
.webp)
June 25, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 4, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Nous sommes ravis d'annoncer l'intégration de Resemble AI avec la passerelle TrueFoundry AI, qui apporte le clonage vocal, la synthèse vocale synchrone et la synthèse vocale en streaming (TTS) dans le même chemin de passerelle que les équipes utilisent déjà pour les LLM, les embeddings et le trafic d'agents.
Les équipes acheminant le trafic d'IA via la passerelle TrueFoundry AI peuvent désormais connecter Resemble AI en tant que fournisseur de synthèse vocale de premier ordre grâce au pass-through SDK natif de la passerelle. Les requêtes vers les points de terminaison /synthesize et /stream de Resemble transitent par le chemin de la passerelle avec une authentification centralisée, un contrôle d'accès par équipe, un suivi unifié des coûts et une traçabilité complète des requêtes. Aucune modification du code client n'est requise, au-delà de la redirection de l'URL de base de Resemble vers la passerelle et de l'authentification avec un jeton TrueFoundry.
Cet article couvre l'architecture de l'intégration. Il explique comment la passerelle TrueFoundry AI expose les fournisseurs de TTS, comment la surface d'API native de Resemble est préservée via la couche de pass-through, et comment le basculement entre plusieurs fournisseurs de TTS fonctionne via les modèles virtuels.
TrueFoundry fournit la couche de contrôle pour les systèmes d'IA en production. Grâce à la passerelle AI, les équipes centralisent le routage des modèles, la gestion des clés, le contrôle d'accès, l'observabilité et le suivi des coûts pour les LLM, les embeddings, et les fournisseurs d'images et d'audio. Chaque requête transite par une seule couche proxy où l'identité est vérifiée, les limites de débit sont appliquées et les traces sont capturées.
Le trafic TTS en production ressemble au trafic LLM de trois manières. Plusieurs fournisseurs sont généralement en jeu car aucun fournisseur TTS unique ne l'emporte sur toutes les dimensions. La latence est importante car les agents vocaux diffusent l'audio aux utilisateurs en temps réel. Le coût s'accumule rapidement au niveau du caractère ou de la seconde et bénéficie des mêmes contrôles de refacturation et de budget que les équipes appliquent déjà aux complétions de chat. Les arguments en faveur de l'utilisation d'une passerelle devant les fournisseurs de LLM s'appliquent directement.
Resemble AI est une plateforme de génération vocale et d'intelligence audio. Son moteur de synthèse principal est le modèle Chatterbox, avec une variante Chatterbox Turbo pour une latence plus faible et la prise en charge des balises paralinguistiques. La plateforme prend en charge le clonage vocal, le SSML, la synthèse HD et la sortie en streaming. Resemble expose également des produits adjacents, notamment Resemble Detect pour la détection de deepfakes audio, ainsi que Audio Edit, Voice Design et Watermark, qui peuvent être intégrés au flux de travail TTS.
Ensemble, les deux plateformes offrent aux équipes un point unique pour gouverner et tracer la génération vocale, parallèlement au reste de leur pile d'IA. TrueFoundry gère le déploiement, le routage et le contrôle opérationnel. Resemble gère la synthèse réelle. L'intégration utilise le pass-through SDK natif de TrueFoundry, qui préserve la surface d'API complète de Resemble sans la contraindre à une forme compatible OpenAI.

Le point de terminaison de synthèse vocale synchrone de Resemble prend un petit ensemble de champs et renvoie l'audio ainsi que des métadonnées de synchronisation. Le point de terminaison de synthèse accepte un `voice_uuid` sélectionnant la voix entraînée ou pré-construite à utiliser, et un champ `data` contenant du texte ou du SSML jusqu'à 3000 caractères. Des champs optionnels contrôlent la sélection du modèle via `model` (par exemple, `chatterbox-turbo`), la précision audio via `precision` (l'un des `MULAW`, `PCM_16`, `PCM_24` ou `PCM_32`), le format de sortie via `output_format` (wav ou mp3), le taux d'échantillonnage, le mode HD via `use_hd` et la gestion des prononciations personnalisées via `apply_custom_pronunciations`.
