July 25, 2026
|
5 min read

Published: January 22, 2026
Blazingly fast way to build, track and deploy your models!
AI outages are happening more frequently, and they hit production systems hard. truefailover is our new resilience feature that automatically routes around model outages, regional failures, and API degradation so your AI applications stay online.
In November 2025, a Google Meet outage disrupted meetings, interviews, and customer calls across the globe. An AWS outage in October 2025 impacted thousands of production systems that depend on cloud infrastructure. Weeks later, a Cloudflare outage in November 2025 caused widespread instability across the internet. And in January 2026, an outage affecting Anthropic’s Claude AI directly stalled AI-powered workflows inside enterprises.
What’s notable isn’t just that these outages happened — it’s where they happened. These were core building blocks that modern applications assume will always be available. For teams running AI in production, these incidents translated into halted workflows, missed SLAs, support queues backing up, and customers left in the lurch.
We built truefailover because “the model is down” is no longer an acceptable failure mode.
Most AI applications today are tightly coupled to a single model, a single provider, or a single region. When that dependency fails — or even slows down — the application fails with it.
This is especially risky because AI outages are rarely clean. They often show up as:
From the outside, the system looks “up,” but users experience timeouts, inconsistent responses, or broken flows.
As Nikunj Bajaj, Co-Founder and CEO of TrueFoundry, explains: “Too many teams have architected for capability, not continuity. They pick the best model on paper, but never ask what happens when it’s unavailable at 3 p.m. on a Tuesday.”
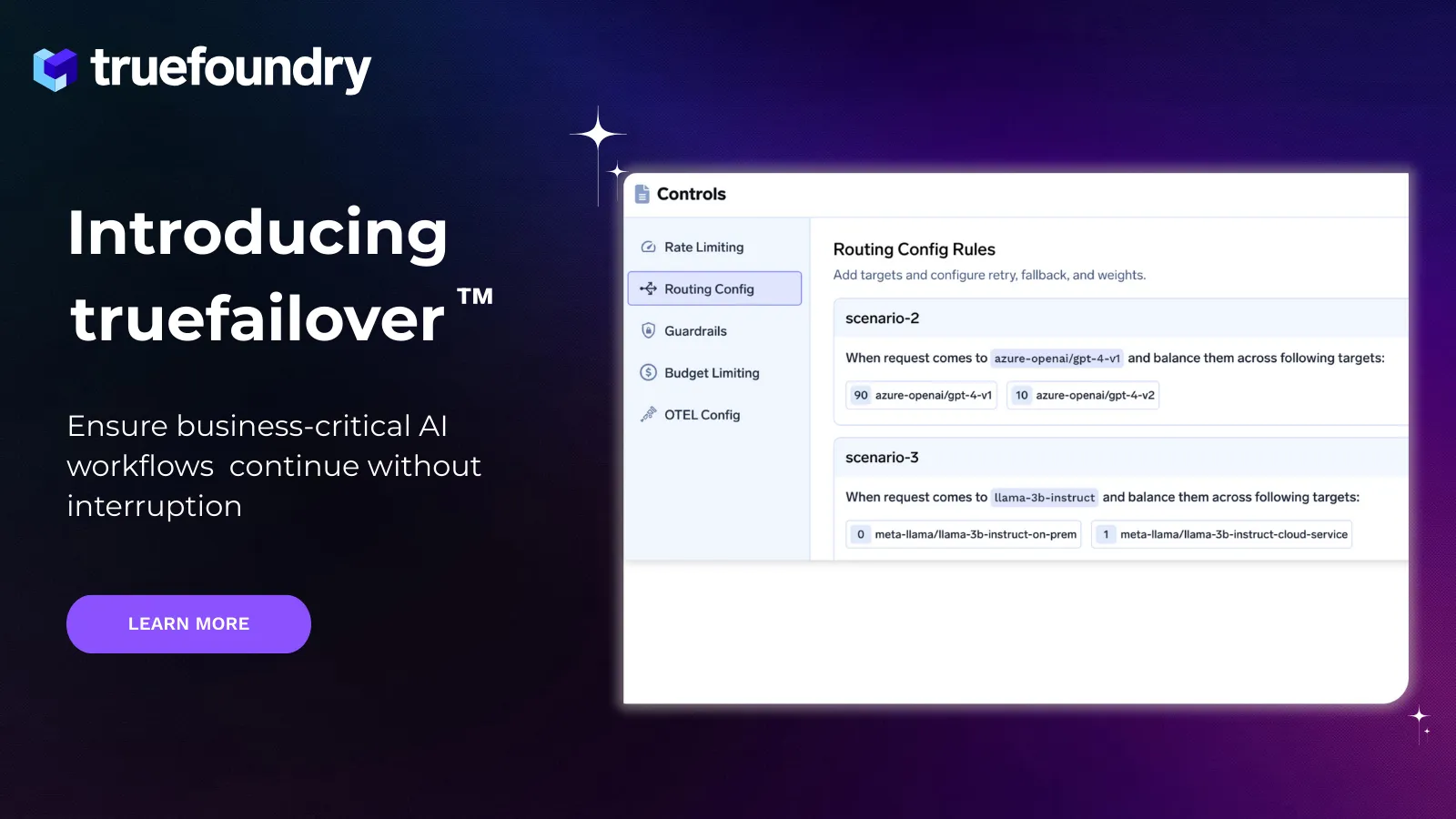
truefailover is a dedicated outage-resilience module built into the TrueFoundry AI Gateway.
It sits between your applications and the AI providers they depend on, continuously monitoring health signals and making real-time routing decisions. When a model, region, or provider becomes unhealthy, traffic is automatically shifted to a healthy alternative — without requiring application teams to change code or intervene manually.
Instead of outages becoming incidents, they become routing events.
At its core, truefailover combines multi-model, multi-region execution with health-aware routing.
Teams define a primary execution path (for example, a preferred model or region) along with one or more fallbacks. truefailovercontinuously evaluates latency, error rates, and other health signals across these options. When conditions degrade beyond acceptable thresholds, traffic is rerouted automatically. This happens fast enough that end users never see the failure.
The following capabilities make this possible:
1. Multi-model failover across providers
truefailover lets you configure fallback models across providers such as OpenAI, Anthropic, Gemini, Groq, Mistral, or self-hosted models. If a primary model is unavailable, rate-limited, or degraded, requests seamlessly flow to the next best option.
This is especially important for customer-facing AI, where “the model is down” is not an acceptable response.
2. Multi-region and multi-cloud resilience
truefailover supports running AI endpoints across regions and clouds, with health-based routing that diverts traffic away from failing zones. Regional outages are isolated instead of cascading globally, while users continue to receive low-latency responses.
3. Degradation-aware routing
Not all failures are binary. truefailover reacts to slowdowns and partial failures — not just hard outages — preventing the “technically up but unusable” scenarios that quietly destroy user experience and SLAs.
4. Built-in observability and traceability
Every routing decision is observable. Teams can see where failures originated, how traffic shifted, and which models absorbed load. This makes incident analysis faster and gives platform teams confidence that failover actually worked.
5. Caching and rate protection
During upstream instability or traffic spikes, truefailover uses strategic caching and rate protection to prevent cascading failures. This allows systems to ride out provider limits and demand surges without sudden brownouts.
truefailover will be available as an add-on resilience module on the TrueFoundry AI Gateway and platform. We’ll be opening an early access program for design partners soon, with broader availability to follow.
If you’re interested in getting early access, you can get in touch with us here.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox

.webp)