
.webp)
June 26, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: May 12, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
"Drained the API quota in 20 minutes" is not a mythical SRE story; it's a Tuesday afternoon with a poorly bounded loop. Token buckets, circuit breakers, and a graceful fallback chain — all enforced at the gateway before the loop touches a provider.
429 is not a crash. It's the gateway telling a runaway agent to back off. The agent obeys, the breaker holds, the budget survives the day.
LLM agents fail in a specific shape. The most common production incident is not a model giving the wrong answer; it is an agent that decides to retry, and retry, and retry, and retry. Each retry is a full provider call. Each call appends to context. Context grows quadratically. Tokens are consumed at a rate the human in front of the keyboard would never produce — because there is no human in front of the keyboard.
The arithmetic is brutal. A 4,000-token initial context, doubling at each step because the previous step's output gets appended, reaches 128,000 tokens at step 5 and the per-step cost has gone up 32×. By step 15 the context has overflowed the model's window and every call is paying the maximum-context rate. By step 30 the loop has spent more than a competent engineer's monthly salary. The agent never noticed; the agent's job is to keep going.
The first time most teams see this, they see it on the next day's bill. The second time, they put rate limiting in. The right place for that rate limiting is not the application — it's the gateway, where a single layer protects every workload regardless of which framework launched the loop. A team that puts the limit inside each agent has to write it again for each agent, miss it in some, and discover the failure modes individually. A team that puts it at the gateway writes it once and inherits the protection across every workload that ever calls a model.
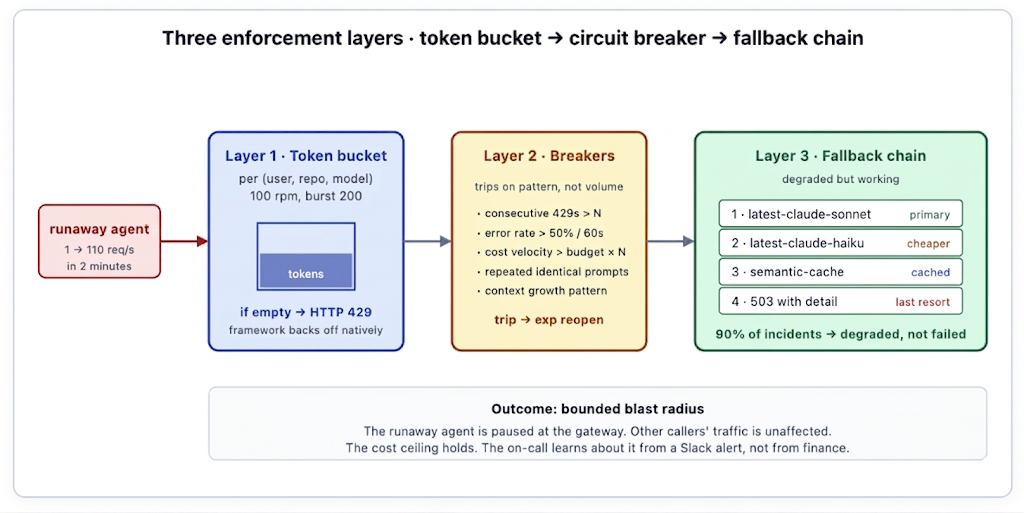
The bucket is the first line. Every (user, repo, model) tuple gets its own bucket — say, 100 requests per minute with a burst of 200. Refills happen continuously at the configured rate. When a request arrives and the bucket is empty, the gateway returns HTTP 429 immediately, before the request reaches the provider. The 429 carries a Retry-After header indicating how long the caller should wait.
The choice of granularity matters. A single bucket per user is too coarse — one rogue script blocks all the user's legitimate work, including the work they need to debug the rogue script. A bucket per request is too fine — there's nothing to throttle. The (user, repo, model) tuple is usually the right shape: it isolates the runaway repository from the user's other workloads, lets the platform team set different ceilings for different model tiers (more permissive on cheap models, stricter on frontier), and produces useful dimensional breakdowns in the rate-limit dashboard. Some teams add a fourth dimension — pipeline or workflow ID — for multi-tenant AI products where the bucket should belong to the customer the request is on behalf of, not the team running the service.
