













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
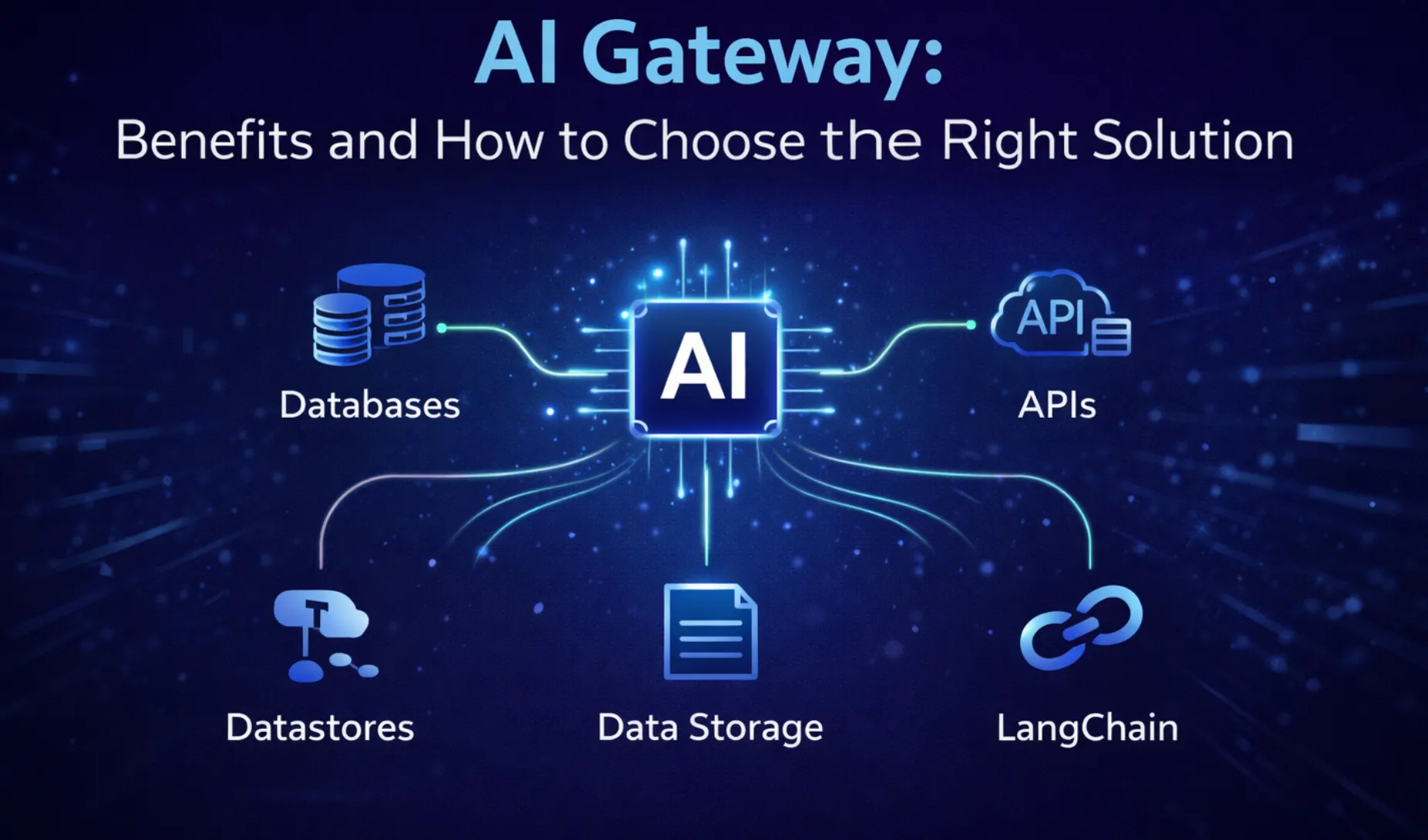
An AI Gateway is an abstraction layer that unifies access to multiple Large Language Models (LLMs) through a single API interface. It provides a consistent, secure, and optimized way to interact with models across providers such as OpenAI, Anthropic, Cohere, Together.ai, or open-source models like Mistral and LLaMA deployed on your own infrastructure.
At its core, an AI Gateway handles the heavy lifting of integrating, routing, authenticating, and monitoring LLM usage across different endpoints. Instead of dealing with multiple SDKs, authentication tokens, rate limits, and pricing models for each provider, teams route all model requests through the Gateway. This streamlines development and enables governance at scale.
TrueFoundry's AI Gateway is built for enterprise-grade performance and observability. It allowsteams to:
In addition, the Gateway supports streaming and non-streaming modes, tool calling (function calling), prompt templating, and tagging for team-level cost breakdowns. With built-in observability, TrueFoundry enables tracking of not just latency and token usage but also user-specific access, traffic trends, and per-endpoint performance.
As LLM usage grows across teams, use cases, and environments, an AI Gateway becomes the foundation for operationalizing generative AI in production. It provides control, visibility, and optimization across the entire lifecycle of LLM interactions.
The increase in AI gateways is mainly in response to growing complexity. Most teams no longer use a single model from one provider. They are testing multiple models, balancing performance with cost, and supporting different use cases across teams. Without an abstraction layer, this situation can quickly become fragile and hard to manage.
Cost pressure has also had a significant impact. As AI usage grows, token consumption and latency shift from being technical issues to business concerns. AI gateways enable teams to route traffic smartly, enforce budgets, and gain insights into actual spending.
Governance is another important factor. As systems handle more sensitive data and regulated workflows, organizations require stronger controls over access, auditing, and compliance. A gateway serves as a natural point for enforcing those policies.
