

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Unternehmen, die GenAI-Apps entwickeln, stehen vor einem bekannten Kompromiss: Eine reine Cloud beschleunigt Experimente, wirft aber Bedenken hinsichtlich der Unternehmensführung und der Kosten auf, während eine reine On-Premise-Lösung zwar die Kontrolle verschärft, die Teams jedoch verlangsamt. Der hybride Ansatz von TrueFoundry gleicht beides aus, indem er eine Split-Plane-Architektur, Kubernetes-native Abläufe und ein KI-Gateway kombiniert, das Governance, Routing und Observability zentralisiert.
- Halten Sie vertrauliche Daten geheim und bleiben Sie gleichzeitig flexibel. Führen Sie Vektordatenbanken, Einbettungen, Artefakte und zentrale Modelldienste in Ihren privaten Umgebungen (vor Ort oder VPC) aus und nutzen Sie Cloud-Endpunkte, wenn Sie Flexibilität benötigen.
- Standardisieren Sie den Zugriff auf Modelle. Das AI Gateway abstrahiert Anbieter, sodass Teams ohne Refactoring zwischen Endpunkten wechseln oder diese kombinieren können.
- Wenden Sie Governance an, ohne die Entwickler auszubremsen. Zentrale Richtlinien für Authentifizierung, Ratenlimits und Kosten ermöglichen es Plattform- und Sicherheitsteams, Leitplanken festzulegen, während die Entwickler den Versand fortsetzen.
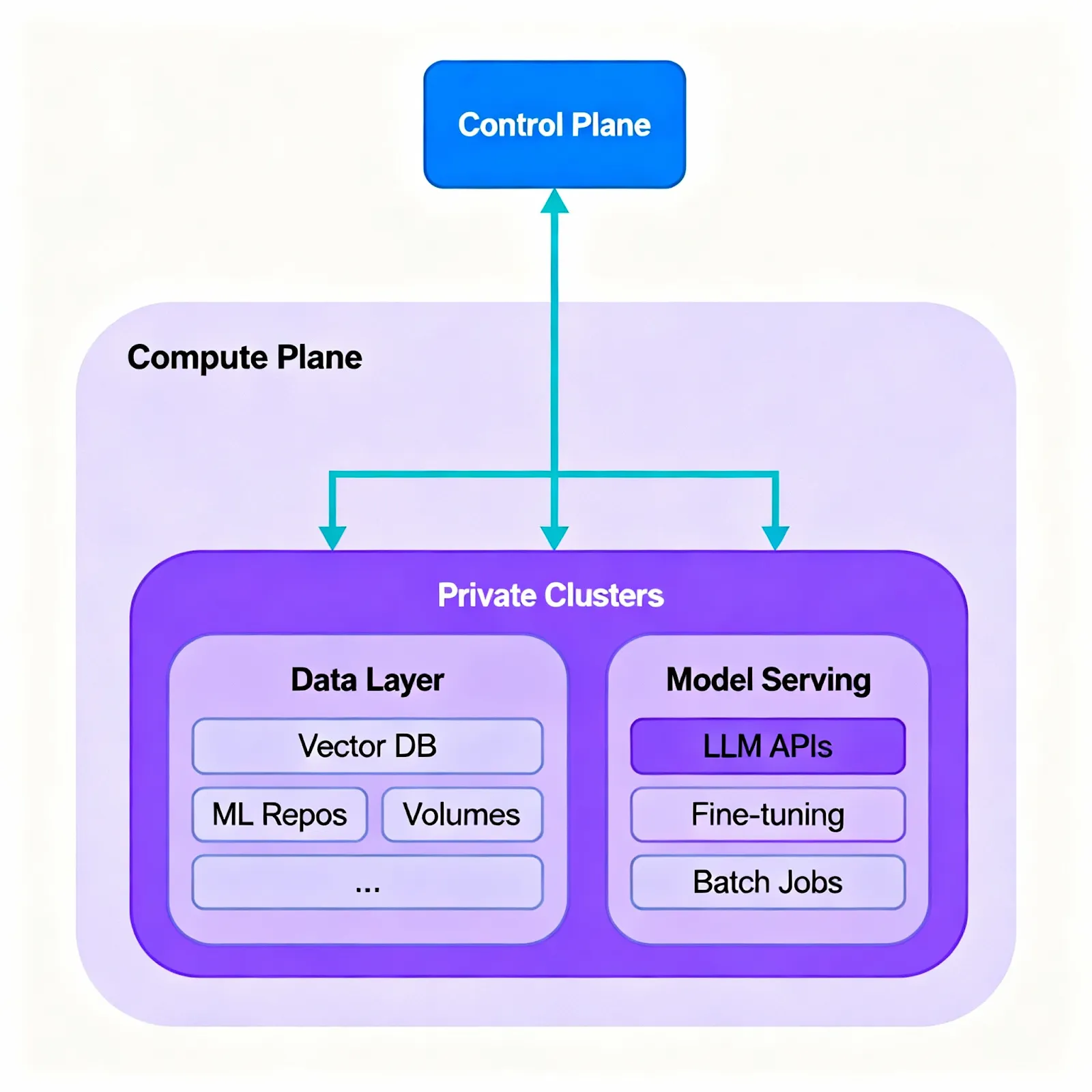
- Geteilte Steuerungs- und Rechenebene: Verwenden Sie eine gehostete oder selbst gehostete Steuerungsebene für Orchestrierung, Richtlinien und Beobachtbarkeit; führen Sie Rechenebenen in privaten Clustern (vor Ort oder VPC) aus, in denen Workloads und Daten gespeichert sind. Diese Entkopplung ermöglicht konsistente Abläufe in allen Umgebungen.
- Kubernetes-nativer Betrieb: Stellen Sie Dienste und Jobs über YAML/CLI bereit; nutzen Sie Health Probes, Autoscaling und standardisierte Rollout-Strategien in allen Clustern; setzen Sie kanarische und blaue/grüne Werbeaktionen ein, um Risiken zu reduzieren; pausieren oder verkleinern Sie inaktive Stacks, um Ressourcen zu sparen.
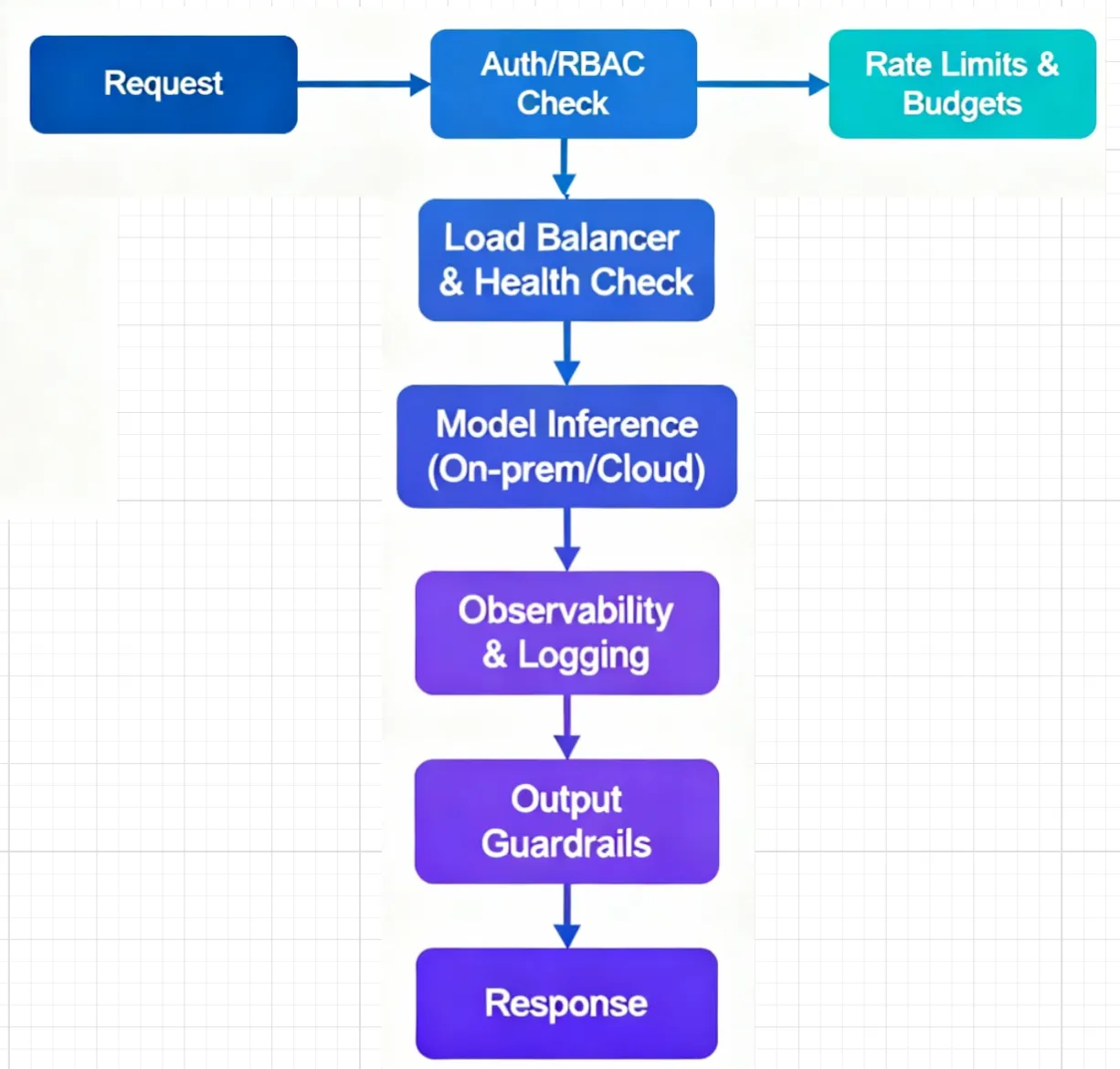
- Authentifizierung und RBAC: Zentralisieren Sie die Schlüssel, integrieren Sie SSO und regeln Sie den Zugriff nach Projekt/Team, um eine unkontrollierte Ausbreitung der Anmeldedaten zu vermeiden.