Most agent frameworks read 429 as a standard backoff signal. The agent pauses, waits for the suggested duration, and retries — exactly the behavior the gateway wants. Frameworks that don't handle 429 gracefully are broken in a different way, but the gateway has already done its job. The contract is HTTP-standard: 429 with Retry-After is what every HTTP client library has known how to handle for fifteen years. Teams that find their agent framework can't process 429 correctly should fix the framework, not the gateway.
Burst is the parameter that gets tuned. Set the burst too low and legitimate bursty workloads (CI triggers, batch evaluations, user-facing chatbot peak hours) hit 429 falsely; set it too high and the rate limit doesn't actually constrain a runaway. The right starting point is empirical — look at the natural burst shape of legitimate traffic in the previous month, set the bucket size to roughly the P99 burst observed, and tune from there based on false-positive complaints.
Token buckets handle volume. Circuit breakers handle pattern. Some runaways pass under the bucket's ceiling but exhibit other signatures of pathological behaviour — an agent that obeys the 100-rpm bucket but is making 100 identical calls per minute in a tight loop is still a runaway, just a slower one. The gateway watches every identity's recent traffic and trips when one of the following holds:
Each breaker has its own trip and reopen logic. The combined effect is that pathological behavior gets stopped quickly without false-positive trips on legitimate bursty traffic. The breaker is configured at the platform level and applies to every identity; the thresholds are tuned over time based on the false-positive rate the team is willing to tolerate.
Cost-velocity is the breaker most teams under-implement, because it requires the gateway to know the cost of each request in real time — input tokens, output tokens, cached tokens, model-specific pricing — and feed it into the breaker logic before the next request is admitted. TrueFoundry's gateway computes per-request cost at egress using current provider pricing and exposes the running cost rate to the breaker as a first-class input. A workload that exceeds its planned cost rate by a configurable multiplier trips; the breaker is parameterised relative to the workload's budget rather than against an absolute dollar number, which makes the threshold durable across provider price changes. Teams that retrofit cost-velocity onto a gateway that doesn't natively know per-request cost end up with stale pricing tables and breaker thresholds that need manual recalibration every quarter; the integrated version doesn't have that maintenance overhead.
When the primary path is unavailable — the token bucket is throttled, the circuit breaker is open, the provider itself is having an outage — hard-failing every request is the wrong outcome. A configurable fallback chain serves degraded output instead. The chain is declarative, per-route configuration:
# Per-route configuration
fallback_chain:
- model: "claude-4-6-sonnet" # primary
- model: "claude-4-5-haiku" # cheaper, still capable
- source: "semantic-cache" # cached response if similar
- response: 503 # last resort, descriptive errorThe chain is a config knob, not a hardcoded behaviour. Different routes have different chains. A coding pipeline may have a 2-step chain (Sonnet → Haiku → 503) because a degraded Haiku result is sometimes worse than a clear failure. A user-facing chatbot may have a 4-step chain that includes the semantic cache as a graceful fallback because any response is better than no response for the user. A high-stakes workflow (legal drafting, financial analysis) may have no fallback chain at all — the only acceptable behaviour on primary failure is to surface the error so a human can decide.
The point is that the platform decides what "degraded" means for each workload, instead of every workload deciding for itself. In practice, this is what turns 90% of "capacity exhausted" incidents into "degraded but working" incidents — visible to the platform team, invisible to the end user. The semantic cache is the under-used member of the chain in most teams' setups; a workload with reasonable cache hit rate (say 30%) survives most short-duration outages by serving cached responses for similar enough queries.
