
.webp)
June 26, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 26, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
La passerelle TrueFoundry AI émet des traces OpenTelemetry pour chaque requête qu'elle traite et les publie de manière asynchrone via NATS vers un exportateur OTEL qui les transmet à tout backend compatible OTLP via HTTP ou gRPC. Honeycomb est un de ces backends. Il accepte les données OTLP à l'adresse https://api.honeycomb.io/v1/traces via HTTP avec encodage protobuf et s'authentifie à l'aide de l'en-tête x-honeycomb-team . Une fois les traces arrivées, Honeycomb indexe chaque attribut de span et les rend disponibles pour des requêtes ad hoc sans nécessiter de schéma prédéclaré.
Cet article explique comment la passerelle TrueFoundry génère et exporte les traces, ce que Honeycomb en fait une fois qu'elles sont arrivées, et comment les deux systèmes se connectent au niveau du protocole.
La passerelle TrueFoundry AI est basée sur le framework Hono et fonctionne comme un pod de passerelle sans état sur 1 vCPU et 1 Go de RAM, gérant plus de 250 requêtes par seconde avec environ 3 ms de latence ajoutée. La passerelle est conforme à OpenTelemetry et génère des spans sur l'ensemble du cycle de vie de chaque requête entrante.
L'arbre de spans couvre cinq étapes. La première est le gestionnaire HTTP entrant qui enregistre l'arrivée de la requête ainsi que les métadonnées du client. La deuxième est l'authentification, où la passerelle vérifie le jeton JWT par rapport à une clé publique mise en cache téléchargée depuis le fournisseur d'identité. Aucun appel d'authentification externe n'est effectué pendant cette étape. La troisième est la résolution du modèle, où la passerelle résout l'identifiant de modèle logique en un point de terminaison de fournisseur physique à l'aide d'une table de routage en mémoire synchronisée depuis le plan de contrôle via NATS. La quatrième est l'appel au fournisseur sortant, où la passerelle traduit la requête du format compatible OpenAI vers le format du fournisseur cible via un adaptateur et la transmet. La cinquième est la gestion de la réponse en streaming, où la passerelle capture le nombre de jetons et les raisons de fin de génération à mesure que la réponse est diffusée.
Les attributs de span suivent les conventions sémantiques gen_ai.* ainsi que des attributs spécifiques à TrueFoundry. L'attribut gen_ai.request.model enregistre l'identifiant du modèle. Les attributs gen_ai.usage.prompt_tokens et gen_ai.usage.completion_tokens enregistrent la consommation de jetons. Les attributs tfy.input et tfy.output les attributs contiennent le texte complet de l'invite et de la réponse. L' tfy.input_short_hand attribut contient une version tronquée pour l'affichage. L' tfy.span_type attribut identifie la catégorie de portée telle que ChatCompletion ou MCPGateway.
Une fois la requête terminée, la passerelle publie ces portées vers NATS de manière asynchrone. Un exportateur OTEL en arrière-plan lit ce chemin asynchrone et transmet les portées au point de terminaison externe configuré. Cette conception signifie que l'exportation des traces n'ajoute jamais de latence au chemin de la requête. La passerelle n'échoue pas une requête si le point de terminaison OTEL externe est inaccessible. Le chemin d'exportation est additif et ne remplace pas le propre stockage interne des traces de TrueFoundry.

Pour les charges de travail où le contenu de l'invite et de la réponse ne doit pas quitter l'environnement, la passerelle fournit un bouton bascule Exclure les données de requête . Lorsqu'il est activé, il supprime tfy.input et tfy.output et tfy.input_short_hand des portées avant l'exportation. Tous les autres attributs de portée, y compris le nombre de jetons, les latences et les métadonnées du modèle, continuent de circuler.
La passerelle MCP suit le même modèle de traçage. Chaque invocation d'outil génère un span qui enregistre l'utilisateur appelant, le serveur MCP, le nom de l'outil, la charge utile complète de la requête et de la réponse, ainsi que la latence. Ces spans apparaissent dans le même arbre de traces que les spans d'appels LLM, permettant une visibilité de trace de bout en bout sur l'ensemble des workflows agentiques.
Honeycomb ingère les données OTLP et stocke chaque span comme une ligne avec des colonnes arbitraires. Il n'y a pas de schéma fixe. Chaque attribut émis par TrueFoundry, qu'il s'agisse de gen_ai.usage.prompt_tokens ou tfy.span_type ou http.response.status_code devient une colonne interrogeable dans Honeycomb dès l'arrivée du premier span le contenant.
