています。これは、より明確なモデルごとの所有権とアクセス制御を備え、同じ戦略、リトライ、フォールバックをパッケージ化したものです。)
OpenAI SDKをすでに使用しているアプリケーションからゲートウェイを呼び出すのは、1行の変更で済みます。クライアントは同じで、ベースURLとキーが異なるだけです。ルーティングの決定はコード内ではなくゲートウェイで行われます。アプリケーションはまた、 X-TFY-METADATA ヘッダーを渡すこともでき、これによりゲートウェイは条件付きコードパスなしでタスク、環境、またはテナントに基づいてルーティングを行います。
Pythonからのゲートウェイ呼び出し (OpenAI互換API)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-personal-access-token>", # Bearer-auth'd JWT
)
resp = client.chat.completions.create(
model="assistant", # logical/virtual model — gateway picks the target
extra_headers={"X-TFY-METADATA": '{"task": "classify"}'}, # drives the matching rule
messages=[{"role": "user", "content": "..."}],
)2026年のエンタープライズアプリケーションは、経済性が大きく異なる複数のモデルを使い分けます。安価なモデル(Claude Haiku 4.5は入力トークン100万あたり約1ドル)は、現在の標準料金でフロンティアモデルよりも数倍安価であり、実用上はレイテンシも低いことが多いです。中間層のモデル(Sonnet 4.6は入力100万あたり3ドル)はその中間に位置します。自己ホスト型のオープンウェイトモデル(Llama、Mistral)は、トークンごとの料金を固定GPU容量とデータ制御と引き換えに提供します。これは、継続的に高い利用率であれば安価ですが、利用率が低い場合は高価になります。各モデルはタスクごとに異なる品質プロファイルを持っています。コードに優れているモデルが抽出では平凡であることもあれば、その逆もあります。
ルーティングとは、各受信リクエストをこれらのモデルのいずれかにマッピングするポリシーです。3つの目標は互いに相反します。最も安価なモデルが最高の品質であることは稀であり、最速のモデルが常に最も安価であるとは限りません。また、難しいタスクに最適なモデルを簡単なタスクに使うのは無駄です。愚直なデフォルト設定、つまりすべてを最高のフロンティアモデルに送る方法は、品質を最大化しますが、最も高価な選択肢であり、多くの場合最も遅いです。安価なモデルがごくわずかな時間とコストで正しく回答できるリクエストに対して、多段階の推論モデルを適用することになります。ルーティングは、そのコストと品質の境界線を、一度に1つのリクエストでナビゲートする場所です。
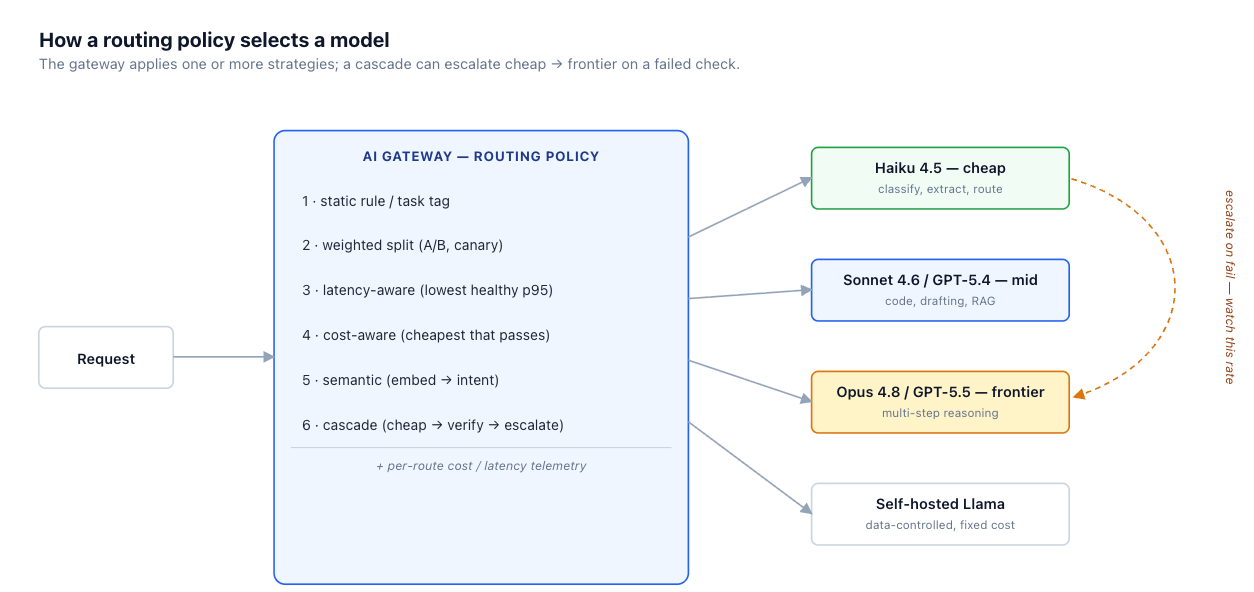
ルーティング戦略は梯子のようなものです。各段は機能とコストを追加し、どこで止めるべきかは、測定されたメリットが追加された複雑さを正当化しなくなる時点です。
静的 / ルールベース。 エンドポイント、ヘッダー、または呼び出し元が設定するタスクタグでルーティングします。分類は安価なモデルへ、コード生成はミドルティアへ。サブミリ秒で、決定論的で、簡単にデバッグ可能です。これは、呼び出し元がタスクタイプをすでに知っている場合に機能し、その頻度はチームが想定するよりも高いです。
重み付け / 負荷分散。 モデル間でトラフィックを割合で分割します。これは、新しいモデルのA/Bテストやカナリアリリース(トラフィックの5%を新しいモデルに送り、メトリクスを監視し、問題なければ徐々に増やす)の基礎となります。
レイテンシー考慮型。 複数のモデルがリクエストに対して許容される場合、現時点で最も健全なp95レイテンシーが低いモデルにルーティングします。これは、いくつかのモデルのいずれでも対応可能な、レイテンシーに敏感なパスに役立ちます。
コスト考慮型。 タスクの品質基準を満たす最も安価なモデルを選択します。これには、タスクごとの品質基準(セクション5)を知る必要があり、それが難しい部分です。