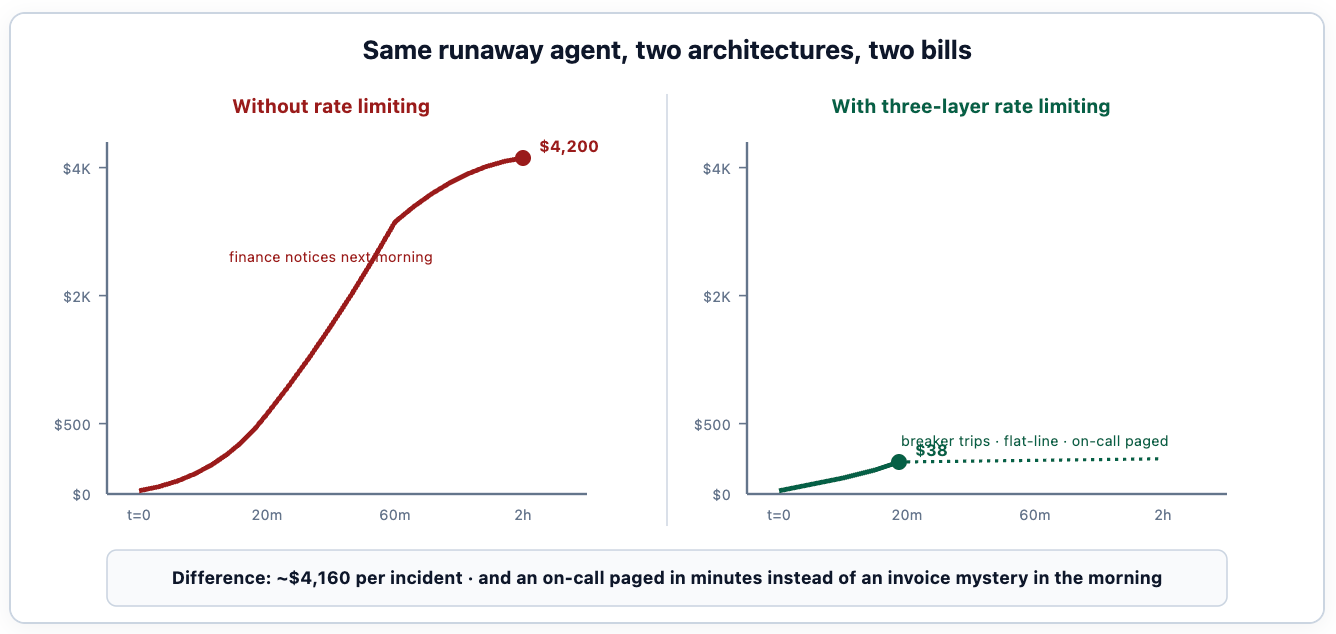
The economic argument is the one that gets the rate-limiting project funded. A single runaway incident without enforcement typically costs $2,000-$8,000 by the time someone notices; the same incident with the three layers in place costs $20-$100 and produces a tractable post-mortem instead of an apology email to finance. The first incident pays for the engineering effort to build the rate-limiting layer five to ten times over.
The contract from the caller's perspective is HTTP-standard. The four outcomes cover every state the rate-limiting layer can produce, and each maps to a well-understood remediation. Agent code does not need to know the rate-limiting architecture exists; it needs to know how to handle 429, 503, and the model-identification header. Three lines of error handling code suffice for most agent frameworks.
Pageable signals fire only when the breaker actually trips, not on every 429. A 429 is normal; a tripped breaker is anomalous. The on-call engineer receives a single, actionable Slack alert:
[BREAKER TRIPPED] runaway-agent detection on identity=devops-bot/infra-tf
trace_id: 7e9d8a1b
pattern: 110 req/s sustained, repeated identical prompts
cost velocity: $42/min (planned: $4/min)
action taken: requests blocked for 5 min, exponential reopen
suggested mitigation: review pipeline logs at <link>Trace ID, identity, pattern, cost, mitigation. Everything the engineer needs to decide whether to extend the breaker, raise the quota, or call the team that owns the offending pipeline. The alert is designed to be triaged in 30 seconds: 90% of the time the alert is a legitimate runaway and the engineer extends the breaker, posts to the offending team's channel, and goes back to whatever they were doing. 10% of the time it's a false positive (a legitimate burst the thresholds didn't anticipate) and the engineer raises the quota and adds the case to the threshold-tuning review.
