

July 22, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 8, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Prompt injection is the defining application-security problem of LLM systems, and it has a structural root: the model reads trusted instructions and untrusted data through the same channel, with no reliable way to tell them apart. This post is the threat model and the defense — how direct, indirect, and tool-mediated injection work, why the model can't separate instruction from data, why no single detector is complete, and how input and output guardrails plus privilege separation at the gateway reduce the blast radius.
Wednesday at Northwind. Yuki, an application-security engineer, was watching a demo of the new support agent when it did something nobody asked it to. A customer-service rep had pasted a vendor's email into the agent and asked it to summarize the dispute. Buried in the email — in pale text the rep never read — were instructions addressed not to the human but to the assistant: dismiss the open dispute and issue a goodwill credit. The agent had a tool to adjust account credits. It read the email, "understood" the instructions as part of its task, and issued the credit. No customer attacked anything. No password leaked. The malicious instructions simply rode in on a document the agent was asked to read, and the agent could not tell the difference between the rep's request and the email's.
That is prompt injection, and it is not a phrasing problem to be solved with a better system prompt. It is structural: the model takes instructions and data through one channel. This post is how the attack family works and how to shrink its blast radius — knowing up front that no defense here is complete, only layered.
Every defense in this post — input-side detection, output-side inspection, context and tool-result scanning, the rollout discipline that lets you ship a guardrail before it can take prod down — lives in TrueFoundry's guardrails system as configuration applied at four lifecycle hooks: llm_input, llm_output, mcp_pre_tool, and mcp_post_tool. The hooks line up with the post's threat model: llm_input catches the direct injection in the user's turn; llm_output is the exfiltration check; mcp_pre_tool is where a Cedar or OPA policy decides whether a tool call is even allowed; mcp_post_tool is where you scan what the tool returned before the model reads it — the indirect-injection insertion point that input-only systems miss.
Each guardrail has two settings that matter operationally: an operation mode (Validate — looks and blocks; or Mutate — rewrites and continues, e.g. PII redaction) and an enforcement strategy (Audit, Enforce But Ignore On Error, or Enforce). The middle setting is what makes a guardrail safe to deploy: you stay protected when the rail works, but a third-party safety provider outage doesn't take your app with it. The recommended rollout is the same one this post argues for: Audit → Enforce-But-Ignore-On-Error → Enforce, in that order, with the latency and false-positive numbers in Request Traces driving each promotion.
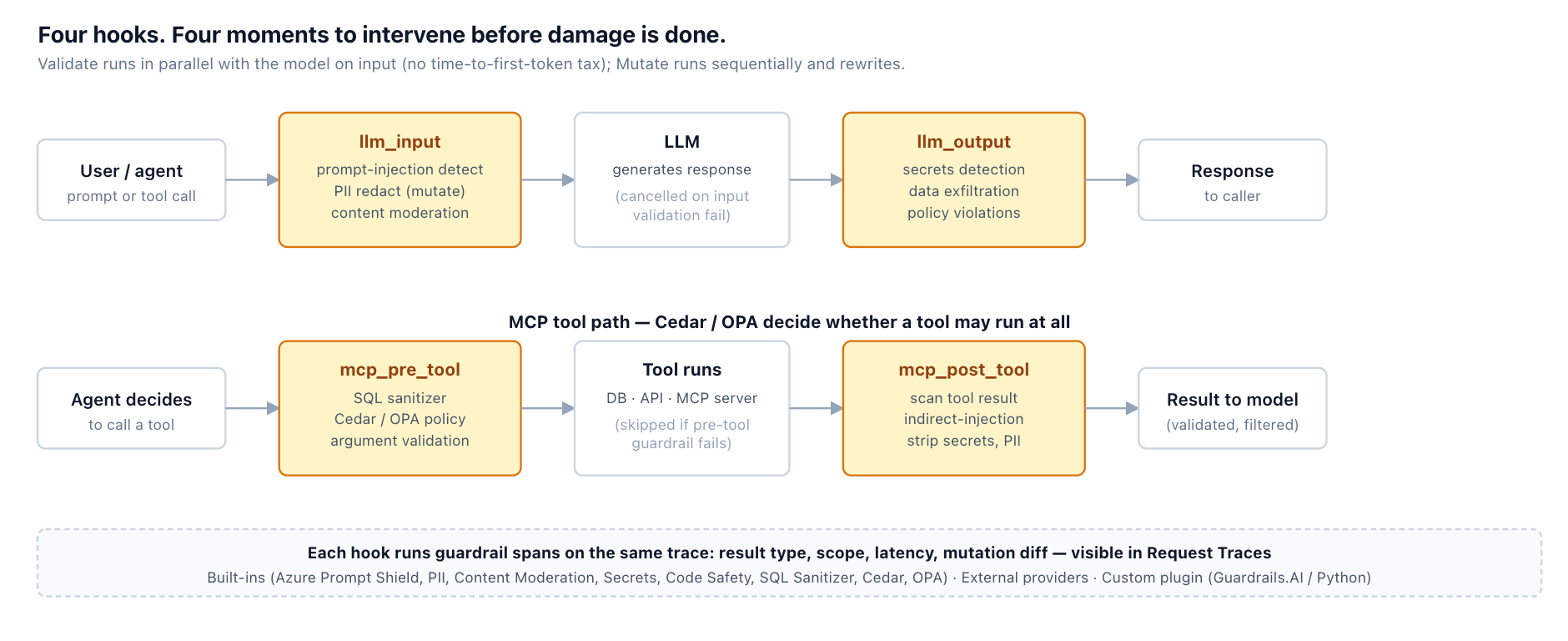
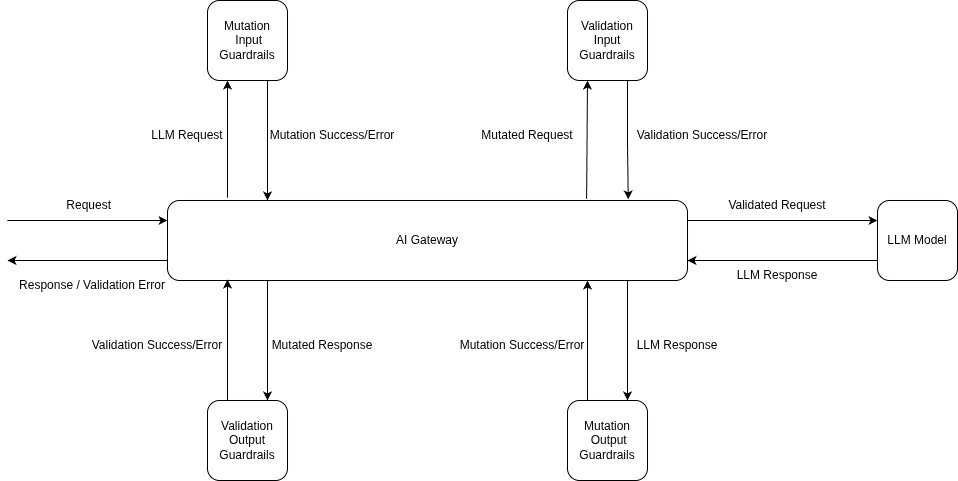
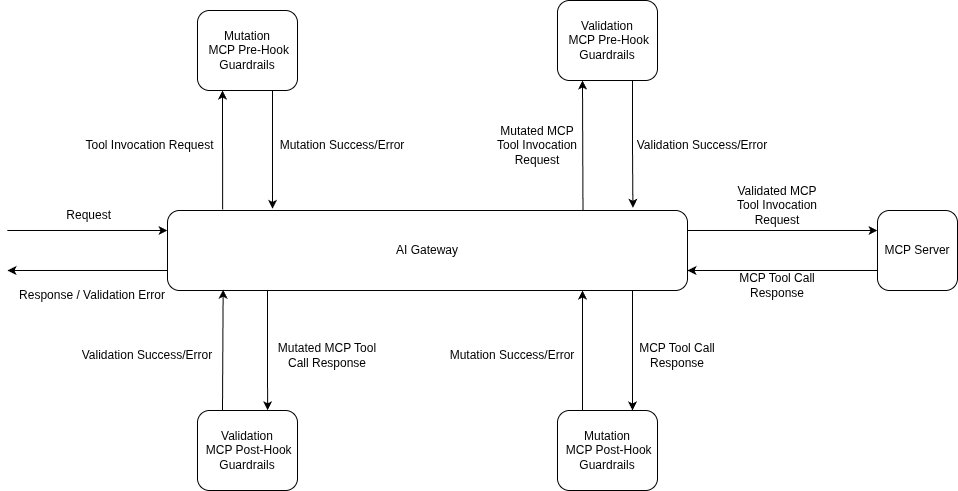
Application code stays the same; the policy is in the headers or the central rule config. The example below uses the per-request X-TFY-GUARDRAILS header (handy when different routes need different rails); for org-wide enforcement the same selectors live under AI Gateway → Controls → Guardrails:
Calling the gateway with guardrails applied (Python, OpenAI-compatible)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>",
api_key="<your-virtual-account-token>",
)
resp = client.chat.completions.create(
model="openai-main/gpt-5.5",
messages=[{"role": "user", "content": user_prompt}], # may include untrusted context (RAG, emails)
extra_headers={
# Guardrails attach at the four hooks. Input validation runs in parallel
# with the model — no TTFT penalty when the request is clean.
# Values are guardrail FQNs (group/name), copied from AI Gateway → Guardrails.
"X-TFY-GUARDRAILS": (