「最も安価」が何を意味するかに注意してください。名目上の入力トークンレートではなく、リクエストの総コストに基づいてルーティングします。実際の数値は、予想される入力トークンと予想される出力トークンに、キャッシュヒット率、リトライおよびヘッジの確率、カスケードエスカレーションの確率、および地域、優先度、または高速モードの乗数を調整したものです。トークナイザーもファミリーによって異なります。Anthropicは、Opus 4.7以降が同じテキストに対して最大35%多くのトークンを出力できると指摘しており、そのため同じプロンプトでも異なるモデルでは異なる課金カウントが生成されます。ルートコストは、料金表を静的テーブルにコピーするのではなく、実際のトレースから見積もってください。
最後の2つの段、セマンティックルーティングとモデルカスケードについては、それぞれ別のセクションで説明します。ほとんどのプロダクションルーターは、既知のタスクタグに対する静的ルール、それ以外のすべてに対するコストまたはレイテンシーを考慮したデフォルト、および可用性のための個別のフォールバックリストを組み合わせたものです。以下の設定は例示であり、正確なスキーマはゲートウェイ固有です。
例示的なルーティングポリシー(概念的 — 正確なスキーマはゲートウェイ固有)
routes:
- match: { header: "x-task", equals: "classify" }
target: claude-haiku-4-5 # cheap tier
- match: { header: "x-task", equals: "code" }
target: claude-sonnet-4-6
- default:
strategy: cost_aware # cheapest model that passes the task's quality bar
candidates: [claude-sonnet-4-6, gpt-5.4]
fallback: [gpt-5.5] # availability, NOT optimization — see section 6上記の梯子が、 TrueFoundryのAIゲートウェイでどのように機能するかを示します。これらの戦略は実際にそこで実行されます。ルーティングはYAMLの gateway-load-balancing-configです。各ルールは、モデル、チーム、または X-TFY-METADATA ヘッダーによってトラフィックの一部に一致し、そのターゲット間で 重み付けに基づいてルーティングします。、 レイテンシーベース、または プライオリティベース の選択。モデルの追加や分割の変更は、再デプロイではなく設定変更です。
TrueFoundryがこれらの戦略をどのように表現するか(gateway-load-balancing-config)
name: routing-config
type: gateway-load-balancing-config
rules:
- id: classify-to-cheap # static task tag -> cheap tier
type: weight-based-routing
when:
models: [assistant]
metadata: { task: classify }
load_balance_targets:
- target: anthropic/claude-haiku-4-5
weight: 100
- id: default-lowest-latency # everything else -> fastest healthy target
type: latency-based-routing
when:
models: [assistant]
load_balance_targets:
- target: anthropic/claude-sonnet-4-6
- target: openai/gpt-5.4各ターゲットは、リトライ、フォールバックリスト、さらにはターゲットごとのプロンプト(prompt_version_fqn)を持つことができるため、各モデルはそれぞれに調整されたプロンプトを受け取ります。ルーティングポリシーとフォールバックチェーンの両方が1つのファイルで表現されるため、両者は明確に区別され、個別に監視可能です。これはセクション6が示す線です。完全なスキーマは ルーティング設定ドキュメントにあります。
同じファイルでカナリアロールアウト(この投稿が新しいモデルのA/Bテストに推奨する重み付け分割パターン)を、アプリ側の分岐なしで処理します。
