














July 20, 2023
|
5 min read

Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
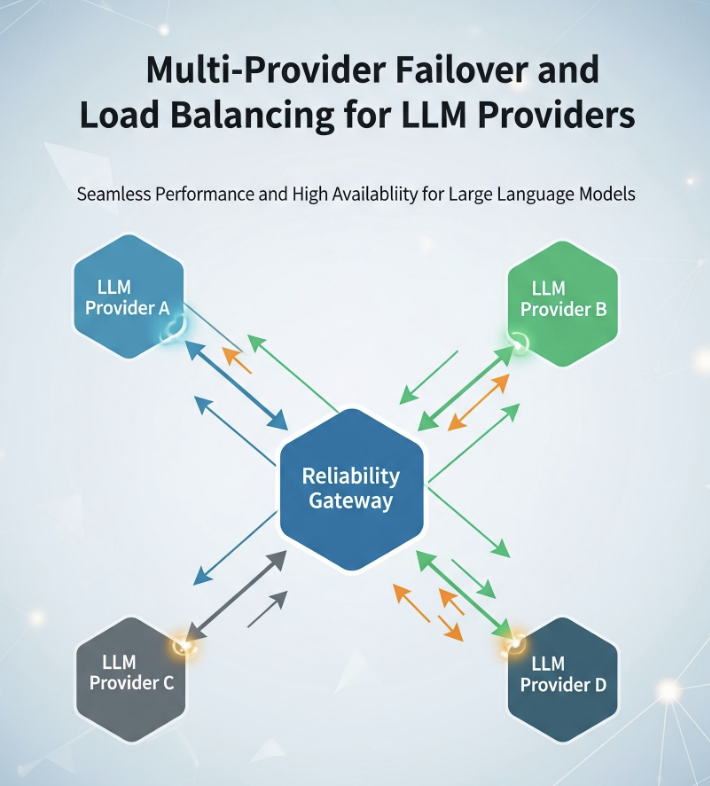
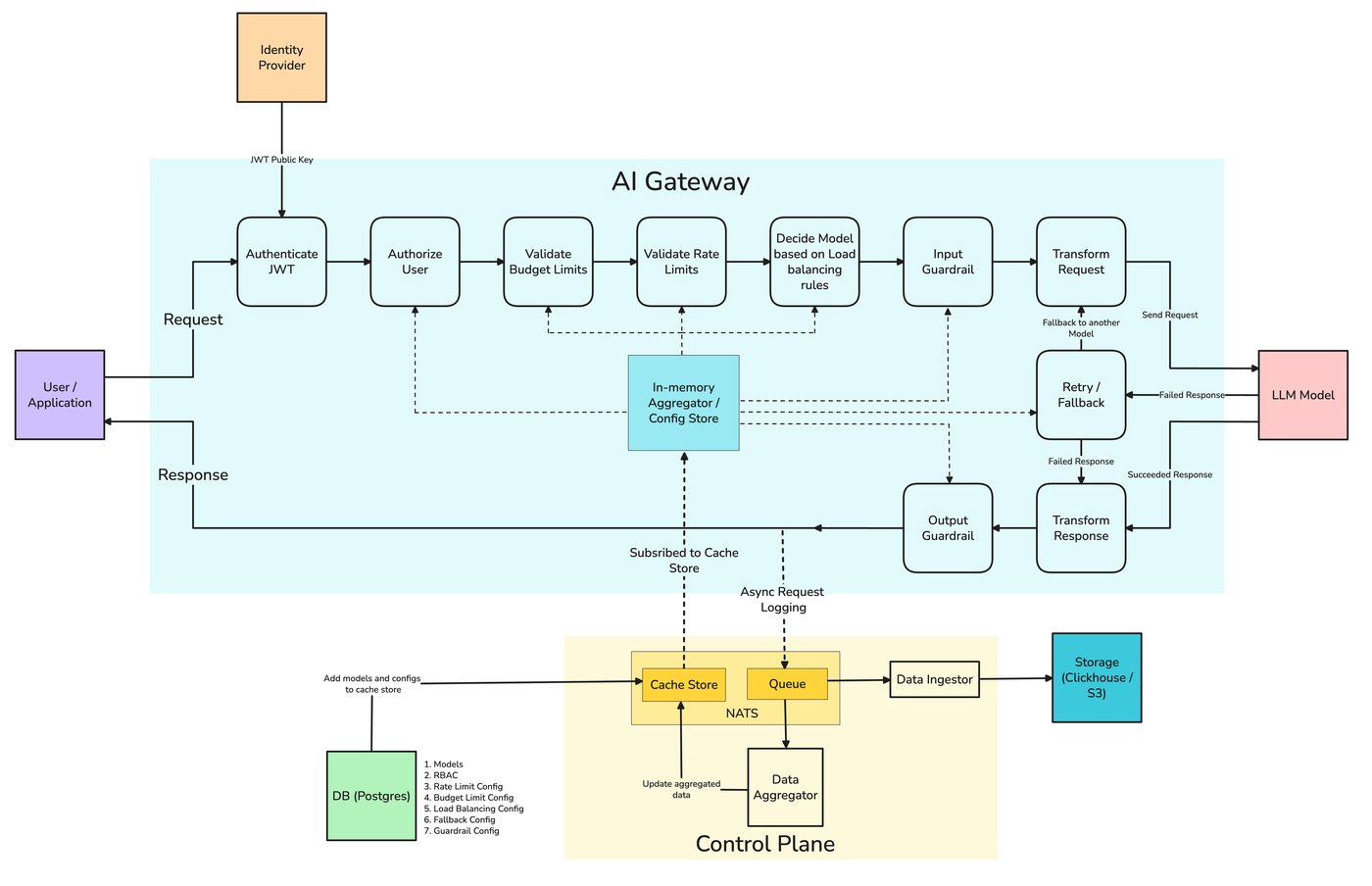
どのモデルプロバイダーにも、地域的な障害、負荷時のレート制限エラー多発、完全に障害には至らないものの劣化するレイテンシーなど、調子の悪い日はあります。アプリケーションが単一のプロバイダーを直接呼び出している場合、そのプロバイダーの最悪の日は、あなたの最悪の日となります。この記事は、それを防ぐための信頼性レイヤーについて解説します。具体的には、LLM呼び出しがどのように失敗するかを分類し、状況を悪化させないリトライ、複数のプロバイダーにまたがるフォールバックチェーン、ヘルスアウェアなロードバランシング、迅速に失敗を検知するサーキットブレーカー、そしてストリーム途中のフェイルオーバーという本当に難しいケースについて説明します。
ノースウィンド社での午前2時14分。 SREのナディアはページングで目を覚ました。顧客対応のサポートエージェントが、一部のユーザーではなく、すべてのユーザーにエラーを返していたのだ。ノースウィンド社自身のサービスは健全で、CPU、メモリ、キューはすべて正常だった。エラーはすべて同じで、モデルプロバイダーからの503エラーだった。プロバイダー側で地域的な障害が発生し、推論エンドポイントが停止していたのだ。ノースウィンド社のエージェントはそのエンドポイントを直接呼び出していたため、すべてのリクエストは停止したエンドポイントに到達し、失敗して顧客にエラーを返した。プロバイダーが復旧するまでの40分間、待つことしかできなかった。エージェントは完了を得るための手段を一つしか持っておらず、それが停止していたのだ。
ポストモーテムでのアクション項目は「より信頼性の高いプロバイダーを選ぶ」ではありませんでした。どのプロバイダーにも障害は発生します。それは「成功しなければならないリクエストに対して、単一のプロバイダーに依存してはならない」というものでした。これはゲートウェイの問題であり、この記事はその解決策を提示します。具体的には、状況を悪化させないリトライ、複数のプロバイダーにまたがるフォールバックチェーン、ヘルスアウェアなロードバランシング、そしてプロバイダーと一緒にシステム全体を巻き込むのではなく、迅速に失敗を検知するサーキットブレーカーについてです。
この記事で説明するすべて — リトライ、フォールバックチェーン、ヘルスアウェアなロードバランシング — は、 TrueFoundryのAIゲートウェイが サービスごとのコードではなく設定として表現するものです。その ルーティング設定は YAMLでロードバランシング、フォールバック、リトライのルールを定義し、最初の一致ルールが優先されるように順序付けて評価し、各アプリケーションで再実装されるのではなく、すべてリクエストに一元的に適用します。
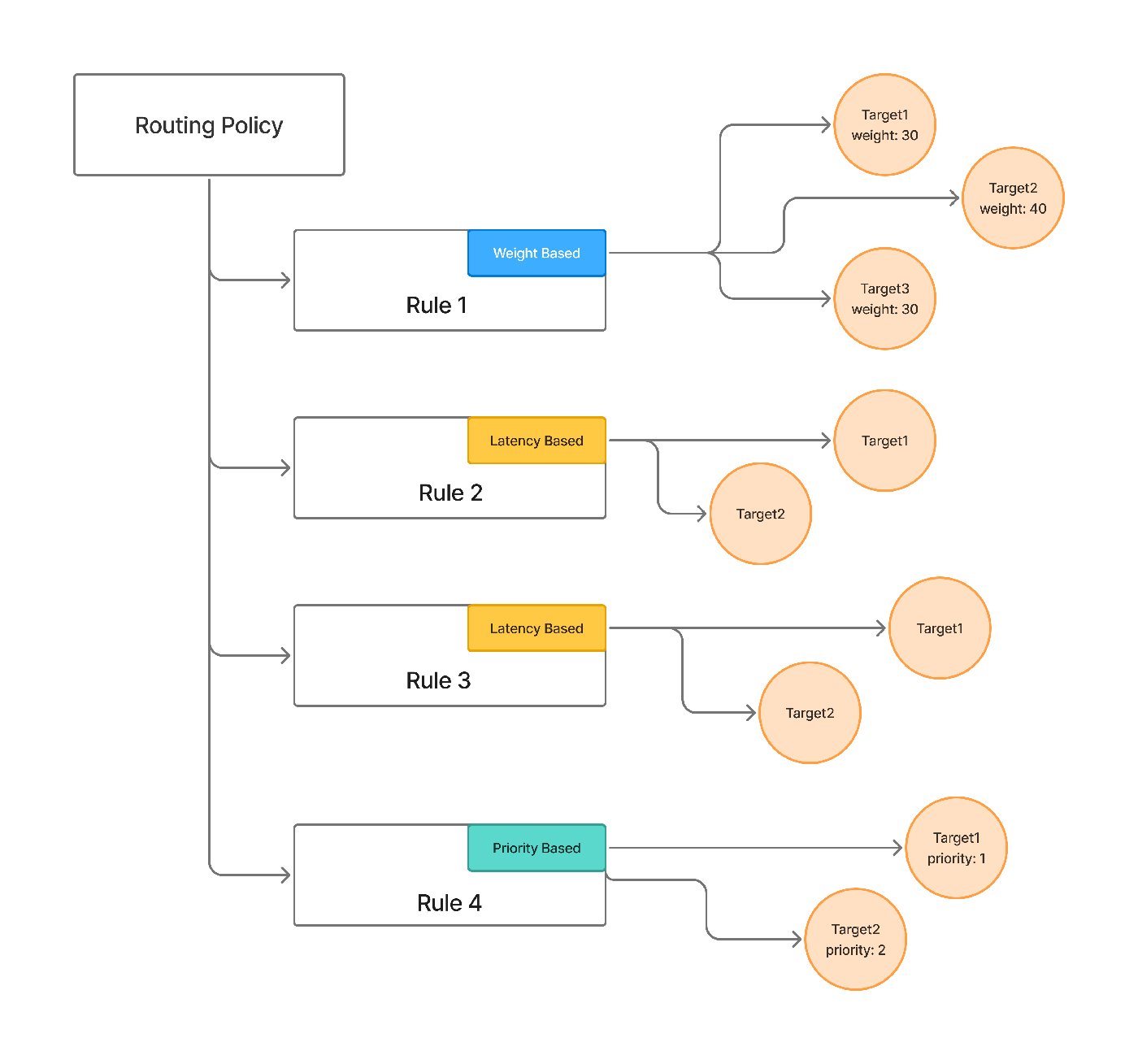