- Token-fähige Kontingente und Budgets: Lege Limits fest, die der LLM-Nutzung (Anfragen und Token) entsprechen und pro Benutzer, Team oder Modell gelten.
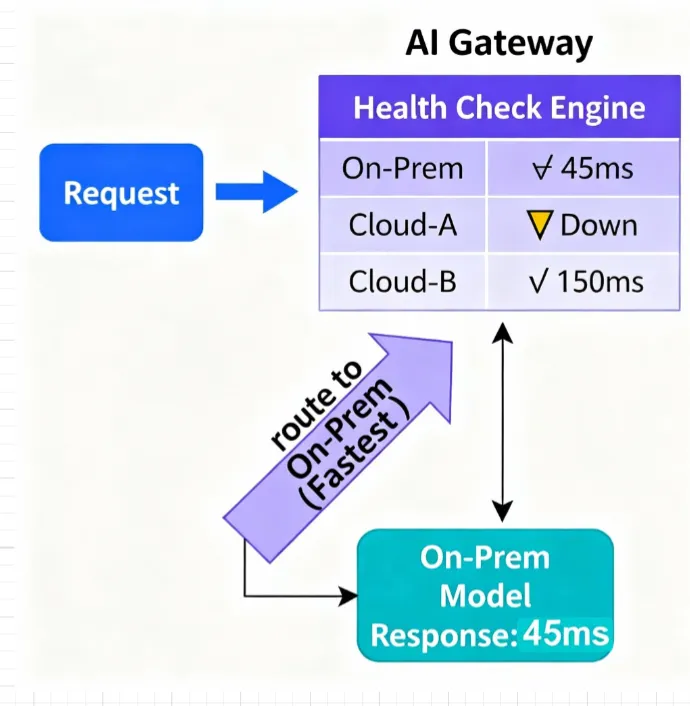
- Routing mehrerer Anbieter: Leiten Sie den Verkehr für Experimente nach Gewichtungen weiter, bevorzugen Sie schnellere, intakte Endpunkte nach Latenz und Zustand und führen Sie bei einem defekten Endpunkt ein automatisches Failover durch.
- Beobachtbarkeit und Kostenverfolgung: Verfolgen Sie Anfragen von Anfang bis Ende, vergleichen Sie Anbieter- und Modellverhalten in verschiedenen Umgebungen und ordnen Sie die Nutzung Teams und Anwendungen zu.
- Leitplanken: Wenden Sie Eingabe-/Ausgabeprüfungen an, um Aufforderungen und Antworten an die Unternehmensrichtlinien anzupassen.
- Richten Sie einen privaten Cluster ein (vor Ort oder VPC).
- Verbinde SSO und Secrets.
- Stellen Sie einen einfachen API-Dienst bereit und registrieren Sie ein Modell hinter dem AI Gateway; validieren Sie Routing, Protokolle und Traces.
