

July 20, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Angenommen, es gibt eine Mannschaft A beauftragt mit der Entwicklung einer RAG-Anwendung für Anwendungsfall-1, dann ist da Mannschaft B das entwickelt eine RAG-Anwendung für Anwendungsfall-2, und dann ist da Mannschaft C, das plant gerade für ihren bevorstehenden Anwendungsfall der RAG-Anwendung. Haben Sie sich gewünscht, dass der Aufbau von RAG-Pipelines für mehrere Teams einfach hätte sein sollen? Jedes Team muss nicht bei Null anfangen, sondern eine modulare Methode verwenden, bei der jedes Team die gleichen Basisfunktionen nutzen und darauf aufbauend effektiv eigene Apps entwickeln kann, ohne dass es zu Störungen kommt?
Mach dir keine Sorgen!! Deshalb haben wir geschaffen Cognita. RAG ist zwar unbestreitbar beeindruckend, aber der Prozess, damit eine funktionale Anwendung zu erstellen, kann entmutigend sein. In Bezug auf Implementierungs- und Entwicklungspraktiken gibt es eine Menge zu verstehen, angefangen bei der Auswahl der geeigneten KI-Modelle für den spezifischen Anwendungsfall bis hin zur effektiven Organisation von Daten, um die gewünschten Erkenntnisse zu gewinnen. Während Tools wie Lang-Kette und Llamaindex Um den Prototyp-Designprozess zu vereinfachen, gibt es noch keine zugängliche, gebrauchsfertige Open-Source-RAG-Vorlage, die bewährte Verfahren enthält und modulare Unterstützung bietet, sodass jeder sie schnell und einfach verwenden kann.
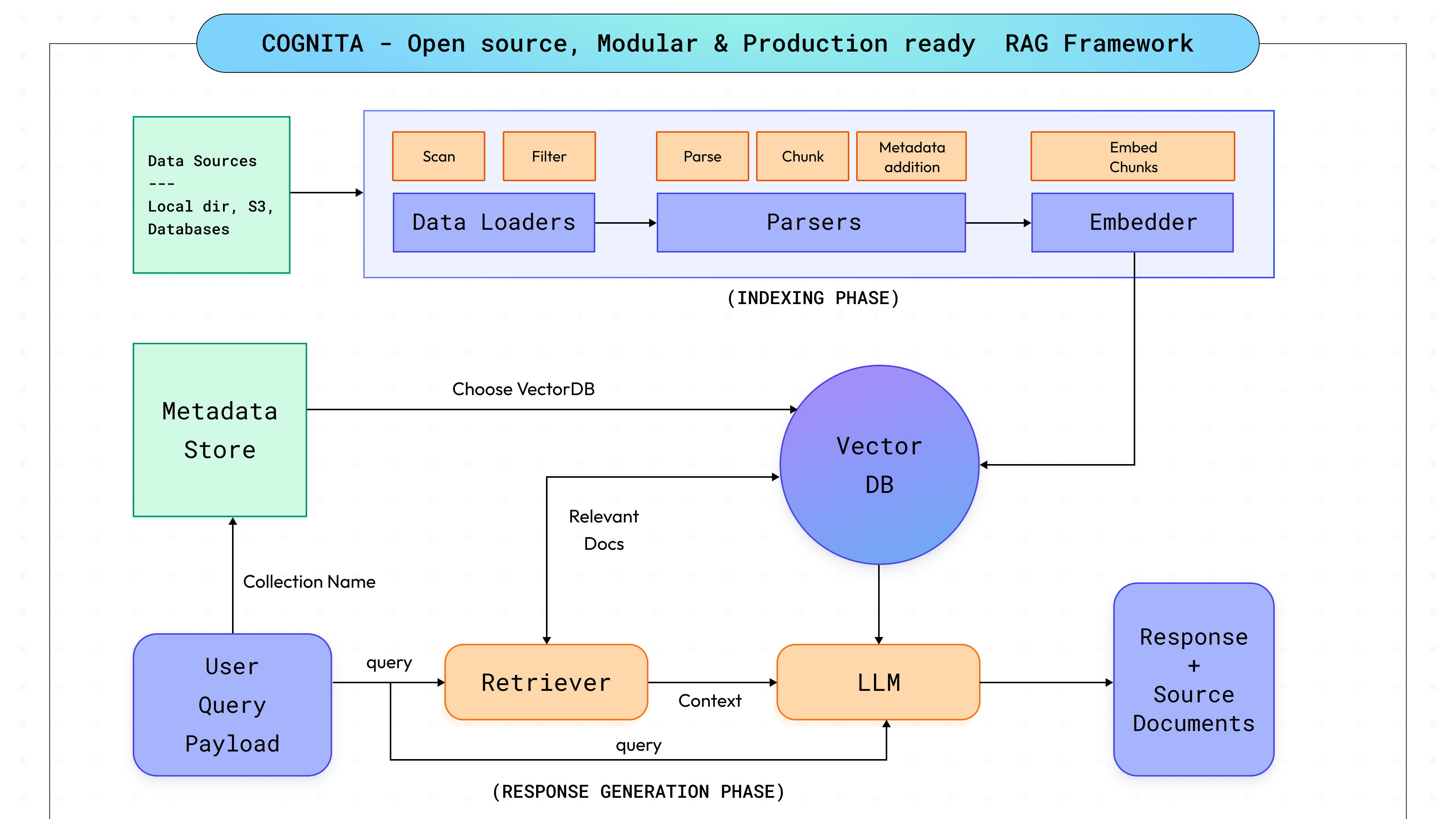
Eintauchen in das Innenleben von Cognita, unser Ziel war es, ein Gleichgewicht zwischen vollständiger Anpassung und Anpassungsfähigkeit zu finden und gleichzeitig die Benutzerfreundlichkeit von Anfang an zu gewährleisten. Angesichts der rasanten Fortschritte bei RAG und KI war es für uns unerlässlich, Cognita unter Berücksichtigung der Skalierbarkeit zu entwickeln, um eine nahtlose Integration neuer Durchbrüche und vielfältiger Anwendungsfälle zu ermöglichen. Dies veranlasste uns, den RAG-Prozess in verschiedene modulare Schritte zu unterteilen (wie in der obigen Abbildung dargestellt, die in den nachfolgenden Abschnitten erörtert wird), was eine einfachere Systemwartung ermöglichte, neue Funktionen wie die Interoperabilität mit anderen KI-Bibliotheken hinzufügte und es den Benutzern ermöglichte, die Plattform an ihre spezifischen Anforderungen anzupassen. Unser Fokus liegt weiterhin darauf, den Benutzern ein robustes Tool zur Verfügung zu stellen, das nicht nur ihren aktuellen Bedürfnissen entspricht, sondern sich auch parallel zur Technologie weiterentwickelt, einschließlich umfassenderer architektonischer Veränderungen wie MCP gegen RAG, um einen langfristigen Wert zu gewährleisten.
