



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 29, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
Operações Financeiras (FinOps) tornou-se uma disciplina essencial na era da nuvem, reunindo equipes de engenharia, finanças e negócios para maximizar o valor dos gastos com tecnologia. À medida que as empresas adotam IA e modelos de linguagem grandes (LLMs) em escala, os princípios de FinOps são agora cruciais também para cargas de trabalho de IA.
Por quê? Porque a IA introduz novos desafios de custo que o gerenciamento tradicional de custos de nuvem não foi projetado para lidar. No mundo impulsionado pela IA, controlar os gastos é tão crítico quanto a precisão do modelo ou o tempo de atividade. Aqui estão alguns desafios de custo únicos introduzidos pelas iniciativas modernas de IA:
FinOps – é a disciplina de gerenciamento financeiro da nuvem, e seus princípios fundamentais são visibilidade, responsabilidade, e otimização. FinOps para IA significa aplicar esses mesmos princípios a esses desafios específicos da IA. Nas seções abaixo, detalharemos como cada princípio FinOps se aplica à IA e, crucialmente, como a plataforma da TrueFoundry ajuda a implementá-los de uma forma prática e amigável para engenheiros.
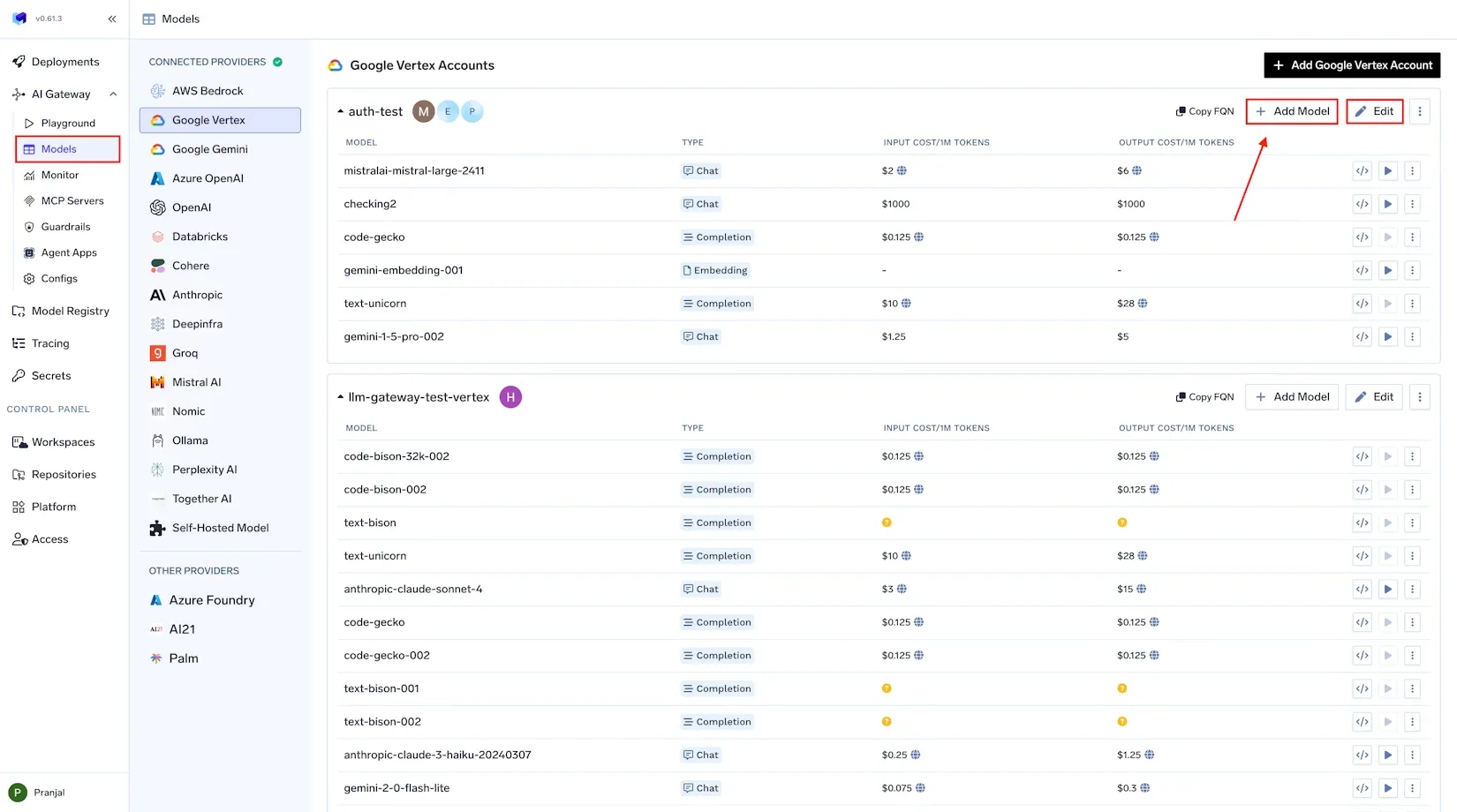
O primeiro pilar do FinOps é a visibilidade – “Não se pode melhorar o que não se mede.” No contexto da IA, visibilidade significa capturar dados abrangentes sobre cada invocação de modelo, para que você saiba exatamente para onde estão indo seus orçamentos de tokens e GPUs. Isso é mais fácil de dizer do que fazer quando o uso está espalhado por vários provedores e infraestruturas. A TrueFoundry aborda isso através de um Gateway de IA por onde todas as solicitações de IA são canalizadas.
