



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
Blazingly fast way to build, track and deploy your models!
Grandes modelos de linguagem estão rapidamente se tornando uma camada central do software empresarial. O que começou como experimentação baseada em nuvem com APIs hospedadas está agora evoluindo para sistemas de nível de produção incorporados em ferramentas internas, aplicações voltadas para o cliente e fluxos de trabalho automatizados.
À medida que essa mudança ocorre, muitas organizações estão se deparando com uma dura realidade: nem todas as cargas de trabalho de IA podem ser executadas na nuvem pública.
Dados empresariais sensíveis, propriedade intelectual proprietária, cargas de trabalho regulamentadas, aplicações críticas de latência e obrigações de conformidade estão levando as equipes a implantar LLMs dentro de infraestrutura on-premise ou privada. No entanto, simplesmente hospedar modelos por conta própria não resolve o problema operacional maior. À medida que mais equipes, aplicações e modelos entram em operação, as organizações precisam de uma maneira consistente de controlar o acesso, aplicar políticas, monitorar o uso e gerenciar custos em todo o seu ecossistema de LLM.
É aqui que uma infraestrutura on-premise de Gateway LLM se torna fundamental.
Em vez de permitir que cada aplicação se integre diretamente com modelos individuais, um Gateway LLM introduz uma camada de controle centralizada que governa como os modelos são acessados e usados. Em ambientes on-premise, este gateway se torna a espinha dorsal que permite às empresas escalar a adoção de LLMs de forma segura, em conformidade e eficiente, sem sacrificar a visibilidade ou o controle.
Um Gateway LLM é uma camada centralizada de acesso e governança que se posiciona entre aplicações e modelos de linguagem. Em vez de as aplicações chamarem os modelos diretamente, todas as requisições LLM fluem através do gateway, que aplica controles de segurança, roteamento, observabilidade e política em um único local.
Em uma configuração on-premise, tanto o gateway quanto os modelos são executados inteiramente dentro da infraestrutura da organização - como um data center, nuvem privada (VPC) ou ambiente isolado (air-gapped). Isso garante que prompts, respostas, embeddings e metadados nunca saiam dos limites controlados.
Em termos gerais, um Gateway LLM on-premise oferece:
Ao abstrair o acesso ao modelo por trás de uma API padronizada, o gateway desvincula o desenvolvimento de aplicações da infraestrutura do modelo. As equipas podem trocar de modelos, introduzir versões ajustadas ou aplicar novas regras de governança sem modificar o código da aplicação.
Em ambientes on-premise onde a infraestrutura é finita, os requisitos de conformidade são rigorosos e a complexidade operacional é alta, esta camada de gateway centralizada é o que torna a adoção de LLMs em larga escala viável. Ela transforma modelos auto-hospedados de implementações isoladas em uma plataforma de IA governada e pronta para produção.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Executar LLMs on-premise raramente é apenas uma decisão de infraestrutura. Geralmente é impulsionado por requisitos empresariais não negociáveis em torno do controlo de dados, segurança e governança. Um Gateway LLM é o que torna estas implementações práticas em escala.
As empresas frequentemente lidam com entradas sensíveis, como documentos internos, registos de clientes, código-fonte ou dados classificados. Em ambientes regulamentados, mesmo dados de prompt transitórios que saem da infraestrutura controlada são inaceitáveis.
Um Gateway LLM no local garante que:
Isso é especialmente crítico para organizações que operam sob requisitos rigorosos de localização ou soberania de dados.
Integrações diretas de aplicação para modelo criam limites de segurança fragmentados. Cada serviço acaba gerenciando suas próprias credenciais, permissões e lógica de acesso, dificultando a aplicação de padrões de segurança uniformes.
Um Gateway LLM centraliza:
Ao rotear todo o tráfego através de uma única camada de controle, as empresas reduzem significativamente sua superfície de ataque e ganham confiança na forma como os modelos são acessados.
Estruturas regulatórias exigem cada vez mais que as organizações respondam a perguntas como:
Um Gateway LLM no local fornece trilhas de auditoria integradas por padrão. Cada solicitação pode ser registrada, medida e rastreada sem depender de equipes de aplicação individuais para implementar a lógica de conformidade corretamente.
Isso é essencial para ambientes sujeitos a GDPR, ITAR, HIPAA ou padrões de governança interna.
Os recursos de GPU on-premise são finitos e caros. Sem controles centralizados, as equipes podem facilmente consumir em excesso a capacidade de inferência ou implantar cargas de trabalho ineficientes.