Cognita besteht aus sieben verschiedenen Modulen, die jeweils an unterschiedliche Bedürfnisse angepasst und gesteuert werden können:
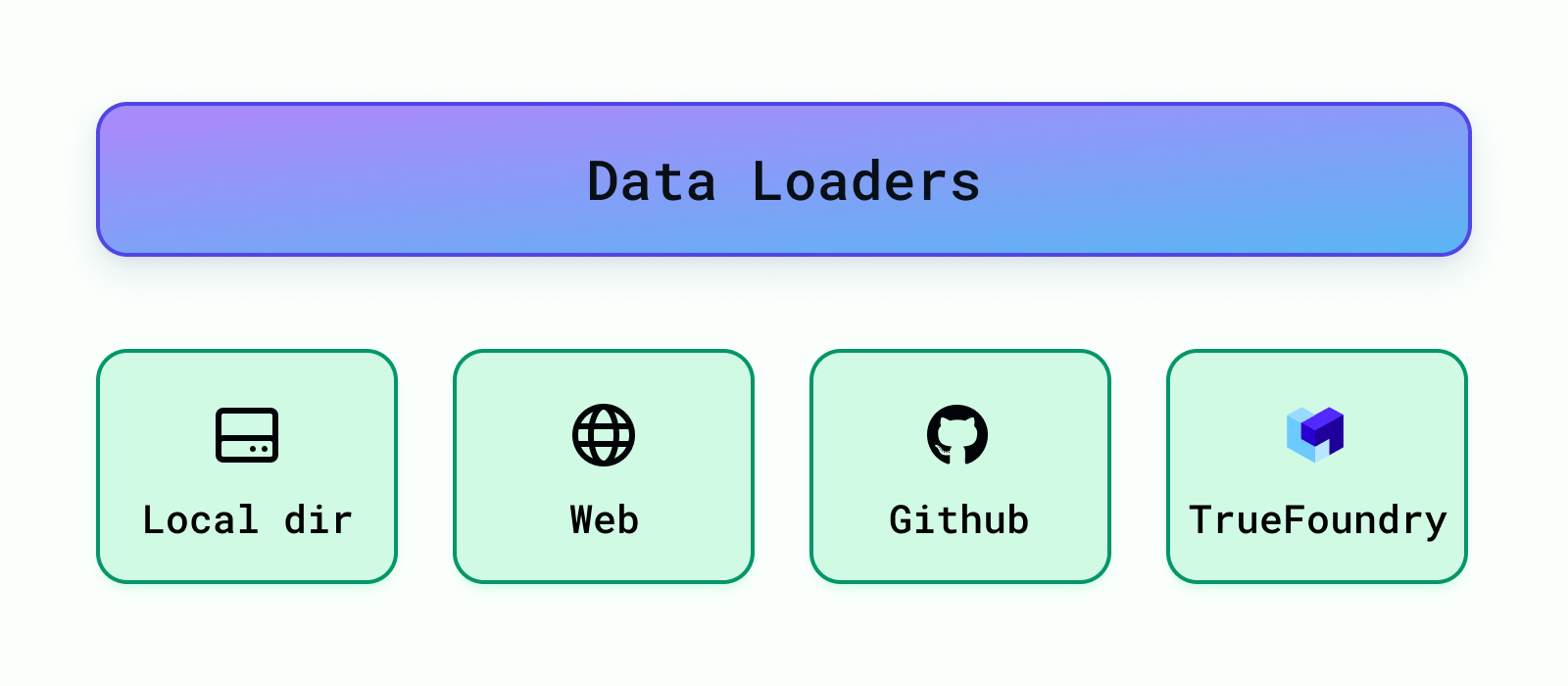
Diese laden die Daten aus verschiedenen Quellen wie lokalen Verzeichnissen, S3-Buckets, Datenbanken, Echte Gießerei Artefakte usw. Cognita unterstützt derzeit das Laden von Daten aus einem lokalen Verzeichnis, einer Web-URL, einem Github-Repository und Truefoundry-Artefakten. Weitere Datenlader können einfach hinzugefügt werden unter Backend/Module/Datenlader/ . Sobald ein Dataloader hinzugefügt wurde, müssen Sie ihn registrieren, damit er von der RAG-Anwendung unter verwendet werden kann backend/modules/dataloaders/__init__.py Um einen Dataloader zu registrieren, fügen Sie Folgendes hinzu:
In diesem Schritt befassen wir uns mit verschiedenen Arten von Daten, wie normalen Textdateien, PDFs und sogar Markdown-Dateien. Ziel ist es, all diese verschiedenen Typen in ein gemeinsames Format umzuwandeln, damit wir später einfacher mit ihnen arbeiten können. Dieser Teil, der als Parsen bezeichnet wird, dauert normalerweise am längsten und ist schwierig zu implementieren, wenn wir ein solches System einrichten. Aber die Verwendung von Cognita kann helfen, da es uns bereits die harte Arbeit der Verwaltung von Datenpipelines abnimmt.
Nachdem wir das gepostet haben, teilen wir die analysierten Daten in einheitliche Blöcke auf. Aber warum brauchen wir das? Der Text, den wir aus den Dateien erhalten, kann unterschiedlich lang sein. Wenn wir diese langen Texte direkt verwenden, fügen wir am Ende eine Menge unnötiger Informationen hinzu. Da alle LLMs außerdem nur eine bestimmte Textmenge gleichzeitig verarbeiten können, können wir nicht den gesamten wichtigen Kontext angeben, der für die Frage benötigt wird. Stattdessen werden wir den Text für jeden Abschnitt in kleinere Teile zerlegen. Intuitiv gesehen enthalten kleinere Abschnitte relevante Konzepte und sind im Vergleich zu größeren Abschnitten weniger laut.
