

July 22, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 8, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
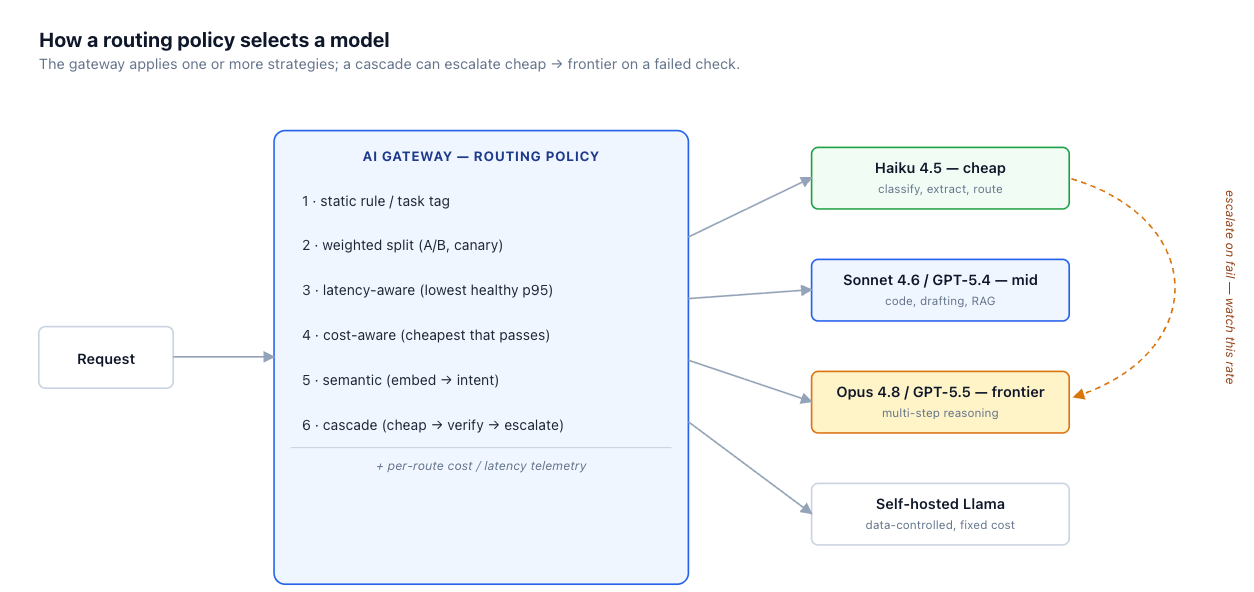
A 2026 application doesn't talk to one model — it talks to a menu of them, spanning frontier, mid-tier, cheap, and self-hosted. Routing is the policy that picks one per request, navigating three goals that pull against each other: cost, latency, and quality. This post walks the routing strategies from static rules to semantic routing and model cascades, the hard problem of measuring the quality you want to route on, why routing is not failover, and the instrumentation that keeps a router from quietly betraying you.
Tuesday at Northwind. Omar, a platform engineer, had spent the quarter proud of one number: a 41% drop in the company's LLM bill. He'd built a router. Simple classification and intent-detection calls went to a cheap model; only the genuinely hard requests — multi-step reasoning, code generation — reached the frontier model. It worked. Finance noticed.
Then the second week's bill came in at three times the first week's, with no traffic increase. Omar traced it. His cascade had a verifier — the cheap model's output was schema-checked, and on a failed check the request escalated to the frontier model. A provider-side update had subtly changed the cheap model's output formatting, the schema check started failing on most responses, and the router had quietly escalated about 90% of traffic to the most expensive model. Nothing errored. Nothing alerted. The router did exactly what it was told; it just stopped doing what Omar meant. The escalation rate had been climbing for nine days, and nobody was watching it.
Routing is often one of the highest-leverage cost levers in an LLM stack and one of the easiest to get quietly wrong. This post is the strategies, their tradeoffs, and the instrumentation that keeps a router honest.