La primitive de requête fondamentale dans Honeycomb est l' BubbleUp analyse. Étant donné un ensemble de traces lentes ou échouées, BubbleUp calcule quelles valeurs d'attribut sont statistiquement surreprésentées dans cet ensemble par rapport à la ligne de base. Pour le trafic de la passerelle LLM, cela signifie identifier si un pic de latence est corrélé à un modèle spécifique, à un utilisateur spécifique ou à un serveur MCP spécifique, sans écrire de requête manuellement.
Honeycomb organise les données en jeux de données. La passerelle TrueFoundry configure service.name à tfy-llm-gateway et Honeycomb achemine les spans vers un jeu de données de ce nom par défaut. Pour acheminer les spans vers un autre jeu de données, le x-honeycomb-dataset en-tête est ajouté à la configuration de l'exportateur à côté de x-honeycomb-team. Plusieurs jeux de données peuvent être utilisés pour séparer le trafic de production et de pré-production ou pour séparer les traces de la passerelle LLM des traces de la passerelle MCP.
L'onglet Traces dans Honeycomb présente la vue en cascade des spans. Chaque ligne est un span. La hiérarchie montre les relations parent-enfant, ainsi un span racine MCPGateway: resources/list avec des spans imbriqués MCP: resources/templates/list et un span sortant POST https://... correspond directement à ce que la passerelle a exécuté. Les barres de durée rendent la distribution de la latence visible en un coup d'œil. Le compteur Spans with errors isole les traces présentant des erreurs.
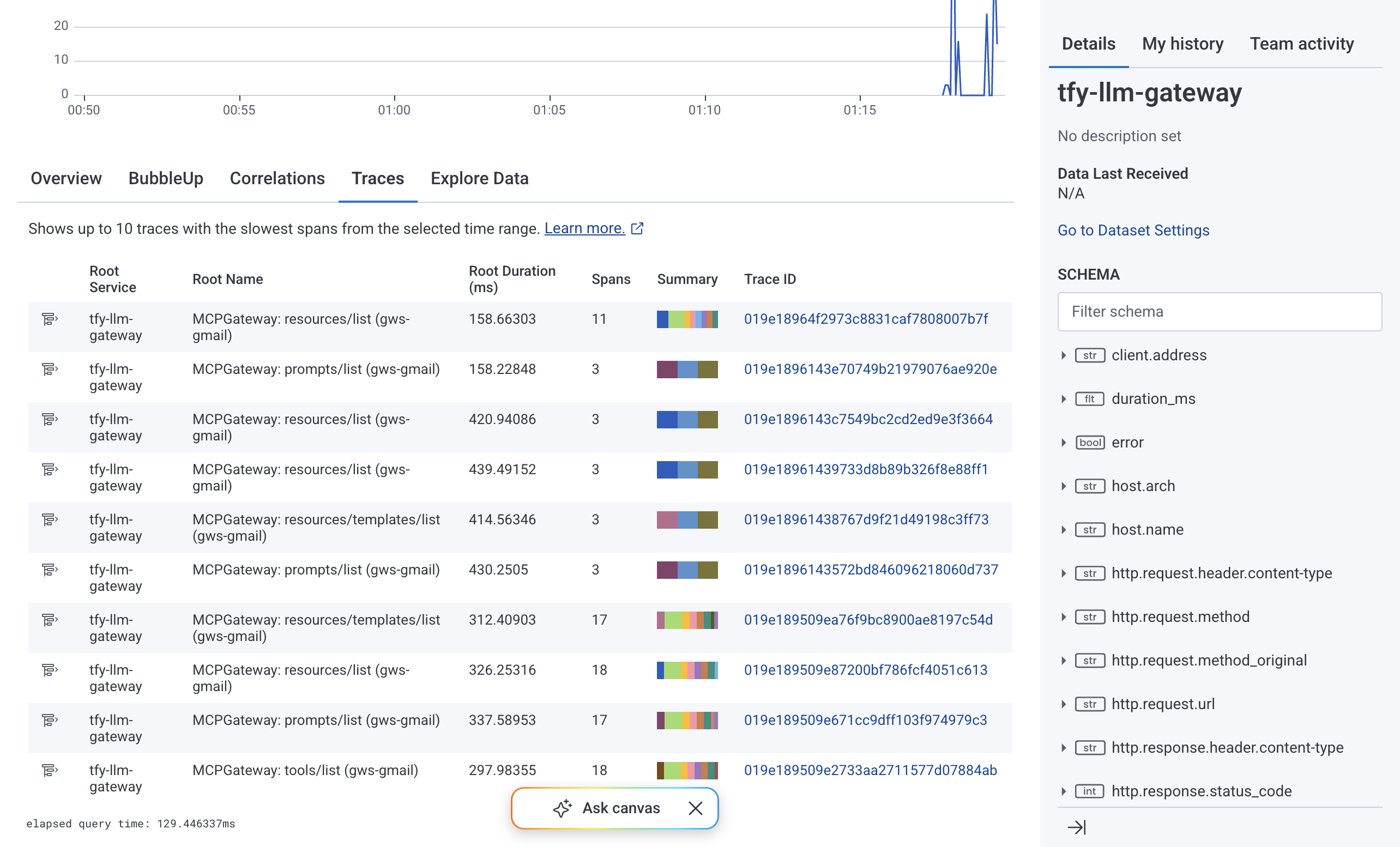
L'onglet Vue d'ensemble agrège le nombre total de spans, d'erreurs et d'exceptions sur la fenêtre temporelle sélectionnée et affiche le volume de traces, le volume de spans et le volume d'erreurs sous forme de graphiques de séries temporelles. Cette vue reflète la santé de la passerelle en un coup d'œil sans avoir à construire un tableau de bord à partir de zéro.