重みベースのルーティングによるカナリアロールアウト(ドキュメントより)
name: loadbalancing-config
type: gateway-load-balancing-config
rules:
- id: gpt4-canary
type: weight-based-routing
when:
models: [gpt-4]
load_balance_targets:
- target: azure/gpt4-v1
weight: 90
- target: azure/gpt4-v2
weight: 10この投稿におけるルーティング決定に関して、TrueFoundry固有の注目すべきレバー(機能)をいくつか挙げます。 仮想モデル は、グローバルルーティング設定のゲートウェイ推奨代替手段です。これらは、同じ重み/レイテンシー/プライオリティ戦略、リトライ、フォールバックを、独自のアクセス制御を持つ単一の論理モデル名の背後にパッケージ化するため、すべての呼び出し元を変更することなく、ルートを昇格または交換できます。 完全一致キャッシュと意味的キャッシュ ルーティング決定の前に位置し、繰り返しクエリに対して保存された応答を返すことで、読み込み負荷の高いワークロードにおけるコストとテールレイテンシーの両方を削減します。そして、同じルーティング設定が一致するのは X-TFY-METADATAであるため、1つのルールファイルで開発/本番環境およびテナントごとのルーティングに対応できます。ルーティング層は、クライアントがルート選択をエンコードするのではなく、クライアントが送信した内容を読み取ります。
静的タグは、呼び出し元がタスクを知っていることを前提としています。しかし、そうでない場合もあります。汎用アシスタントは1つのエンドポイントを公開し、すべてのリクエストがそこに到達します。意味的ルーティングは、リクエスト自体からタスクを推論します。プロンプトを埋め込み、最も近い意図のセントロイドを見つけ(または小さな分類器を実行し)、推論された意図に基づいてルーティングします。
意味的ルーティング — リクエストを埋め込み、最も近い意図でルーティング
emb = embed(req.text) # ~5–20 ms, small per-call cost
intent = nearest_centroid(emb, centroids) # e.g. "sql", "summarize", "chat", "reason"
model = ROUTING_TABLE.get(intent, DEFAULT) # intent -> specialized modelコストは、埋め込み呼び出し(約5~20ミリ秒、トークンごとの少額の料金)と安価な分類ステップです。正直に言うと、これが真価を発揮するのは、呼び出し元で意図がまだ不明な場合に限られます。呼び出し元のコードがx-task=classifyのようなヘッダーを設定できるのであれば、それは無料で、決定的で、より良い方法です。意味的ルーティングは、リクエストにラベルが付いていない汎用アシスタントの入り口に属するものであり、各呼び出しの目的をすでに知っている内部パイプラインに無理やり組み込むべきではありません。欠点としては、製品の意図が変化するにつれてセントロイドと分類器がドリフトし、メンテナンスが必要になること、そして誤分類によって誤ったモデルにルーティングされることです。そのため、意味的ルーターには健全なデフォルトとフォールバックが依然として必要です。埋め込みと分類のステップがどこで実行されるにせよ、ゲートウェイは推論された意図と、それがトレース上で選択したモデルを記録するのに最適な場所です。これは、ルートごとの可視性であり、 TrueFoundryのAIゲートウェイ がすでにシンプルな戦略に対して提供しているものであり、誤ったルーティングを不可視なものではなく、デバッグ可能なものに変えるものです。
カスケードはまず安価なモデルを試し、結果をチェックし、チェックが失敗した場合にのみ、より強力なモデルにエスカレートします。チェックは、スキーマ検証(出力が期待される構造に対して解析されるか?)、信頼度または自己整合性シグナル、あるいは判定モデルである場合があります。
スキーマ検証付きの安価なものを優先するカスケード
def answer(req):
draft = call_model("claude-haiku-4-5", req)
if schema_ok(draft) and confident(draft):
return draft, "haiku"
