

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 8, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
KI-gestützte Codierungstools wie OpenCode verändern die Art und Weise, wie Entwickler mit Code interagieren, grundlegend. Anstatt mit isolierten Codefragmenten zu arbeiten, analysieren diese Systeme Dateien, Abhängigkeiten und den historischen Kontext. Das Ergebnis ist ein erheblicher Produktivitätsschub, aber auch eine neue Herausforderung in Bezug auf Kosten und Skalierbarkeit, die viele Teams unterschätzen: Verwendung von Tokens.
Im Gegensatz zu herkömmlichen Entwicklertools mit vorhersehbaren Lizenzkosten wird die Nutzung von OpenCode durch eine tokenbasierte Preisgestaltung geregelt. Jede Interaktion, Codegenerierung, Refactoring, Debugging oder Überprüfung — verbraucht Token. Da Teams die Nutzung auf Entwickler, Repositorys und automatisierte Agenten skalieren, wird der Token-Verbrauch zum wichtigsten Kostentreiber.
Was dies besonders schwierig macht, ist, dass die Verwendung von Token häufig nicht intuitiv. Kleine Änderungen der Kontextgröße, der Prompt-Struktur oder des Agentenverhaltens können zu großen Schwankungen beim Token-Verbrauch führen. Ohne ein klares mentales Modell dafür, wie Token verwendet werden, haben Teams Schwierigkeiten, Kosten vorherzusagen, Arbeitsabläufe zu optimieren oder Leitplanken durchzusetzen.
In diesem Blog wird beschrieben, wie die Token-Nutzung in OpenCode auf technischer Ebene funktioniert, warum codebezogene Workloads besonders tokenlastig sind und was Plattformteams verstehen sollten, bevor sie die Nutzung in der Produktion skalieren.
Im Kern folgt die Verwendung von OpenCode-Tokens der gleichen Mechanik wie die meisten LLM-betriebenen Systeme: Tokens werden sowohl für Eingaben als auch für Ausgaben verbraucht. Die Art der Codierungsworkloads führt jedoch zu zusätzlicher Komplexität.
Die Verwendung von OpenCode-Tokens kann grob in zwei Kategorien unterteilt werden:
In OpenCode enthalten Prompt-Token normalerweise:
Zu den Abschluss-Token gehören:
Aus Kostensicht Prompt-Token sind oft der dominierende Faktor bei der Verwendung von OpenCode, insbesondere wenn Repositorys und Kontextgrößen zunehmen.
Codebezogene Aufgaben verhalten sich ganz anders als Abfragen in natürlicher Sprache. Verschiedene Faktoren tragen zu einem höheren Token-Verbrauch bei:
Im Gegensatz zu Chat-basierten Anwendungsfällen sendet OpenCode häufig:
Selbst eine „kleine“ Codebasis kann schnell in Zehntausende oder Hunderttausende von Tokens übersetzt werden, wenn mehrere Dateien enthalten sind.
Der Quellcode ist dicht. Syntax, Einrückung, Symbole und Formatierung zählen alle zu den Tokens. Ein paar tausend Codezeilen können weit mehr Zeichen verbrauchen als eine entsprechende Menge an Klartext.
OpenCode-Workflows beinhalten häufig:
Bei jedem Schritt können Kontext- oder Zwischenausgaben erneut gesendet werden, wodurch die Token-Nutzung für eine einzelne Aufgabe multipliziert wird.
Wenn OpenCode über Agenten oder Automatisierung verwendet wird (z. B. durch Refactoring über mehrere Dateien hinweg oder Ausführung in CI-Pipelines), nimmt die Token-Nutzung schnell zu:
Dies macht die agentengesteuerte Nutzung leistungsstark, aber auch teuer, wenn nicht begrenzt.
Eine der größten Herausforderungen bei der Verwendung von OpenCode-Tokens besteht darin, Entwickler sehen selten, dass der vollständige Kontext an das Modell gesendet wird. Redakteure und Tools abstrakt:
Infolgedessen können zwei scheinbar ähnliche Aufgaben völlig unterschiedliche Token-Fußabdrücke haben. Ohne eine explizite Nachverfolgung auf Anforderungsebene entdecken Teams Kostenprobleme oft erst nach Nutzungsspitzen.