これらの要素は、以下の障害分類に対応しています。各ターゲットは独自の retry_config — 試行回数、遅延、リトライすべきステータスコード(デフォルトでは429/500/502/503)— を持ち、そして別の fallback_status_codes リストは、リトライが役に立たない場合にリクエストを次のターゲットに移動させます。 優先度ベースのルーティングは 順序付けられたフェイルオーバーチェーンを提供し、 レイテンシーベースのルーティング 最もレイテンシーの低い健全なターゲットを優先し、不健全なターゲットは1分あたりのリクエスト数、トークン数、失敗数から検出され、クールダウンのために一時的に除外されます。ドキュメントでは、セクション8で説明されているストリーミングの難しいケース、つまりプロバイダー固有のストリーム過負荷処理についても触れており、ユーザーにトークンが表示される前にフォールスルーが発生するようにしています。
OpenAI SDKをすでに使用しているアプリケーションからゲートウェイを呼び出すのは、同じクライアントでベースURLとキーが異なるだけなので、1行の変更で済みます。そのため、信頼性ポリシーはコードではなく設定に存在します。
# Calling the gateway from Python (OpenAI-compatible API)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-personal-access-token>", # Bearer-auth'd JWT
)
resp = client.chat.completions.create(
model="gpt-5.5", # the gateway resolves retries + fallback per the config
messages=[{"role": "user", "content": "Summarize the document."}],
)
print(resp.choices[0].message.content)本番環境のLLMアプリケーションは、制御できないインフラストラクチャに依存しています。プロバイダーは地域的および世界的な障害を抱え、レート制限を超過すると429エラーを返し(単に過負荷の場合もあります)、負荷がかかるとエラーを返さずにレイテンシーが低下します。直接統合すると、プロバイダーが単一障害点となり、ダウンしているパス以外に完了への道はありません。
これを解決する作業、つまりリトライ、フォールバック、ロードバランシング、サーキットブレーキングは、横断的なものです。モデルを呼び出すすべてのサービスにこれが必要であり、サービスごとに実装すると、それぞれが同じロジックを再実装し、互いに乖離してしまいます。その結果、エージェントチームのリトライポリシーと検索チームのリトライポリシーが微妙に異なり、どちらも微妙に間違っているという事態になります。ゲートウェイは、すべてのプロバイダーを認識し、すべてのキーを保持し、APIを単一の形式に正規化する唯一のコンポーネントです。これは、あるプロバイダーから別のプロバイダーへのフェイルオーバーにまさに必要なことです。信頼性を一元化することで、 TrueFoundryのAI Gateway 1つのポリシーが均一に適用され、フェイルオーバーイベントが他のテレメトリーと同じリクエストトレースに記録されることを意味します。
最も一般的な信頼性の誤りは、すべての障害を「エラー、リトライ」として扱うことです。異なる障害には異なる対応が必要であり、以下の表がその指針となります。これを誤ると、レート制限が障害に発展します。