Also Read: OpenRouter vs AI gateway
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

An AI Gateway brings a structured and scalable approach to managing LLM usage across teams and environments. Below are the key features that make it essential for modern GenAI workflows:
Unified Access: AI Gateways offer a single API interface to access multiple LLMs across vendors like OpenAI, Anthropic, or in-house models. This eliminates the need to manage individual APIs, SDKs, or keys for each provider.
Authentication and Authorization: AI Gateways enforce secure access through centralized key management. Developers receive scoped API keys while root keys remain protected, integrated with secret managers like AWS SSM, Google Secret Manager, or Azure Vault.
Role-Based Access Control (RBAC): Ensures that only authorized users can access specific models or actions, aligning with enterprise security standards.
Performance Monitoring: Track latency, error rates, and token throughput for each model endpoint. This helps detect issues early, optimize routing, and maintain SLAs.
Usage Analytics: Detailed logs and dashboards show who used which model, when, and how, offering transparency across projects and enabling cost attribution per user, team, or feature.
Cost Management: Gateways track token-level usage and associate costs with users, teams, or endpoints. This provides clear visibility into spend patterns and helps prevent cost overruns.
API Integrations: Support for external APIs and tools such as evaluation pipelines, prompt guardrails, or vector databases enables seamless integration with broader AI/ML ecosystems.
Custom Model Support: Users can bring their own fine-tuned or proprietary models into the Gateway, routing traffic alongside commercial models.
Caching: Store and reuse identical or similar LLM responses to save tokens and reduce latency.
Routing and Fallbacks: Intelligent request routing based on latency, cost, or reliability. Includes fallback mechanisms and auto-retries to improve resiliency.
Rate Limiting and Load Balancing: Supports user-level quotas, rate limiting, and load balancing across model providers for optimal throughput and stability.
Evaluating the best AI gateway requires a comprehensive assessment of its capabilities across access control, model integration, observability, and cost governance. A robust AI Gateway should simplify model usage while ensuring scalability, performance, and security for production-grade applications.
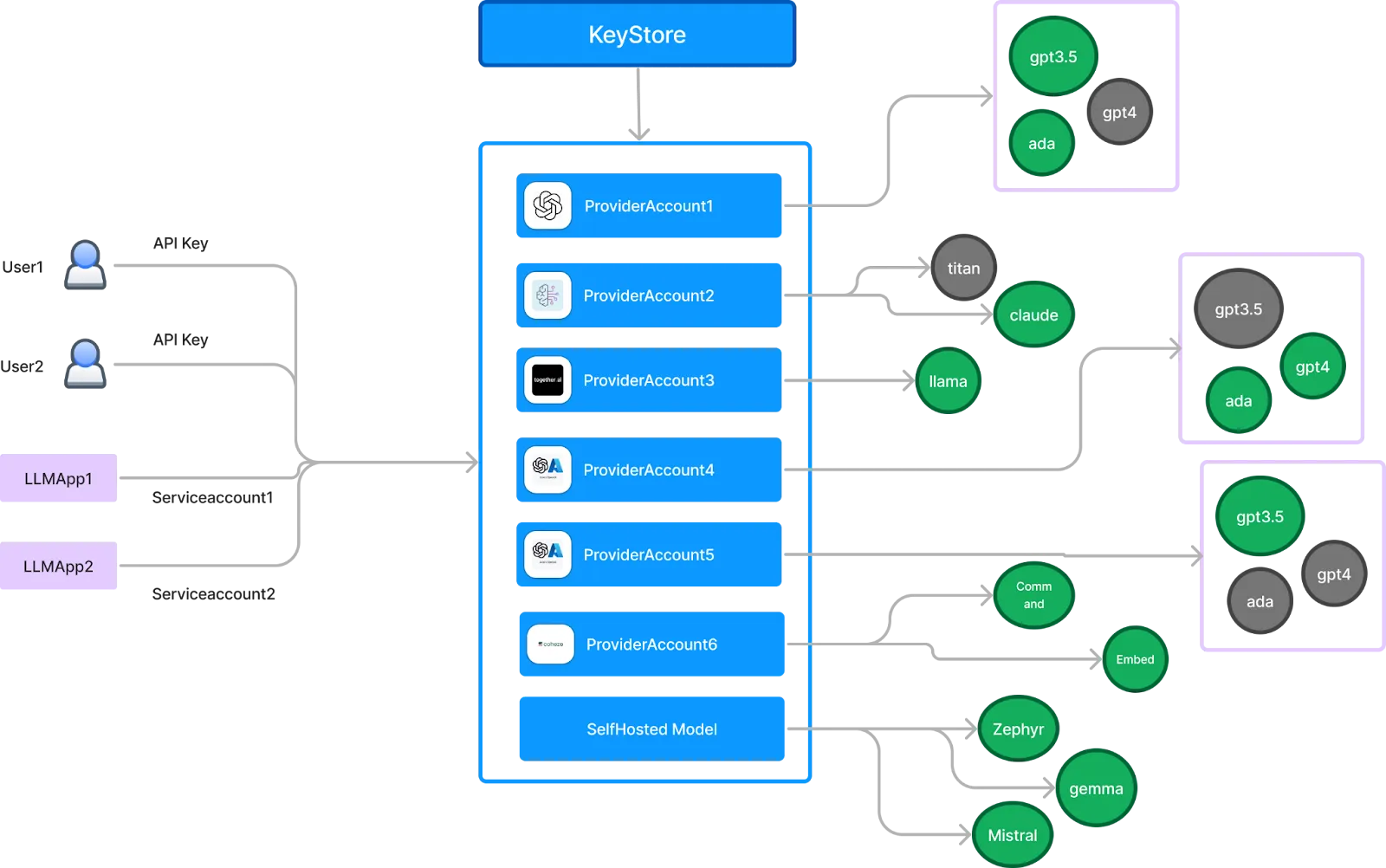
A strong AI Gateway centralizes API key management by issuing individual keys to each user or service while safeguarding root keys using secret managers like AWS SSM, Google Secret Store, or Azure Vault.