# Escalate — but COUNT it. A rising escalation rate is a cost incident.
metrics.incr("router.escalation")
return call_model("gpt-5.5", req), "gpt-5.5"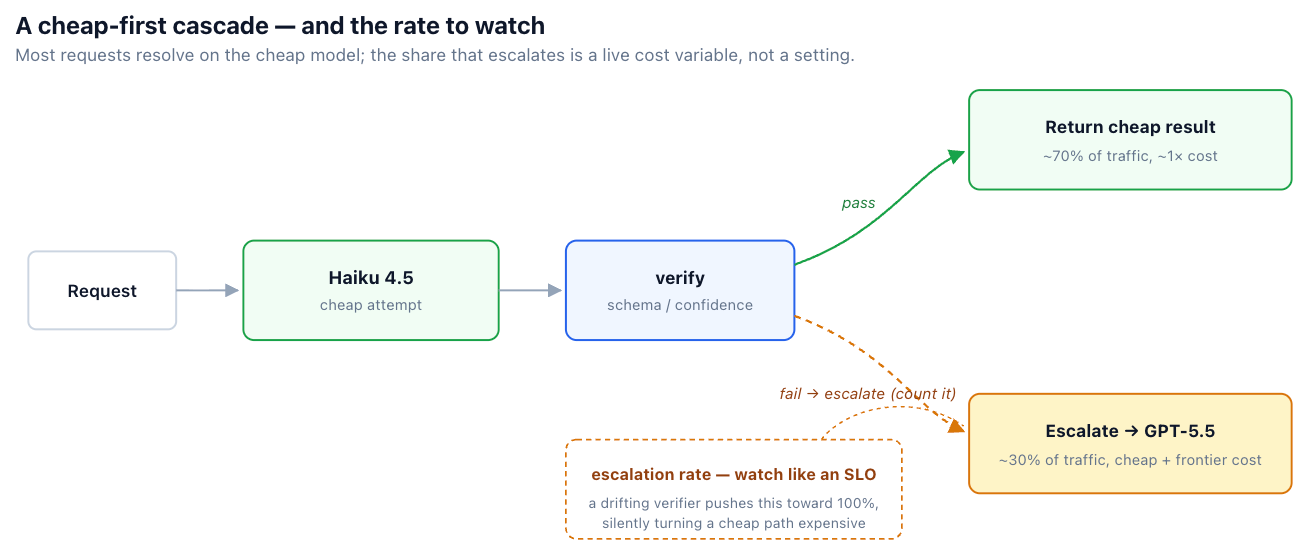
その経済性は非常に魅力的です。安価な層がほとんどのリクエストを解決する場合、ブレンドされたコストは安価な層の価格に近づきます。例として、Haikuと指定されたフロンティアモデルとの間に約5倍の標準料金差がある場合、70%の安価な解決率で、ブレンドされたコストは、エスカレートする30%の安価な試行に費用を支払った後でも、常にフロンティアモデルを使用する場合の約半分になります。(一部のプレミアム、プロ、または優先ティアがそうであるように、差を10倍に広げると、同じカスケードで約40%に近づきます。)正確な節約額は、解決率と実際の価格差に依存するため、仮定するのではなく測定してください。
カスケードは、エスカレートされたすべてのリクエストに安価なモデルのレイテンシーも追加します。つまり、安価な呼び出しの時間と、その後のフロンティア呼び出しの時間の両方を支払うことになります。インタラクティブでレイテンシーに敏感なパスでは、その二重のホップは誤ったトレードオフとなる可能性があります。カスケードは、ブレンドされたコストの利点がエスカレーション時のテールレイテンシーを上回る、スループット重視または非同期のワークロードで真価を発揮します。
コストやレイテンシーに基づくルーティングは、どちらも直接観測可能であるため、簡単です。品質に基づくルーティングは、最適化する前に品質を測定する必要があるため、より困難です。忠実度とコストの順に増加する3つのアプローチ:
オフライン評価セット。 タスクタイプごとに厳選され、ラベル付けされたセット。各候補モデルをそれに対して実行し、結果からルーティングテーブルを構築します。SQLにはこのモデル、要約にはあのモデルといった具合に。繰り返し実行するのは安価ですが、評価セットの代表性以上のものにはなりません。
オンラインLLMジャッジ 本番トラフィックをサンプリングし、審査モデルで応答を評価します。実際の分布に近いですが、コストとレイテンシーが増加し、審査モデル自体も誤りを犯す可能性があります。生成モデルと同じ盲点を持つ審査モデルは、それらを追認してしまうでしょう。