Aus diesem Grund reicht es nicht aus, die Token-Mechanik allein zu verstehen. Teams brauchen Einblick in den tatsächlichen Token-Verbrauch pro Aufgabe, pro Entwickler und pro Workflow um fundierte Optimierungsentscheidungen zu treffen.

Die meisten Spitzen bei der Nutzung von OpenCode-Tokens werden nicht durch einen einzigen offensichtlichen Fehler verursacht. Sie ergeben sich aus der Art und Weise, wie OpenCode in realen technischen Arbeitsabläufen verwendet wird — insbesondere, wenn Tools und Agenten tief in Entwicklungs- und Automatisierungspipelines integriert sind.
Im Folgenden sind die häufigsten Szenarien aufgeführt, die den Token-Verbrauch überproportional erhöhen.
Einer der größten Faktoren, die zur hohen Token-Nutzung beitragen, ist zu breite Kontextabgrenzung. Viele OpenCode-Workflows enthalten ganze Verzeichnisse oder große Teilmengen eines Repositorys, um „sicher zu sein“, auch wenn nur ein kleiner Teil des Codes relevant ist.
Zu den Beispielen gehören:
Da Prompt-Token linear mit der Kontextgröße skalieren, kann allein dieses Muster die Kosten schnell vervielfachen.
OpenCode arbeitet oft iterativ: Code generieren, überprüfen, anpassen, neu generieren. In vielen Setups jede Iteration sendet den vollständigen Kontext erneut, einschließlich Dateien und früherer Ausgaben.
Dies führt zu:
Ohne Caching oder intelligente Wiederverwendung von Kontexten wird die Iteration zu einem der teuersten Muster.
Wenn OpenCode über Agenten oder automatisierte Workflows verwendet wird, kann die Token-Nutzung schnell eskalieren, wenn die Ausführung nicht explizit begrenzt ist.
Zu den häufigsten Ursachen gehören:
Da diese Prozesse oft im Hintergrund ablaufen, bemerken Teams möglicherweise erst, wenn die Kosten in die Höhe schnellen.
Refactoring- und Review-Aufgaben sind in der Regel tokenintensiver als die Codegenerierung, da sie Folgendes erfordern:
Wenn diese Aufgaben auf große Codebasen oder mehrere Pull-Requests angewendet werden, steigt die Token-Nutzung erheblich.
Die Verwendung von OpenCode, der in CI-Pipelines oder Automatisierungsworkflows eingebettet ist, führt zu einem anderen Risikoprofil. Diese Systeme:
Selbst eine bescheidene Token-Nutzung pro Lauf kann teuer werden, wenn sie über viele Builds oder Bereitstellungen hinweg multipliziert wird.
Schließlich ist einer der am meisten übersehenen Treiber für eine hohe Token-Nutzung das Fehlen von Sichtbarkeit. Wenn Teams nichts sehen können:
Optimierung wird zum Rätselraten. Teams reagieren darauf oft, indem sie die Nutzung global einschränken, anstatt sich mit den spezifischen Workflows zu befassen, die die Kosten in die Höhe treiben.
Sobald die Teams verstanden haben, woher die Token-Nutzung kommt, ist der nächste Schritt die Optimierung. Wichtig ist, dass es bei der Optimierung nicht darum geht, die Nutzung willkürlich einzuschränken, sondern darum Absichtliches Verwenden von Tokens damit Produktivitätssteigerungen nicht zu unkontrollierten Kosten werden.
Im Folgenden finden Sie praktische Best Practices, die die Verwendung von OpenCode-Tokens konsequent reduzieren, ohne die Ausgabequalität zu beeinträchtigen.
Der effektivste Optimierungshebel ist Steuern, welcher Kontext an das Modell gesendet wird. Mehr Kontext ist nicht immer besser, besonders wenn er irrelevant ist.
Zu den praktischen Techniken gehören:
Eine gute Faustregel: Wenn eine Datei nicht erforderlich ist Grund für die Änderung, es sollte nicht Teil der Aufforderung sein.
Anstatt große Mengen an Code im Voraus zu senden, sollten Teams dazu übergehen Abruf auf Abruf.