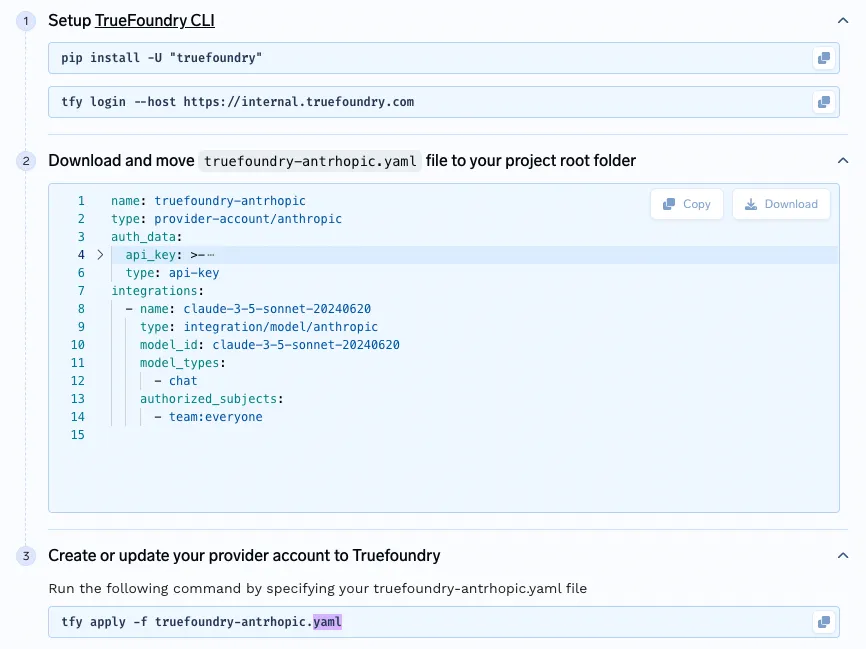
TrueFoundry’s Gateway allows administrators to manage fine-grained access to all integrated models, whether self-hosted or third-party, via a unified admin interface. Access control configurations are tracked in versioned YAML files, ensuring auditability and compliance.
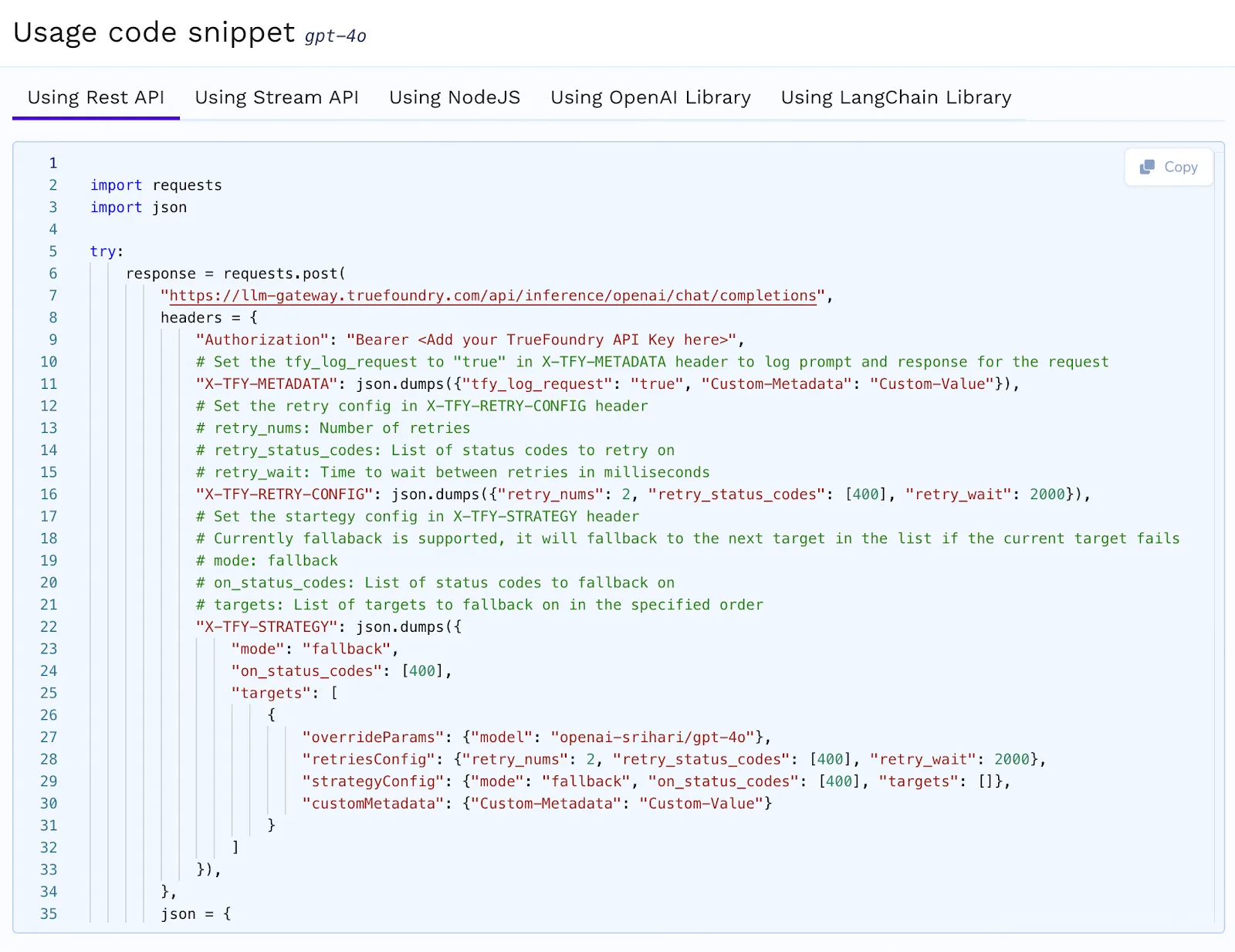
The AI Gateway should offer a standardized interface for interacting with multiple models. TrueFoundry follows the OpenAI request-response format, making it compatible with LangChain and OpenAI SDKs. Developers can switch between models without modifying their code. TrueFoundry also provides auto-generated code snippets for different providers and programming languages, simplifying integration.