Um Gateway LLM permite:
Isso permite que as organizações tratem a inferência de LLM como um recurso gerenciado, em vez de uma despesa descontrolada.
Um on-premise Gateway LLM não é um serviço único. É uma pilha de infraestrutura em camadas projetada para controlar como os modelos são acessados, governados e operados em ambientes corporativos.
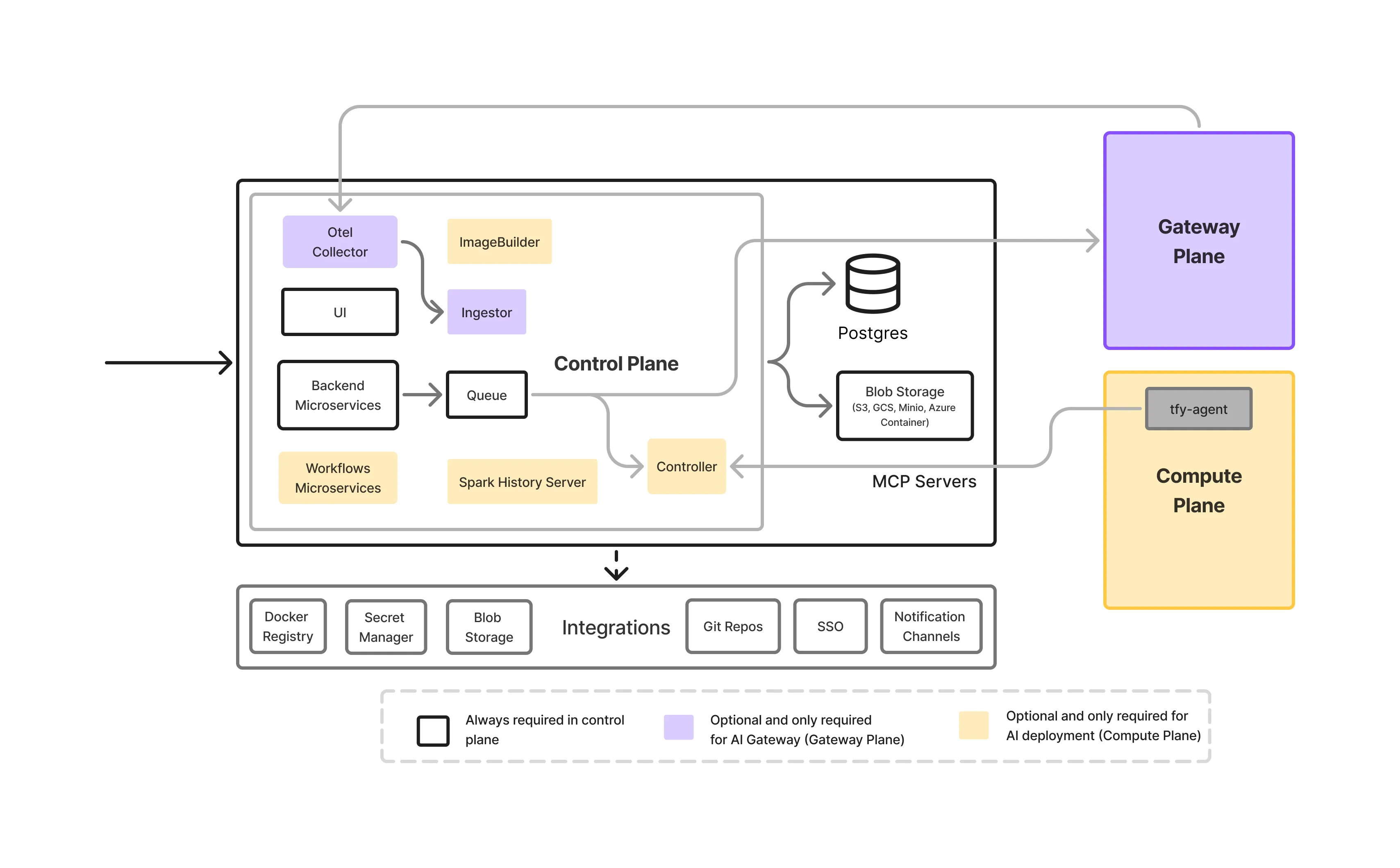
Esta é a porta de entrada para todo o tráfego LLM.
