

June 18, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 23, 2026
.webp)
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Vos systèmes semblent fonctionner correctement d'après le tableau de bord de votre couche d'infrastructure, avec des modèles d'IA déployés et des agents autonomes actifs. Pourtant, personne dans votre organisation ne sait quel agent appelle quels outils, accède à quelles données sensibles, qui est responsable, et ce que cela coûte à l'organisation dans son ensemble.
C'est exactement le type de problème qu'un plan de contrôle d'IA est conçu pour résoudre. Alors que les grandes entreprises passent de l'expérimentation isolée basée sur les LLM à des systèmes d'IA de qualité production qui pensent, se comportent et communiquent à travers les applications métier et l'infrastructure, la couche de gouvernance gérant ces systèmes d'IA devient aussi importante que les modèles d'IA eux-mêmes.
Cet article explique ce qu'est un plan de contrôle d'IA, comment il diffère des concepts d'infrastructure traditionnels, ce qu'il doit couvrir pour les charges de travail d'IA agentiques, et comment TrueFoundry fournit un plan de contrôle unifié pour les entreprises qui connectent et gouvernent des systèmes d'IA de qualité production à grande échelle.
Un plan de contrôle d'IA est le centre de gouvernance centralisé qui régit, suit et applique les règles d'entreprise à travers les nombreux systèmes d'IA d'une organisation, y compris les interactions LLM, les agents d'IA, les intégrations d'outils MCP et les connexions d'agent à agent.
Le concept de plan de contrôle d'IA est adapté du domaine des réseaux, où la séparation entre le plan de contrôle et le plan de données est une infrastructure fondamentale depuis des décennies. Dans les réseaux, le plan de contrôle gère les décisions de routage et l'application des politiques, tandis que le plan de données transporte le trafic réel. La même distinction s'applique à l'IA.
Le plan de contrôle d'IA gère quels modèles et outils peuvent être accédés, comment les requêtes des agents sont acheminées, quelle politique de gouvernance s'applique, et quels enregistrements sont conservés dans la piste d'audit. L'exécution agentique réelle — appels d'inférence à un pool de GPU, invocations d'outils via MCP, messages entre agents — est gérée indépendamment par le plan de données. Cela permet aux équipes de plateforme d'ajuster le routage, les budgets et les masquages sans recoder ou redéployer le logiciel de l'agent.
Aux débuts du déploiement de l'IA en entreprise, le processus était simple. Les équipes effectuaient quelques appels d'API vers des modèles de langage étendus, maintenaient une petite équipe et construisaient un système de journalisation basique.
Ces jours sont révolus, nous avons maintenant :
Lorsque vous introduisez des agents autonomes, la complexité se multiplie d'une manière que les invites ponctuelles n'ont jamais engendrée. Une seule requête utilisateur peut déclencher 15 appels différents sur autant d'outils et impliquer au moins cinq systèmes distincts, chacun avec ses propres limites d'accès, ses implications en termes de coûts et ses niveaux de sensibilité des données sensibles.
Sans un plan de contrôle de l'IA central :
Lorsque les agents autonomes agissent au nom d'utilisateurs ayant une autorité réelle, les systèmes d'IA non gouvernés engendrent des risques importants en matière de conformité réglementaire, et pas seulement des problèmes de coûts.
.webp)
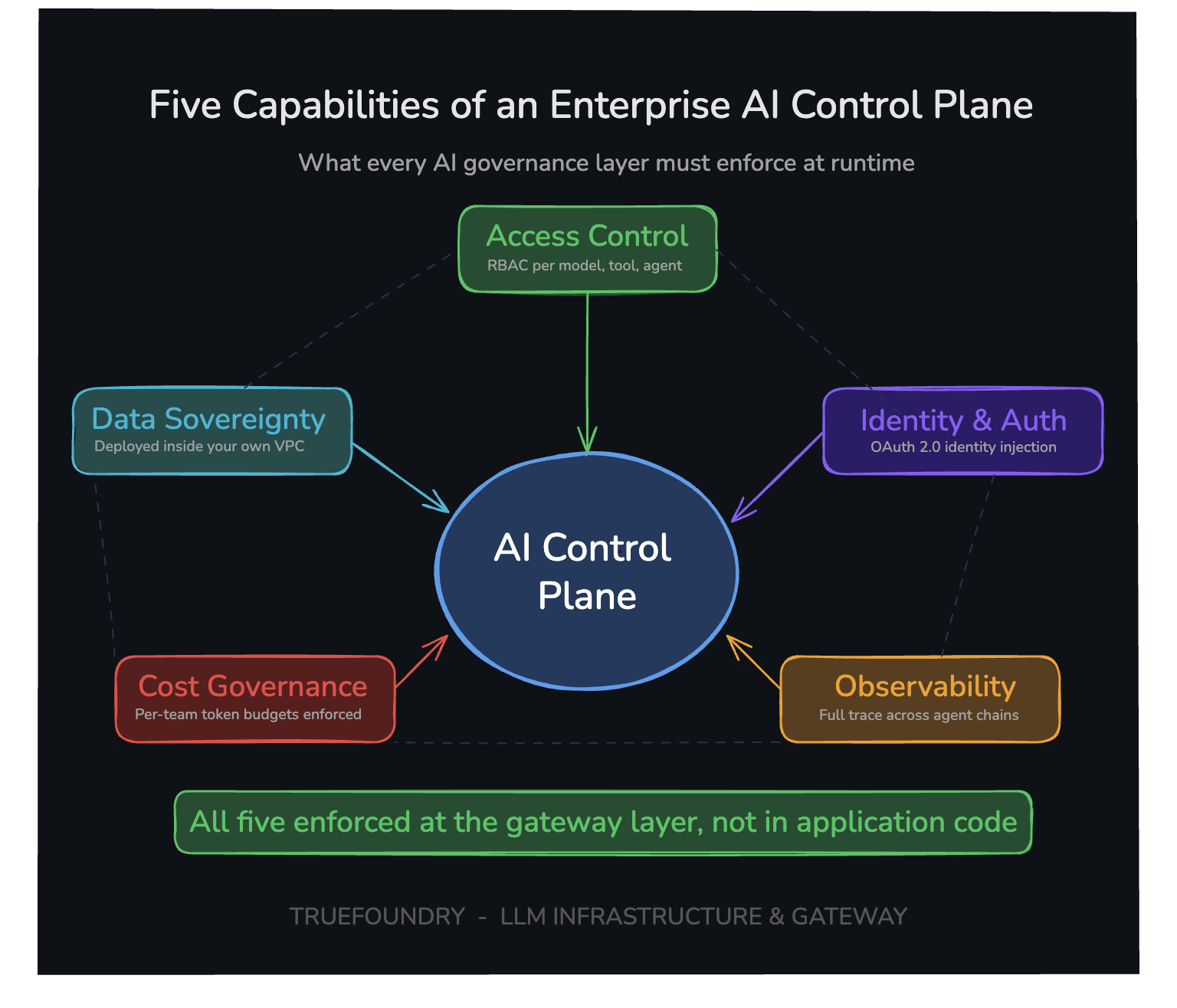