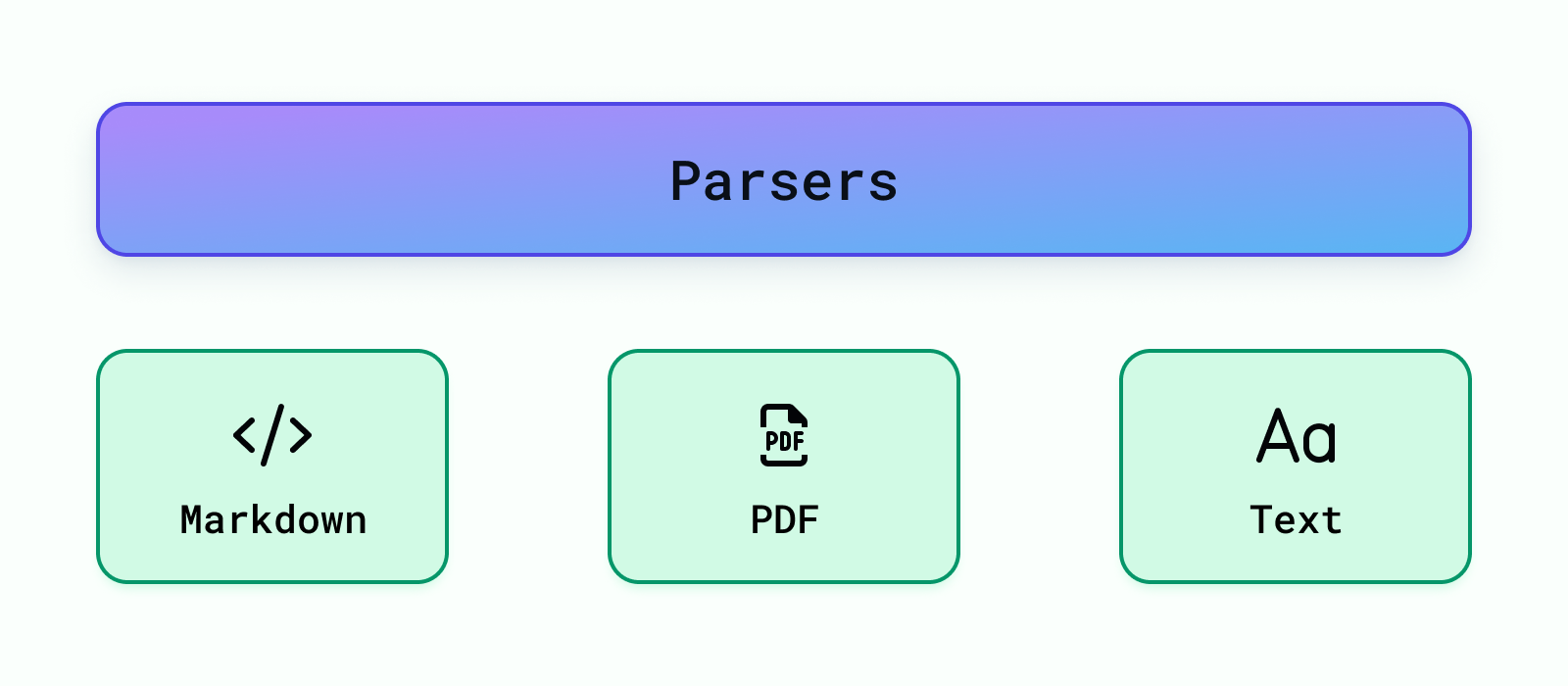
Derzeit unterstützen wir das Parsen für Abschlag, PDF und Text Dateien. Weitere Datenparser können einfach hinzugefügt werden unter Backend/Module/Parser/ . Sobald ein Parser hinzugefügt wurde, müssen Sie ihn registrieren, damit er von der RAG-Anwendung unter verwendet werden kann backend/modules/parsers/__init__.py Um einen Parser zu registrieren, fügen Sie Folgendes hinzu:
Sobald wir die Daten in kleinere Teile aufgeteilt haben, wollen wir die wichtigsten Teile für eine bestimmte Frage finden. Eine schnelle und effektive Methode, dies zu tun, besteht darin, ein vortrainiertes Modell (Einbettungsmodell) zu verwenden, um unsere Daten und die Frage in spezielle Codes umzuwandeln, die als Einbettungen bezeichnet werden. Dann vergleichen wir die Einbettungen der einzelnen Datenblöcke mit denen für die Frage. Durch die Messung der Kosinusähnlichkeit Zwischen diesen Einbettungen können wir herausfinden, welche Chunks am engsten mit der Frage zusammenhängen, was uns hilft, die besten zu verwenden.
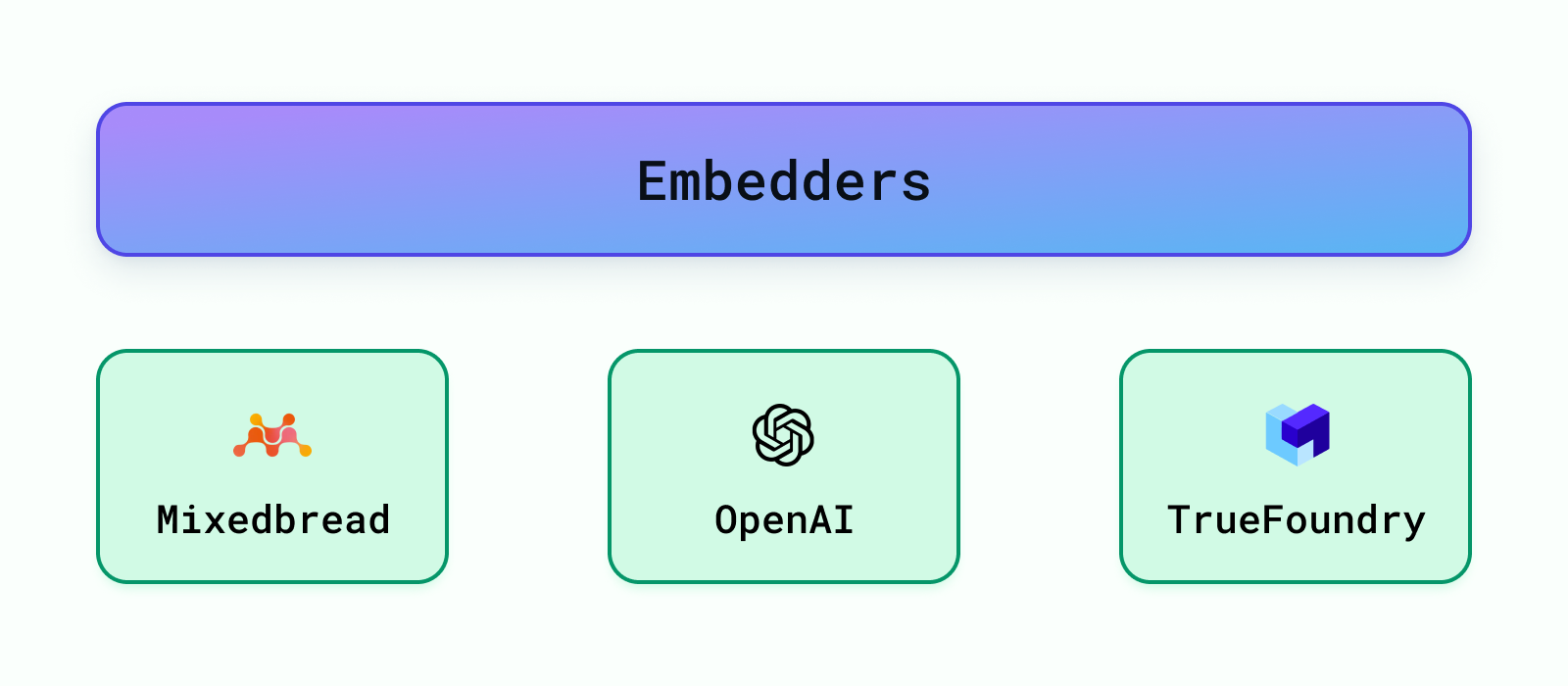
Zum Einbetten der Daten stehen viele vortrainierte Modelle zur Verfügung, z. B. Modelle von OpenAI, Cohere usw. Die beliebtesten Modelle finden Sie unter Der Benchmark für massive Texteinbettung (MTEB) von HuggingFace Bestenliste. Wir bieten Unterstützung für OpenAI Embeddings, TrueFoundry Embeddings und auch aktuelle SOTA Einbettungen (Stand April 2024) von gemischtes Brot - Ai.