ビジネス指標に対するA/Bテスト 究極の基準:トラフィックの一部を候補にルーティングし、実際に重視する指標(解決率、高評価、下流のコンバージョンなど)を測定します。時間と労力がかかりますが、これは代理指標ではなく、対象そのものを測定します。
これらすべてに共通する注意点:感覚でルーティングしてはいけません。デモでは「問題なさそうに見える」安価なモデルでも、数週間にわたって下流の指標を静かに悪化させる可能性があります。すべてのルーティング変更を測定された品質ゲートに紐付け、品質はタスク固有のものであることを忘れないでください。単一のリーダーボードの順位はルーティングテーブルではありません。なぜなら、一般的なベンチマークでトップのモデルでも、特定の抽出タスクでは平凡な性能かもしれないからです。これら3つの方法すべてが必要とする本番環境からのシグナル — どのモデルがどのリクエストを処理し、次に何が起こったか — は、ゲートウェイがすでに記録しているものです。 TrueFoundryの ルートごとのトレースは、上記のオフライン評価セットとオンラインサンプリングの自然な情報源となります。
これら3つの方法すべてが考慮すべきこと:本番ルーターは、自身が選択したモデルしか認識しません。Haikuにリクエストをルーティングした場合、Sonnet、Opus、またはGPT-5.5の方が優れていたかどうかを知ることはできません — 反事実(もし別の選択をしていたらどうなっていたか)は見えないのです。ルーティングテーブルの正確性を保つために、シャドウ評価のためにトラフィックの一部をサンプリングするか、他の候補モデルで実際の要求をオフラインでリプレイするか、または定期的にチャンピオン/チャレンジャーテストを実行してください。それがなければ、ルーターは古いポリシーを静かに利用し続け、別のモデルがタスクに対してより優れていたり、安価になったり、安全になったりしたことに気づかなくなります。
ルーティングとフェイルオーバーは仕組み(候補モデルのリストと、それらの中から選択するポリシー)を共有しているため、混同しやすいです。それらは異なる目的であり、それらを統合するとインシデントを引き起こします。
ルーティングは最適化である: すべての候補が正常な場合、コスト、レイテンシー、または品質の点で最適なものを選択する。 フェイルオーバーは可用性である: 選択されたモデルがダウンしているか、タイムアウトしている場合、リクエストが成功するように別のモデルにフォールバックする(これは本シリーズの次回の投稿のテーマです)。この区別は運用上重要です。