Beispiele:
Dieser Ansatz reduziert die Größe der Eingabeaufforderung und verbessert gleichzeitig häufig die Qualität der Argumentation, da das Modell gezieltere Informationen erhält.
Generische Aufforderungen fördern in der Regel umfassendere Überlegungen und größere Ergebnisse, was sowohl die Anzahl der Eingabeaufforderungen als auch die Abschlusswerte erhöht.
Bessere Muster:
Eingabeaufforderungen mit Aufgabenbereich reduzieren nicht nur die Token-Nutzung, sondern verbessern auch den Determinismus.
Agentenbasierte Workflows verstärken die Token-Nutzung, wenn sie nicht aktiviert sind. Jeder Agent sollte innerhalb klar definierter Grenzen arbeiten.
Zu den wichtigsten Leitplanken gehören:
Ohne diese Grenzen können Agenten unbeabsichtigt große Kontexte mehrfach neu verarbeiten, was die Nutzung in die Höhe treibt.
Viele OpenCode-Workflows wiederholen ähnliche Aufgaben über Iterationen oder Benutzer hinweg. Durch Caching kann der Verbrauch redundanter Token erheblich reduziert werden.
Anwendbare Szenarien:
Selbst teilweises Caching auf Workflow-Ebene kann zu erheblichen Einsparungen führen.
Während Eingabeaufforderungs-Tokens oft dominieren, spielen auch Abschlusstoken eine wichtige Rolle, insbesondere bei Refactoring- oder erklärungsintensiven Workflows.
Zu den Techniken gehören:
Klare Ausgabebeschränkungen reduzieren unnötige Ausführlichkeit.
Schließlich sollte die Optimierung nicht reaktiv sein. Teams sollten die Verwendung von Tokens instrumentieren vom ersten Tag an.
Zumindest bedeutet das Tracking:
Ohne diese Daten können Teams nicht zwischen produktiver Nutzung und Verschwendung unterscheiden.
Die meisten Teams haben am ersten Tag keine Probleme mit der Verwendung von OpenCode-Tokens. Die Probleme treten allmählich auf, da sich die Nutzung auf Entwickler, Repositorys und automatisierte Workflows ausbreitet. Was als individuelles Produktivitätstool beginnt, wird schnell zu einer gemeinsamen Infrastruktur, und die Token-Nutzung skaliert auf eine Weise, die schwer vorherzusagen oder zu verwalten ist.
Im großen Maßstab wird OpenCode nicht mehr von einem einzelnen Entwickler in einem Editor verwendet. Es wird verwendet von:
Jeder dieser Verbraucher generiert unabhängig die Token-Nutzung. Ohne eine zentrale Ansicht wird es schwierig, grundlegende Fragen zu beantworten wie wer benutzt Tokens, zu welchem Zweck, und zu welchem Preis.
Frühe Optimierungsbemühungen werden häufig auf Anwendungs- oder Toolebene, benutzerdefinierte Eingabeaufforderungslimits, Kontextausgleich oder Wiederholungslogik implementiert. Diese helfen zwar lokal, lassen sich aber nicht auf folgende Bereiche skalieren:
Infolgedessen werden die Politiken fragmentiert und inkonsistent. Ein Team optimiert aggressiv, während ein anderes unwissentlich die Kosten in die Höhe treibt.
Automatisierung verändert die Mathematik. Ein Workflow, der eine bescheidene Anzahl von Token pro Lauf verbraucht, kann teuer werden, wenn:
Da diese Jobs ohne direkte menschliche Sichtbarkeit ausgeführt werden, nehmen die Ineffizienzen schnell zu. Spitzen bei der Token-Nutzung sind häufig eher auf die Automatisierung als auf die interaktive Nutzung zurückzuführen.
Ohne eine detaillierte Zuordnung sehen Teams nur aggregierte Nutzungszahlen. Das macht die Optimierung reaktiv und unverblümt.
Zu den häufigsten Ausfallarten gehören:
Effektive Kontrolle erfordert Wissen welche Arbeitsabläufe Mehrwert generieren und welche Abfall erzeugen etwas, das aggregierte Kennzahlen nicht preisgeben können.