最後の行は、チームが最も頻繁に誤解する点です。コンテンツフィルターによる拒否は、一時的な障害ではなく、リクエストの特性です。それをリトライすると時間と費用が無駄になり、別のプロバイダーにフェイルオーバーしても同じ拒否が発生することが多いため、サイレントにループさせるのではなく、リトライ不可として表面化させるべきです。別途、プロンプトを書き換えたり、ユーザーに明確化を求めたり、より安全なワークフローにルーティングしたりする修復パスがあるかもしれませんが、それはポリシーフローであり、フェイルオーバーではありません。ゲートウェイでこのテーブル(どのシグナルがリトライ、フォールバック、表面化にマッピングされるか)を一度エンコードすることで、各サービスはそれを再発明するのではなく、同じ分類を継承します。このマッピングを均一に適用することは、 TrueFoundryのAI Gateway が一元化する機能の一部です。
リトライは最初の防衛線であり、最も簡単に自分自身を攻撃する武器になり得ます。リトライを安全にするには3つのルールがあります。指数バックオフ(失敗するたびに長く待つ)、ジッター(クライアントが同時にリトライしないように待機時間をランダム化する)、そしてプロバイダーのレート制限ヘッダーを尊重することです。これは、送信される場合はRetry-After、または残り/リセットヘッダー(例: x-ratelimit-* )がプロバイダーの契約である場合(サーバーがいつ戻ってくるべきかを指示したら、それに従う)です。
それらが防ぐのは「サンダリング・ハード」現象です。プロバイダーが負荷の下で429を返し始め、すべてのクライアントが即座に同期してリトライすると、リトライ自体が過負荷を維持してしまいます。これは、復旧が必要なまさにその時にプロバイダーを釘付けにする、自ら招いたサービス拒否状態です。ジッターはリトライの同期を解除し、バックオフは時間とともに負荷を軽減し、Retry-Afterは、いつ容量が回復するかについてのプロバイダー自身のシグナルを尊重します。同様に重要なのは、成功しないものをリトライしないことです。不正な形式のリクエストやコンテンツフィルターによる拒否は、次の試行でも同様に失敗する4xxエラーであり、それをリトライしても、レイテンシーとコストが増えるだけです。
# Exponential backoff with jitter; honor Retry-After; cap attempts
for attempt in range(MAX_ATTEMPTS): # keep MAX small — 2–3 — then fall back
resp = call(provider, req)
if resp.ok:
return resp
if resp.status == 429 and resp.retry_after:
sleep(resp.retry_after) # respect the server's hint
elif resp.retryable: # 5xx, timeout
sleep(min(CAP, BASE * 2 ** attempt) * random.uniform(0.5, 1.0))
else:
break # non-retryable (4xx, content filter) — stop
raise Exhausted(provider) # hand off to the fallback chain
一貫したリトライポリシーは、各サービスが独自に持つと、とかく逸脱しがちなものです。 TrueFoundryのAI Gatewayに適用されると、バックオフ、ジッター、およびRetry-Afterの処理は、それを経由するすべてのサービスで統一され、リトライ後にフォールバックする境界は、5つのわずかに異なる動作ではなく、1つの設定された動作となります。
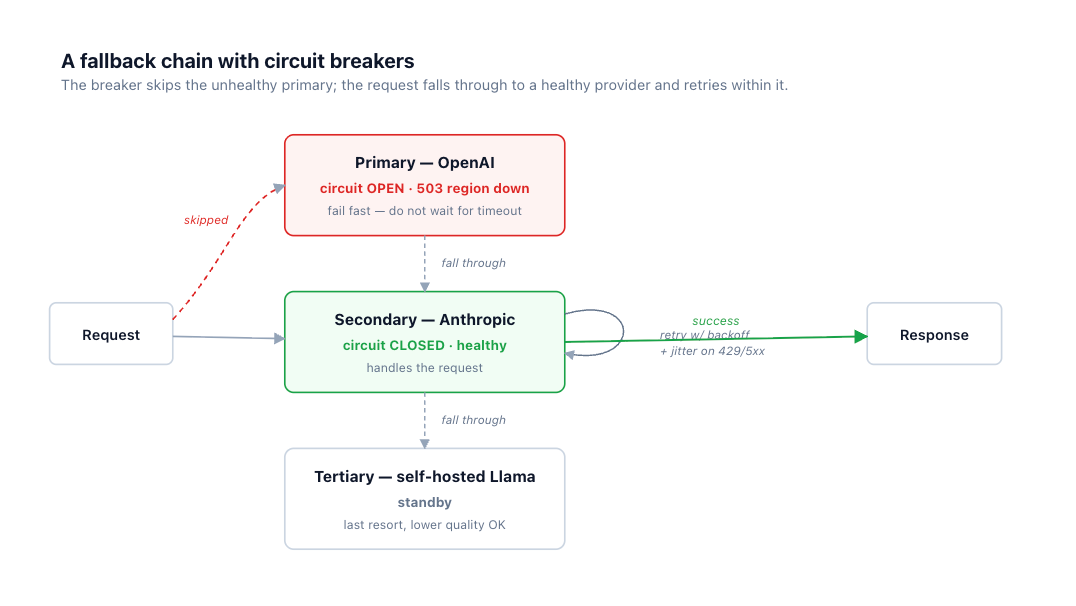