障害によってトリガーされた安価なモデルへのフォールバックは、静かに品質を低下させる可能性があり、それは意図的なコスト削減策と誤解されるのではなく、「プライマリがダウンしたためフォールバックした」と記録されるべきです。逆に、一時的な500エラーはフェイルオーバーをトリガーすべきであり、永続的なルーティング変更ではありません。2つのポリシーを分離し、個別に監視可能にしてください。「コストのためにXにルーティングされた」と「Xが異常だったためYにフォールバックした」は異なるイベントであり、トレース上でも異なるように見えるべきです。ゲートウェイは TrueFoundryの 両者が混同されることなく共存する場所である — ルーティングポリシーとフォールバックチェーンは、別個のものとして設定され、トレースされます。
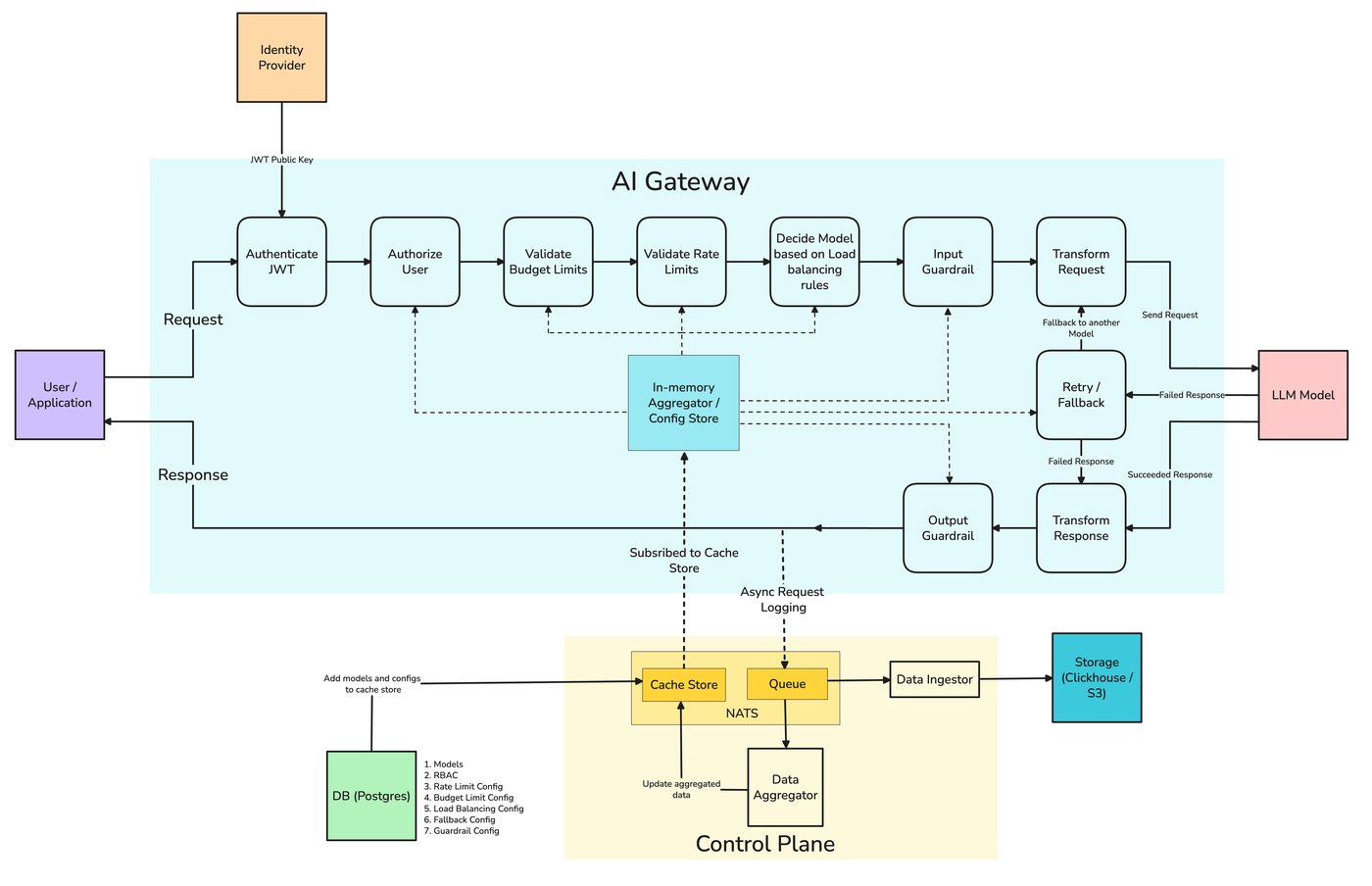
ルーティングロジックはアプリケーション内に存在することもできますが、ゲートウェイの方がより自然な場所である理由は2つあります。第一に、ゲートウェイはすでにプロバイダーAPIを正規化しているため、あるモデルから別のモデルへのルート切り替えは、コード変更ではなく設定変更で済みます。例えば、OpenAIモデルとAnthropicモデルを切り替える際に、リクエストの構築を書き直す必要はありません。第二に、ルーティングの決定に必要なコストとレイテンシーのテレメトリーをすでに保持しています。適切にルーティングするために必要なデータは、ゲートウェイがすでに収集しているデータなのです。
ルーティングの一元化は TrueFoundryのAIゲートウェイ サービス全体に適用される単一のポリシー、新しいモデルをA/Bテストする単一の場所、そしてコールドオープンによって有効になったブレンドコストとカスケードエスカレーション率を監視する単一の場所を意味します。ゲートウェイは、ホスト型モデルとセルフホスト型モデルの両方に対して、ルーティングルール、重み付けされたロードバランシング、およびフォールバックチェーンを、統一されたOpenAI互換APIを通じて公開します。また、ルートごとのコストとレイテンシは、コストアトリビューションの投稿と同じアトリビューションビューに表示されます。役割分担は明確に述べる価値があります。ゲートウェイはルーティングを行い、数値を提供します。アプリケーションは、品質の定義と、各タスクでどのモデルが最適かを決定する評価セットを引き続き所有します。