La charge utile de la réponse renvoie le succès et un champ `audio_content` encodé en base64 contenant les octets audio synthétisés. Les métadonnées de synchronisation arrivent dans `audio_timestamps` avec les caractères graphèmes et leurs temps, ainsi que les caractères phonèmes et leurs temps, pour les cas d'utilisation d'alignement en aval comme la synchronisation labiale et le sous-titrage. La réponse indique également la `duration` (la durée audio en secondes), la `synth_duration` (le temps de synthèse brut), l'`output_format`, le `sample_rate` et tout problème signalé par le synthétiseur pendant la génération.
Un second point de terminaison à `/stream` prend en charge la synthèse en streaming via HTTP pour les cas d'utilisation d'agents vocaux où le temps d'obtention du premier fragment audio est important. La forme de la requête est la même. La réponse est un flux de trames audio plutôt qu'une seule charge utile base64. L'authentification pour les deux points de terminaison est un jeton porteur émis depuis la console de compte Resemble.
La passerelle TrueFoundry AI fonctionne sur le framework Hono, et un seul pod de passerelle gère plus de 250 requêtes par seconde sur 1 vCPU et 1 Go de RAM avec environ 3 ms de latence ajoutée. Les pods de passerelle sont sans état, liés au CPU et évoluent horizontalement jusqu'à des dizaines de milliers de RPS grâce à des pods supplémentaires. Le plan de contrôle et le plan de passerelle sont séparés. La configuration du fournisseur, y compris les identifiants, les règles de routage et les limites de débit, réside dans le plan de contrôle et se synchronise avec les pods de passerelle via NATS. Le chemin de requête réel reste en mémoire sans appels externes au-delà de l'appel du fournisseur lui-même.
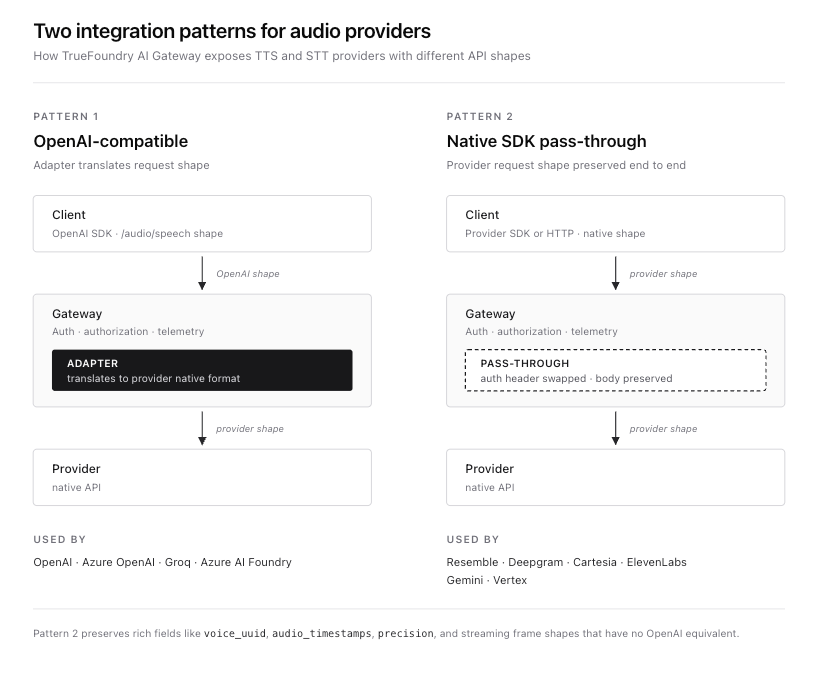
Pour le TTS, la passerelle expose deux modèles d'intégration.
Le premier est le API compatible OpenAI modèle à l'URL de base de la passerelle. Les fournisseurs qui utilisent le format `/audio/speech` d'OpenAI (OpenAI, Azure OpenAI, Azure AI Foundry et Groq) se connectent ici. Les clients utilisent le SDK OpenAI standard et la passerelle traduit la requête au format natif du fournisseur via une couche d'adaptation.