プライマリに対するリトライが尽きると、フォールバックチェーンがリクエストを維持します。プライマリ、次にセカンダリ、次にターシャリです。これには2つの軸があります。プロバイダー間(Claude、次にGPT、次にGemini)では、独立した障害ドメインが得られます。異なるインフラ、異なるインシデントであるため、セカンダリがプライマリと同じ理由でダウンしている可能性は低いです。プロバイダー内(代替リージョンまたはデプロイメント)は設定が安価ですが、障害ドメインを共有するため、プロバイダー全体の問題ではなく、局所的な問題から保護します。
フォールバックチェーンの例(概念図 — 正確なスキーマはゲートウェイ固有)
fallbacks:
- provider: openai/gpt-5.5
- provider: anthropic/claude-sonnet-4-6 # different vendor = independent failure domain
- provider: self-hosted/llama-3.x # last resort; lower quality acceptable to stay up
trigger_on: [5xx, timeout, circuit_open] # NOT content-filter rejections
これは単なるパターンではありません。 TrueFoundryのAI Gateway がどのように構成されているかを示しています。フォールバックチェーンは、優先度ベースのルーティングルールです。各ターゲットは優先度、独自のリトライポリシー、および次のターゲットへのフォールスルーをトリガーすべきステータスコードを持ちます。これは、1つのOpenAI互換APIの背後にあるホスト型モデルとセルフホスト型モデルにまたがり、アプリケーションが知ることなく、フォールバックが異なるベンダーまたは独自のモデルになることができます。
TrueFoundryが同じチェーンをどのように表現するか(gateway-load-balancing-config)
name: reliability-config
type: gateway-load-balancing-config
rules:
- id: chat-failover
type: priority-based-routing # ordered chain: priority 0, then 1, then 2
when:
models: [gpt-5.5]
load_balance_targets:
- target: openai/gpt-5.5
priority: 0
retry_config: { attempts: 2, on_status_codes: ["429","500","502","503"] }
fallback_status_codes: ["429","500","502","503"]
- target: anthropic/claude-sonnet-4-6 # different vendor = independent failure domain
priority: 1
- target: self-hosted/llama-3.x # last resort; lower quality OK
priority: 2ターゲット内でのリトライは retry_configを介して行われ、 fallback_status_codes がいつ諦めて次に進むかを決定します。ゲートウェイのリクエストレベルのビューは、どのターゲットが試行され、なぜフォールスルーが発生したかを記録するため、フェイルオーバーは推測ではなくデバッグ可能です。そして、重みベースおよびレイテンシーベースの戦略を含む完全なスキーマは、 ルーティング設定ドキュメント.
