

June 25, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 23, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
La Parte 1 hizo el diagnóstico: tokenmaxxing no es un problema de uso de IA; es un problema del plano de control. Si los tokens brutos se convierten en un objetivo, la gente optimizará para los tokens brutos. Si el aprovechamiento de IA gobernado se convierte en el modelo operativo, la plataforma puede fomentar la adopción mientras se limitan los costos, los riesgos y el ruido operativo. Esta parte concreta esa arquitectura.
La tesis es sencilla. Cada solicitud de IA que sale de una aplicación empresarial es, se trate así o no, un evento en tiempo de ejecución con consecuencias de costo, seguridad y auditoría. El punto más estratégico para aplicar controles a esos eventos es el gateway — la capa que se interpone entre cada aplicación y cada modelo y backend de herramienta. Un panel de control construido aguas abajo puede describir lo que sucedió. Solo el gateway puede decidir qué sucede a continuación.
Un panel de control informa un problema. Un gateway previene el siguiente. La arquitectura a continuación es lo que hace operativa esa distinción.
Una solicitud de IA gobernada necesita cuatro envoltorios a su alrededor antes de salir de la aplicación. Piense en esto como el modelo OSI para la IA empresarial: cada capa tiene una responsabilidad específica y un modo de fallo específico cuando está ausente.
Estos envoltorios deben estar en la ruta de la solicitud, no en un informe que alguien lee el viernes. Un panel de control construido a posteriori puede describir un problema; solo un envoltorio en la solicitud activa puede influir en la siguiente llamada. Este es el principio arquitectónico que separa una plataforma de IA gobernada de un complemento de análisis.
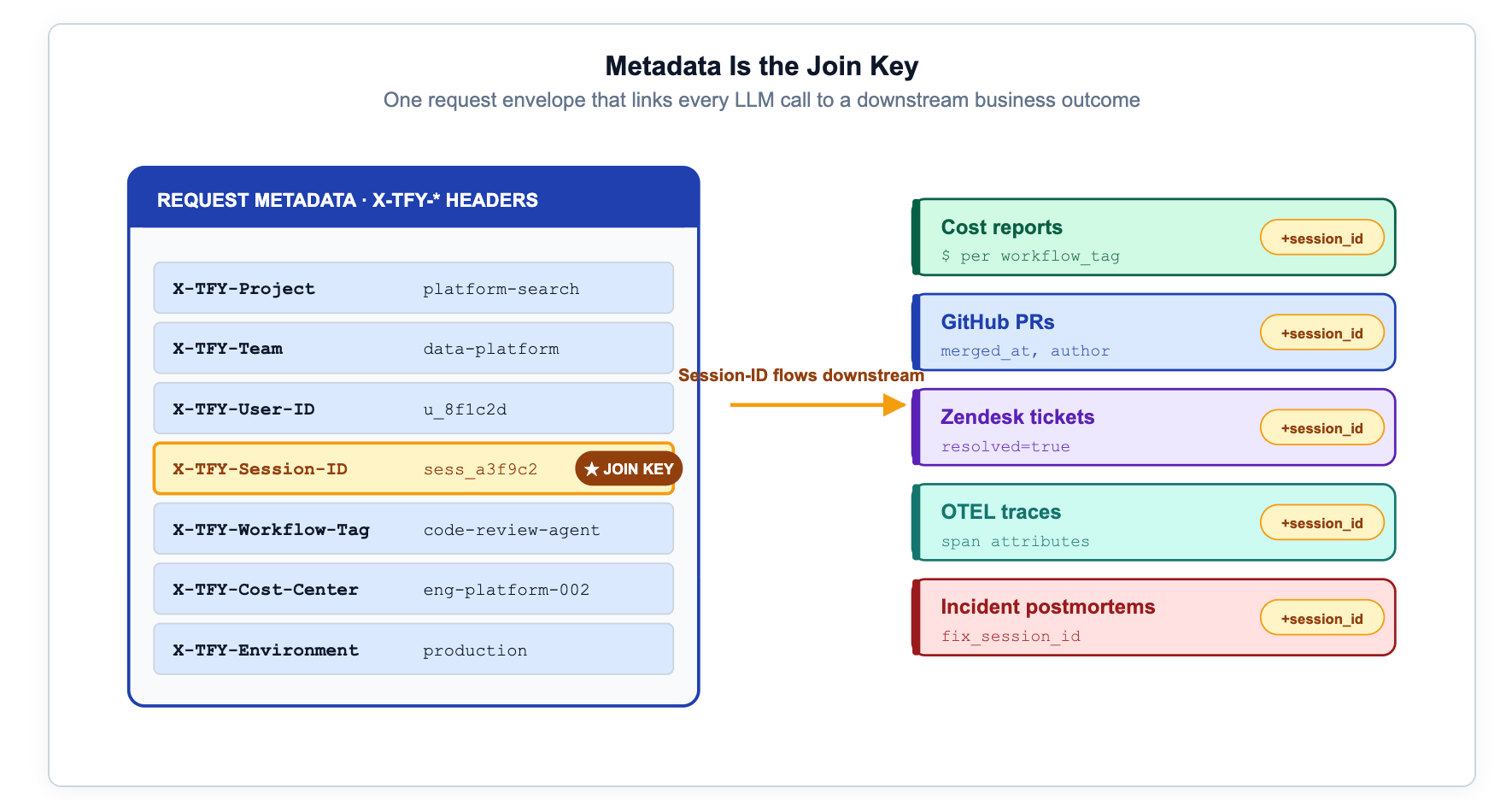