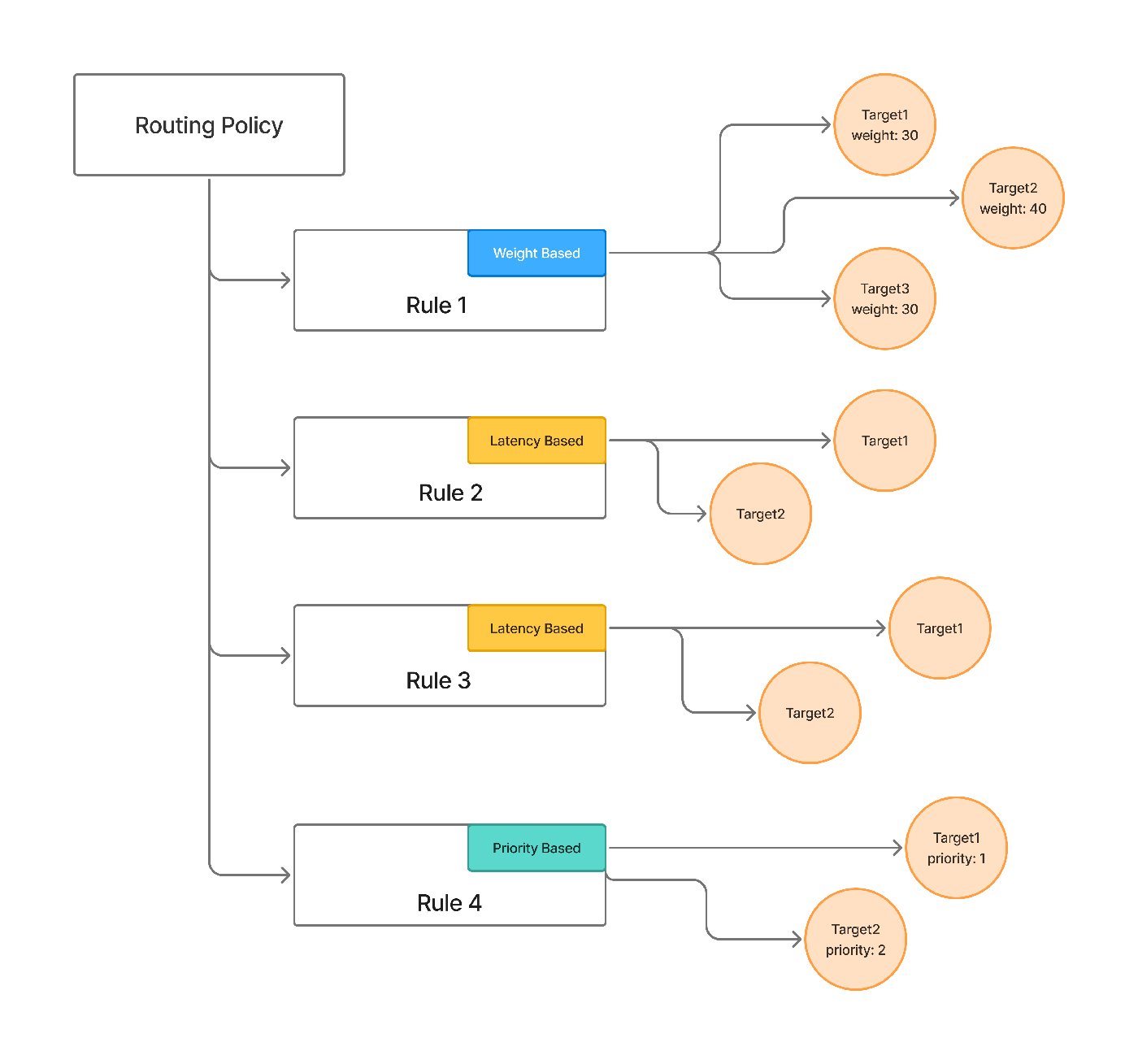
The routing strategies in this post aren't abstractions — they're how TrueFoundry's AI Gateway is configured. Its routing configuration matches each request by model, by subject (user, team, or virtual account), or by an X-TFY-METADATA header, evaluates rules top-to-bottom with first-match-wins, and sends the request to a target model — all as YAML applied at the gateway rather than branching logic in the app.
The three strategies map onto the ladder in section 2: weight-based for splits and canaries, latency-based to favor the lowest-latency healthy target, and priority-based for ordered preference with fallback. Per-target overrides also cover the model-specific-prompt problem this post raises — you can attach a different prompt_version_fqn per target so each model gets a prompt tuned for it — alongside per-target retries and fallback. (For new setups the docs recommend Virtual Models, which package the same strategies, retries, and fallbacks with clearer per-model ownership and access control.)