Ele lida com autenticação, autorização, validação de requisições e decisões de roteamento. Ao aplicar políticas centralizadamente, o plano de controle elimina a necessidade de as equipes de aplicação incorporarem lógica de segurança ou governança em seu código.
Esta camada é responsável por serviço de modelos, hospedando os LLMs reais em execução no local e expondo-os para inferência de baixa latência e acelerada por GPU, incluindo:
O gateway abstrai esses modelos por trás de uma API unificada, permitindo que as equipes alterem ou atualizem modelos sem impactar os aplicativos.
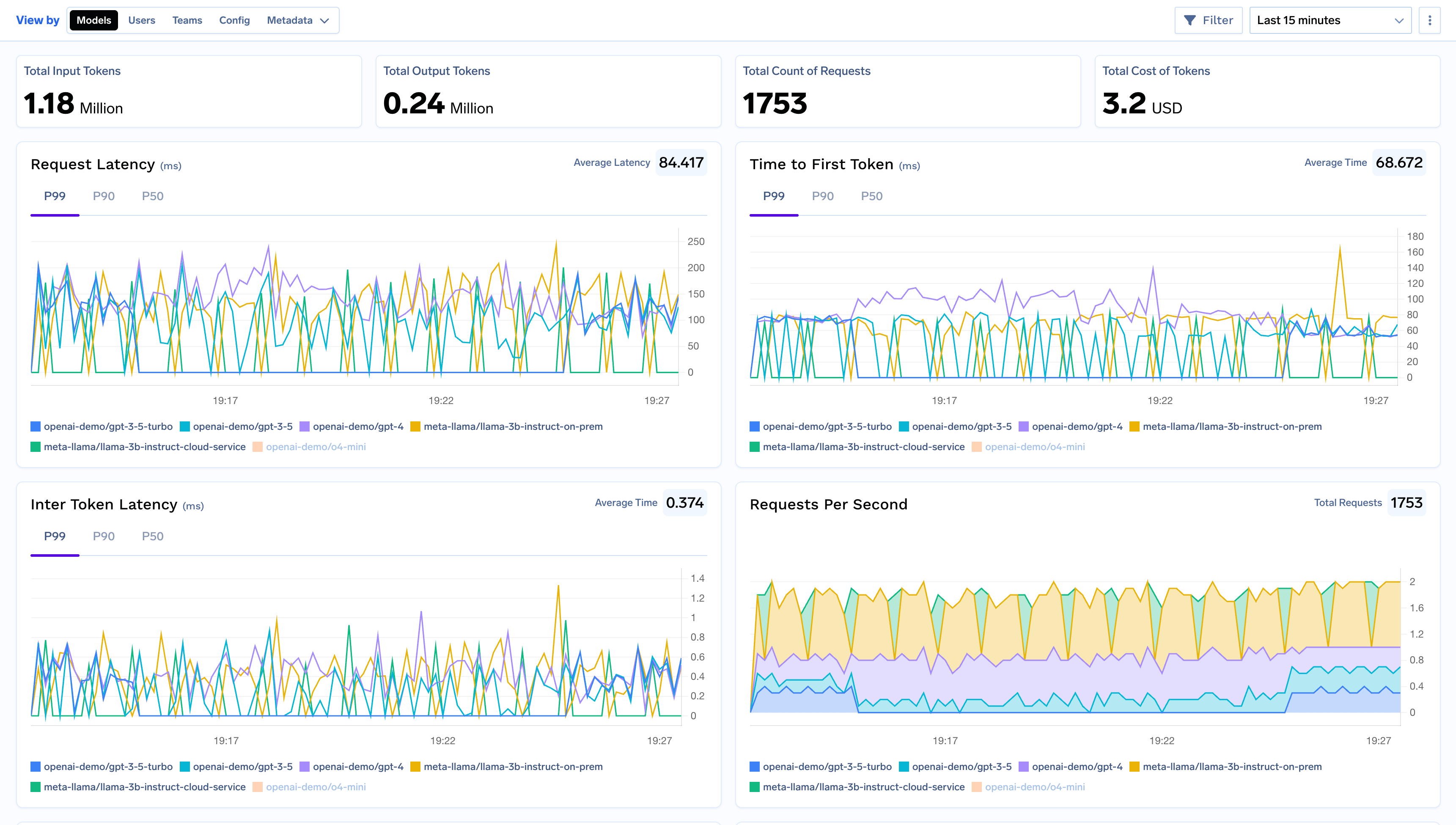
A visibilidade é essencial em ambientes no local onde os recursos são limitados.