El primer estándar de implementación es un contrato de metadatos estricto. Utilice claves con valores de cadena, envíelas en cada solicitud y hágalas obligatorias en sus envoltorios de SDK, bibliotecas de cliente internas, frameworks de bots y plantillas de agentes. El costo de un campo faltante se manifiesta más tarde como una línea de factura faltante, un pico no atribuible o un evento de barrera de seguridad que nadie puede asignar a un propietario.
// JSON — minimum metadata contract
// Treat as a strict schema, not a suggestion.
{
"team": "payments-platform", // maps to FinOps cost center
"project_id": "proj-agentic-refactor", // rate/budget scoping key
"workflow": "repo-understanding", // routing and policy selector
"surface": "ide-agent", // hourly rate-limit selector
"environment": "production", // budget tier selector
"cost_center": "eng-core", // accounting integration
"ticket_id": "ENG-18472", // outcome join key — THE most important field
"policy_version": "ai-leverage-v1" // audit trail
}
// Python SDK — never skip the metadata header:
// extra_headers={"X-TFY-METADATA": json.dumps(metadata)}El etiquetado es el trabajo de ingeniería más barato en toda esta arquitectura y lo primero que falla cuando los equipos lo omiten.
En el gateway de TrueFoundry, esto viaja como el encabezado X-TFY-METADATA. El mismo espacio de nombres de clave luego impulsa todo aguas abajo: los presupuestos se aplican por proyecto, los límites de tasa se aplican por flujo de trabajo, los paneles de control se agrupan por equipo, las trazas se unen a los tickets y finanzas asigna el gasto por centro de costos. No hay una segunda fuente de verdad.
El objetivo arquitectónico no es añadir controles. Es mantener un mapeo estrecho entre cada modo de fallo realista y el control específico que lo previene. Aquí está la taxonomía completa:
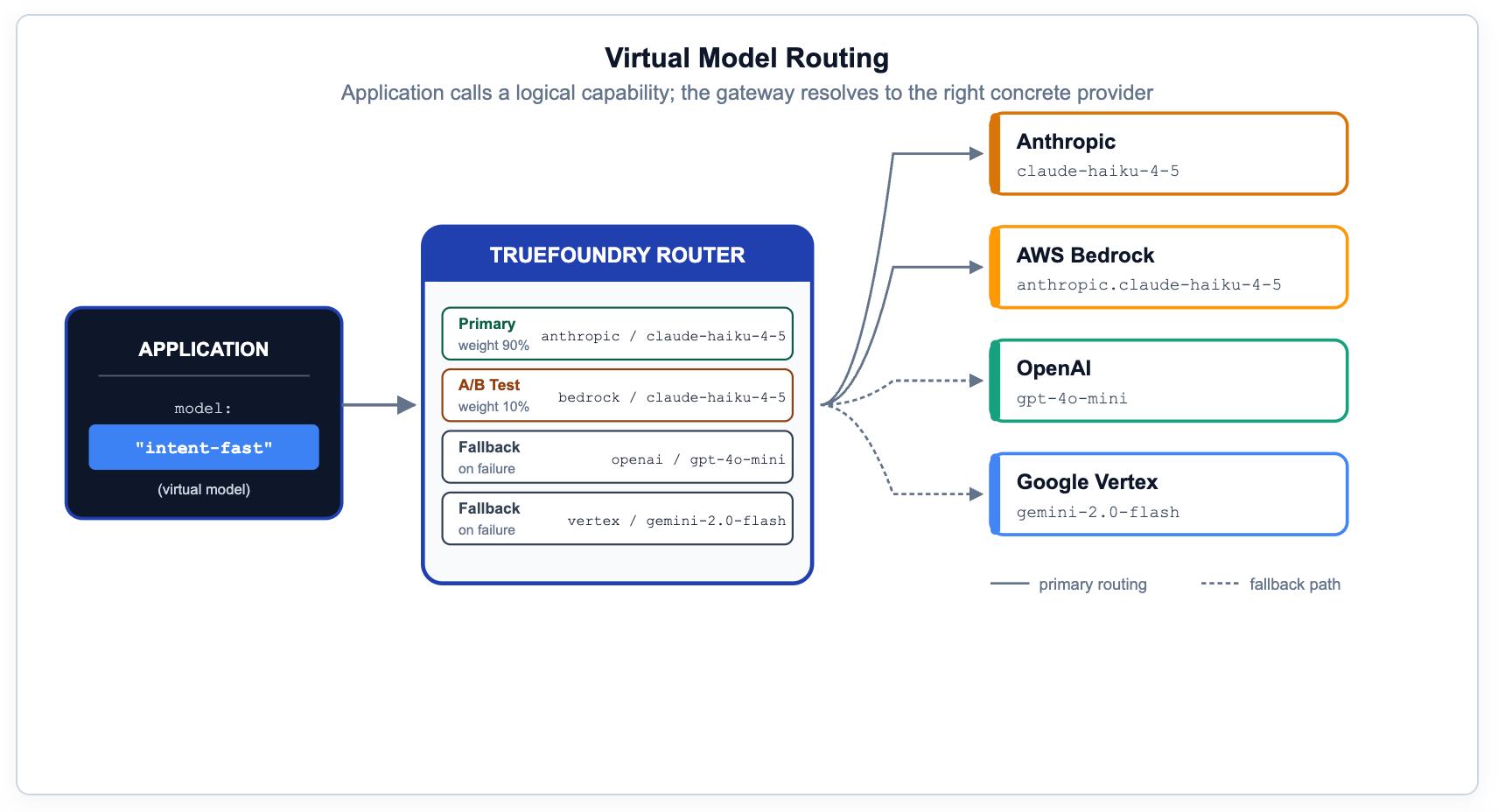
Si el código de la aplicación nombra un modelo de proveedor específico, ha perdido la capacidad de migrar, probar, hacer pruebas A/B o realizar una conmutación por error sin cambios en el código. El patrón correcto es exponer capacidades lógicas — nombres como prod/engineering-assistant o prod/frontier-reasoning — y dejar que el gateway los resuelva a objetivos físicos basándose en metadatos, prioridad, peso o latencia medida.