Cliquer sur n'importe quel ID de trace développe la cascade complète des spans pour cette trace. Chaque span affiche son nom de service, sa durée et les éventuels drapeaux d'erreur. Les spans enfants imbriqués reflètent la hiérarchie d'appels interne de la passerelle, permettant d'isoler quelle étape a introduit de la latence pour chaque requête.

La passerelle TrueFoundry exporte les traces via OTLP HTTP avec encodage protobuf. Honeycomb accepte ce format à deux points de terminaison régionaux.
L'authentification utilise un seul en-tête. Le x-honeycomb-team en-tête contient la clé API d'ingestion Honeycomb. La clé doit avoir le Envoyer des événements champ d'application de la permission. Il n'y a pas de flux OAuth ni d'échange de jeton d'accès. La clé est envoyée comme valeur d'en-tête simple à chaque requête d'exportation.
x-honeycomb-team: <votre-clé-api-d'ingestion-honeycomb>
Le routage des jeux de données est contrôlé par un deuxième en-tête facultatif. Lorsque x-honeycomb-dataset est omis, Honeycomb utilise service.name des attributs de ressource pour déterminer le jeu de données cible. Lorsqu'il est défini explicitement, toutes les traces de ce lot d'exportation sont écrites dans le jeu de données nommé, indépendamment de service.name.
x-honeycomb-dataset: tfy-llm-gateway-production
La passerelle TrueFoundry n'ajoute pas automatiquement les chemins de signal au point de terminaison configuré. Le chemin complet, y compris /v1/traces doit être présent dans le champ du point de terminaison. Cela diffère de l'exportateur HTTP OTLP de l'OpenTelemetry Collector qui ajoute /v1/traces automatiquement en fonction du type de signal du pipeline. Dans le Collector, une seule URL de base comme https://api.honeycomb.io:443 est suffisant car le Collecteur résout le chemin à partir de la définition du pipeline. Dans TrueFoundry, le point de terminaison est utilisé tel quel.
L'interface de configuration de TrueFoundry correspond directement aux champs requis par Honeycomb.
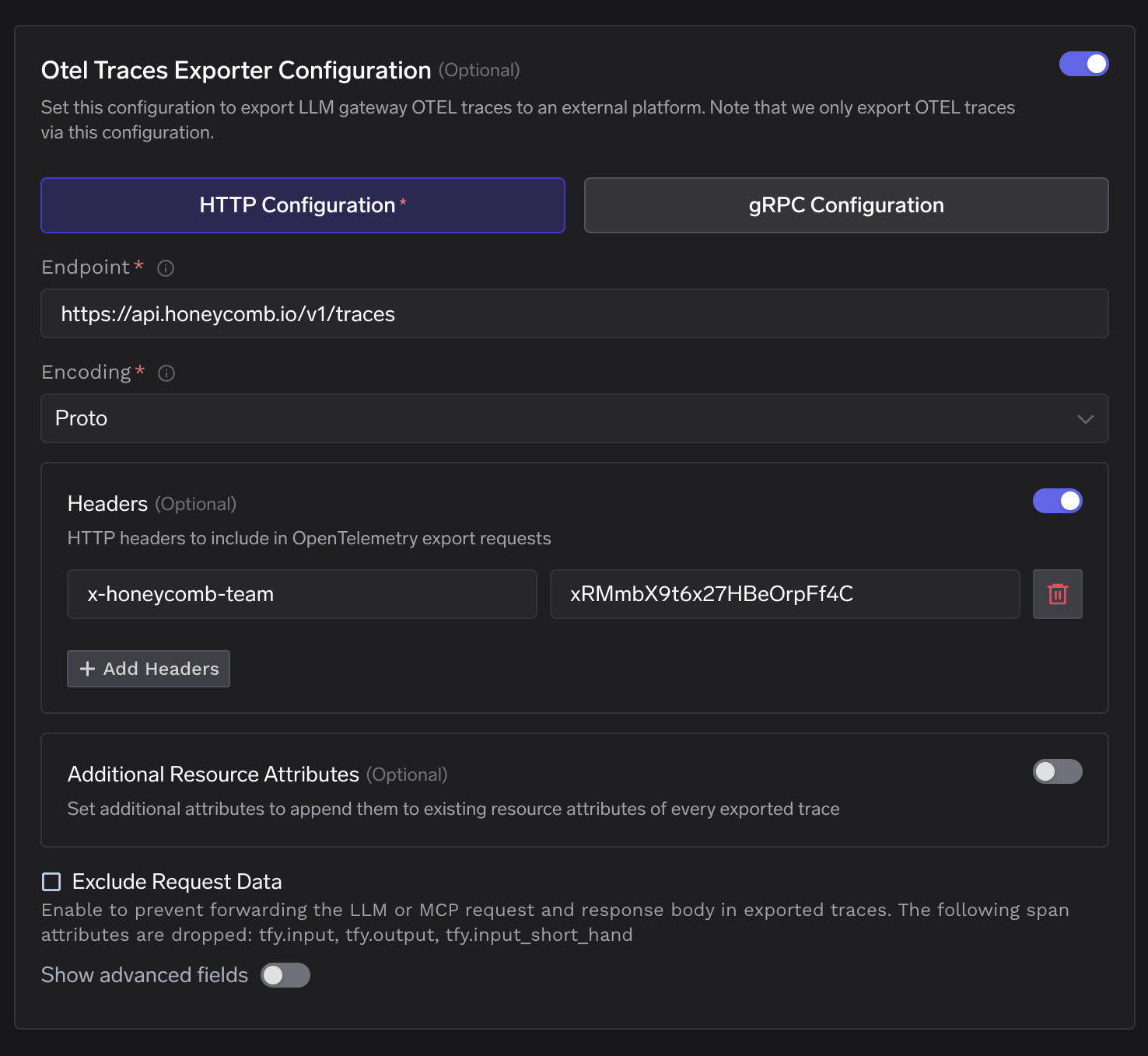