Gateway de IA Unificado: O Gateway de IA da TrueFoundry atua como um único ponto de entrada (proxy) para todas as chamadas de modelos de IA – seja você acessando uma API externa como OpenAI ou Anthropic, ou um modelo auto-hospedado rodando em sua infraestrutura. Ao rotear todas as solicitações de inferência através de um único gateway, você estabelece um “painel único de controle” para observabilidade e rastreamento de custos. O gateway reconhece as nuances específicas do modelo, como contagem de tokens e latência, e registra cada solicitação de forma estruturada. Isso elimina pontos cegos da fragmentação de ferramentas: independentemente do modelo ou provedor utilizado, o uso é rastreado centralmente.
Registro Granular e Metadados: Cada solicitação que passa pelo AI Gateway da TrueFoundry é automaticamente registrada com metadados ricos para atribuição. Isso inclui o nome do modelo, carimbo de data/hora, contagem de tokens de entrada/saída, latência, o usuário ou chave de API que faz a solicitação e muito mais. As equipes também podem anexar tags/metadados personalizados a cada solicitação, como customer_id, application, environment ou feature_name.
Por exemplo, você pode marcar as solicitações com o recurso do produto ou a equipe interna responsável. A TrueFoundry facilita isso, permitindo que os desenvolvedores incluam um cabeçalho X-TFY-METADATA nas chamadas de API. Por exemplo, usando o SDK Python:
client = OpenAI(api_key="...", base_url="https://llm-gateway.truefoundry.com/api/inference/openai")
response = client.chat.completions.create(
model="openai-main/gpt-4",
messages=[{"role": "user", "content": "Hello"}],
extra_headers={
"X-TFY-METADATA": '{"application":"booking-bot","environment":"staging","customer_id":"123456"}',
"X-TFY-LOGGING-CONFIG": '{"enabled": true}'
}
)
Neste trecho, a solicitação é marcada com um nome de aplicativo, ambiente e ID de cliente como metadados. Todos os valores são strings (máx. 128 caracteres), e você pode incluir quantos campos forem necessários. Essas tags viajam com a solicitação através do gateway e são registradas em logs e métricas.
Coleta de Métricas em Tempo Real: O AI Gateway não apenas registra dados brutos – ele também emite métricas estruturadas para monitoramento. Para cada solicitação, a TrueFoundry rastreia métricas como o número de tokens de entrada, tokens de saída e o custo estimado dessa solicitação. Essas métricas são rotuladas com dimensões como nome do modelo, nome de usuário (ou serviço) e quaisquer tags de metadados personalizados que você tenha habilitado como rótulos.
Por exemplo, llm_gateway_request_total_cost é uma métrica de contador que acumula o custo dos tokens utilizados, rotulada por modelo, usuário e metadados personalizados como customer_id. Isso significa que você pode detalhar instantaneamente o custo por quaisquer categorias que sejam importantes para o seu negócio (equipe, cliente, recurso, etc.) em suas ferramentas de monitoramento.
