




July 30, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: July 7, 2026

Blazingly fast way to build, track and deploy your models!
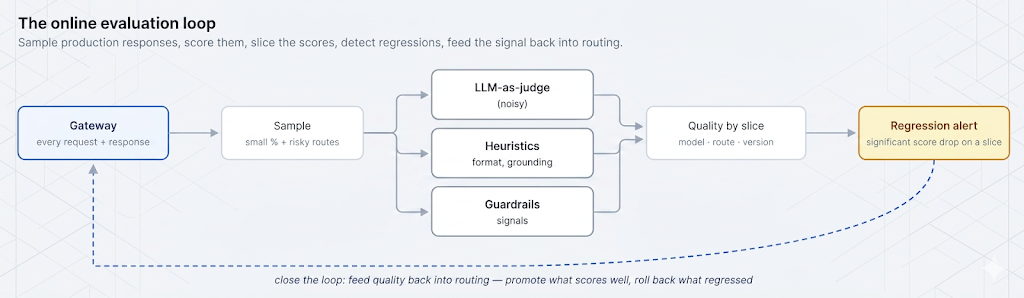
You can route by cost, fail over on outages, and cache aggressively — and still ship a change that quietly makes your answers worse. Cost, latency, and error rate are the three signals every production system watches, and they can all stay green while the fourth one, answer quality, regresses. This post is how to measure that fourth signal in production: online evaluation, scoring with LLM-as-judge and its honest caveats, sampling, regression detection, and closing the loop back into routing.
Leena, an ML engineer, made a change everyone wanted. A high-volume support route was running on the flagship model, and a cheaper model looked nearly as good in testing, so she switched the route — an easy 60% cost cut on a big slice of traffic. Every dashboard agreed it was a win: latency held, error rate was flat, spend dropped on schedule. The change shipped, the savings landed, and the team moved on. Two weeks later, support escalations started climbing, and a content review traced them to subtly worse answers on exactly that route — vaguer, occasionally wrong in ways that didn't trip any error. The quality had dropped the day she shipped. Nothing measured it, so nothing caught it for two weeks.
This is the blind spot at the center of LLM operations. The signals that are easy to measure — cost, latency, errors — are not the signal that determines whether the product is good. Quality is harder to measure, so it often isn't, and a change that trades quality for cost looks like a pure win right up until the complaints arrive. Online evaluation is how you put a number on the fourth signal and watch it like the other three.
Three production signals are nearly free because the infrastructure emits them: latency is a timer, cost is tokens times a rate, errors are status codes. Quality is none of these. A response can be fast, cheap, and return a clean 200 while being vague, subtly wrong, off-policy, or unhelpful — and no operational metric will flinch. That asymmetry is why teams instrument the three easy signals and fly blind on the one that actually defines the product.
Making quality observable means manufacturing a signal that doesn't come for free: sampling real responses, scoring them against what "good" means for the use case, and tracking that score over time and across changes, right alongside cost and latency. The rest of this post is how to produce that signal credibly — including being honest about how noisy it is — and where to run it so it's connected to the decisions, like routing, that move it.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada







.webp)


.webp)
.png)
.webp)
.webp)
.webp)