ルーティングは無料ではなく、オーバーヘッドは戦略によって異なります。静的ルールは1ミリ秒をはるかに下回る時間で評価されます。レイテンシを考慮したルーティングには、リアルタイムのp95テレメトリが必要ですが、これは読み取りコストが低いです。セマンティックルーティングは、埋め込み呼び出し(約5~20ミリ秒)と軽量な分類器を追加します。カスケードは、エスカレートするすべてのリクエストに対して、安価なモデルの完全なレイテンシを追加します。
設計原則は、ルーティングの決定を、それに先行するモデル呼び出しと比較して安価に保つことです。1ミリ秒未満のルールは、500ミリ秒以上の生成に対してはノイズに過ぎません。セマンティックステップは、アシスタントの入り口で十分に許容できるコストです。カスケードのエスカレーションにおける二重のレイテンシは、インタラクティブなパスで精査すべき点です。また、カスケードまたは品質向上が、各リクエストで2回目のモデル呼び出しのコストを支払うことを明確に正当化しない限り、品質測定のためにすべてのルートにジャッジモデル呼び出しを追加しないでください。トラフィックの一部をサンプリングしてオンライン評価を行うことで、通常、リクエストごとの追加コストなしで必要なシグナルを得られます。ルーティングの決定とモデル呼び出しが同じトレース上にあるため、決定自体のオーバーヘッドは仮定ではなく測定可能です。 TrueFoundryのAIゲートウェイ ルートごとのレイテンシを記録するため、セマンティックステップやカスケードホップが実際に期待どおりに安価であることを確認できます。
ルーティングはゲートウェイとアプリケーションのどちらに置くべきですか?
メカニズムはゲートウェイに属します。ゲートウェイはプロバイダーAPIを正規化し、コスト/レイテンシのテレメトリを保持するため、ルーティングはコードではなく設定になります。アプリケーションは、品質の定義と、タスクごとに最適なモデルを決定する評価セットを引き続き所有します。つまり、ゲートウェイはポリシーに基づいてリクエストをどこに送信するかを決定し、アプリはポリシーがどうあるべきかを決定すると考えてください。
安価なモデルへのルーティングは品質を損なわないのでしょうか?
感覚でルーティングする場合のみです。セクション5の全体的なポイントは、ルーティングの変更は、デプロイされる前にタスクごとに測定された品質ゲートを通過する必要があるということです。分類基準を満たす安価なモデルは、品質の低下ではありません。測定なしに「十分良い」と仮定された安価なモデルが、品質低下を引き起こすのです。
カスケード検証器はどのように選択すればよいですか?