Integração com Painéis de Monitoramento: A observabilidade da TrueFoundry foi projetada para se integrar à sua pilha de monitoramento existente. O gateway expõe um endpoint /metrics com métricas compatíveis com Prometheus e também pode enviar métricas via OpenTelemetry. Com algumas configurações, você pode fazer com que o gateway publique métricas para o seu backend Prometheus ou Datadog em tempo real. Uma vez ingeridas, essas métricas podem ser visualizadas em painéis Grafana ou em qualquer plataforma de análise que sua organização utilize.
Na verdade, a TrueFoundry fornece JSON de painel Grafana pré-construído para métricas do AI Gateway, cobrindo visualizações por modelo, por usuário e por regra de configuração.
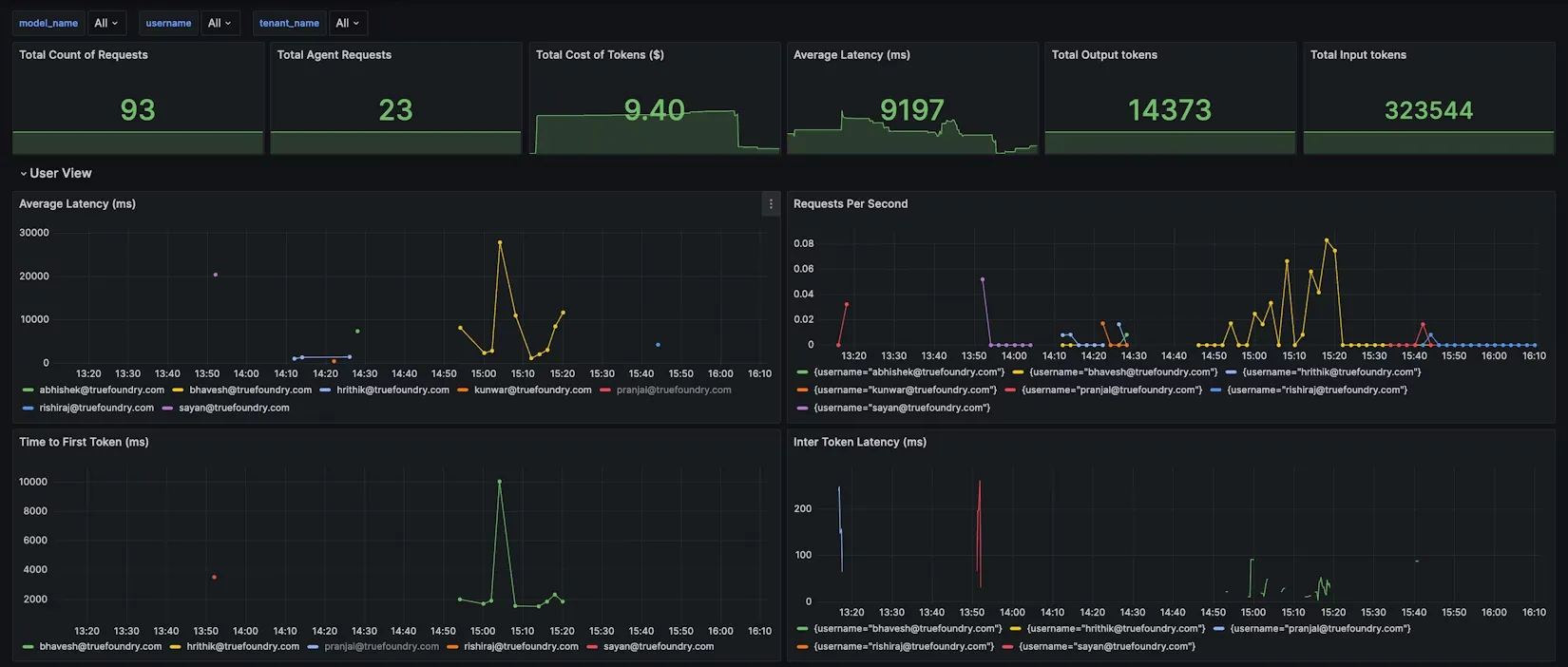
Por exemplo, a Visualização do Modelo pode mostrar o uso de tokens e a latência por modelo, enquanto a Visualização do Usuário detalha o uso por nome de usuário para identificar usuários com alto consumo. Você pode até adicionar filtros personalizados ao painel para suas tags de metadados (por exemplo, filtrar todos os gráficos por customer_id ou projeto) para obter relatórios de custo sob demanda para um determinado cliente ou projeto.