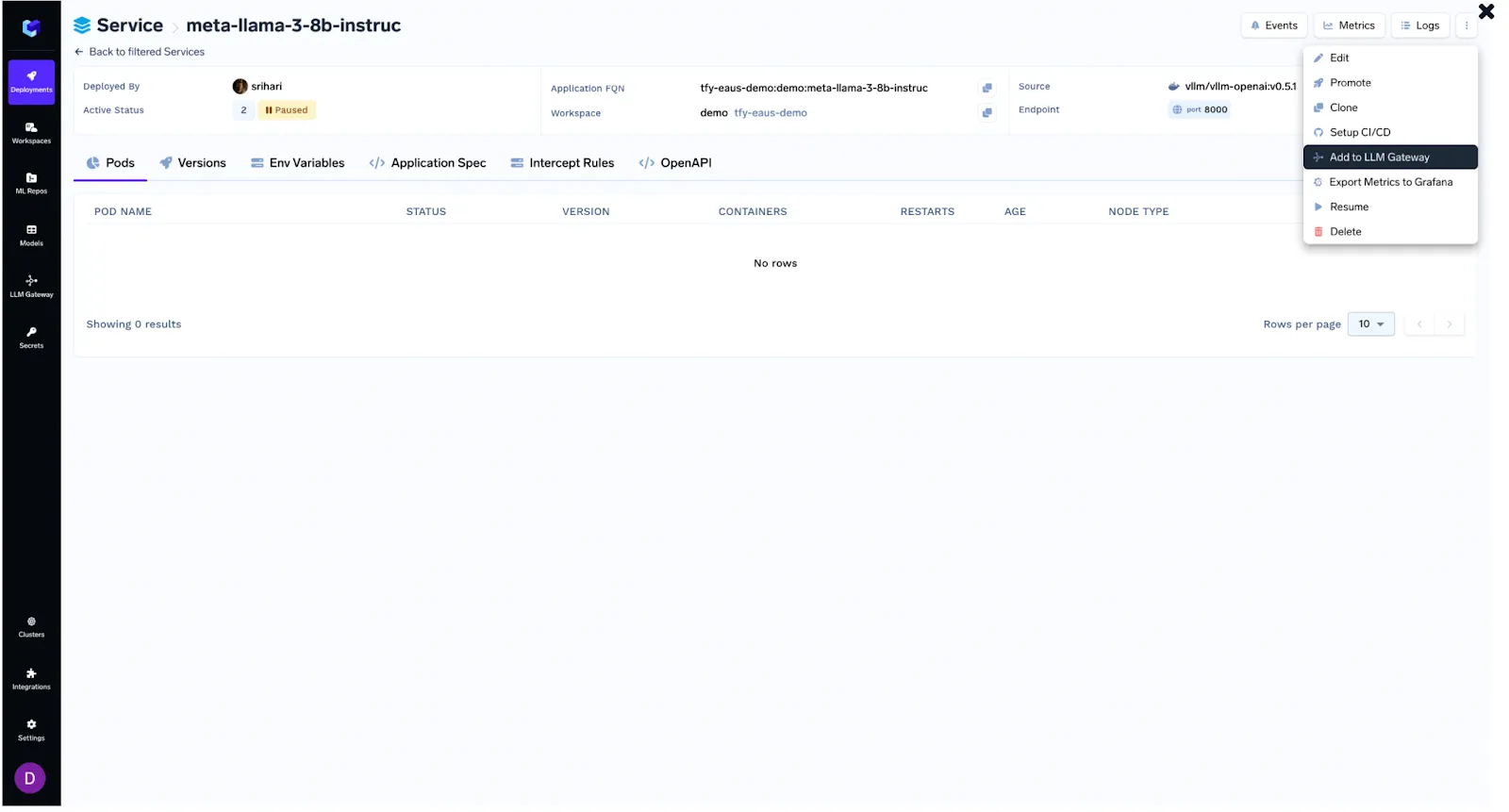
TrueFoundry supports three key routes for model access: third-party providers (like OpenAI, Cohere, AWS Bedrock, and Anthropic), self-hosted open-source models (deployed via HuggingFace or custom infrastructure), and TrueFoundry-hosted models shared across clients. This flexibility enables teams to mix and match models based on use case, budget, or latency requirements.