注目すべき2つ目のパターン、つまり、ほとんどの規制対象ワークロードが採用する、オンプレミスをプライマリとしクラウドをフォールバックとする構成も、同様に導入されます。
オンプレミスプライマリとクラウドフォールバック(ドキュメントより)
name: loadbalancing-config
type: gateway-load-balancing-config
rules:
- id: priority-failover
type: priority-based-routing
when:
models: [gpt-4]
load_balance_targets:
- target: onprem/llama
priority: 0
fallback_status_codes: ["429", "500", "502", "503"]
- target: bedrock/llama
priority: 1
retry_config:
attempts: 2
delay: 100内部では、フェイルオーバーシステムは保護対象よりも信頼性が高くなければなりません。そのため、ゲートウェイはすべてのレート制限、ロードバランシング、認証チェックを インメモリで、リクエストパス上に外部ホップを挟まず、ログとメトリクスをNATSキューを介して非同期で送信することで、ログパイプラインのダウンがライブリクエストの失敗につながることを防ぎます。公開されているベンチマークでは、1 vCPU / 1 GB RAMで350 RPSを達成し、200 RPSではトレーシングを有効にした場合でも約7ミリ秒のオーバーヘッドです。ゲートウェイプレーンはステートレスであり、コントロールプレーンが一時的に利用不能になった場合でも、最後に同期された設定からトラフィックを処理し続けます。これは、インシデント発生時に特に役立ちます。TrueFoundryはこれらの特性を truefailover™という、ゲートウェイ上に構築された障害耐性製品として提供しています。これは、上記のマルチモデルフェイルオーバーに加えて、マルチリージョン、マルチクラウド、および劣化認識ルーティング機能を追加します。
ロードバランシングには2つの役割があります。1つは、単一のバックエンドやキーがボトルネックにならないようにトラフィックを分散すること。もう1つは、健全でないバックエンドからトラフィックを遠ざけることです。一般的な戦略としては、重み付けラウンドロビン(容量に応じて分割)、最小遅延(最も高速で健全なバックエンドを優先)、最小負荷(処理中のリクエストが最も少ないバックエンドを優先)があります。
スループットに関して正しく理解すべき点があります。ヘッドルームは、追加のキーからではなく、独立したクォータプールから生まれます。個別のプロバイダー、デプロイメント、リージョン、または個別にプロビジョニングされたプロジェクトやアカウントはそれぞれ独自の制限を持つため、それらに負荷を分散することで真に容量が増加します。うまくいかないのは、同じ組織内でAPIキーを増やせばクォータが倍増すると考えることです。ほとんどのプロバイダーは、組織、プロジェクト、またはモデルファミリーレベルでレート制限を適用するため、1つの組織下のキーは1つのプールを共有します。(例えばOpenAIは、同じ組織内の追加キーでは制限が引き上げられず、一部のモデルファミリーはプールを共有すると述べています。)