Ao centralizar todos esses dados, você alcança visibilidade completa sobre o consumo de IA. Torna-se trivial responder a perguntas como: Qual equipe gerou mais tokens GPT-4 esta semana? Quanto custou nosso novo recurso de chatbot em chamadas de API? Quais clientes ou usuários estão gerando o maior uso? Com o TrueFoundry, você pode simplesmente ativar um filtro ou executar uma consulta para obter essas respostas. Este nível de transparência é a base para o FinOps em IA – ele ilumina cada token e hora de GPU, transformando a incerteza em insights acionáveis.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

A visibilidade prepara o terreno, mas o FinOps também exige responsabilidade e proativa governança dos gastos. No FinOps em nuvem, as equipes são incentivadas a assumir a responsabilidade pelo seu uso e a aderir aos orçamentos. No FinOps em IA, dada a imprevisibilidade do uso, é essencial impor algumas salvaguardas para que os custos não fujam do controle devido a um bug ou a um experimento descontrolado. A plataforma do TrueFoundry incorpora governança de custos diretamente na camada de infraestrutura de IA, para que você possa controlar o uso em tempo real em vez de apenas reportá-lo após o ocorrido.
Atribuição por Requisição e Rateios de Custos: Como o TrueFoundry marca e rastreia cada requisição com metadados de equipe e projeto, você pode atribuir custos em um nível granular em tempo real. Isso permite modelos internos de chargeback ou showback – por exemplo, mostrar a cada equipe de produto quanto seus recursos estão gastando em IA, ou cobrar um cliente externo pelo seu uso específico.
As métricas de custo da TrueFoundry podem ser filtradas por esses atributos para produzir detalhamentos instantâneos (custo por usuário, por recurso, por cliente, etc.). Compartilhar esses relatórios cria responsabilidade: as equipes podem ver o impacto do seu código e dos seus prompts na fatura, e o setor financeiro pode garantir que as despesas sejam mapeadas para unidades de negócio ou clientes.
Controle de Acesso Baseado em Funções e Permissões: Parte da governança é garantir o uso apenas autorizado de recursos caros. O gateway de nível empresarial da TrueFoundry suporta controle de acesso baseado em funções (RBAC) e gerenciamento de chaves de API. Isso significa que você pode restringir quem tem permissão para chamar certos modelos de alto custo ou limitar o acesso a recursos experimentais.
Por exemplo, você pode permitir que um ambiente de QA ou de homologação use um modelo menor, mas apenas a produção pode chamar a API cara do GPT-4. Ou você pode limitar a chave de API de um desenvolvedor júnior a um modelo sandbox. Ao controlar o acesso, você evita o uso acidental de modelos caros por pessoas não autorizadas. Combinado com logs de auditoria detalhados e metadados, isso também cria um rastro de auditoria para conformidade (ou seja, você sabe exatamente qual usuário ou serviço fez cada solicitação).
Políticas de Limitação de Taxa: Uma das salvaguardas FinOps mais poderosas é a limitação de taxa. O AI Gateway da TrueFoundry permite configurar regras flexíveis de limitação de taxa para limitar o uso em várias dimensões – por usuário, equipe, modelo ou até mesmo tags personalizadas.
Por exemplo, você pode dizer “O Usuário X só pode fazer 1.000 solicitações GPT-4 por dia” ou “Todas as solicitações do projeto ABC são limitadas a 50.000 tokens por hora.” A configuração é definida em um formato YAML simples. Aqui está um trecho de exemplo ilustrando algumas regras:
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
# 1. Limit a specific user to 1000 requests/day on the GPT-4 model
- id: "limit-gpt4-user1-daily"
when:
subjects: ["user:[email protected]"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_day
# 2. Limit each project (by metadata tag) to 50k tokens per hour
- id: "project-{metadata.project_id}-hourly"
when: {}
limit_to: 50000
unit: tokens_per_hourNa regra #1 acima, um usuário específico (identificado por sua chave de API ou nome de usuário) é limitado a 1000 solicitações GPT-4 por dia. Na regra #2, impomos um limite de 50 mil tokens/hora por projeto, assumindo que cada solicitação inclua um project_id em seus metadados. A sintaxe {metadata.project_id} significa que o gateway aplicará um bucket separado para cada ID de projeto único encontrado. Na prática, essa regra impede que qualquer projeto consuma acidentalmente mais de 50 mil tokens em uma hora (por exemplo, se uma integração falhar ou um cliente tiver um pico inesperado). O gateway avalia as solicitações recebidas contra essas regras em ordem, e se uma solicitação exceder um limite, ela é limitada ou rejeitada no mesmo instante.