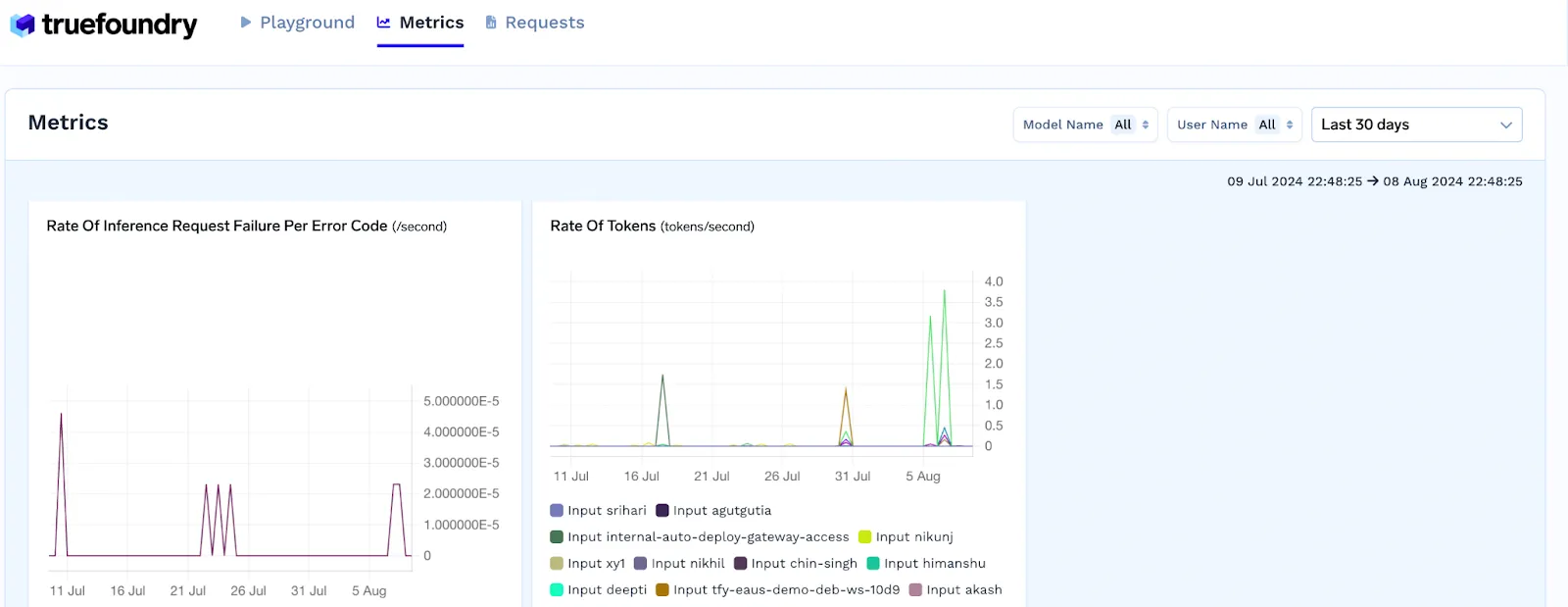
To ensure reliability, the Gateway should monitor latency, error rates, throughput, and inference failures. TrueFoundry captures key metrics like request latency, rate of tokens, and rate of inference failures, making it easy to identify performance bottlenecks through real-time dashboards.
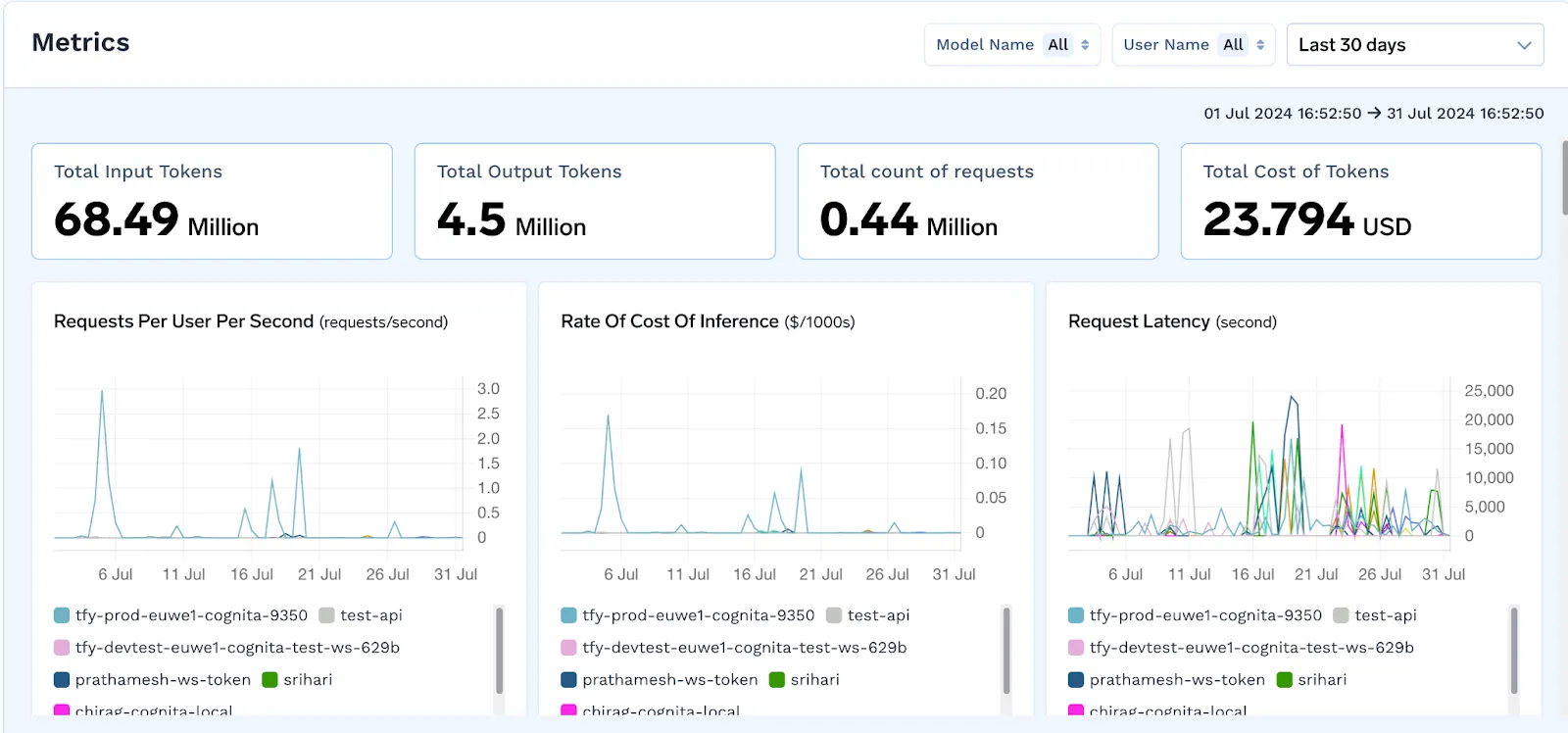
Understanding how, when, and by whom models are used is critical for governance. TrueFoundry logs detailed request and response activity, token consumption, and cost per model. These insights help teams manage workloads and optimize usage patterns.