In vielen Unternehmen übertrifft die Einführung von KI-Tools die Unternehmensführung. Die Nutzung von OpenCode verbreitet sich schneller als:
Zu dem Zeitpunkt, zu dem die Verwendung von Tokens zu einem Problem wird, sind die Tools bereits tief in die Arbeitsabläufe eingebettet, was nachträgliche Kontrollen schwierig und störend macht.
Das Kernproblem ist nicht Missbrauch — es ist dezentrale Nutzung ohne zentrale Steuerung. Da OpenCode zu einer gemeinsam genutzten Infrastruktur wird, muss die Token-Nutzung auf die gleiche Weise verwaltet werden, wie Teams Rechen-, Speicher- oder CI-Ressourcen verwalten.
Dies erfordert:
Ohne diese Änderung bleibt die Token-Nutzung unvorhersehbar und die Optimierungsbemühungen bleiben reaktiv.
Sobald die OpenCode-Nutzung den Produktionsmaßstab erreicht hat, funktionieren Ad-hoc-Tracking und manuelle Optimierungen nicht mehr. In dieser Phase muss die Token-Nutzung wie jede andere gemeinsam genutzte Infrastrukturressource behandelt werden - kontinuierlich gemessen, zentral gesteuert und eigentumsgebunden.
Viele Teams verfolgen zunächst die Token-Nutzung in einzelnen Tools oder Workflows. Dies bietet zwar lokale Einblicke, geht aber schnell kaputt, wenn:
Jede Integration berichtet unterschiedlich über die Nutzung, und keine bietet eine ganzheitliche Ansicht. Infolgedessen fehlt den Plattformteams eine einzige Informationsquelle für den Token-Konsum.
Im großen Maßstab muss die Überwachung an der Ebene anfragen, nicht nur die Werkzeugebene. Effektive Erfassung von Setups:
Auf diese Weise können Teams Fragen beantworten wie:
Ohne diese Granularität bleiben Optimierungsbemühungen grob und oft fehlgeleitet.
Unternehmensführung beginnt mit der Attribution. Die Token-Nutzung muss den Eigentümern zugeordnet werden, die darauf reagieren können.
Zu den gängigen Attributionsmodellen gehören:
Sobald die Verantwortung geklärt ist, verlagern sich die Kostengespräche von der abstrakten Budgetierung hin zu konkreten Entscheidungen darüber, welche Workflows einen ausreichenden Mehrwert bieten.
Überwachung allein verhindert Kostenüberschreitungen nicht. Produktionssysteme benötigen Durchsetzungsmechanismen die in Echtzeit funktionieren.
Zu den typischen Leitplanken gehören:
Diese Kontrollen sollten zentral durchgesetzt werden, damit alle OpenCode-gestützten Workflows sie automatisch erben.
Der rote Faden, der sich durch effektive Regierungsstrukturen zieht, ist Zentralisierung. Richtlinien, Grenzwerte und Sichtbarkeit der Token-Nutzung müssen an einem gemeinsamen Kontrollpunkt gespeichert werden und müssen nicht erneut in allen Tools implementiert werden.
Hier kommen infrastrukturorientierte Plattformen wie Wahre Gießerei passt natürlich. Durch die Zentralisierung des KI-Datenverkehrs, der Beobachtbarkeit und der Durchsetzung von Richtlinien können Plattformteams die Nutzung von OpenCode-Tokens über Entwickler, Agenten und automatisierte Systeme hinweg einheitlich verwalten — ohne einzelne Teams auszubremsen.
Aus Plattformsicht besteht die zentrale Herausforderung bei der Verwendung von OpenCode-Tokens darin, nicht zu verstehen wie Tokens werden verbraucht, aber wo Kontrolle und Sichtbarkeit herrschen sollten.
TrueFoundry geht dieses Problem an, indem es die Nutzung von KI und LLM, einschließlich entwicklerorientierter Tools wie OpenCode, als gemeinsam genutzte Infrastruktur behandelt, die standardmäßig beobachtbar, kontrollierbar und kostenbewusst sein muss. Im Mittelpunkt dieses Ansatzes steht KI-Gateway, das als Kontrollebene für den gesamten LLM-Verkehr im gesamten Unternehmen fungiert.