Alertas e Cotas de Orçamento: Além dos limites de taxa brutos, a TrueFoundry permite definir limites orçamentários. Você pode definir tetos de gastos mensais ou diários para uma equipe ou aplicação. Por exemplo, você pode orçar US$ 1000/mês para a experimentação de LLMs por uma equipe de desenvolvimento. O Gateway pode rastrear o custo cumulativo das requisições e, uma vez que o limite é ultrapassado, pode enviar alertas ou desativar o uso adicional até que um administrador intervenha. Isso é essencialmente aplicação automatizada do orçamento. Em vez de descobrir no final do mês que a Equipe A gastou demais, você detecta (por exemplo) a 80% do orçamento e pode tomar medidas.
O gateway da TrueFoundry pode até mesmo limitar automaticamente ou pausar requisições quando um orçamento é esgotado, evitando gastos excessivos e notificando as partes interessadas. As equipes financeiras apreciam esse tipo de rede de segurança, pois transforma a governança de custos em um processo ativo e contínuo, em vez de uma análise pós-fato.
Diretrizes e Validação de Prompts: Outro aspecto da governança é a aplicação das melhores práticas em prompts e padrões de uso para evitar explosões de custos. A plataforma da TrueFoundry inclui recursos de salvaguarda para, por exemplo, bloquear certos prompts inseguros ou ineficientes. Você pode configurar regras para rejeitar prompts que excedam um comprimento máximo de token ou contenham conteúdo não permitido.
Da mesma forma, a TrueFoundry suporta esquemas de saída estruturados e modelos de prompt que ajudam a manter as respostas concisas e previsíveis, controlando indiretamente o uso de tokens.
O princípio final do FinOps é a otimização – melhorando continuamente a eficiência de custos sem sacrificar o desempenho ou os resultados. Após alcançar visibilidade e estabelecer a governança, as organizações podem focar em obter mais valor de cada dólar gasto em IA. A TrueFoundry oferece múltiplas vias para otimizar cargas de trabalho de IA, desde o roteamento inteligente de requisições no nível do modelo até a utilização eficiente da infraestrutura de GPU.
Seleção Inteligente de Modelos (Dimensionamento Correto de Modelos): Nem toda tarefa exige o modelo mais caro. Um pilar da otimização de custos de IA é usar o modelo mais barato e suficiente modelo para cada tarefa. O AI Gateway da TrueFoundry suporta roteamento de modelo híbrido estratégias para que você possa direcionar automaticamente as solicitações para diferentes modelos com base em políticas de custo ou complexidade.
Por exemplo, você pode rotear consultas simples ou solicitações de baixa prioridade para um modelo menor e mais barato (como um modelo 7B de código aberto ou um nível GPT-3.5 da OpenAI), e enviar apenas consultas complexas ou de alto risco para um modelo premium como o GPT-4. Muitas equipes descobrem que uma grande porcentagem do seu tráfego pode ser tratada por modelos mais baratos, reservando o modelo caro para os poucos casos em que sua capacidade superior é realmente necessária. A TrueFoundry torna isso viável ao permitir o roteamento baseado em regras (ou até mesmo roteamento dinâmico baseado em ML) na configuração do gateway. O resultado é evitar o pagamento excessivo por modelos "exagerados" – você nunca paga a mais por uma capacidade que não precisa quando o gateway pode mudar automaticamente para um modelo mais barato para os cenários certos.
Processamento em Lote e Cache: Quando você paga por solicitação ou por token, compensa eliminar trabalho redundante. A plataforma da TrueFoundry oferece recursos para processamento em lote e cache de resposta para melhorar a eficiência. Com a API de Inferência em Lote, você pode combinar múltiplos prompts ou entradas em uma única solicitação para amortizar os custos indiretos.
Otimização e Truncamento de Prompts: Outra via de otimização é a redução do tamanho do prompt. Através da observabilidade, você pode descobrir que certos prompts são desnecessariamente longos (por exemplo, incluindo contexto irrelevante). Técnicas como compressão de prompt, uso de histórico mais curto ou emprego de Geração Aumentada por Recuperação (onde o conhecimento externo é buscado de forma relevante em vez de despejar um documento inteiro no prompt) podem reduzir a contagem de tokens.