En TrueFoundry, para esto sirven los Modelos Virtuales y la configuración de enrutamiento. Las mismas reglas cubren despliegues canary, preferencias regionales, configuraciones on-prem con respaldo en la nube y anulaciones de prompts específicas del proveedor. Esta es la capacidad más subestimada en la pila de gobernanza: hace que el cumplimiento, la optimización de costos y la migración de modelos sean invisibles para los desarrolladores de aplicaciones.
# YAML — gateway-load-balancing-config
# Evaluated top-to-bottom; first match wins.
name: engineering-agent-routing
type: gateway-load-balancing-config
rules:
# Simple repo questions: cheap-first with frontier fallback.
- id: 'simple-repo-questions'
type: priority-based-routing
when:
models: ['prod/engineering-assistant']
metadata:
workflow: 'repo-understanding'
load_balance_targets:
- target: openai-main/gpt-4o-mini
priority: 0
retry_config: {attempts: 2, delay: 100, on_status_codes: ['429','500']}
fallback_status_codes: ['429', '500', '502', '503']
- target: anthropic-main/claude-sonnet
priority: 1
# Security-critical: strongest reasoner first.
- id: 'security-critical-review'
type: priority-based-routing
when:
metadata:
workflow: 'security-review'
load_balance_targets:
- target: anthropic-main/claude-opus
priority: 0
- target: openai-main/gpt-4.1
priority: 1
# Cost-sensitive batch: on-prem first, cloud as overflow.
- id: 'batch-processing-jobs'
type: priority-based-routing
when:
metadata:
surface: 'batch-pipeline'
load_balance_targets:
- target: on-prem/llama-3.1-70b
priority: 0
- target: openai-main/gpt-4o-mini
priority: 1
Documentación de enrutamiento: truefoundry.com/docs/ai-gateway/load-balancing-overview
Una vez que las aplicaciones de IA entran en producción, manejan datos de usuarios reales y, en configuraciones agentivas, realizan acciones reales a través de herramientas. El perímetro de seguridad no es una única cosa. Son cuatro puntos de control, situados en los cuatro momentos en que la pasarela puede intervenir antes de que una solicitud cause daño.