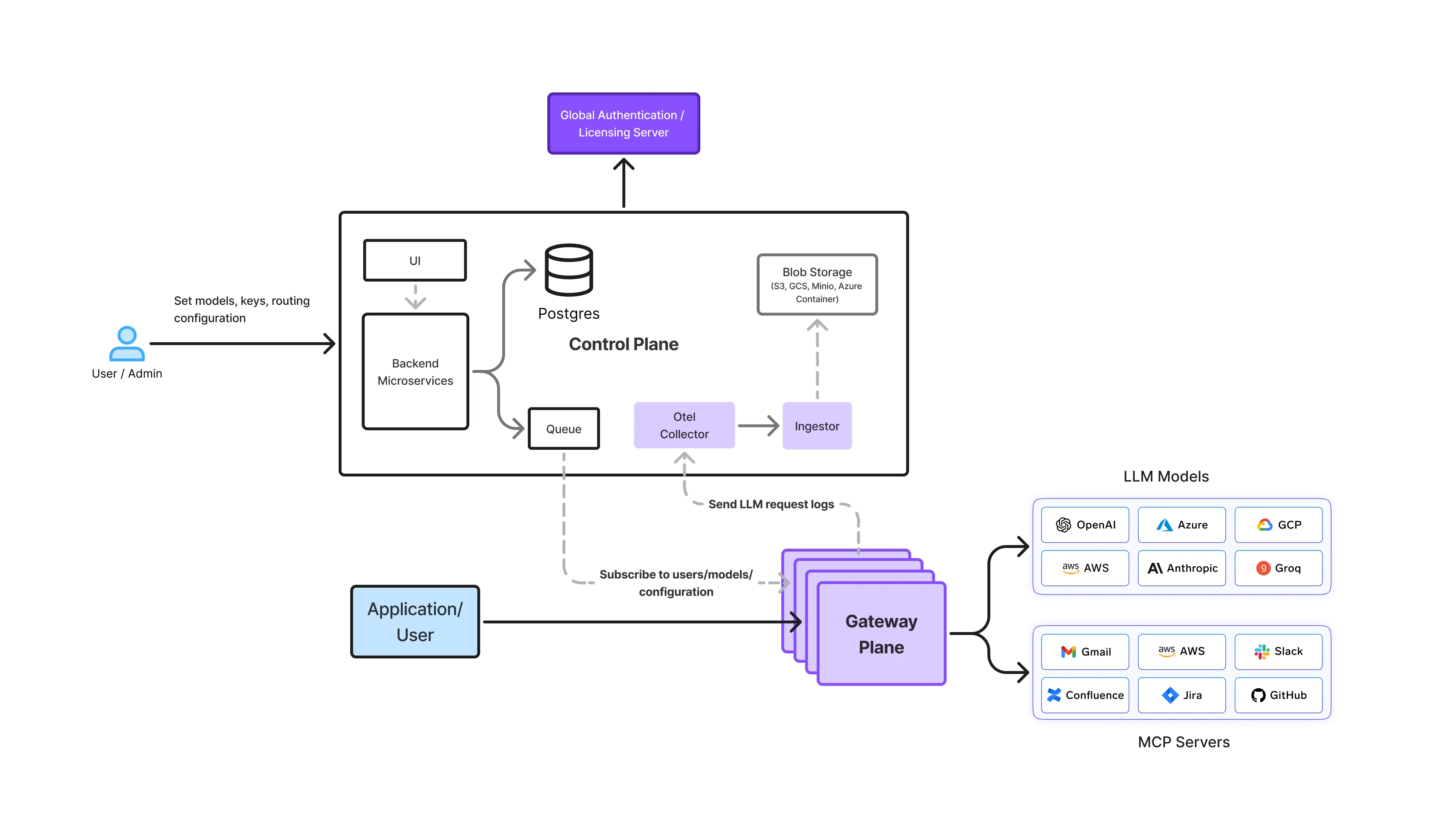
In einem TrueFoundry-Setup interagiert OpenCode nicht direkt mit den zugrunde liegenden LLM-Anbietern. Stattdessen laufen alle Anfragen über das AI Gateway, das eine einzige, konsistente Schnittstelle für Inferenzen bietet.