Le second est le passage direct via le SDK natif modèle à {GATEWAY_BASE_URL}/tts/{providerAccountName}. Les fournisseurs dotés d'API natives riches qui ne correspondent pas parfaitement au format OpenAI (Deepgram, Cartesia, ElevenLabs, Gemini et Vertex) se connectent ici. La forme complète de la requête et de la réponse du fournisseur est préservée. La passerelle gère l'authentification, le contrôle d'accès, le traçage et le routage, mais ne réécrit pas la charge utile. C'est le modèle qu'utilise Resemble car le corps de la requête Resemble, avec voice_uuid, audio_timestamps, les niveaux de précision et le sélecteur de modèle chatterbox-turbo, n'a pas d'équivalent dans le contrat TTS d'OpenAI.
Lorsqu'une requête atteint un pod de passerelle, le chemin ressemble à ceci. Le jeton TrueFoundry dans l'en-tête d'autorisation est validé par rapport aux clés publiques IdP mises en cache. L'identité de l'équipe est résolue par rapport à une carte en mémoire et l'autorisation au compte fournisseur Resemble est vérifiée. Le corps de la requête est transmis au point de terminaison de synthèse ou de streaming de Resemble avec le jeton bearer Resemble attaché côté serveur. La réponse est diffusée en continu au client. L'interaction complète est capturée dans une trace avec le nom du modèle, le compte fournisseur, le nombre de caractères d'entrée, la durée de la réponse, la durée de la synthèse et la latence. Il n'y a pas d'allers-retours supplémentaires au-delà de l'appel réel au fournisseur.
Resemble est enregistré dans le plan de contrôle TrueFoundry en tant que compte fournisseur, avec le jeton bearer Resemble stocké comme secret. Une fois le compte ajouté, la passerelle expose deux routes TTS pour celui-ci. La route SDK native à {GATEWAY_BASE_URL}/tts/{providerAccountName}/synthesize sert de proxy au point de terminaison synchrone. La route de streaming à {GATEWAY_BASE_URL}/tts/{providerAccountName}/stream sert de proxy au point de terminaison de streaming. Les deux routes préservent exactement la forme de la requête et de la réponse Resemble.
Un appel client minimal ressemble à l'extrait ci-dessous. Notez que le seul changement par rapport à un appel Resemble direct est l'URL de base et l'en-tête d'authentification.
curl -X POST {GATEWAY_BASE_URL}/tts/resemble-prod/synthesize \
-H "Authorization: Bearer ${TFY_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "voice_uuid": "55592656",
"data": "Hello from the gateway.",
"model": "chatterbox-turbo",
"output_format": "mp3",
"use_hd": false }'Le code d'application existant qui cible directement Resemble migre en échangeant l'URL de base et le jeton bearer. Les UUID vocaux, les charges utiles SSML, les paramètres de précision et le mode HD sont tous transférés sans modification. Les bibliothèques clientes officielles de Resemble peuvent être configurées de la même manière en surchargeant leur URL de base.