Le Attributs de ressource supplémentaires champ ajoute des paires clé-valeur au bloc de ressources de chaque span exporté. Ceci est utile pour ajouter une balise d'environnement de déploiement ou un identifiant de cluster qui n'est pas déjà présent dans les attributs de span.
La Exclure les données de requête case à cocher supprime tfy.input et tfy.output et tfy.input_short_hand avant que les spans ne quittent la passerelle. Honeycomb recevra toujours tous les attributs structurels, y compris les nombres de jetons, les latences, les noms de modèles et les indicateurs d'erreur.
Lorsqu'une requête atteint la passerelle TrueFoundry, l'arbre de spans complet est assemblé en mémoire pendant le traitement de la requête et publié sur NATS une fois la réponse terminée. L'exportateur OTEL s'abonne à ce sujet NATS et regroupe les spans avant de les envoyer à https://api.honeycomb.io/v1/traces via HTTPS avec l' x-honeycomb-team en-tête présent. Honeycomb écrit chaque span comme une ligne dans le tfy-llm-gateway jeu de données. Les spans deviennent interrogeables quelques secondes après leur arrivée.
Aucune modification du code de l'application n'est requise. Aucun conteneur sidecar n'est déployé à côté de la passerelle. Aucun SDK n'est intégré au client. L'intégration se résume à une configuration sur la passerelle : une URL de point de terminaison et un en-tête d'authentification. Les clients existants appelant la passerelle via l'API compatible OpenAI continuent de fonctionner sans modification.
Le principe qui rend cette intégration fiable est le chemin d'exportation asynchrone. L'exportation des traces est découplée du cycle de vie des requêtes via NATS. Une panne de l'API Honeycomb ou une partition réseau entre la passerelle et le point d'ingestion de Honeycomb n'affecte pas la disponibilité de l'inférence. La passerelle traite les requêtes et publie les spans vers NATS, que l'exportation en aval réussisse ou non. Cela signifie que le pipeline d'observabilité peut être configuré, reconfiguré et redémarré sans affecter le chemin de traitement des requêtes.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception
© 2026 Tous droits réservés.




.webp)

.webp)
.webp)
.png)






.webp)
.webp)