O gateway oferece:
Isso permite que as equipes entendam como os modelos estão sendo usados e identifiquem problemas de desempenho ou custo antecipadamente.
As regras de governança são definidas uma vez e aplicadas em todos os lugares.
Isso inclui:
A governança centralizada evita o desvio de políticas entre equipes e aplicativos.
Os serviços de gateway e modelo geralmente são executados em infraestrutura baseada em Kubernetes com suporte a GPU. Esta camada oferece:
Garante que o gateway opere de forma confiável como parte da pilha de IA on-prem mais ampla.
Numa configuração on-premise, o Gateway LLM atua como a camada de controle central entre aplicações e modelos auto-hospedados. Todas as requisições passam por esta camada, garantindo segurança, governança e observabilidade consistentes.
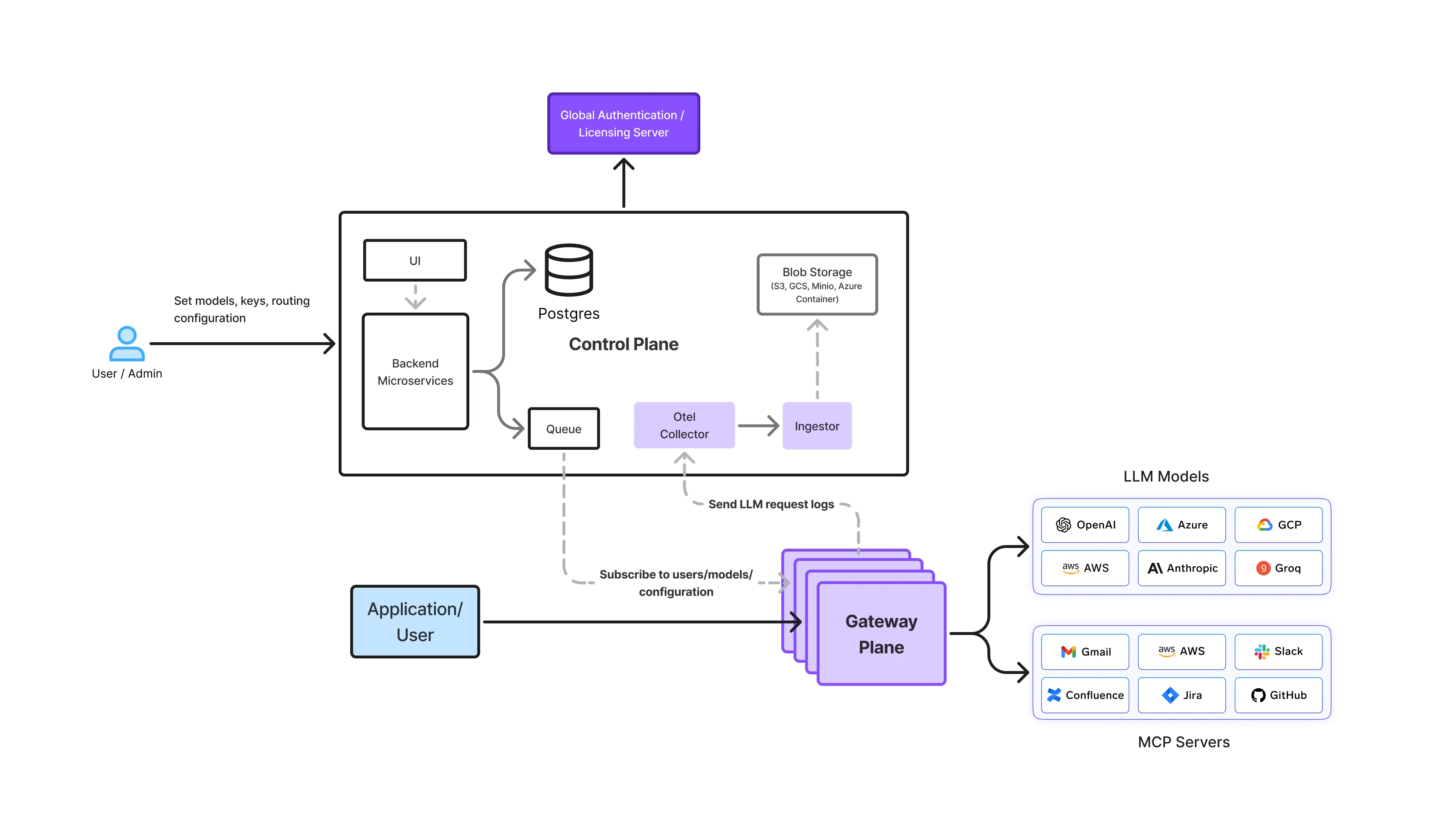
Empresas implantam Gateways LLM on-premise de diferentes maneiras, dependendo dos requisitos de segurança, conformidade e conectividade. A arquitetura do gateway permanece a mesma, o modelo de implantação muda.