バランサーは、キーごとの仮定ではなく、プロバイダーのレート制限ヘッダーで報告される実際の残りの容量に基づいてルーティングすべきです。ヘルスチェックには2種類あります。アクティブ(各バックエンドを定期的にプローブする)とパッシブ(実際のトラフィックを監視し、エラー率がしきい値を超えたときにバックエンドを異常とマークする — これは次のセクションで説明するサーキットブレーキングです)です。パッシブはより安価であり、実際のリクエストが遭遇する状況を反映します。プロバイダーとキーをまたいだバランシングは、 TrueFoundryのAIゲートウェイの主要な機能です。これは、バランサーが必要とするキーをすでに保持しており、バックエンドごとの遅延とエラー率を把握しているため、それを行うのに最適な場所です。
プロバイダーがダウンしているときにトラフィックを送り続けることは、積極的に有害です。すべてのリクエストはタイムアウトするまで待機してから失敗し、その待機中のリクエストが積み重なり、キューが詰まり、プロバイダーの障害が自社のレイテンシーとリソース枯渇に波及します。サーキットブレーカーは、高速に失敗することでこれを防ぎます。
これは小さなステートマシンです。 クローズ は通常動作です。エラーがあるしきい値(ある期間における高いエラー率、またはN回の連続した失敗)を超えると、ブレーカーはトリップして オープンになります。そのプロバイダーへのリクエストは、タイムアウトを待つことなく即座に失敗します(または直接フォールバックにスキップします)。クールダウン後、 ハーフオープン に移行し、単一のプローブ要求を通過させます。プローブが成功すれば、ブレーカーはクローズし、通常のトラフィックが再開されます。失敗すれば、ブレーカーは再度オープンし、別のクールダウン期間に入ります。その結果、ダウンしたプロバイダーは、完全なタイムアウト1回ではなく、リクエストごとに1回の高速な拒否で済むようになります。これは、クリーンなフェイルオーバーと連鎖的な速度低下との違いです。
サーキットブレーカー — 障害が発生しているプロバイダーへの送信を停止する
if breaker.state == "open":
if breaker.cooldown_elapsed():
breaker.state = "half_open" # probe with one request
else:
raise SkipProvider # fail fast → fall through to the chain
resp = call(provider, req)
breaker.record(resp) # closes on success, re-opens on failed probe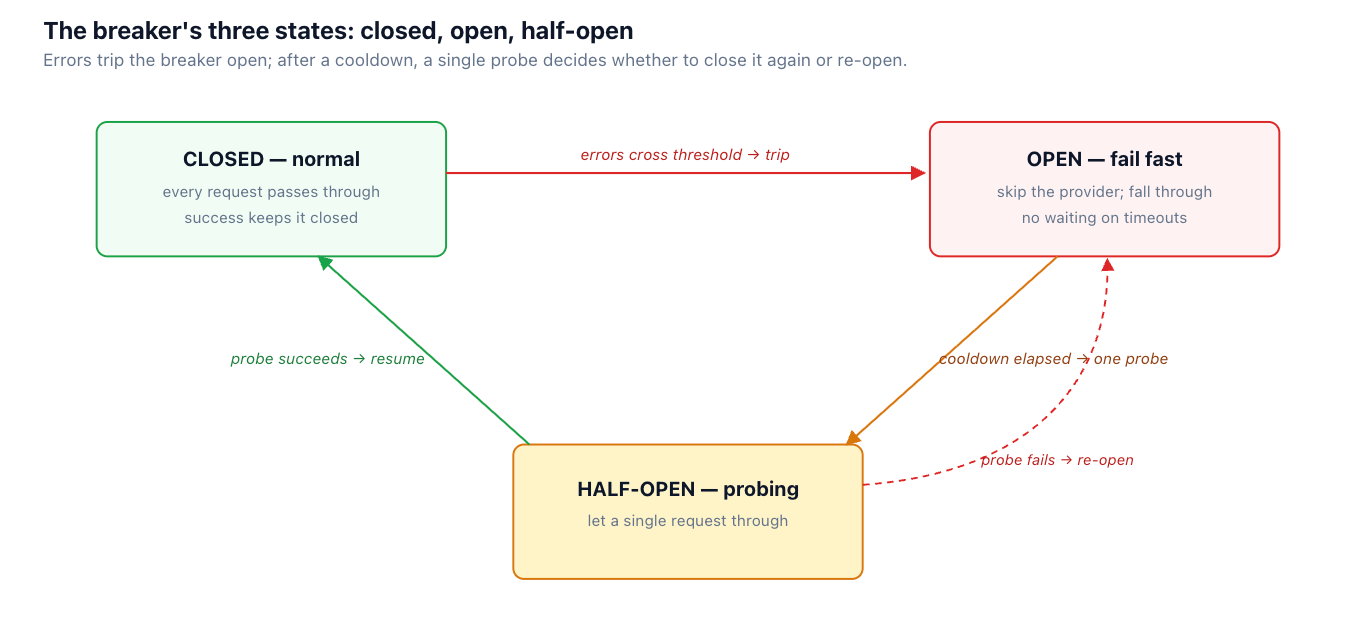
前述のフォールバック図のように、プライマリのブレーカーは503エラーが連続した後にオープンになるため、リクエストは待機することなくそれをスキップします。 TrueFoundry's AI Gateway のヘルスアウェアなルーティングは、これをプロバイダー全体に適用するため、異常なバックエンドは、各サービス内でリクエストごとに再発見されるのではなく、ゲートウェイでバイパスされます。
信頼性の問題の中には、障害ではなく「テール」に起因するものがあります。ほとんどのリクエストは高速ですが、p99が遅いのは、一部のリクエストがたまたまプロバイダーの処理が遅いタイミングに当たってしまうためです。ヘッジングはこのテールに対処します。短い遅延の後、同じリクエストを2番目のプロバイダーに送信し、最初に返ってきた応答を採用します。これにより、個々の呼び出しにおいて単一プロバイダーの最悪のレイテンシーに縛られることがなくなるため、遅いテールが解消されます。