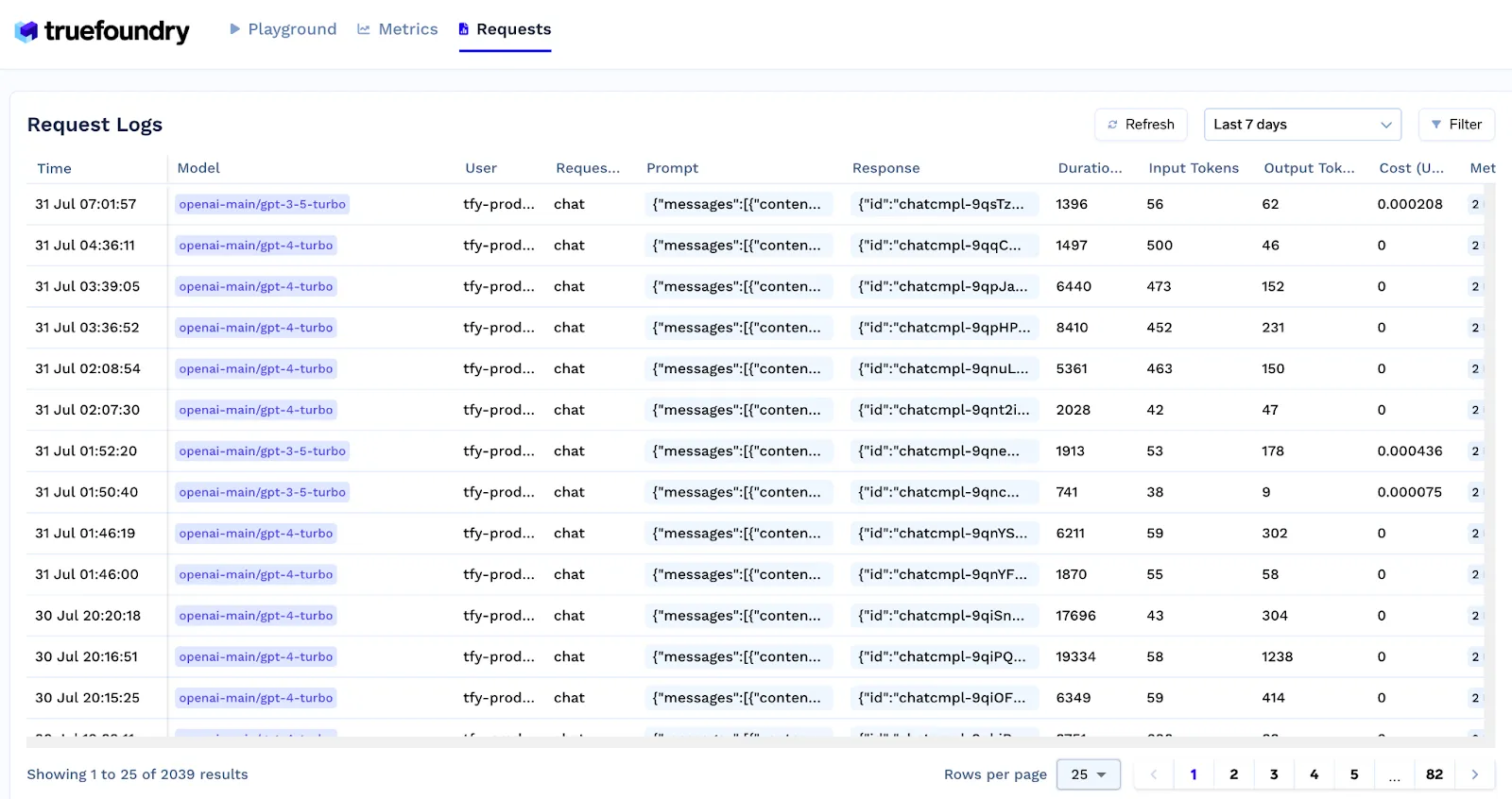
The Gateway should log costs from all model interactions, whether hosted internally or through commercial APIs. TrueFoundry provides full visibility into model usage costs across users, teams, and projects. Integrated dashboards allow organizations to track spend, configure alerts, and apply rate limits or budget caps to control overages.
Advanced features in an AI Gateway determine how effectively it can operate in real-world, production-scale environments. TrueFoundry’s AI Gateway brings a rich set of capabilities that optimize performance, improve reliability, and seamlessly integrate with broader systems, making it enterprise-ready from day one.
Caching helps reduce latency and save costs by avoiding redundant model calls. TrueFoundry supports both exact match caching (for identical prompts) and semantic caching (for similar meaning queries), which enhances speed without compromising on relevance. You can configure cache expiration policies and manually invalidate outdated entries when needed. This ensures that the gateway serves fast, accurate, and up-to-date responses.
For production-critical applications, the gateway automatically routes traffic to alternative models if the primary one fails, ensuring uninterrupted service. Automatic retries help recover from transient errors without user intervention. Built-in rate limiting helps enforce quotas and prevent overuse, while load balancing distributes traffic across multiple models or providers to maintain optimal throughput and minimize latency.