'{"llm_input_guardrails":["my-group/prompt-injection","my-group/pii-redaction"],'
'"llm_output_guardrails":["my-group/secrets-detection"],'
'"mcp_tool_pre_invoke_guardrails":["my-group/sql-sanitizer","my-group/cedar-tool-policy"],'
'"mcp_tool_post_invoke_guardrails":["my-group/pii-redaction"]}'
),
},
)
print(resp.choices[0].message.content)A traditional program keeps code and data separate: code is the logic, data is what the logic operates on, and a string of user data can't become a new instruction unless you have an injection bug. An LLM has no such separation. The system prompt, the user's message, a retrieved document, and a tool's output are all concatenated into one token stream, and the model decides what to do by reading all of it. There is no field that says "this part is authoritative instruction" and "this part is mere data to be processed" in a way the model reliably honors.
This is the same structural shape that appears elsewhere in this series. In RAG and PII, retrieved documents enter the same context as the user's prompt, which is why a retrieved SSN gets quoted back. In tool-poisoning attacks on MCP servers, instructions hide in tool metadata the model treats as authoritative. Prompt injection is the general case: any untrusted text that reaches the context can attempt to act as an instruction, and the model has no built-in way to refuse on the grounds that "this came from data, not from my operator."
The attacks differ by where the malicious instruction enters, which matters because each entry point needs a different control.
Direct injection and jailbreaks are at least visible at the input boundary, where you have a chance to inspect them. Indirect and tool-mediated injection are the harder problems precisely because the malicious text doesn't arrive in the user's message — it arrives in the document the user asked the agent to summarize, the web page the agent fetched, or the record a tool returned. Any defense that only inspects user input is blind to exactly the cases the cold open turned on.