出力が構造化されている場合、スキーマ検証が最も安価で信頼性の高い検証器です。これは決定的であり、モデル呼び出しを追加しません。オープンエンドの出力の場合、ジャッジモデルはより高性能ですが、2回目の呼び出しコストがかかり、間違っている可能性もあります。どちらを選択するにしても、エスカレーション率を計測し、アラートを設定してください。検証器のずれは、カスケードが静かにコスト問題になる一般的な原因だからです。
セマンティックルーティングはレイテンシを過剰に増加させますか?
埋め込みに約5~20ミリ秒と安価な分類ステップが追加されます。これは通常、数百ミリ秒の生成に対しては許容されますが、100ミリ秒未満の分類や高QPSの内部パスでは無料ではないため、ノイズと仮定するのではなく、自身のパスで測定してください。本当の問題はレイテンシではなく、そもそもそれが必要かどうかです。呼び出し元がヘッダーでタスクをラベル付けできる場合、それは無料で決定的であり、セマンティックルーティングはリクエストがラベルなしで到着した場合にのみその価値を発揮します。
これはコストアトリビューションとフェイルオーバーとどのように連携しますか?
ルーティングの決定とそれによって生じるブレンドコストは、コストに関する投稿で説明されている同じトレースごとのアトリビューションに紐付けられるため、どのルートが支出を促進しているかを確認できます。フェイルオーバーは別の懸念事項であり、最適化ではなく可用性に関するもので、次の投稿で説明します。停電によるフォールバックがコスト決定のように見えないように、これら2つを別個の、個別にログに記録されたイベントとして扱ってください。
オマールのルーターは間違っていませんでした。ただ監視されていなかっただけです。この投稿で紹介されている戦略は、それらと並行して監視する数値(エスカレーション率、ルートごとのブレンドコスト、各モデル変更の品質ゲート)と同じくらい安全です。積極的にルーティングを行いますが、まずは計測を行ってください。
TrueFoundryのAIゲートウェイ は、アプリケーションと1,600以上のモデル(OpenAI、Anthropic、Google、AWS Bedrock、Azure OpenAI、および自社ホスト型モデルを含む)の間に位置し、単一のOpenAI互換APIを通じて機能するエンタープライズグレードのコントロールプレーンです。本稿で紹介するルーティング戦略を、コードではなく設定として実現します。重みベース、レイテンシベース、優先度ベースのルーティング、モデルカスケード、フォールバック、ターゲットごとのプロンプトオーバーライドなど、これらすべてがYAMLで記述され、ルートごとに適用されます。
ゲートウェイはすでにすべてのプロバイダーを正規化し、ルートごとのコスト、レイテンシ、リクエスト/ルーティングメタデータを記録しているため、ルーティングが測定可能になる場所でもあります。モデルのA/Bテスト、カスケードのエスカレーション率の監視、ブレンドされたコストの割り当てをすべて一箇所で行えます。これらのトレースを、他の場所で収集した評価およびフィードバックシグナルと組み合わせることで、同じビューが品質ビューにもなります。さらに、厳密なキャッシュとセマンティックキャッシュ、RBAC、予算管理、レート制限、ガードレールを追加し、SaaS、VPC内、オンプレミス、またはエアギャップ環境でデプロイ可能で、SOC 2、HIPAA、ITARに準拠しています。また、GartnerのAIゲートウェイ市場ガイドにも掲載されています。詳細については、 ルーティングとロードバランシングのドキュメント または AIゲートウェイの概要 をご覧ください。
NorthwindとOmarは例示です。モデル名とトークンあたりの価格は、2026年6月時点のプロバイダーの公開料金表を反映しており、時間の経過とともに変更されます。コストとレイテンシの数値(約5倍の価格差、70%の低解像度例、5~20ミリ秒の埋め込みオーバーヘッドなど)は、トレードオフを説明するための代表的な仮定であり、測定値ではありません。本番環境のポリシーを設定する前に、ご自身のトラフィックと評価セットに対してルーティング戦略をベンチマークしてください。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