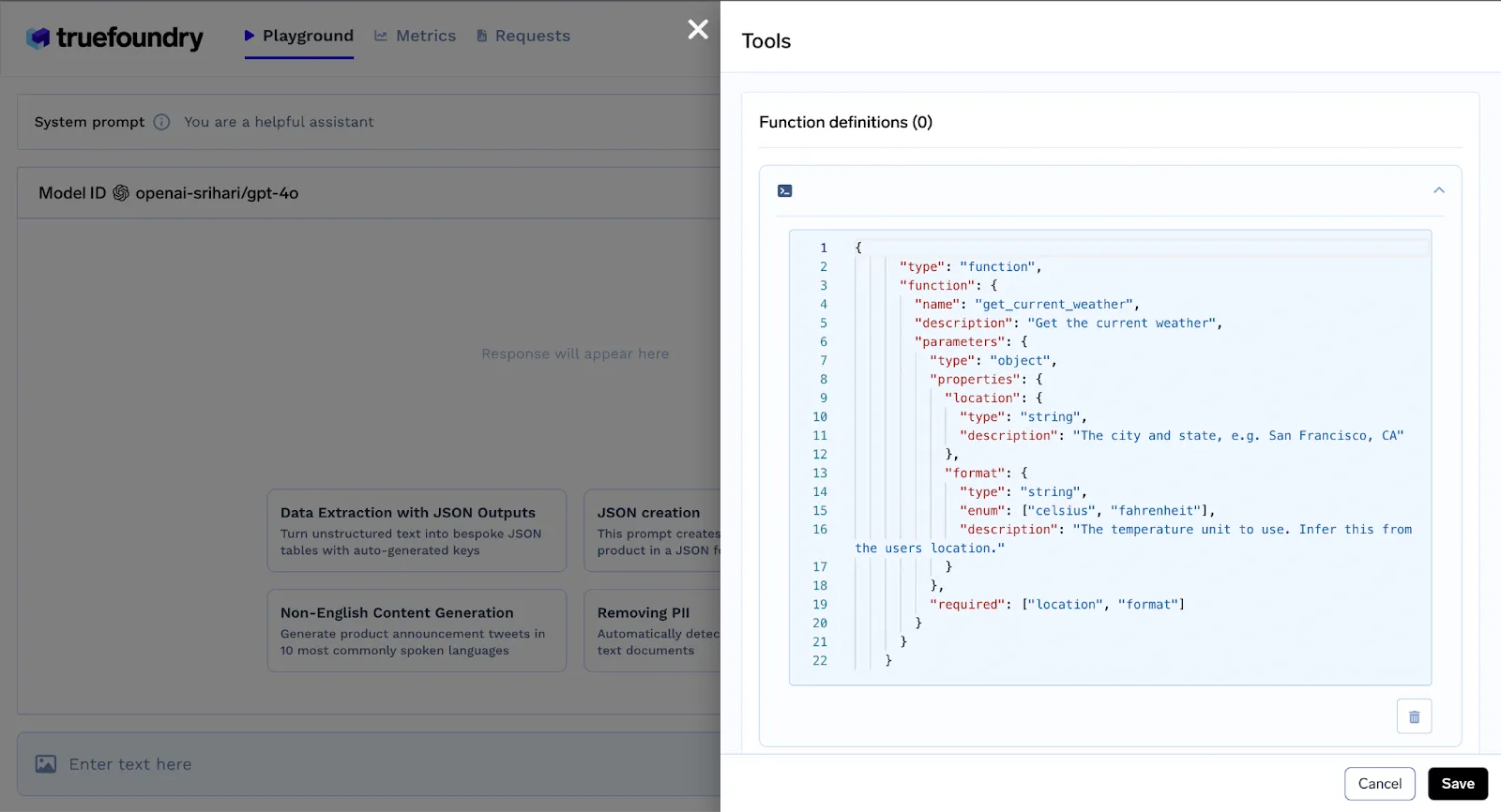
TrueFoundry’s Gateway supports tool calling by simulating interactions with external APIs. While the actual function is not executed by the gateway, the model can return structured outputs representing the intended tool call. This is ideal for building workflows where LLMs need to decide when and how to invoke tools, enabling developers to design and test these behaviors safely.
Modern applications often involve more than just text. The Gateway supports multimodal inputs such as text and images within the same request, which unlocks use cases like document Q&A, visual search, or customer support enriched with screenshots or product photos. This makes the AI Gateway suitable for both traditional NLP and next-gen AI applications that require context from multiple data formats.
TrueFoundry enables deep integration with your existing stack. You can plug in observability tools like Prometheus and Grafana for real-time monitoring, implement safety layers using Guardrails AI or NeMo Guardrails, and evaluate model quality continuously using Arize or MLflow. This connected ecosystem ensures that your AI system is not just performant, but also safe, transparent, and continuously improving.
An AI Gateway delivers significant operational, financial, and engineering advantages for organizations integrating large language models (LLMs) into their products and workflows. It acts as a control plane for AI consumption, providing a consistent interface, enforcing security, and optimizing performance at scale.