The alert format is the operational artefact that gets tuned more than the breaker thresholds themselves. The first version of the alert is usually too verbose (everyone wants to know everything) and gets ignored; the seventh version is the one that contains exactly the five facts the engineer actually needs. The discipline is treating the alert as a product, with the on-call as the user.
TrueFoundry's default alert format ships with those five facts (trace ID, identity, pattern, cost velocity, deep link to the workload's dashboard) calibrated against the operational lessons of running this rate-limit layer for the platform's existing customers. Teams can override the format per route; most don't, because the default is already what they would have converged on by the seventh iteration. The structural design is the contribution — naming the right five facts at the right granularity — not the YAML schema that holds them.
The three layers compose into a per-route configuration that the platform team owns. Below is what a working configuration looks like for a CI/CD agentic workload — the canonical case where rate limiting matters most because the human pacing mechanism is absent:
name: ci-cd-agent-routing
type: gateway-load-balancing-config
rules:
- id: ci-agent-primary-route
when:
subjects:
- team:platform
models:
- ci-agent
type: priority-based-routing
load_balance_targets:
- target: anthropic/claude-sonnet
priority: 0
retry_config:
attempts: 3
delay: 200
on_status_codes: ["429", "500", "503"]
fallback_status_codes: ["429", "500", "502", "503"]
- target: anthropic/claude-haiku
priority: 1
retry_config:
attempts: 2
delay: 100
- target: cache/semantic-cache
priority: 2
fallback_candidate: trueThe configuration is the artefact. It's reviewed in pull requests, version-controlled alongside the gateway deployment, and changed when the team's tolerance changes (a new workload type with different burst patterns, a tightening cost ceiling, a new model option in the fallback chain). The platform team owns the schema; individual workload teams can override specific fields for their routes within bounds the platform team sets.
Every primitive in the manifest above — the per-identity token buckets, the four named circuit breakers, the declarative fallback chain, the actionable-format alerting — is a TrueFoundry gateway primitive rather than custom middleware. The platform team picks the granularity, sets the thresholds, configures the chain; there is no rate-limiting middleware to build, test, and maintain. Teams who have implemented the same three layers on top of a gateway without these primitives end up writing the same several hundred lines of Lua or Python middleware, the same Redis-backed bucket store, the same alert formatter — and discover most of the edge cases (race conditions on bucket refills, breaker-state propagation across replicas, fallback-chain ordering under partial outages) the third or fourth time the runaway happens in production.
Four patterns appear regularly in teams' first cuts at rate limiting, and each produces a different failure mode worth knowing.
Mistake 1: too-coarse bucket key. A single bucket per user means one runaway agent blocks the user's debugging work — including the work they need to find and fix the runaway. The (user, repo, model) tuple is usually the right granularity; teams that aggregate higher than this end up with operationally painful incidents.
Mistake 2: no fallback chain. A workload that fails hard on every 429 produces a worse user experience than necessary. Even if the team doesn't want a fallback model (quality concerns are legitimate), serving a cached response or a "temporarily unavailable" message is better than a 5xx that the user reads as "the AI is broken."
Mistake 3: paging on every 429. 429s are normal — they're the system working as designed. Pages should fire only when the breaker trips, not when the bucket throttles. Teams that page on 429 end up either ignoring the alerts (because most are noise) or running with their buckets set so high that the limit doesn't constrain anything.
Mistake 4: cost-velocity thresholds set as static dollar amounts. A static threshold ("$10/minute is too much") becomes obsolete quickly as the team's traffic and pricing change. The threshold should be relative to the workload's planned budget — "10× planned rate" is durable across cost changes; "$10/minute" is brittle.
Rate limiting is one of the few platform changes where the deployment risk is asymmetric: not enforcing is the status quo (with occasional expensive incidents), enforcing too aggressively breaks legitimate workloads. The rollout sequence should bias toward observation first, enforcement second.
Week 1 — Audit-only buckets, audit-only breakers. Deploy the rate-limiting layer with every threshold set to "log but don't enforce." Every request still goes through; the gateway records what would have been throttled or what would have tripped a breaker. The dashboard at the end of the week answers the questions the team didn't know they needed to: which workloads are bursty, which ones already exhibit loop signatures, how many requests/minute the busiest legitimate user actually produces.