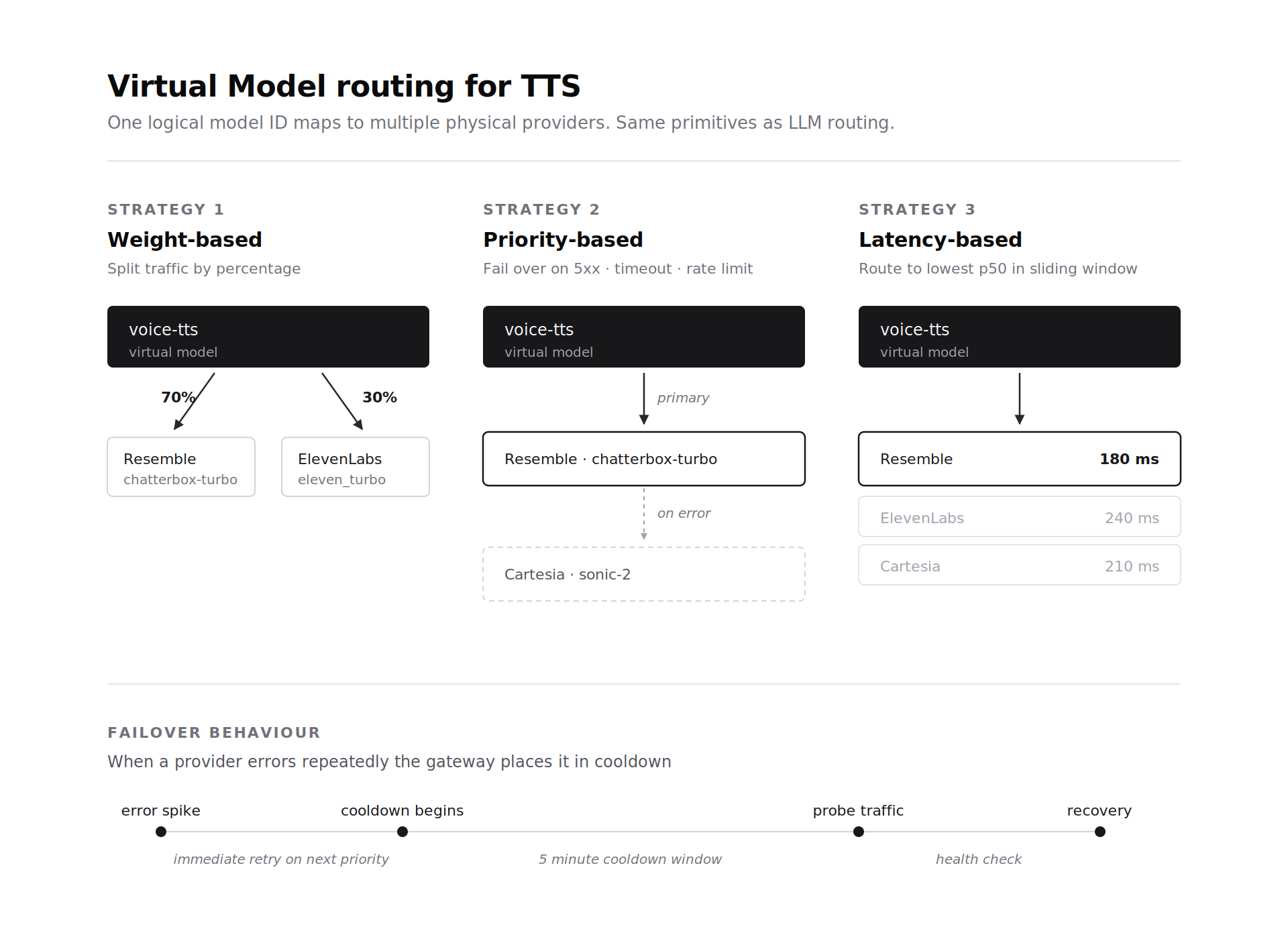
Les piles d'agents vocaux exécutent souvent plus d'un fournisseur TTS en production pour des raisons de coût et de latence. L'abstraction de modèle virtuel de la passerelle s'étend aux fournisseurs TTS de la même manière qu'aux fournisseurs LLM. Un identifiant de modèle virtuel correspond à un ou plusieurs déploiements TTS physiques avec des règles de routage. Basé sur le poids le routage distribue le trafic par pourcentage entre les fournisseurs. Basé sur la priorité le routage essaie le premier fournisseur et bascule en cas d'erreur 5xx, de délai d'attente ou de limite de débit. Basé sur la latence le routage envoie le trafic au fournisseur ayant la latence p50 la plus faible dans la fenêtre glissante.