一元化されたアクセスとガバナンス
複数のチームやアプリケーションが異なるLLMプロバイダーと連携する場合、個別のキー、トークン、アクセス権の管理は複雑になりがちです。AIゲートウェイはアクセス制御を一元化し、ロールベースの権限、監査ログ、安全なキー管理を実現します。
例: マーケティング、製品、サポートチーム全体でAI機能を展開するグローバル企業は、AIゲートウェイを利用してスコープ付きAPIキーを割り当て、各チームの特定のモデルへのアクセスを制限することで、偶発的な誤用やデータ漏洩のリスクを低減しています。
コストの透明性と予算管理
LLMは、特にチーム全体での利用が増えるにつれて、運用コストの大きな部分を占める可能性があります。AIゲートウェイは、ユーザー、チーム、プロジェクトごとのきめ細かなコスト追跡を提供します。この可視性により、組織は予算を管理し、非効率性を特定し、必要に応じてチャージバックモデルを導入できるようになります。
例: 顧客にAI搭載機能を提供するSaaS企業は、ゲートウェイを介して利用状況を監視し、そのデータに基づいて実際のトークン消費量に応じた段階的料金設定を導入しています。
シームレスなモデル切り替えと抽象化
統合されたAPIレイヤーにより、組織はアプリケーションコードを変更することなくLLMやプロバイダーを切り替えることができます。これにより、新しいモデルのテスト、より良い価格交渉、商用からオープンソースへの移行が容易になります。
例: 当初商用LLMを使用していたスタートアップ企業が、データプライバシーとコスト削減のため、ゲートウェイの抽象化によりコードベースを変更することなく、ファインチューニングされたオープンソースモデルに移行しました。
信頼性と復元力の向上
ゲートウェイは、組み込みのフォールバック、自動再試行、キャッシング、ロードバランシングを提供することで、負荷がかかっている場合やプロバイダーの障害時でも、中断のないサービスと一貫したパフォーマンスを保証します。
例: トラフィックの多いチャットボットシステムは、複数のプロバイダー間でリクエストを動的にルーティングし、必要に応じてキャッシュされた応答にフォールバックすることで、突然のトラフィックスパイクを処理します。
コンプライアンスと可観測性
規制対象業界にとって、モデルの使用状況を追跡および監査する能力は極めて重要です。AIゲートウェイは、監視、ロギング、セキュリティツールと統合することで、コンプライアンス基準と内部ガバナンスポリシーを満たします。
例: ヘルスケア企業は、ゲートウェイを介してすべてのリクエストと応答をログに記録することで、データアクセス境界を維持しながら、監査目的の完全な追跡可能性を可能にしています。
もし、 APIゲートウェイとAIゲートウェイ といった用語が混同しやすいと感じるなら、それはあなただけではありません。多くのチームは、APIをスケールさせる際に初めてゲートウェイに遭遇します。その背景を踏まえ、AIゲートウェイがどのように異なり、そもそもなぜ存在するのかを説明します。
AIゲートウェイは、大規模言語モデル(LLM)の複雑さに特化して構築されています。単なるトラフィック管理を超え、データの「インテリジェンス」を処理します。
従来のAPIゲートウェイと専門的なAIゲートウェイの明確な比較を以下に示します。
要するに、従来のゲートウェイはデータの動きを管理します。AIゲートウェイはデータのコストと動作を管理します。最新のAIスタックにとって、ゲートウェイはコストの急増とセキュリティリスクに対する主要な防御策となります。
組織が大規模言語モデルの利用を拡大するにつれて、安全で信頼性が高く、効率的なインターフェースの必要性が不可欠になります。AIゲートウェイは、複数のプロバイダーの管理、アクセス制御の実施、コストの追跡、大規模なパフォーマンスの確保といった複雑さを抽象化する基盤レイヤーとして機能します。これにより、チームはLLMを活用したアプリケーションを自信を持って、かつ制御しながら実験、デプロイ、監視できるようになります。
社内コパイロット、顧客向けチャットインターフェース、またはマルチモーダルAIワークフローを構築しているかどうかにかかわらず、AIゲートウェイは、進化するモデルエコシステムをサポートするのに十分な柔軟性を保ちながら、インフラストラクチャの標準化を支援します。キャッシュ、ルーティング、コスト配分、ツール呼び出しなどの機能は、エンタープライズグレードのデプロイメントにおけるその価値をさらに高めます。
急速に変化するAIの状況において、AIゲートウェイの導入は単なる利便性にとどまりません。それは、運用の成熟度、可観測性、および長期的なスケーラビリティへの戦略的な投資です。
これらの機能を実際に見てみませんか? TrueFoundryのデモを予約する 本日、貴社のエンタープライズAIインフラストラクチャをいかに一元化し、安全に保つかについてご説明します。
AIゲートウェイは、複数のLLMプロバイダーを単一のAPIの下に統合する集中管理プレーンとして機能します。異なるエンドポイント間でのリクエストルーティング、認証、パフォーマンス監視といった重い処理を管理します。自動リトライの処理やチーム固有のレート制限を定義することで、AIインフラストラクチャの安定性とコスト効率を確保します。
最高のAIゲートウェイは、本番環境レベルの信頼性とベンダーの柔軟性を提供する必要があります。TrueFoundryは、低レイテンシーのためのセマンティックキャッシュや、障害を防ぐための自動モデルフォールバックといった独自のエンタープライズ機能を提供するため、有力な候補です。これにより、チームはアプリケーションコードを書き換えることなく、商用モデルとセルフホスト型モデルをシームレスに切り替えることができます。
AIファイアウォールがプロンプトインジェクションのようなセキュリティ上の脅威に特化して焦点を当てるのに対し、AIゲートウェイはデータフローのより広範な「インテリジェンス」を管理します。ゲートウェイは、トークンベースのロードバランシング、セマンティックキャッシング、モデルフェイルオーバーといった運用タスクを処理します。ゲートウェイを包括的な管理レイヤー、ファイアウォールを特定のセキュリティガードと考えると分かりやすいでしょう。
TrueFoundryは、部門横断的なトークン使用量とコストの詳細な可視性を提供することで、企業がAIをスケールアップできるよう支援します。ロールベースのアクセス制御とバージョン管理されたプロンプト管理によりガバナンスを簡素化し、コンプライアンスと再現性を確保します。この一元化されたアプローチにより、組織は実験的なプロトタイプから、安全で高性能な本番環境へと効率的に移行できます。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