Em ambientes altamente regulamentados, a infraestrutura opera com nenhum acesso à rede externa.
Nessas configurações, o Gateway LLM oferece controle total enquanto atende a rigorosos requisitos de isolamento.
Muitas empresas implantam Gateways LLM dentro de suas próprias contas de nuvem ou redes privadas.
Este modelo é comum para SaaS regulamentado e organizações de serviços financeiros.
Algumas organizações dividem as cargas de trabalho com base na sensibilidade.
O gateway garante políticas consistentes mesmo quando múltiplos ambientes de execução estão envolvidos.
Embora os Gateways LLM on-premise ofereçam controle e conformidade, eles também introduzem desafios operacionais para os quais as empresas precisam se planejar.
Gerenciar cargas de trabalho de inferência com suporte de GPU on-premise requer um planejamento de capacidade cuidadoso. Sem automação, escalar modelos ou lidar com picos de tráfego pode se tornar operacionalmente pesado.
Ambientes on-premise têm capacidade de computação finita. Roteamento inadequado ou falta de controles de solicitação podem levar a problemas de latência ou GPUs subutilizadas. O gerenciamento centralizado de tráfego é essencial para equilibrar desempenho e eficiência.
À medida que múltiplas equipes adotam LLMs, as regras de governança podem facilmente se desviar se aplicadas no nível do aplicativo. Manter controles de acesso e políticas de uso consistentes em todos os ambientes é difícil sem um gateway centralizado.
As empresas devem manter registros claros do uso de LLM sem sobrecarregar o armazenamento ou impactar o desempenho. Encontrar o equilíbrio certo entre observabilidade e sobrecarga é um desafio comum.
Empresas que obtêm sucesso com implantações de LLM on-premise tratam o gateway como infraestrutura central, não apenas um proxy de API.
Todas as aplicações e agentes devem aceder aos modelos exclusivamente através do gateway. Isto elimina integrações ocultas e garante segurança e governação uniformes.
As aplicações nunca devem depender de endpoints de modelo específicos. Abstrair os modelos por trás do gateway permite que as equipas troquem, atualizem ou ajustem modelos sem alterações no código.
Os controlos de acesso, limites de taxa e regras de utilização devem residir na camada do gateway – e não dentro da lógica da aplicação. Isto evita a divergência de políticas entre equipas e ambientes.
Desenvolvimento, staging e produção devem ser isolados ao nível da infraestrutura e da política. Isto reduz o risco e torna a experimentação mais segura.
Capture telemetria suficiente para auditoria e otimização, enquanto mascara ou limita dados sensíveis de prompts onde necessário. A observabilidade deve permitir o controlo, não introduzir novos riscos.
Seguir estas práticas garante que os Gateways LLM on-premise permaneçam seguros, escaláveis e geríveis à medida que a adoção cresce.
À medida que as empresas avançam para além da experimentação e incorporam modelos de linguagem grandes em sistemas centrais, o controlo torna-se tão importante quanto a capacidade. As implementações on-premise abordam as necessidades de residência de dados, segurança e conformidade, mas sem uma camada de acesso centralizada, rapidamente se tornam fragmentadas e difíceis de governar.
Uma infraestrutura de Gateway LLM on-premise fornece esse plano de controlo em falta. Padroniza a forma como as aplicações interagem com os modelos, impõe políticas consistentes e oferece a visibilidade necessária para operar LLMs de forma responsável em escala.
Escolher o melhor gateway LLM para implantações on-premise requer equilibrar governança, desempenho e simplicidade operacional, em vez de focar apenas no roteamento de requisições.
Em vez de tratar modelos auto-hospedados como serviços isolados, as organizações que adotam uma abordagem 'gateway-first' transformam os LLMs em infraestrutura empresarial gerenciada - segura, observável e pronta para o crescimento a longo prazo.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