Weitere Einbetter können einfach hinzugefügt werden unter Backend/Module/Embedder/ . Sobald ein Embedder hinzugefügt wurde, müssen Sie ihn registrieren, damit er von der RAG-Anwendung unter verwendet werden kann backend/modules/embedders/__init__.py Um einen Parser zu registrieren, fügen Sie Folgendes hinzu:
Hinweis: Denken Sie daran, dass Einbettungen nicht die einzige Methode sind, um wichtige Chunks zu finden. Wir könnten für diese Aufgabe auch ein LLM verwenden! LLMs sind jedoch viel größer als Einbettungsmodelle und haben eine Begrenzung der Textmenge, die sie gleichzeitig verarbeiten können. Deshalb ist es klüger, Einbettungen zu verwenden, um zuerst die besten K Chunks auszuwählen. Dann können wir LLMs für diese weniger Chunks verwenden, um herauszufinden, welche Chunks am besten als Kontext für die Beantwortung unserer Frage verwendet werden können.
Sobald beim Einbettungsschritt einige potenzielle Übereinstimmungen gefunden wurden, was eine Menge sein kann, wird ein Schritt zur Neubewertung durchgeführt. Eine Neubewertung stellt sicher, dass die besten Ergebnisse ganz oben stehen. Dadurch können wir die obersten x Dokumente auswählen, wodurch unser Kontext übersichtlicher wird und die Abfrage kürzer wird. Wir bieten Unterstützung für SOTA reranker (Stand April 2024) von gemischtes Brot - Ai was implementiert ist unter Backend/Module/Reranker/
Sobald wir Vektoren für Texte erstellt haben, speichern wir sie in einer sogenannten Vektordatenbank. Diese Datenbank verfolgt diese Vektoren, sodass wir sie später mit verschiedenen Methoden schnell finden können. Reguläre Datenbanken organisieren Daten in Tabellen, wie Zeilen und Spalten, aber Vektordatenbanken sind etwas Besonderes, da sie Daten speichern und finden, die auf diesen Vektoren basieren. Das ist sehr nützlich, um Bilder zu erkennen, Sprache zu verstehen oder Dinge zu empfehlen. In einem Empfehlungssystem wird beispielsweise jeder Artikel, den du empfehlen möchtest (wie ein Film oder ein Produkt), in einen Vektor umgewandelt, wobei verschiedene Teile des Vektors verschiedene Merkmale des Artikels repräsentieren, wie zum Beispiel sein Genre oder seinen Preis. Ähnlich verhält es sich bei Sprachkenntnissen: Jedes Wort oder Dokument wird in einen Vektor umgewandelt, wobei Teile des Vektors Merkmale des Wortes oder Dokuments darstellen, z. B. wie oft das Wort verwendet wird oder was es bedeutet. Diese Vektordatenbanken sind so konzipiert, dass sie diese effizient verarbeiten. Mithilfe verschiedener Methoden, um zu messen, wie nah Vektoren beieinander sind, z. B. wie ähnlich sie sind oder wie weit sie voneinander entfernt sind, finden wir Vektoren, die der angegebenen Benutzerabfrage am nächsten kommen. Die gängigsten Methoden, dies zu messen, sind die euklidische Entfernung, die Kosinusähnlichkeit und das Punktprodukt.
Es gibt verschiedene verfügbare Vektordatenbanken auf dem Markt, wie Qdrant, SingleStore, Weaviate usw. Wir unterstützen derzeit Adrant und Einzelner Laden. Die Klasse Qdrant Vector DB ist definiert unter /backend/modules/vector_db/qdrant.py, während die SingleStore Vector DB-Klasse definiert ist unter /backend/modules/vector_db/singlestore.py
Andere Vektor-DBs können auch hinzugefügt werden in der vektor_db Ordner und kann registriert werden unter /backend/modules/vector_db/__init__.py
Um Vektor-DB-Unterstützung in Cognita hinzuzufügen, muss der Benutzer Folgendes tun:
BasisvektorDB (aus backend.modules.vector_db.base importiere BaseVectorDB) und initialisieren Sie es mit Vector DBConfig (aus backend.types importiere VectorDBConfig)Sammlung erstellen: Um die Sammlung/das Projekt/die Tabelle in Vector DB zu initialisieren.upsert_documents: Um die Dokumente in die Datenbank einzufügen.get_collections: Ruft alle in der Datenbank vorhandenen Sammlungen ab.löschen_Sammlung: Um die Sammlung aus der Datenbank zu löschen.get_vector_store: Um den Vektorspeicher für die angegebene Sammlung abzurufen.get_vector_client: Um den Vektor-Client für die angegebene Sammlung abzurufen, falls vorhanden.list_daten_punkt_vektoren: Um bereits vorhandene Vektoren in der Datenbank aufzulisten, die den einzufügenden Dokumenten ähnlich sind.Datenpunkt-Vektoren löschen: Um die Vektoren aus der Datenbank zu löschen, werden alte Vektoren des aktualisierten Dokuments entfernt.Wir zeigen nun, wie wir dem RAG-System eine neue Vektor-DB hinzufügen können. Wir nehmen ein Beispiel für beide Adrant und Einzelner Laden Vektor-dbs.
Adrant ist eine Open-Source-Vektordatenbank und Vektor-Suchmaschine, die in Rust geschrieben wurde. Es bietet einen schnellen und skalierbaren Vektor Ähnlichkeitssuche Service mit praktischer API. Gehen Sie wie folgt vor, um die Qdrant-Vektordatenbank zum RAG-System hinzuzufügen:
In der ENV-Datei können Sie Folgendes hinzufügen
VECTOR_DB_CONFIG = '{"url“: "<url_here>„, „provider“: „qdrant"}' # Qdrant-URL für die bereitgestellte InstanzVECTOR_DB_CONFIG=' {"Anbieter“ :"qdrant“, "local“ :"true "} '# Für lokale dateibasierte Qdrant-Instanz ohne Docker
QDRANT Vector DB in backend/modules/vector_db/qdrant.py das erbt von BasisvektorDB und initialisiere es mit Vector DBConfigSammlung erstellen Methode zum Erstellen einer Sammlung in Adrantupsert_documents Methode zum Einfügen der Dokumente in die Datenbankget_collections Methode, um alle in der Datenbank vorhandenen Sammlungen abzurufenlöschen_Sammlung Methode zum Löschen der Sammlung aus der Datenbankget_vector_store Methode, um den Vektorspeicher für die angegebene Sammlung zu erhaltenget_vector_client Methode, um den Vektor-Client für die angegebene Sammlung abzurufen, falls vorhandenlist_daten_punkt_vektoren Methode, um bereits vorhandene Vektoren in der Datenbank aufzulisten, die den einzufügenden Dokumenten ähnlich sindDatenpunkt-Vektoren löschen Methode zum Löschen der Vektoren aus der Datenbank, die verwendet wird, um alte Vektoren des aktualisierten Dokuments zu entfernenSingleStore bietet leistungsstarke Vektordatenbankfunktionen, die sich perfekt für KI-basierte Anwendungen, Chatbots, Bilderkennung und mehr eignen, sodass Sie keine spezielle Vektordatenbank ausschließlich für Ihre Vektor-Workloads betreiben müssen. Im Gegensatz zu herkömmlichen Vektordatenbanken speichert SingleStore Vektordaten zusammen mit anderen Datentypen in relationalen Tabellen. Durch die Verknüpfung von Vektordaten mit verwandten Daten können Sie problemlos erweiterte Metadaten und andere Attribute Ihrer Vektordaten mit der vollen Leistungsfähigkeit von SQL abfragen.