コストは現実的であり、明確に述べる価値があります。ヘッジが発動すると、2回の呼び出しに対して料金が発生します。勝者が戻ったら敗者をキャンセルするべきですが、キャンセルによって無料になるとは限りません。プロバイダーや生成の進行状況によっては、キャンセルされた呼び出しでも部分的なトークンに対して課金される可能性があるため、両方の試行を追跡すること。これを手頃な価格に抑える方法は、レイテンシープロファイルに合わせて調整された遅延(例えばp95付近)の後でのみヘッジを発動させることです。これにより、すべてのリクエストではなく、遅いテールのみをヘッジします。2つの注意点があります。呼び出しが冪等でない場合、ヘッジングは副作用を重複させる(純粋な完了処理では問題ないが、ツール呼び出しエージェントでは考慮すべき点)こと、そしてプロバイダーに負荷を追加するため、これはテールレイテンシー対策ツールであり、デフォルトではないことです。ヘッジングは、ロードバランシングと同様の理由で、当然ながらゲートウェイの懸念事項です。ゲートウェイはすでに両方のプロバイダーを認識しており、2番目の呼び出しを発動して調整できるため、フォールバックやロードバランシング制御と並んで、ルートごとのポリシーとして位置づけられるべきです。 TrueFoundry's AI Gateway がすでに一元化している、サービスごとの特注コードとしてではなく。
これらの制御のいずれも普遍的な値を持つわけではありませんが、盲目的にコピーすべき設定ではなく、調整するための妥当な出発点があります。
上記はすべて、リクエストをきれいに再試行またはリダイレクトできることを前提としています。ストリーミングはその前提を崩します。ユーザーにすでに200トークンをストリーミングした後にストリームが停止した場合、透過的にプロバイダーを切り替えることはできません。新しいプロバイダーは最初から開始するため、表示される出力を再開するか(不自然)、2つのモデルの出力をつなぎ合わせるか(一貫性がない)のどちらかになります。決定的な解決策はありません。
現実的な選択肢には、いくつかのトレードオフが伴います。ストリームをサーバー側でバッファリングし、完了または検証されてからリリースする方法があります。これによりフェイルオーバーはクリーンになりますが、そもそもストリーミングを選んだ理由である知覚されるレイテンシーのメリットは失われます。ストリーム途中の障害による再開を受け入れ、それを許容するUXを設計することもできます。あるいは、重要なパスでは、ストリームを開始する前に、ストリーミングではない最初のトークンでプロバイダーが稼働していることを確認できます。これは、コンテキストエンジニアリングとPIIに関する投稿でのストリーミングに関する議論が別の方向から提起したのと同じ緊張関係です。ストリーミングは、レイテンシーのために回復性と事後制御を犠牲にします。ストリーミングフェイルオーバーは、グローバルな設定ではなく、パスごとの意図的な決定として扱ってください。内部のバッチエージェントにとっての最適な答えは、顧客対応チャットの場合とは異なります。その選択はパスごとに行われるため、他のルートごとのポリシーが存在する場所に属します。つまり、ルートごとの設定の種類です。 TrueFoundryのAIゲートウェイ 一元化するため、チャットパスとバッチパスが1つの設定の下で異なるバッファリング選択を行うことができます。
プロバイダー間フォールバックか、プロバイダー内フォールバックか?