Week 2 — Enable the token bucket only, on one workload class. Pick the highest-risk class — usually CI/CD agentic pipelines, where there is no human pacing mechanism. Enable the token bucket with thresholds set to the P99 of observed legitimate traffic plus a margin. Watch for 429s for the week. False positives (legitimate workloads hitting the limit) get the threshold raised; absent false positives, the next workload class is enabled.
Week 3 — Add the cost-velocity breaker. The cost-velocity breaker is the one that catches the slow runaways the token bucket misses. Configure it at 10× planned rate as the default; tune per workload after a week of audit data. Pages are configured but routed only to the platform team during week 3, not to product on-calls — the threshold is still being tuned.
Week 4 — Other breakers, fallback chain. Add the loop-signature detector. Configure fallback chains per route, in close consultation with the workload owners — they know what "degraded" should look like for their use case. The semantic cache populates over the first week of operation; cache hit rates climb gradually and stabilise around 20-40% for most workloads.
Week 5+ — Steady state. The pages route to product on-call. The rate-limit dashboard is part of the team's regular review. New workloads default into the audit-only state and get explicitly graduated to enforcement. The thresholds get re-tuned quarterly as traffic patterns shift; the breaker rules get extended as new pathological patterns are discovered. The system runs as infrastructure, not as a project.
The rate-limiting layer is owned by the platform team. The workload-specific thresholds are co-owned with the workload teams. Getting the boundary right matters because each has different decision rights and different time horizons.
The platform team owns the architecture. Which breakers exist, what the alert format is, what the audit log captures, how the configuration is reviewed. These are stable across workloads; they change rarely. The platform team's job is to provide primitives, document them, and tune the defaults.
The workload team owns the parameters. The bucket size for their workload, the fallback chain order, the cost-velocity threshold. These are workload-specific and change as the workload's requirements evolve. The platform team reviews changes (a workload requesting an enormous bucket gets a conversation, not an automatic approval), but the workload team has the operational ownership.
The on-call is rotated between platform and product. Pages from the rate-limiting layer go to a shared rotation. Platform engineers handle pages where the issue is platform infrastructure (the breaker logic itself is wrong); product engineers handle pages where the issue is their workload (the runaway is in their code). The handoff is the alert content; if the alert says "your workflow looped 200 times in 5 minutes, here's the trace," the product engineer is the right responder.
The pattern that fails is platform owning everything end-to-end. Platform engineers don't know what "degraded but acceptable" means for the customer-support chatbot; product engineers don't have the visibility into platform-wide signals. The split is what makes the operating model sustainable.
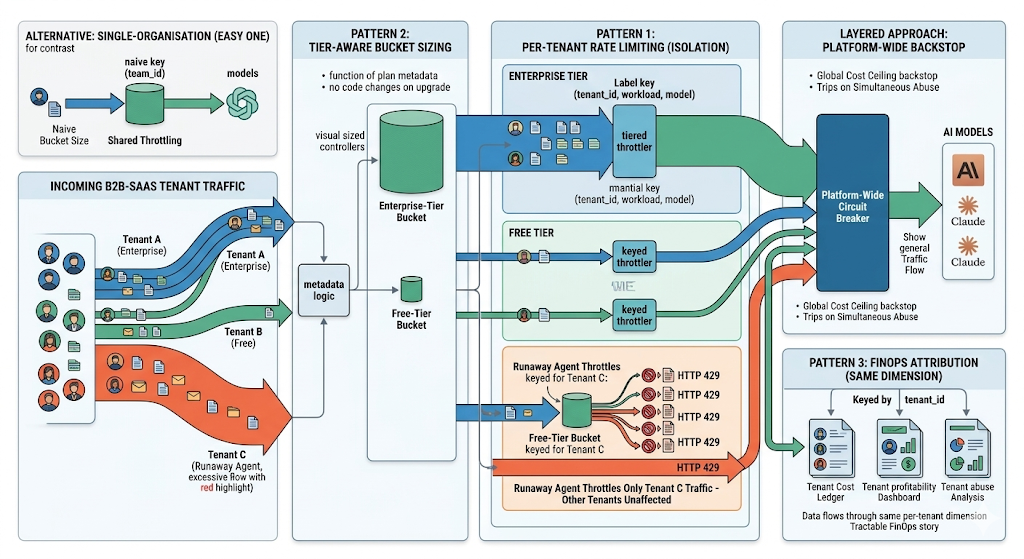
The single-organisation case where every caller belongs to one team is the easy one. Many production AI deployments are multi-tenant: a B2B-SaaS product offers AI features to its own customers, each of whom can produce traffic of arbitrary shape. The rate-limiting layer needs to isolate tenants from each other and to enforce per-tenant pricing tiers without changing the architecture.