Architektonisch ermöglicht dies:
Durch den Wegfall des direkten Modellzugriffs aus einzelnen Tools erhalten Plattformteams einen vollständigen Überblick darüber, wie OpenCode tatsächlich von Entwicklern, Agenten und der Automatisierung genutzt wird.
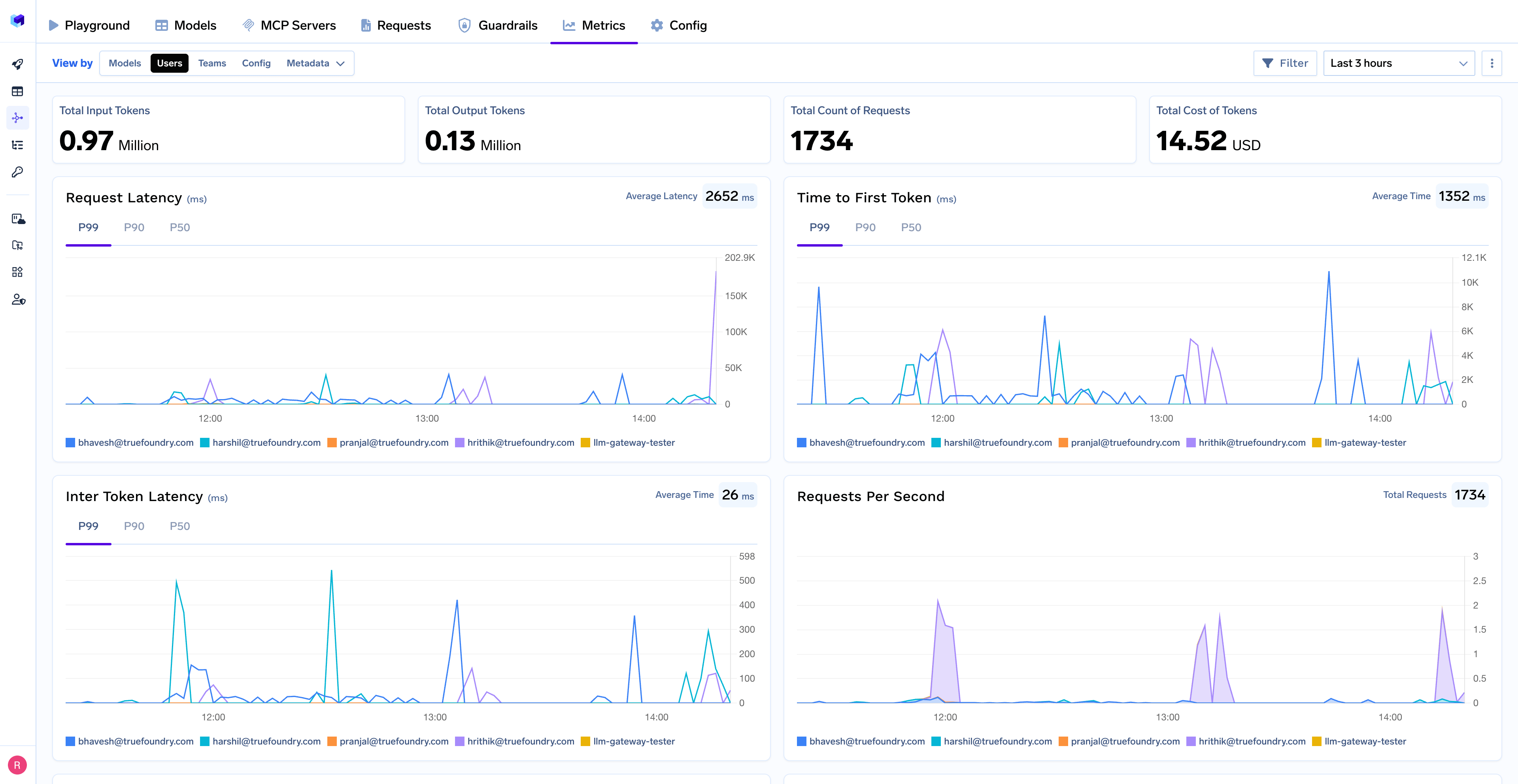
Das AI Gateway von TrueFoundry erfasst Token-Verwendung auf Anforderungsebene, einschließlich:
Entscheidend ist, dass diese Telemetrie nicht an ein vom Anbieter kontrolliertes System gebunden ist. Protokolle und Kennzahlen werden in der Cloud und im Speicher des Kunden gespeichert, sodass Teams:
Dadurch wird das bei KI-Tools häufig auftretende „Blackbox“ -Problem vermieden und eine langfristige Optimierung ermöglicht.