SingleStore bietet Entwicklern eine kostenlose Stufe, um mit ihrer Vektordatenbank zu beginnen. Sie können sich für ein kostenloses Konto anmelden hier. Gehen Sie nach der Anmeldung zu Wolke -> Arbeitsplatz -> Benutzer erstellen. Verwenden Sie die Anmeldeinformationen, um eine Verbindung zur SingleStore-Instanz herzustellen.
In der ENV-Datei können Sie Folgendes hinzufügen
VECTOR_DB_CONFIG = '{"url“: "<url_here>„, „provider“: „singlestore"}' # url: mysql://{user}: {password} @ {host}: {port}/{db}
Gehen Sie wie folgt vor, um SingleStore vector db zum RAG-System hinzuzufügen:
SingleStore-Vector DB in backend/modules/vector_db/singlestore.py das erbt von BasisvektorDB und initialisiere es mit Vector DBConfigSammlung erstellen Methode zum Erstellen einer Sammlung in SingleStoreupsert_documents Methode zum Einfügen der Dokumente in die Datenbankget_collections Methode, um alle in der Datenbank vorhandenen Sammlungen abzurufenlöschen_Sammlung Methode zum Löschen der Sammlung aus der Datenbankget_vector_store Methode, um den Vektorspeicher für die angegebene Sammlung zu erhaltenget_vector_client Methode, um den Vektor-Client für die angegebene Sammlung abzurufen, falls vorhandenlist_daten_punkt_vektoren Methode, um bereits vorhandene Vektoren in der Datenbank aufzulisten, die den einzufügenden Dokumenten ähnlich sindDatenpunkt-Vektoren löschen Methode zum Löschen der Vektoren aus der Datenbank, die verwendet wird, um alte Vektoren des aktualisierten Dokuments zu entfernenDies enthält die notwendigen Konfigurationen, die ein Projekt oder eine RAG-App eindeutig definieren. Eine RAG-App kann eine Reihe von Dokumenten aus einer oder mehreren Datenquellen zusammen enthalten, die wir als Kollektion. Die Dokumente aus diesen Datenquellen werden mithilfe von Methoden zum Laden, Analysieren und Einbetten von Daten in die Vektordatenbank indexiert. Für jeden RAG-Anwendungsfall enthält der Metadatenspeicher:
Wir definieren derzeit zwei Möglichkeiten, diese Daten zu speichern, eine örtlich und andere Verwendungen Echtes Foudry. Diese Geschäfte sind definiert unter - Backend/Module/metada_store/
Sobald die Daten indexiert und in Vector DB gespeichert sind, ist es jetzt an der Zeit, alle Teile miteinander zu kombinieren, um unsere App zu verwenden. Query Controller machen das einfach! Sie helfen uns, die Antwort auf die entsprechende Benutzeranfrage abzurufen. Ein typischer Abfrage-Controller sieht wie folgt aus:
Name der Sammlung relevant Vektor-db wird mit seiner Konfiguration wie verwendeter Embedder, Vektor-DB-Typ usw. abgerufenabfragen, relevante Dokumente werden mit dem abgerufen Retriever von Vector DB.Kontext und zusammen mit der Abfrage a.k.a Frage wird gegeben an LLM um die Antwort zu generieren. Dieser Schritt kann auch eine schnelle Abstimmung beinhalten.Hinweis: Bei Agenten können die Zwischenschritte auch gestreamt werden. Es liegt an der jeweiligen App, das zu entscheiden.
Abfrage-Controller-Methoden können direkt als API bereitgestellt werden, indem den jeweiligen Funktionen HTTP-Dekoratoren hinzugefügt werden.
Gehen Sie wie folgt vor, um Ihren eigenen Abfrage-Controller hinzuzufügen:
App 2. Daher schreiben wir unseren Controller unter /backend/modules/query_controller/app-2/controller.pyQuery-Controller Decorator an Ihre Klasse und übergeben Sie den Namen Ihres benutzerdefinierten Controllers als ArgumentPost, erhalten, löschen um Ihre Methoden zu einer API zu machenbackend/modules/query_controllers/__init__.pyEin Beispiel für einen Abfrage-Controller ist geschrieben unter: /backend/modules/query_controller/example/controller.py Bitte beziehen Sie sich zum besseren Verständnis
Ein typischer Cognita-Prozess besteht aus zwei Phasen:
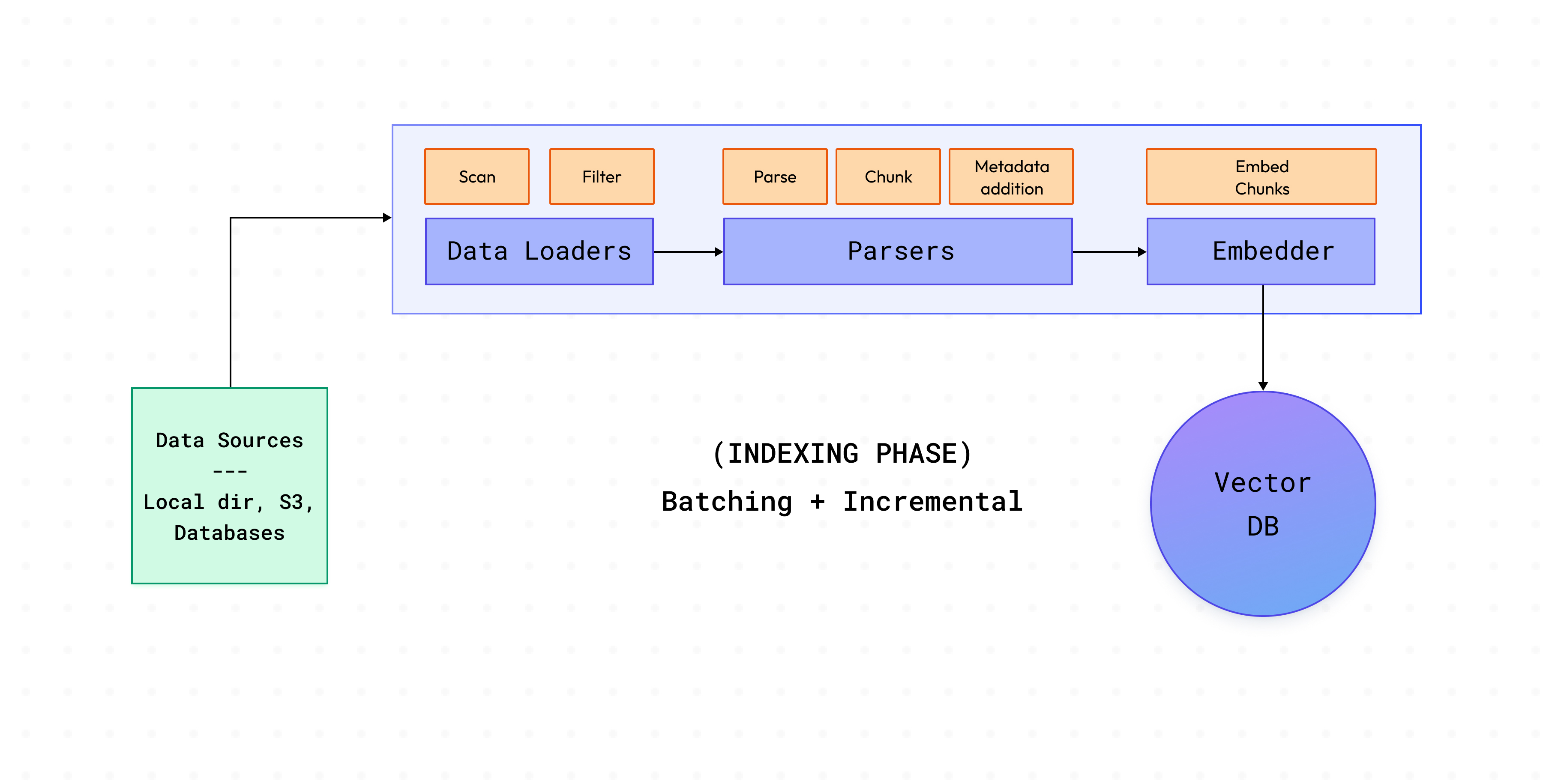
In dieser Phase werden Daten aus Quellen geladen, die in diesen Quellen vorhandenen Dokumente analysiert und in der Vektordatenbank indexiert. Cognita geht noch einen Schritt weiter, um große Mengen an Dokumenten verarbeiten zu können, die bei der Produktion anfallen.