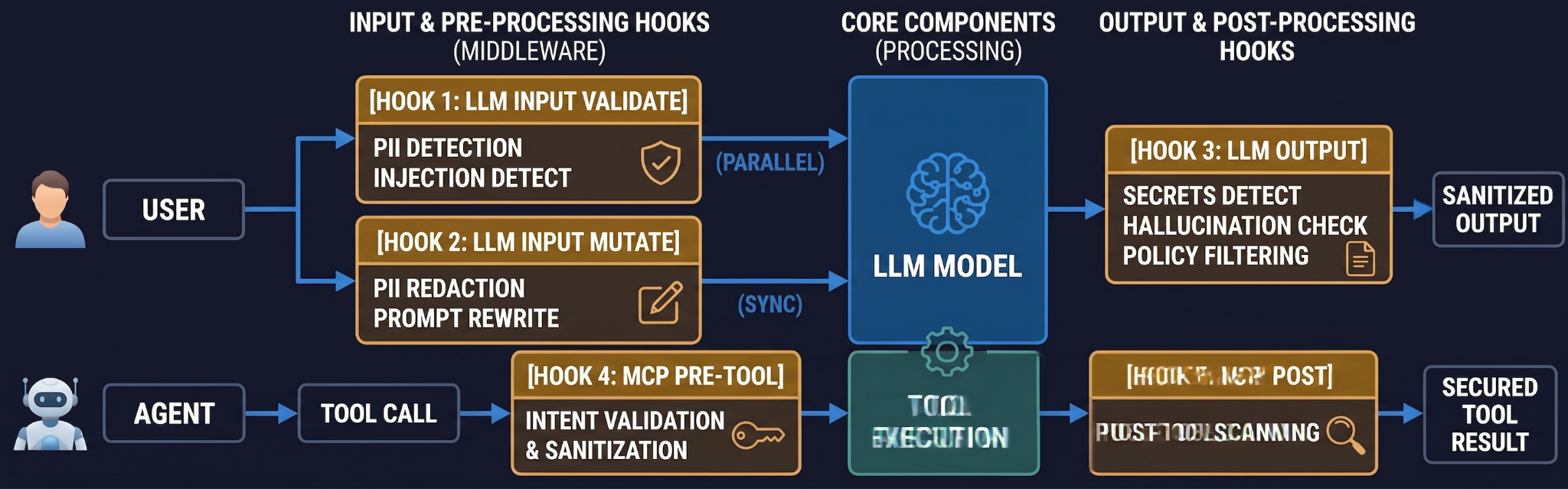
# Per-request guardrails — passed via X-TFY-GUARDRAILS header.
# For org-wide enforcement: AI Gateway → Controls → Guardrails.
X-TFY-GUARDRAILS: {
"llm_input_guardrails": [
"global/pii-redaction",
"global/prompt-injection-detection"
],
"llm_output_guardrails": [
"global/secrets-detection",
"global/hallucination-check"
],
"mcp_tool_pre_invoke_guardrails": [
"global/sql-sanitizer",
"global/cedar-permissions"
],
"mcp_tool_post_invoke_guardrails": [
"global/secrets-detection",
"global/pii-redaction"
]
}
# Rollout strategy — never go straight to blocking in production:
# Phase 1: mode=audit (log violations, let requests through)
# Phase 2: mode=enforce (block on fail, fail-open on provider errors)
# Phase 3: mode=strict (block on fail AND on provider errors)
Implemente las barandillas de seguridad en tres pasos: Auditoría → Aplicar-pero-ignorar-errores → Estricto. La configuración intermedia es la que le salvará el día en que un proveedor de seguridad externo sufra una interrupción.
Resumen de las barandillas de seguridad: truefoundry.com/docs/ai-gateway/guardrails-overview
Detección de PII/PHI: truefoundry.com/docs/ai-gateway/tfy-pii
Detección de secretos: truefoundry.com/docs/ai-gateway/secrets-detection
Dos preguntas dominan las operaciones una vez que el uso de IA gobernada está en producción: '¿por qué esta solicitud se comportó de esta manera?' y '¿el costo que estamos pagando se corresponde con el trabajo que estamos obteniendo?' Ninguna de las dos se puede responder con un gráfico de recuento de tokens.