Le basculement pour le TTS fonctionne sur les mêmes primitives que le basculement LLM. Les erreurs non récupérables déclenchent une nouvelle tentative immédiate sur le fournisseur prioritaire suivant. Les pics d'erreurs placent un fournisseur en période de "cooldown" de 5 minutes et le trafic de sonde vérifie la récupération. Une équipe utilisant Resemble Chatterbox Turbo comme chemin principal à faible latence peut basculer vers Cartesia ou ElevenLabs sans modifier le code client. Le modèle virtuel gère la sélection.
Le suivi des coûts capture l'utilisation du TTS avec la même granularité que l'utilisation du LLM. La passerelle enregistre le nombre de caractères d'entrée, la durée de synthèse, le modèle, l'équipe et l'utilisateur pour chaque requête. Le service d'agrégation calcule les dépenses par équipe et par utilisateur et alimente les mêmes tableaux de bord et primitives d'application budgétaire qui couvrent déjà les complétions de chat et les embeddings. Les limites de débit s'appliquent via l'algorithme du "Sliding Window Token Bucket" avec des fenêtres par minute définies par utilisateur, équipe ou modèle. Pour le TTS, l'unité est les caractères ou les requêtes plutôt que les jetons, mais l'algorithme reste inchangé.
Chaque requête TTS émet une trace. Les attributs de la trace incluent le compte fournisseur, l'identifiant du modèle (par exemple resemble-prod/chatterbox-turbo), le nombre de caractères d'entrée, la durée de la réponse en secondes, le temps de synthèse brut, le format de sortie, le taux d'échantillonnage et la latence côté passerelle. Les traces sont émises de manière asynchrone via NATS et exportées via OTEL vers le backend d'observabilité configuré par l'équipe (Arize, Langfuse, LangSmith ou toute autre cible prise en charge). L'option "Exclude Request Data" s'applique de la même manière que pour les complétions de chat afin de ne pas inclure le texte d'entrée dans les traces exportées lorsque la confidentialité des données l'exige.
Cela signifie que les appels TTS apparaissent dans la même chronologie de trace que l'appel LLM en amont qui a produit le texte et l'action d'agent en aval qui a consommé l'audio. Pour le débogage des agents vocaux, cette consolidation est cruciale. Une interaction échouée peut être tracée depuis la complétion LLM qui a sélectionné la réponse, en passant par la synthèse TTS qui l'a rendue, jusqu'à l'action suivante entreprise par l'agent.
Le flux de requête de bout en bout se présente comme suit. Un client envoie une requête TTS à la passerelle à l'adresse {GATEWAY_BASE_URL}/tts/{providerAccountName}/synthesize ou à son équivalent en streaming, avec un jeton bearer TrueFoundry. La passerelle authentifie l'appelant à l'aide de clés IdP mises en cache, résout le compte fournisseur et vérifie l'autorisation de l'équipe et de l'utilisateur en mémoire. Si un modèle virtuel est utilisé, la logique de routage sélectionne un fournisseur physique en fonction du poids, de la priorité ou de la latence. Le corps de la requête est transmis à Resemble avec le jeton bearer Resemble côté serveur attaché. La réponse est diffusée en continu au client, en conservant la forme complète de la charge utile de Resemble, y compris le contenu audio, les horodatages et les métadonnées de durée. Chaque étape est capturée dans une étendue de trace (trace span) émise de manière asynchrone vers NATS et exportée via OTEL.
Rien d'autre n'a besoin de changer dans l'application. Aucune réécriture de SDK n'est requise, aucune gestion de l'authentification par fournisseur côté client, et aucun pipeline d'observabilité séparé pour le trafic vocal. La passerelle est déjà dans le chemin de requête pour le reste de la pile IA, et Resemble s'y intègre via une transmission native. Le code client Resemble existant continue de fonctionner avec un simple échange d'URL de base.
En savoir plus sur le TrueFoundry AI Gateway et la plateforme Resemble AI. Ajoutez Resemble en tant que compte fournisseur dans le plan de contrôle de la passerelle et appelez le point de terminaison de synthèse ou de streaming à la route /tts/{providerAccountName} depuis le code d'application existant.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception
© 2026 Tous droits réservés.










.webp)





.webp)
.webp)