INKREMENTELL Indizierung, es gibt auch einen anderen Modus, der in Cognita unterstützt wird, nämlich VOLL Indizierung. VOLL Bei der Indizierung werden die Daten erneut in den Vektor db aufgenommen, unabhängig davon, ob für die angegebene Sammlung Vektordaten vorhanden sind.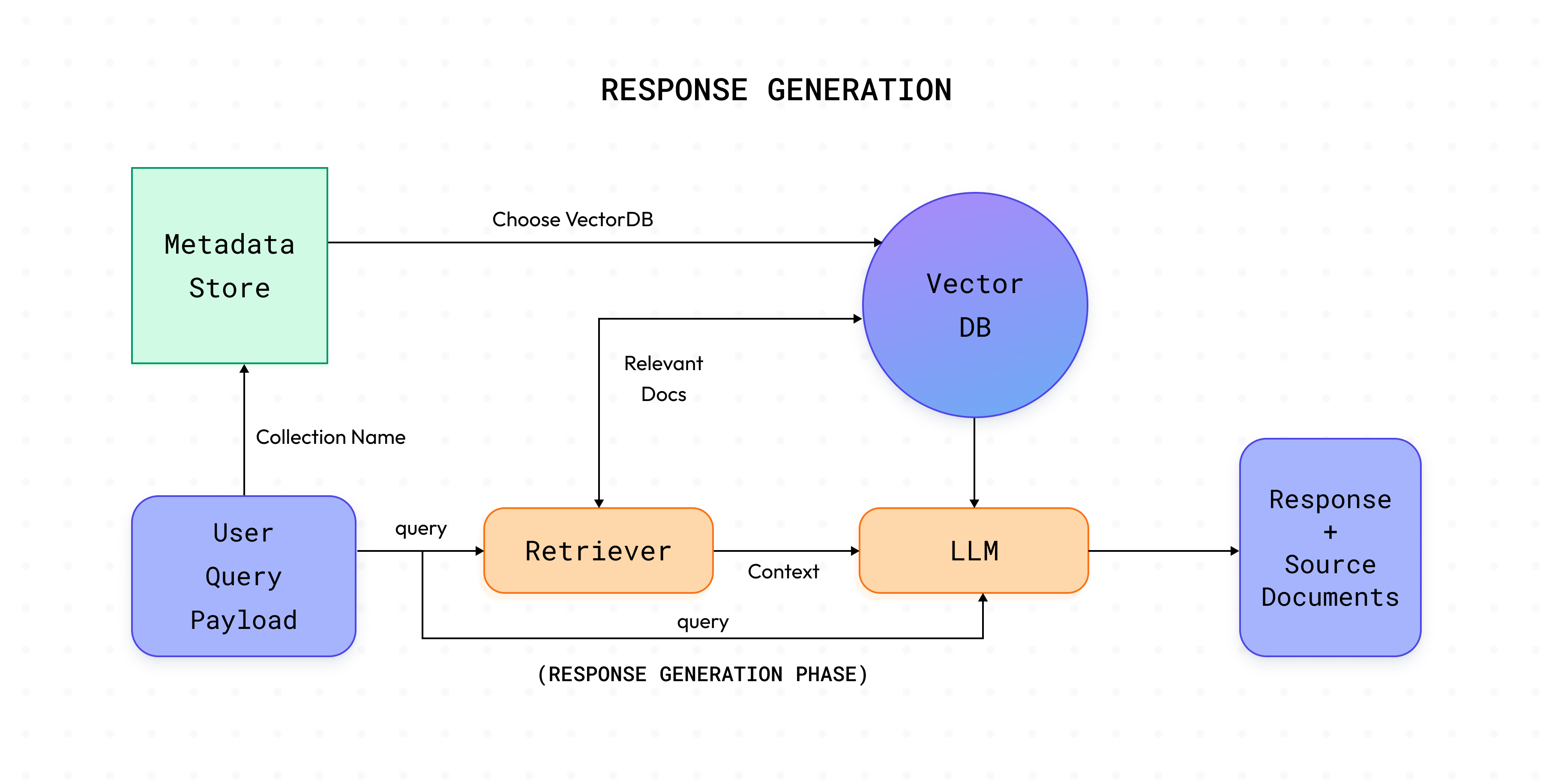
In der Phase der Antwortgenerierung wird der angerufen /antwort Endpunkt Ihres definierten Abfrage-Controller und generiert die Antwort für die angeforderte Anfrage.