両方とも、順序立てて行います。プロバイダー内(代替リージョン/デプロイ)は安価で局所的な問題を処理しますが、障害ドメインを共有するため、プロバイダー全体にわたるインシデントが発生すると、ティア全体が停止します。プロバイダー間は独立した障害ドメインを提供し、冒頭で述べたような障害からあなたを救います。ただし、異なるモデルからサービスを提供することになるため、出力のばらつきが大きくなるという代償が伴います。堅牢なチェーンは通常、まず代替デプロイメントを試行し、次に異なるベンダーに切り替えます。
別のモデルにフォールバックすると、出力は変わらないのですか?
はい、それがセクション4で述べたトレードオフです。フォールオーバーは、フォールバックモデルが異なる形式で応答し、拒否し、推論するため、忠実度を犠牲にして可用性を確保します。フォールバックの出力をプライマリと同じスキーマで検証してください(特に構造化された応答の場合)。また、フォールバックがプライマリ専用に調整されたプロンプトから開始しないように、プロンプトをポータブルに保ってください。
再試行は何回設定すべきですか?
少ない回数で、通常は2回か3回です。指数関数的バックオフ、ジッター、およびRetry-Afterヘッダーを尊重して行います。実際にダウンしているプロバイダーに対して再試行を増やしても、成功するはずだったフォールバックを遅らせるだけであり、プロバイダーが苦戦しているまさにその瞬間に負荷を増やしてしまいます。目標は、一時的な障害を乗り切り、その後引き継ぐことであり、ダウンしたエンドポイントを叩き続けることではありません。
すべてのリクエストをヘッジすべきですか?
いいえ。すべてをヘッジすると、プロバイダーのコストと負荷が2倍になります。ヘッジは、p95付近に調整された遅延の後でのみ発動し、テールレイテンシーが実際に問題となるパスでのみ使用してください。非冪等な呼び出しの場合、注意が必要です。ヘッジによって副作用が重複する可能性があります。
これはアプリケーションに置くべきですか、それともゲートウェイに置くべきですか?
ゲートウェイです。ゲートウェイはすべてのプロバイダーとキーを認識し、APIを正規化することで、アプリケーションの変更なしにフォールバック先を異なるベンダーにすることができます。また、すべてのサービスにわたって一貫した再試行/フォールバック/サーキットブレーカーポリシーを適用できます。サービスごとの実装はばらつき、同じロジックが重複します。ゲートウェイはフェイルオーバーイベントもトレースするため、「プライマリが開いていたためフォールバックした」ということが推測ではなく可視化されます。これは、このシリーズの以前のコストと可観測性に関する作業につながります。
ナディアの障害は、より良いプロバイダーを必要としたのではなく、2つ目のプロバイダーとそれを使用するためのポリシーを必要としていました。LLMトラフィックの信頼性は、他の依存関係と同じ規律です。サーバーを尊重する再試行、独立した障害ドメインをまたぐフォールバック、高速に失敗するサーキットブレーカーといったものが、すべてのプロバイダーを一度に認識するレイヤーで適用されます。
TrueFoundryのAIゲートウェイ は、アプリケーションと1,600以上のモデル(OpenAI、Anthropic、Google、AWS Bedrock、Azure OpenAI、および自社ホスト型モデルを含む)の間に位置するエンタープライズグレードのコントロールプレーンであり、単一のOpenAI互換APIの背後にあります。これにより、この投稿で述べた信頼性パターンが、サービスごとのコードではなく設定に変換されます。フォールバックチェーン、重み付けおよびレイテンシーベースのロードバランシング、再試行、ヘルスアウェアルーティングなど、すべて一度定義すればすべてのリクエストに適用されます。
ゲートウェイはキーを保持し、すべてのプロバイダーを正規化し、リクエストごとのコスト、レイテンシー、エラー、フォールバックのテレメトリーを記録するため、フェイルオーバーを自動化し、監視可能にするのに最適な場所です。SaaSとして、VPC内、オンプレミス、またはエアギャップ環境にデプロイ可能で、RBAC、予算、レート制限、ガードレールが組み込まれています。SOC 2、HIPAA、ITARに準拠しており、GartnerのAIゲートウェイ市場ガイドにも掲載されています。信頼性機能については、 ロードバランシングとフォールバックのドキュメント または AIゲートウェイの概要をご覧ください。
NorthwindとNadiaは例示です。障害モードの分類、リトライ、フォールバック、ロードバランシング、サーキットブレーカーのパターンは、LLMトラフィックに適用される標準的な信頼性エンジニアリングです。2〜3回のリトライ、p95付近でのヘッジといった具体的な数値は、あくまで代表的な出発点であり、普遍的な設定ではありません。ご自身のトラフィック、SLO、プロバイダーの制限に合わせて調整してください。レート制限の余裕は、独立したクォータプール(個別のプロバイダー、プロジェクト、またはアカウント)から得られるものであり、単一組織内の追加キーから得られるものではありません。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。




.webp)




.png)








.webp)
.webp)