- Leiten Sie bestehende Anwendungen über das Gateway weiter.
- Aktiviere RBAC, Token-fähige Kontingente/Budgets und gemeinsame Observability-Dashboards.
- Entfernen Sie fest codierte Anbieteranmeldeinformationen aus Apps; verwalten Sie sie zentral.
- Hosten Sie Vektor-DBs, Einbettungen und Artefakte in Ihrer privaten Umgebung.
- Stellen Sie wichtige Modelle für primäre Datenflüsse on-Premise/VPC bereit; nutzen Sie weiterhin Cloud-Endpunkte für Überläufe oder Experimente über Gateway-Routing.
- Fügen Sie Staging- und Produktionscluster über Standorte/Clouds hinweg hinzu.
- Nutze kanarische oder blaugrüne Werbeaktionen, skaliert automatisch nach Traffic und pausiere inaktive Umgebungen, wenn es angemessen ist.
- Vergleichen Sie das Verhalten von Äpfeln zu Äpfeln vor Ort und in der Cloud mit gängigen Protokollen und Metriken.
- Automatische Skalierung und Skalierung auf Null: Passen Sie die Kapazität an die Nachfrage nach APIs, Workern und Batch-Jobs an.
- Richtlinien-basiertes Routing: Leiten Sie den Traffic zu Endpunkten weiter, die Ihren Latenz-/SLA- und Budgetrichtlinien entsprechen, und greifen Sie auf Fehler oder Kontingentbeschränkungen zurück.
- Zentralisierte Budgets und Überprüfbarkeit: Setzen Sie Beschränkungen pro Team und Modell durch und behalten Sie eine zentrale Informationsquelle für Schlüssel, Zugriff und Nutzung.
- Sicherere Rollouts: Canary- und Blue/Green-Strategien reduzieren den Explosionsradius und unterstützen ein schnelles Rollback.
- Konsistente Kontrollen: Richtlinien, Geheimnisse und Zugriff werden zentral verwaltet, während Entwickler Self-Service bereitstellen.
- Einheitliche Telemetrie: Protokolle, Metriken und Traces an einem Ort beschleunigen Debugging, Kapazitätsplanung und Kostenüberprüfungen.
- Überall derselbe Arbeitsablauf: Das Kubernetes-First-Modell sorgt dafür, dass Entwicklung, Staging und Produktion sowohl vor Ort als auch in der Cloud aufeinander abgestimmt sind.
- Schnelles „Bereitstellen und Skalieren“ für APIs und Worker mithilfe von Vorlagen und CLI/YAML-Flows.
- Integrierte Beobachtbarkeit, die die Feedback-Zyklen verkürzt.
- Wiederverwendbare Muster für gängige GenAI-Workloads (z. B. RAG-Pipelines, Chat-APIs, asynchrone Verarbeitung), sodass Teams liefern können, ohne die Infrastruktur neu erfinden zu müssen.
— Tag 1—2: Erstellen Sie eine private Rechenebene, verbinden Sie SSO/Secrets, stellen Sie eine kleine API und ein Modell hinter dem Gateway bereit und bestätigen Sie den Anforderungsfluss mit Tracing.
— Tag 3—5: Leiten Sie eine bestehende App durch das Gateway, aktivieren Sie Token-fähige Kontingente und Dashboards und standardisieren Sie die Anmeldeinformationen von Anbietern zentral.
- Woche 2: Fügen Sie eine zweite Umgebung hinzu, führen Sie Canary-Routing für einen produktionsnahen Endpunkt ein und testen Sie Autoscaling- und Fallback-Regeln.
- AI-Gateway-Architektur: https://www.truefoundry.com/blog/how-to-think-about-ai-gateway-architecture-in-the-generative-ai-stack
- KI-Plattformen vor Ort: https://www.truefoundry.com/blog/on-premise-ai-platform
- Strategien zum Lastenausgleich: https://www.truefoundry.com/blog/load-balancing-in-ai-gateway
- Bewährte Verfahren zur Ratenbegrenzung: https://www.truefoundry.com/blog/rate-limiting-in-llm-gateway
- Implementierung von KI-Leitplanken: https://www.truefoundry.com/blog/ai-guardrails-in-enterprise- Beobachtbarkeitsmuster: https://www.truefoundry.com/blog/observability-in-ai-gateway
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