A TrueFoundry suporta fluxos de trabalho RAG e até mesmo ferramentas de gerenciamento de prompts (como versionamento e teste de prompts) para ajudar as equipes a iterar em direção a prompts mais eficientes. Por exemplo, em vez de uma conversa de usuário enviar todo o histórico do chat a cada turno, você pode resumir ou descartar o contexto mais antigo assim que ele se tornar irrelevante – trocando um pouco de precisão por uma grande economia de custos. O Prompt Playground e as análises da TrueFoundry podem ajudar a analisar como o comprimento do prompt se correlaciona com o custo, destacando onde você pode "cortar gordura".
Otimização do Uso de GPU: Para equipes que executam modelos auto-hospedados ou realizam trabalhos de treinamento, otimizar a infraestrutura de GPU é crucial para FinOps. A plataforma de ML da TrueFoundry foi projetada para maximizar a utilização da GPU e eliminar o desperdício. As principais capacidades incluem:
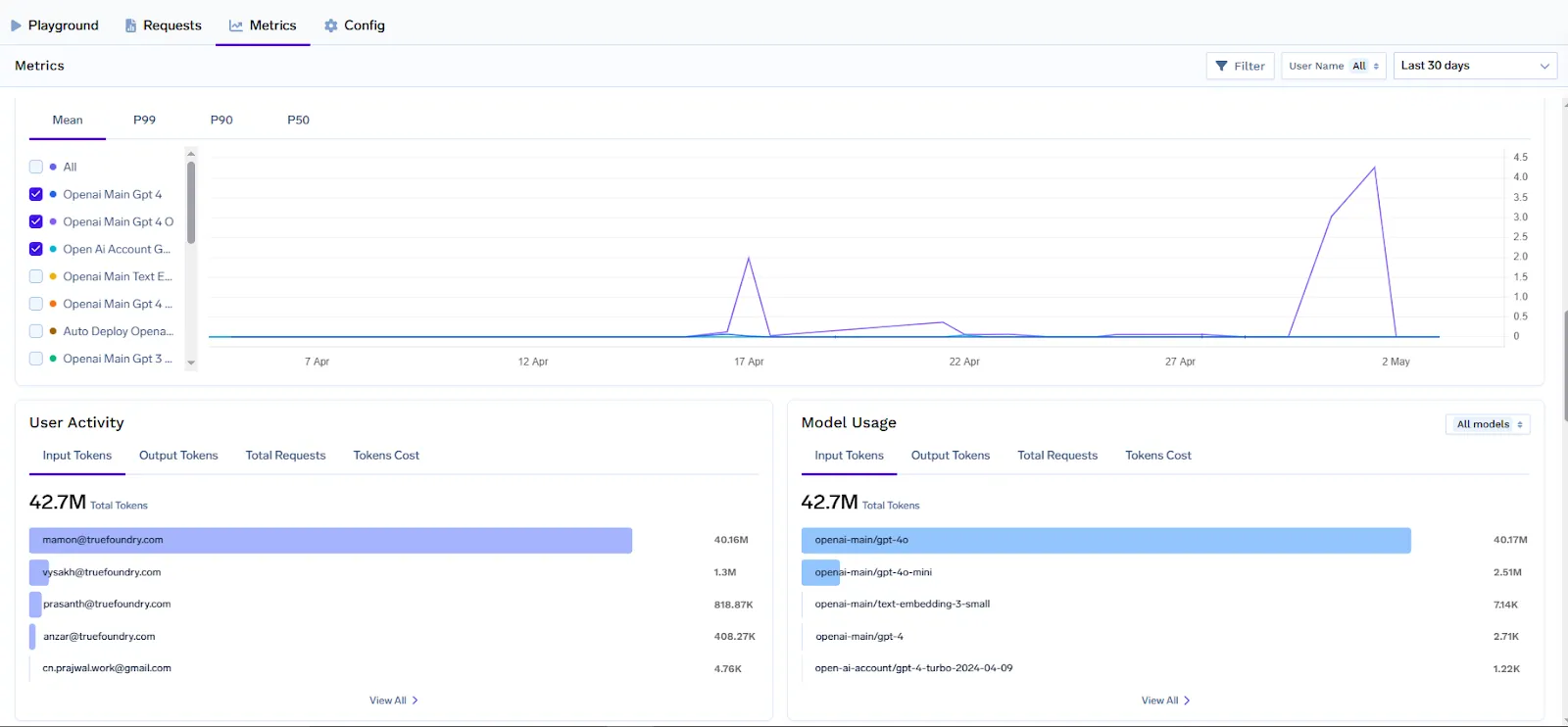
Uma iniciativa prática de FinOps se beneficia de relatórios claros e painéis que reúnem métricas e insights de negócios. A TrueFoundry simplifica a criação de painéis de FinOps para IA fornecendo todos os dados necessários prontos para uso e pontos de integração para ferramentas populares.