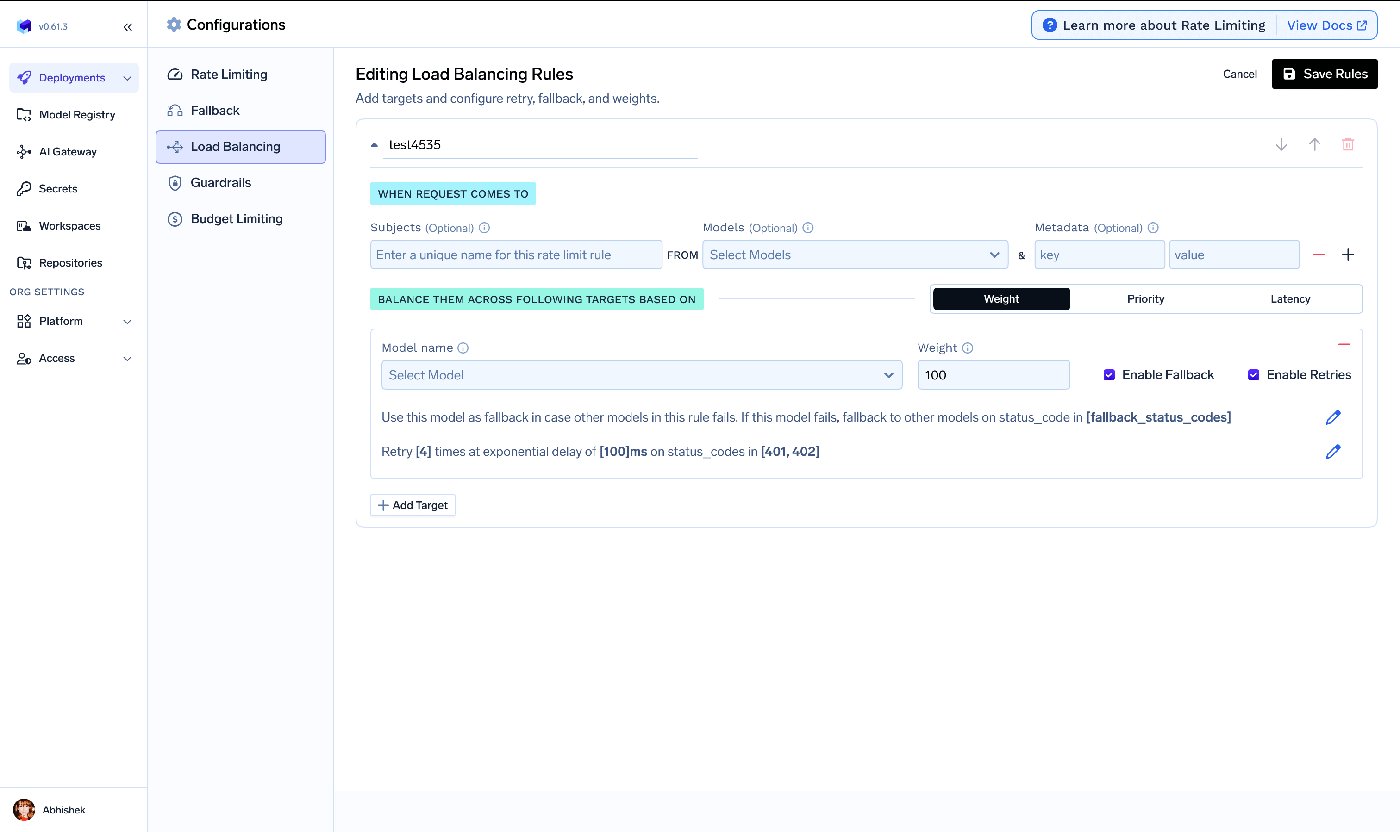
Calling the gateway from an application is a one-line change for anything already using the OpenAI SDK — same client, different base URL and key — and the routing decision happens at the gateway, not in your code. The application can also pass an X-TFY-METADATA header so the gateway routes by task, environment, or tenant without conditional code paths:
Calling the gateway from Python (OpenAI-compatible API)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-personal-access-token>", # Bearer-auth'd JWT
)
resp = client.chat.completions.create(
model="assistant", # logical/virtual model — gateway picks the target
extra_headers={"X-TFY-METADATA": '{"task": "classify"}'}, # drives the matching rule
messages=[{"role": "user", "content": "..."}],
)An enterprise app in 2026 has a menu of models with very different economics. Cheap models (Claude Haiku 4.5 at roughly $1 per million input tokens) are several times less expensive than frontier models on current standard rates, and often lower-latency in practice. Mid-tier models (Sonnet 4.6 at $3 per million input) sit in between. Self-hosted open-weight models (Llama, Mistral) trade per-token pricing for fixed GPU capacity and data control — cheaper at sustained high utilization, but expensive when utilization is low. Each model also has a different quality profile per task: a model that's excellent at code may be mediocre at extraction, and vice versa.
Routing is the policy that maps each incoming request to one of these models. The three goals pull against each other: the cheapest model is rarely the highest-quality, the fastest is not always the cheapest, and the best-quality model for a hard task is wasted on an easy one. The naive default — send everything to the best frontier model — maximizes quality but is the most expensive option and frequently the slowest, applying a multi-step reasoning model to requests a cheap model would answer correctly in a fraction of the time and cost. Routing is where that cost/quality frontier gets navigated, one request at a time.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada







.png)

.webp)
.webp)
.webp)