Die folgenden Schritte zeigen, wie Sie die Cognita-Benutzeroberfläche zum Abfragen von Dokumenten verwenden:
1. Datenquelle erstellen
Datenquellen Registerkarte 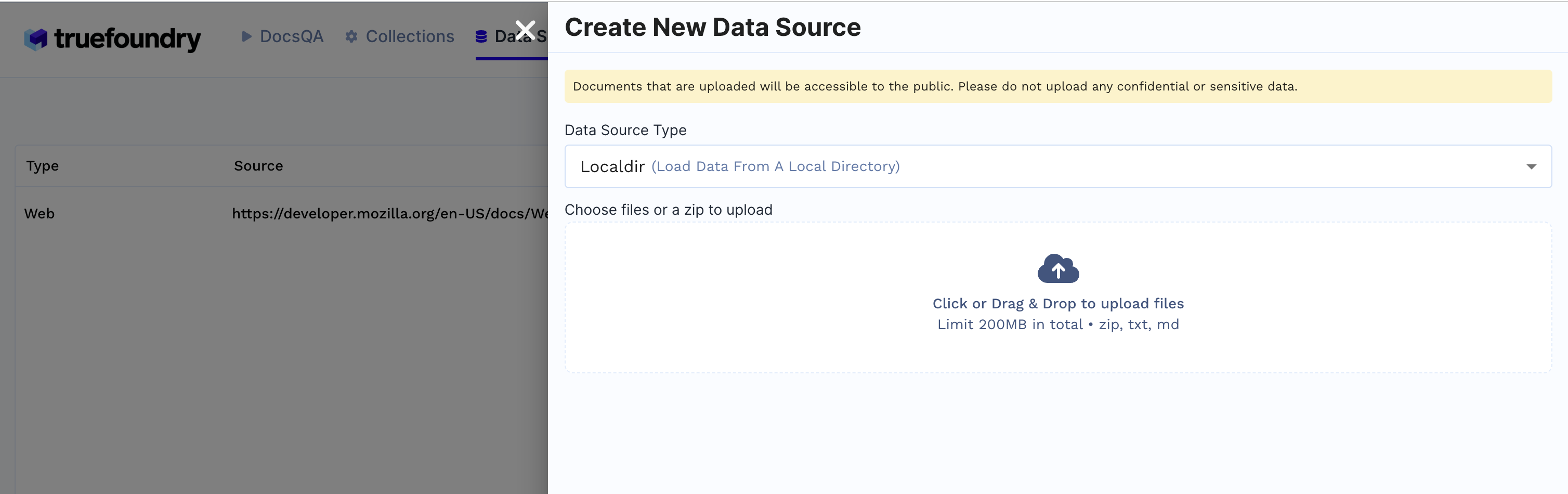
+ Neue DatenquelleLokales Verzeichnis ist ausgewählt, laden Sie Dateien von Ihrem Computer hoch und klicken Sie auf Einreichen.
2. Sammlung erstellen
Sammlungen Registerkarte+ Neue Kollektion 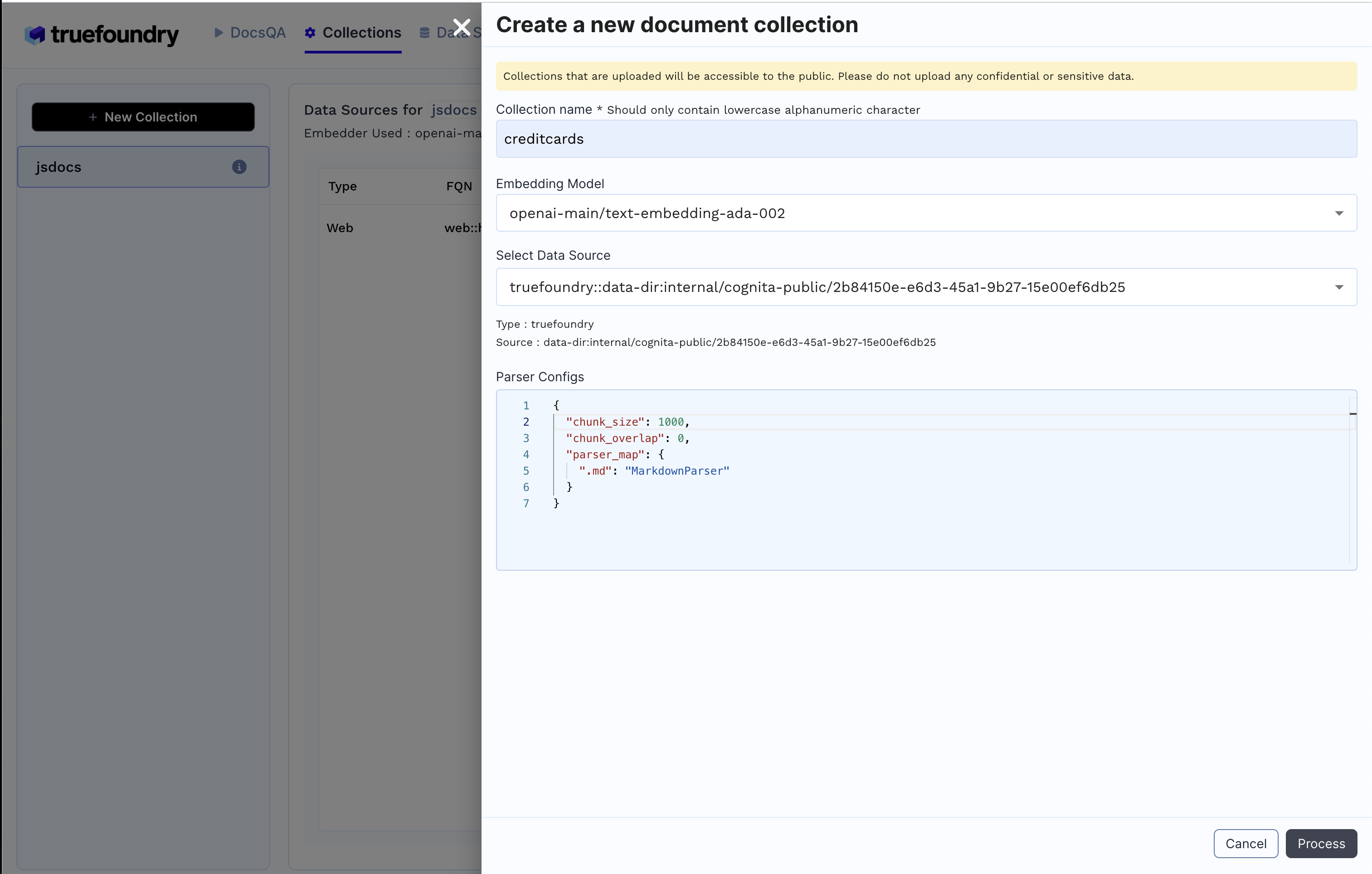
Prozess um die Sammlung zu erstellen und die Daten zu indexieren. 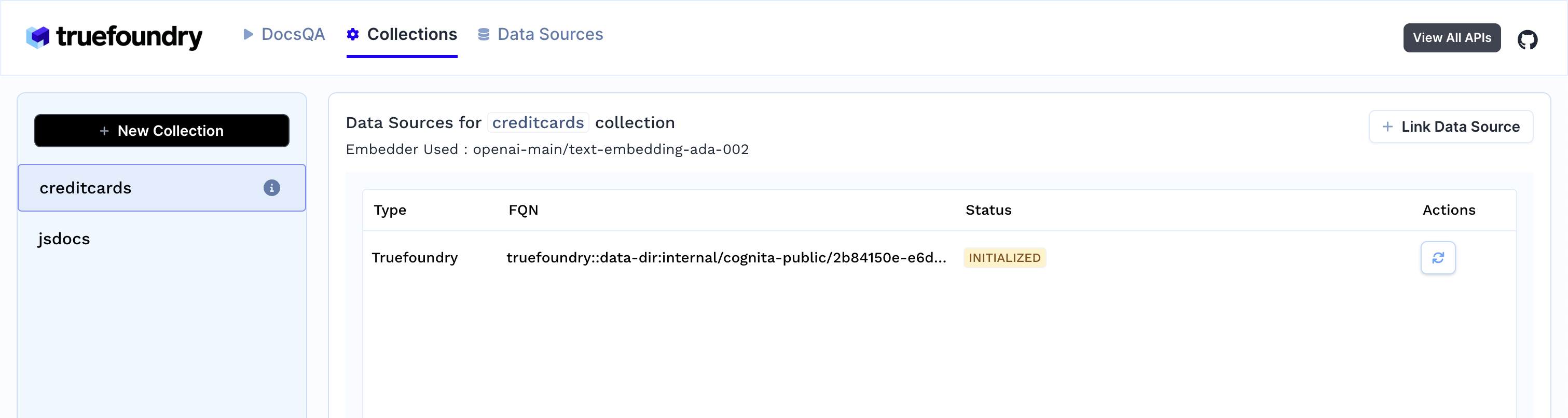
3. Sobald Sie die Sammlung erstellt haben, beginnt die Datenaufnahme. Sie können ihren Status einsehen, indem Sie Ihre Sammlung im Tab Sammlungen auswählen. Sie können später auch weitere Datenquellen hinzufügen und sie in der Sammlung indizieren.