Usando as métricas exportadas pelo AI Gateway, as equipes podem construir painéis no Grafana, Datadog ou qualquer ferramenta de BI para visualizar o uso de IA e as tendências de gastos. Por exemplo, como cada solicitação é rotulada com equipe e modelo, você poderia criar um painel no Grafana mostrando “Custo por Equipe (Últimos 7 Dias)” consultando a métrica llm_gateway_request_total_cost agrupada por tenant_name (equipe). Outro painel pode mostrar “Tokens por Requisição por Modelo” para identificar quais modelos consomem muitos tokens e podem precisar de otimização. A solução da TrueFoundry painel pré-configurado do Grafana já inclui visualizações para analisar o uso por modelo, por usuário e por regras de configuração (por exemplo, para ver se algum limite de taxa está sendo atingido com frequência). Você pode estendê-las com metadados personalizados; por exemplo, adicionar um filtro para customer_id como uma variável, para que as partes interessadas possam selecionar um cliente específico e ver seu uso de tokens e custo ao longo do tempo.
A integração com outras ferramentas de monitoramento e APM é possível via OpenTelemetry. Se sua organização usa Datadog, você pode encaminhar as métricas do gateway para a ingestão de métricas do Datadog (já que o Datadog pode ingerir métricas OpenTelemetry ou Prometheus). Isso significa que suas métricas de custo de IA podem coexistir com suas métricas de custo de infraestrutura. Torna-se fácil correlacionar, por exemplo, um aumento no uso de tokens com uma implantação específica ou lançamento de recurso, porque todos os dados estão acessíveis em um só lugar.
A TrueFoundry também oferece uma API de Análise para dados de uso, assim, se você preferir puxar os dados para um painel financeiro personalizado ou uma planilha, pode fazê-lo. Muitas empresas exportam dados brutos (a TrueFoundry até permite o download de dados de custo em CSV) para combinar com registros de faturamento, obtendo uma imagem completa do custo por projeto ao adicionar despesas gerais como armazenamento ou rede.
A chave é que, com a base que a TrueFoundry estabelece (marcação de metadados, métricas em tempo real), a criação desses insights de FinOps não exige a construção de um pipeline de dados do zero. Você obtém dados precisos e ricos em atribuição em tempo real, o que é um grande avanço em relação a esperar pela fatura da nuvem no final do mês. Líderes de engenharia, ML e finanças podem revisar juntos painéis que respondem a perguntas técnicas e de negócios sobre o uso de IA. Essa visibilidade multifuncional promove uma cultura de conscientização de custos
Implementar FinOps para IA é uma jornada contínua. Começa com conscientização e se transforma em uma disciplina incorporada ao ciclo de vida de desenvolvimento de IA. Ao estabelecer práticas de visibilidade, responsabilidade e otimização, as organizações progridem na maturidade FinOps – de relatórios de custos reativos para controle de custos em tempo real e, eventualmente, otimização preditiva. Mais importante, construir uma cultura FinOps em torno da IA garante a sustentabilidade. A adoção da IA estagnará se os custos crescerem sem controle ou de forma imprevisível. Ao ver a IA através da lente FinOps, as organizações tratam o acesso a modelos e o tempo de GPU como recursos valiosos a serem gerenciados, não como magia ilimitada. Essa mudança cultural é possibilitada por ferramentas: quando as equipes têm acesso de autoatendimento a métricas e relatórios de custos, elas podem assumir a responsabilidade. A solução da TrueFoundry acelera essa adoção cultural ao tornar o uso da IA transparente e governado por design – a visibilidade e os controles de custos vêm incorporados na plataforma, não como um adendo.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