Da der gesamte OpenCode-Verkehr das Gateway durchläuft, können Kostenkontrollen angewendet werden konsistent und in Echtzeit.
Plattformteams können:
Diese Richtlinien werden einmal am Gateway durchgesetzt und gelten automatisch für jeden OpenCode-basierten Workflow, ohne dass Änderungen an Editoren, Plugins oder internen Tools erforderlich sind.
Die Architektur von TrueFoundry wurde für Umgebungen entwickelt, in denen die OpenCode-Nutzung über die IDE hinausgeht. CI-Pipelines, Hintergrundjobs und Agenten erzeugen oft den größten und am wenigsten sichtbaren Token-Verbrauch.
Indem Teams diese Workloads über dasselbe AI-Gateway weiterleiten, können sie:
Dadurch ist es möglich, die OpenCode-Nutzung im gesamten Unternehmen zu skalieren, ohne an Vorhersagbarkeit oder Kontrolle zu verlieren.
Die Verwendung von OpenCode-Tokens ist die eigentliche Skalierungsbeschränkung für KI-gestützte Codierung. Da sich die Nutzung auf Entwickler, Repositorys, Automatisierung und Agenten ausbreitet, wird es schwierig, den Token-Verbrauch ohne zentrale Transparenz und Steuerung vorherzusagen und zu kontrollieren.
Dies auf Tool- oder Anwendungsebene zu verwalten, ist nicht skalierbar. Die Token-Nutzung erfordert Beobachtbarkeit auf Anforderungsebene, klare Zuordnung und Durchsetzung in Echtzeit, wobei KI-gestütztes Programmieren als gemeinsam genutzte Infrastruktur und nicht als isolierte Funktion behandelt wird.
Plattformen wie Wahre Gießerei spiegeln Sie diesen Ansatz wider, indem Sie den OpenCode-Verkehr über ein KI-Gateway zentralisieren, sodass Teams die Token-Nutzung konsistent überwachen, steuern und optimieren können. Für führende Plattformen und Techniker ist die Erkenntnis einfach: Wenn OpenCode im Mittelpunkt der Softwareentwicklung steht, muss die Token-Nutzung mit der gleichen Sorgfalt verwaltet werden wie bei jeder anderen kritischen Infrastrukturressource.
Die genaue Überprüfung der Verwendung von Opencode-Tokens erfordert explizites Tracking und Instrumentierung auf Anforderungsebene. Da Tools oft den gesamten Kontext abstrahieren, der an das Modell gesendet wird, ist es entscheidend, einen Überblick über den tatsächlichen Token-Verbrauch pro Aufgabe, Entwickler und Workflow zu gewinnen, um Kosten vorherzusagen und Ihre Nutzung effektiv zu optimieren.
Die Verwendung von Opencode-Tokens ist das tokenbasierte Preismodell für KI-gestützte Codierungstools wie OpenCode. Jede Interaktion, von Eingabeaufforderungen und Codekontext bis hin zu generiertem Code und Erklärungen, verbraucht Token. Die Verwaltung dieser Opencode-Token-Nutzung ist von entscheidender Bedeutung, da sie für Entwicklungsteams in den USA zum Hauptkostentreiber wird.
Um die Verwendung von Opencode-Tokens zu reduzieren, beschränken Sie die Kontextinjektion auf wichtige Dateien und vermeiden Sie so eine breite Einbindung des Repositorys. Vermeiden Sie die wiederholte Rehydrierung von Kontexten, indem Sie Ausgaben über mehrere Iterationen hinweg intelligent wiederverwenden. Teilen Sie komplexe Aufgaben in kleinere Schritte auf und verwenden Sie präzise Eingabeaufforderungen. Die Überwachung des Token-Verbrauchs für jede Aufgabe liefert wichtige Erkenntnisse zur Optimierung von Kosten und Effizienz.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