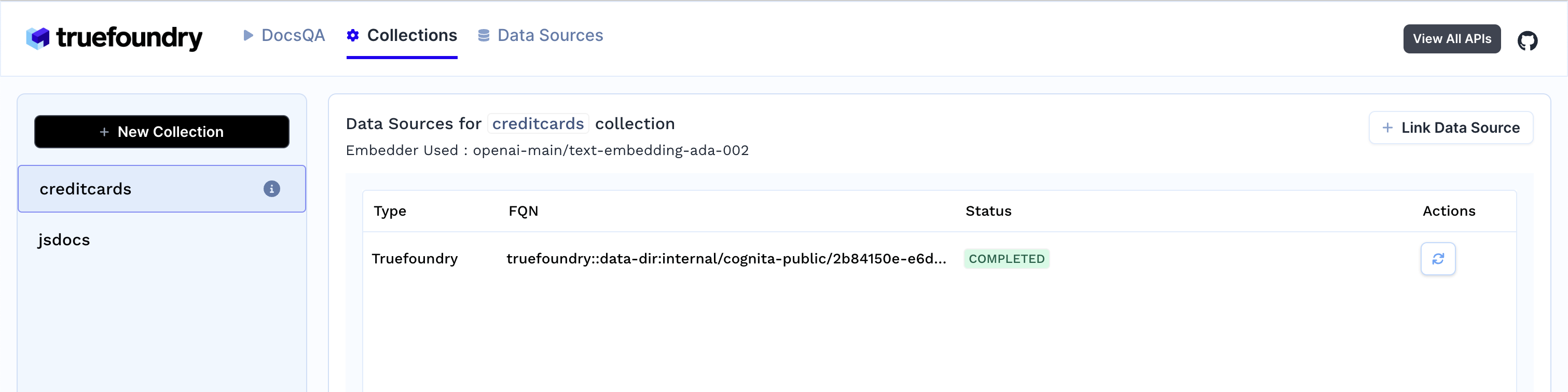
4. Generierung von Antworten
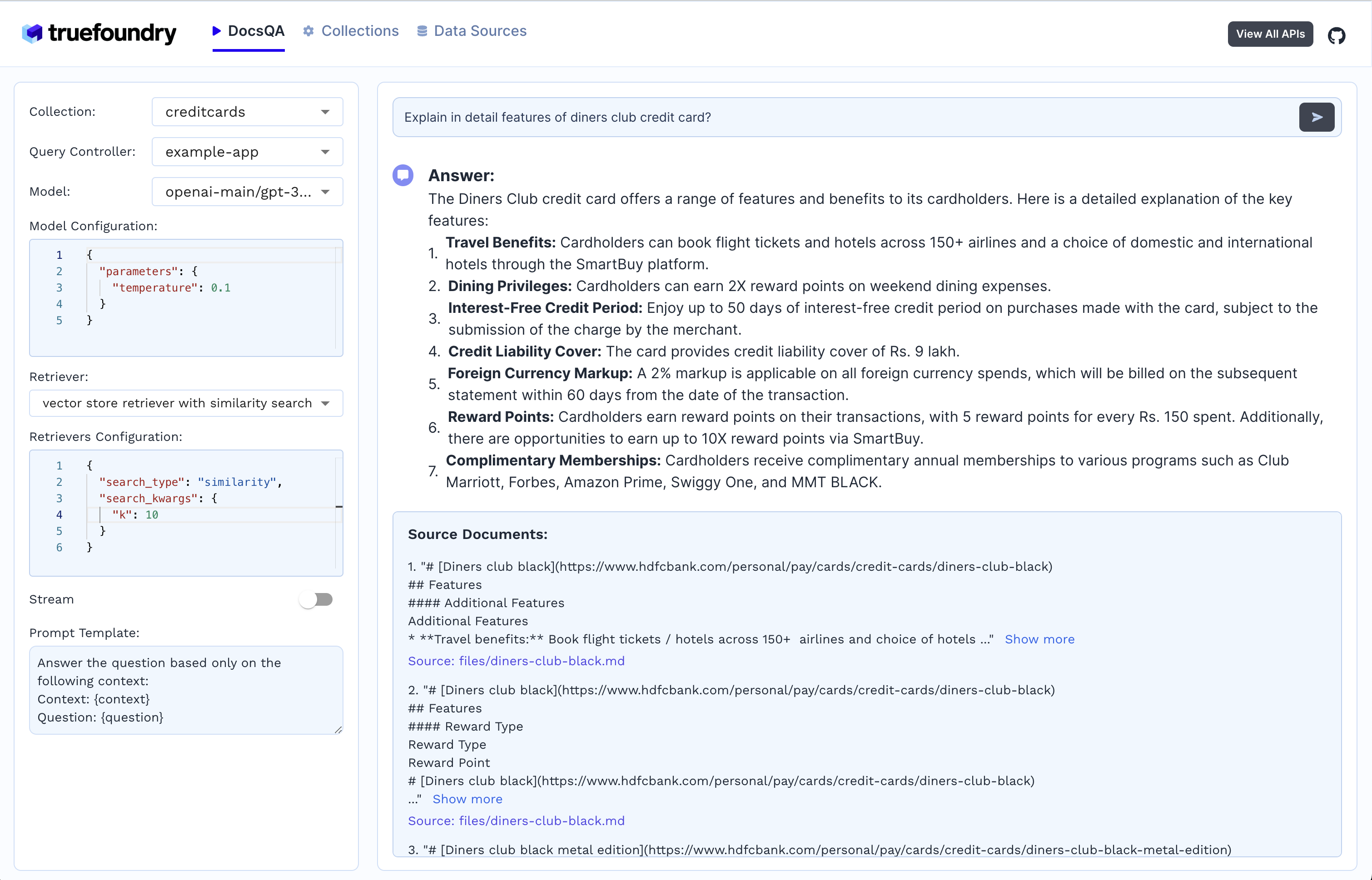
Buche ein pPersonalisierte Demo oder melden Sie sich an heute, um mit der Erstellung Ihrer RAG-Anwendungsfälle zu beginnen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)




.webp)
.webp)


.webp)
.webp)
.webp)
.png)