La información mínima necesaria para responderlas — y la que la pasarela de TrueFoundry proporciona de forma predeterminada:
Documentación de análisis: truefoundry.com/docs/ai-gateway/analytics
Exportación de OpenTelemetry: truefoundry.com/docs/ai-gateway/export-opentelemetry-data
Los cuatro envolventes anteriores fueron diseñados asumiendo solicitudes de estilo chat: una aplicación envía un prompt, el modelo devuelve texto. Las cargas de trabajo de IA modernas han superado esa suposición. Los agentes llaman a herramientas. Las herramientas llaman a otras herramientas. Una única solicitud de usuario puede generar una trayectoria de agente de 50 pasos que toca media docena de servidores MCP. La superficie de costos, la superficie de seguridad y la superficie de auditoría se han trasladado del prompt a la llamada de herramienta.
Por eso, la pasarela de TrueFoundry se comunica de forma nativa tanto con la API de LLM como con el Protocolo de Contexto del Modelo (MCP). El mismo sobre de identidad, los mismos disyuntores y los mismos ganchos de observabilidad se aplican tanto a una llamada de herramienta como a una finalización de chat. La identidad de OAuth 2.0 se inyecta en las llamadas de herramientas de MCP para que un agente actúe como un usuario específico, no como una cuenta de servicio, cuando consulta una base de datos o crea un ticket de Jira. Los servidores MCP virtuales permiten componer un 'servidor de agente financiero' lógico a partir de herramientas distribuidas en tres servidores MCP reales, con control de acceso y límites de velocidad aplicados a la composición.
El Protocolo de Contexto del Modelo es importante por el coste, no solo por la arquitectura. TrueFoundry informa de un ahorro de hasta el 99% en tokens de inferencia cuando los agentes utilizan la recuperación activa de herramientas en lugar de rellenar el contexto en las indicaciones, y una sobrecarga de llamadas a herramientas medida en aproximadamente 10 ms.
→ Descripción general de la pasarela MCP
Es tentador integrar estos controles en el código de la aplicación: un *wrapper* aquí, un decorador de Python allá, una clase auxiliar en el *framework* del agente. Eso funciona hasta que tienes tres equipos de aplicación, dos proveedores de modelos, una adquisición, una auditoría PCI y un incidente de límite de velocidad un martes.
En ese momento, descubres que has construido cuatro planos de control ligeramente diferentes que no concuerdan, y que ninguno de ellos puede detener una solicitud de un equipo que no importó el *wrapper*. La pasarela existe por la misma razón que existían las pasarelas API hace una década: es el único lugar donde cada solicitud, de cada aplicación, en cada entorno, puede ser observada y moldeada de manera uniforme.
La objeción a una pasarela es siempre 'un salto más en la ruta de la solicitud'. La pasarela de IA de TrueFoundry añade aproximadamente 5 ms de sobrecarga p50 y gestiona más de 350 solicitudes por segundo en una única vCPU. La objeción no se sostiene ante los números.
La pasarela es también el único lugar que puede abarcar toda la superficie de la infraestructura de IA moderna: más de 1000 LLM de más de 19 proveedores, además de los servidores MCP a los que llaman sus agentes, y los modelos autoalojados detrás de su VPC. TrueFoundry fue mencionada en el informe de Gartner '10 mejores prácticas para optimizar los costes de IA generativa y agéntica 2026', porque la única forma en que las empresas optimizan realmente en esta superficie es ejecutando cada solicitud a través de una capa gobernada.
→ Arquitectura de la plataforma
→ Arquitectura del plano de la pasarela
La maximización de tokens es un síntoma de una adopción de IA sin gestión. La arquitectura anterior es la cura. La identidad define quién pregunta. La política define qué está permitido. La seguridad define qué es aceptable. La observabilidad define qué ocurrió realmente. Juntos, convierten la actividad de tokens en bruto en un ciclo de vida de solicitud gobernado: responsable, útil, seguro y ajustable.
El objetivo no es reducir el uso de la IA. El objetivo es hacer que cada línea sea explicable.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada
© 2026 Todos los derechos reservados.



.webp)
.webp)











.webp)
.webp)