Cinq capacités essentielles distinguent un plan de contrôle de l'IA fonctionnel d'une simple surcouche au-dessus d'une passerelle. Chacune doit fonctionner au niveau de l'infrastructure, et non au sein du code applicatif, pour être efficace.
Seules les équipes et les utilisateurs autorisés peuvent utiliser les modèles, les outils et les agents d'IA. L'application des politiques s'opère au niveau de la passerelle avant que toute requête d'agent ne soit envoyée à un système backend, et non appliquée par le code applicatif après coup.
Les exigences incluent le RBAC pour les équipes et les utilisateurs, l'autorisation au niveau de l'outil plutôt qu'au simple niveau de l'API, l'application des politiques avant l'exécution plutôt qu'après, et une politique cohérente appliquée à tous les services. Si l'une de ces exigences n'est pas satisfaite, la logique d'accès devient fragmentée et incohérente entre les équipes, créant ainsi le problème des agents fantômes à grande échelle.
Les comptes de service partagés augmentent considérablement le rayon d'impact lorsque les identifiants sont compromis. Si un jeton de service d'agent est divulgué, il peut lire n'importe quelle base de données et appeler n'importe quelle API chaque fois qu'il a agi au nom d'un utilisateur.
Un plan de contrôle de l'IA adéquat doit injecter l'identité de l'utilisateur dans chaque requête, garantir que les agents autonomes agissent toujours de manière cohérente avec l'identité d'un utilisateur réel, mapper les identités des utilisateurs à des permissions spécifiques et délimitées, et s'intégrer avec les fournisseurs d'identité d'entreprise tels qu'Okta et Microsoft Azure AD. Cela fait passer l'IA d'une automatisation anonyme à un modèle d'exécution conscient de l'identité qui satisfait aux cadres réglementaires et aux exigences d'audit de conformité.
Chaque requête doit être journalisée en utilisant l'identité de l'utilisateur, le modèle, l'outil, le coût, la latence et la sortie dans un format structuré et consultable pour prendre en charge les flux de travail basés sur des agents avec une traçabilité à travers des chaînes d'exécution complètes de processus multi-étapes, et pas seulement l'entrée et la sortie finales.
Pour les flux de travail des agents d'IA spécifiquement, l'observabilité nécessite une profondeur supplémentaire. Traçabilité de l'exécution étape par étape, enregistrements des décisions intermédiaires, et télémétrie et métadonnées de la chaîne d'invocation des outils. Sans cela niveau d'observabilité, le débogage d'une défaillance de système d'IA relève de la conjecture plutôt que de la preuve. Les métriques sur les flux de travail des agents doivent être accessibles via un tableau de bord unifié avec une visibilité en temps réel.
L'utilisation des jetons doit être surveillée avec des limites budgétaires configurables appliquées avant que les coûts ne soient engagés. Une visibilité en temps réel sur les coûts de tous les LLM élimine les surprises de facturation et empêche l'IA de fonctionner sans responsabilisation.
L'application est aussi importante que le suivi. Le plan de contrôle de l'IA doit appliquer une limite budgétaire définie par équipe, service et point d'accès, un coût maximal défini par transaction, et des estimations de coûts pré-exécution avant que les transactions ne s'exécutent. Sans ces contrôles, les frais s'accumulent sans responsabilisation et n'apparaissent qu'à la clôture du cycle de facturation. Les dirigeants d'entreprise ont besoin d'une attribution du retour sur investissement au niveau de la charge de travail, et non d'une facture cloud consolidée.