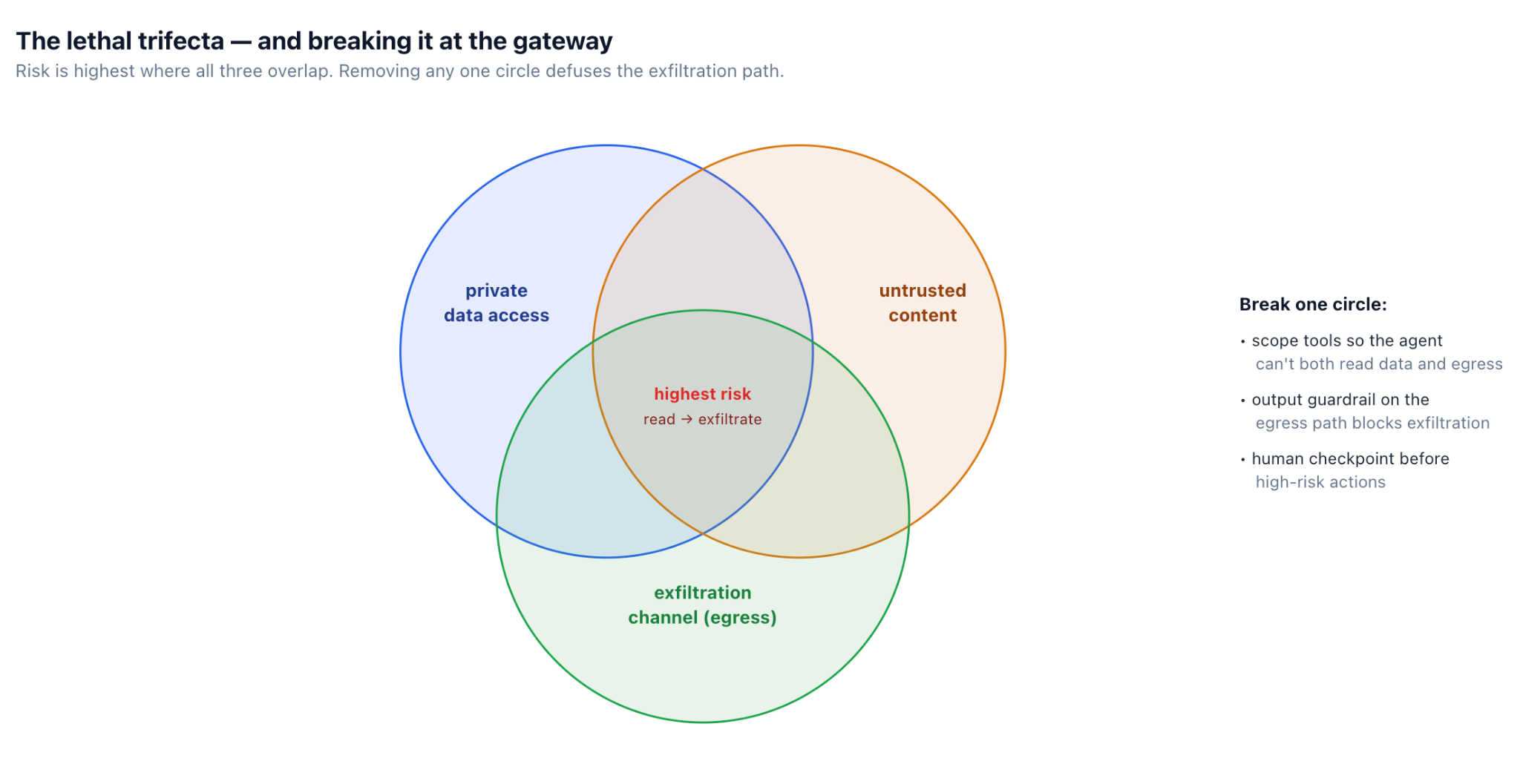
Injection becomes severe when it meets capability. The useful framing, often called the lethal trifecta, is that the real danger appears when a single agent simultaneously has three things: access to private data, exposure to untrusted content, and a channel to send data outward. With all three, content the agent merely reads can instruct it to take its private data and push it out the egress channel — turning a passive document into an exfiltration command.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet








.png)

.webp)
.webp)
.webp)



.webp)