The pattern that works adds tenant as another dimension on the bucket key. The bucket is keyed by (tenant, workload, model) — one tenant's runaway agent throttles only that tenant's traffic; other tenants are unaffected. The platform's overall cost ceiling sits above the per-tenant ceilings; a single tenant exceeding their tier hits their bucket first, and the platform-wide breaker provides a backstop for the case where multiple tenants are misbehaving simultaneously.
Tier-aware bucket sizing is the second pattern. The free-tier customer gets a smaller bucket than the enterprise-tier customer; the bucket sizes are derived from the tenant's plan. When a tenant upgrades plans, the bucket size updates without code changes — the tier is metadata on the tenant identity, the bucket size is a function of the tier. Teams that hard-code bucket sizes in application code end up rewriting them every time the pricing changes; teams that derive them from tenant metadata inherit the right behaviour automatically.
The third pattern: per-tenant cost attribution flows through the same dimension. If the bucket is keyed by tenant, the cost ledger is keyed by tenant, the audit log is keyed by tenant, the rate-limit dashboard is keyed by tenant. The platform's FinOps story (which tenants are the most expensive, which ones are profitable, which ones are abusing the system) becomes tractable from the same data the rate-limiting layer was already producing.
Start from the natural traffic shape — look at P99 burst for the workload over the previous month and size the bucket roughly there. Adjust based on false-positive rate (legitimate workloads complaining about 429s) and breaker trip rate (runaways escaping the bucket). The bucket is a per-workload parameter; one size does not fit all.
No — they compose. The provider's limits are absolute; the gateway's limits are per-identity and finer-grained. The provider's limit might say "100,000 requests/minute org-wide"; the gateway's limit says "100 requests/minute for this CI pipeline." Both apply; the gateway's limit will usually trigger first for individual workloads.
Configure a higher bucket for that workload. A workload that's known to need 1,000 rpm gets a bucket sized accordingly; the threshold is per-workload, not platform-wide. The discipline is reviewing the higher bucket with the platform team before granting it, not granting unlimited capacity by default.
Yes. A streaming response that runs for two minutes consumes one bucket token at request time but generates significant cost over the stream's duration. The cost-velocity breaker handles this case; the token-bucket layer is augmented with a streaming-cost monitor that can cancel the stream if cost velocity exceeds threshold mid-stream.
Yes — the cost-velocity breaker includes "spike detection": a single request whose cost exceeds N× the workload's average cost (typically 50× or 100×) trips the breaker even if no rate pattern is visible. This catches the case where an agent submits a context-overflowed request that costs $50 instead of the usual $0.05.
Roll out in audit-only mode first — the breaker calculates whether it would have tripped but doesn't actually block. After a week the team has a real distribution: which workloads would have tripped, how often, on which conditions. Tune the thresholds against the audit-only data, then enable enforcement. The audit-only week is cheap insurance against false positives.
No — the fallback chain takes over. If the fallback chain is exhausted, the application gets a clean HTTP 503 with a structured error body it can render to the user. Crashes don't happen at the gateway; they happen in poorly-handled application code that doesn't know what to do with a 503. The fix is application-side error handling, not gateway changes.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception
© 2026 Tous droits réservés.




.webp)

.webp)
.webp)
.png)






.webp)
.webp)