Le routage du trafic d'IA via des plateformes SaaS externes pour la gouvernance et/ou l'analyse expose les entreprises à des risques d'exfiltration de données et à des responsabilités en matière de conformité. Chaque invite peut contenir des informations personnelles identifiables (PII), des informations de santé protégées (PHI), du code source, des dossiers clients et la stratégie interne d'une organisation. Dans de nombreux cas, l'envoi de copies de tous ces éléments à un fournisseur d'observabilité tiers en échange d'une jolie vue de trace ne suffira tout simplement pas en termes de compromis acceptables pour la plupart des entreprises réglementées.
Pour une gouvernance/un contrôle approprié, le nouveau plan de contrôle doit faire quatre choses :
1) Il doit fonctionner depuis votre infrastructure, soit dans votre VPC, soit sur site (c'est-à-dire, par opposition au cloud)
2) Il doit garder les données dans les limites de sécurité appropriées de l'infrastructure de votre organisation
3) Il doit minimiser les transferts de données inutiles depuis l'infrastructure de votre organisation
4) Il doit fournir une preuve complète de conformité (par exemple, SOC 2, HIPAA, etc.) pour les exigences réglementaires.
Ce facteur joue généralement un rôle important dans les décisions de déploiement au niveau de l'entreprise.
De nombreuses organisations cherchent à créer un plan de contrôle d'IA en utilisant les outils dont elles disposent déjà, mais toutes les combinaisons présentent toujours les mêmes lacunes structurelles.
Tous ces outils étaient initialement conçus pour des défis antérieurs aux exigences de gouvernance spécifiques aux agents d'IA. Collectivement, leurs lacunes rendent impossible l'application des politiques sur les requêtes d'agents en direct avant l'exécution, et ce, pour chaque modèle et outil au sein du périmètre réseau d'une organisation.
Le plan de contrôle d'IA de TrueFoundry permet aux organisations de connecter, surveiller et gérer tous les agents autonomes sur plusieurs fournisseurs de cloud à partir d'une interface unique, plutôt que de maintenir des outils distincts pour les agents, les proxys et d'autres composants. En unifiant la passerelle LLM, la passerelle MCP et la passerelle d'agents en un seul plan de contrôle, les organisations gouvernent les charges de travail agentiques à partir d'une seule couche de gouvernance plutôt que de trois systèmes déconnectés.
Le TrueFoundry passerelle IA se déploie uniquement au sein du compte AWS, GCP ou Azure de l'organisation. Tous les appels d'inférence, l'orchestration des agents d'IA, l'exécution des outils et les interactions MCP sont gérés sans que les données ne sortent du périmètre réseau de l'organisation, garantissant ainsi la conformité aux exigences réglementaires HIPAA, SOC 2 et ITAR.
Cela signifie qu'une équipe de plateforme peut activer un nouveau fournisseur, lui acheminer 10 % du trafic, appliquer une règle d'application de politique de rédaction des PII, limiter les dépenses quotidiennes à 2 000 $ et auditer tous les appels sans redéployer aucune application.
Réserver une démo pour découvrir comment TrueFoundry unifie la gouvernance de l'IA, sécurise les flux de travail des agents, contrôle les coûts et offre un contrôle de qualité production pour tous les déploiements d'entreprise.
.webp)
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception
© 2026 Tous droits réservés.




.webp)






.webp)
.webp)
.webp)
.webp)
.webp)

.webp)

.webp)
